
轻量级SaaS化应用数据链路构建方案的技术探索及落地实践


导语
2022腾讯全球数字生态大会已圆满落幕,大会以“数实创新、产业共进”为主题,聚焦数实融合,探索以全真互联的数字技术助力实体经济高质量发展。大会设有29个产品技术主题专场、18个行业主题专场和6个生态主题专场,各业务负责人与客户、合作伙伴共同总结经验、凝结共识,推动数实融合新发展。
本次大会设立了微服务与中间件专场,本专场从产品研发、运维等最佳落地实践出发,详细阐述云原生时代,企业在开发微服务和构建云原生中间件过程中应该怎样少走弯路,聚焦业务需求,助力企业发展创新。
随着大数据时代的到来,企业在生产和经营活动中产生的各类数据正以前所未有的速度增长,通过对实时及历史数据的融合分析,及时挖掘业务洞察和辅助决策,已成为企业的普遍行动。在云原生的浪潮下,企业需要聚焦业务,迫切需要简单易行,零代码地配置搭建起自己的可以达到将本增效效果的数据链路系统。
本篇文章将从以下几个方面对围绕着消息队列如何快速搭建数据链路的落地实践进行分享。
数据链路构建的挑战
技术架构体系的建设
客户实践和落地案例

数据链路构建的挑战与开源生态
数据链路构建的挑战
如下图所示,这是一张经典的数据链路的架构图,从左到右依次可以分为数据源、数据接入层、数据缓冲层、数据处理层和右边的数据目标。在这样一个典型的数据链路里,技术组件非常多,导致整个图非常复杂,这会增加运维成本。
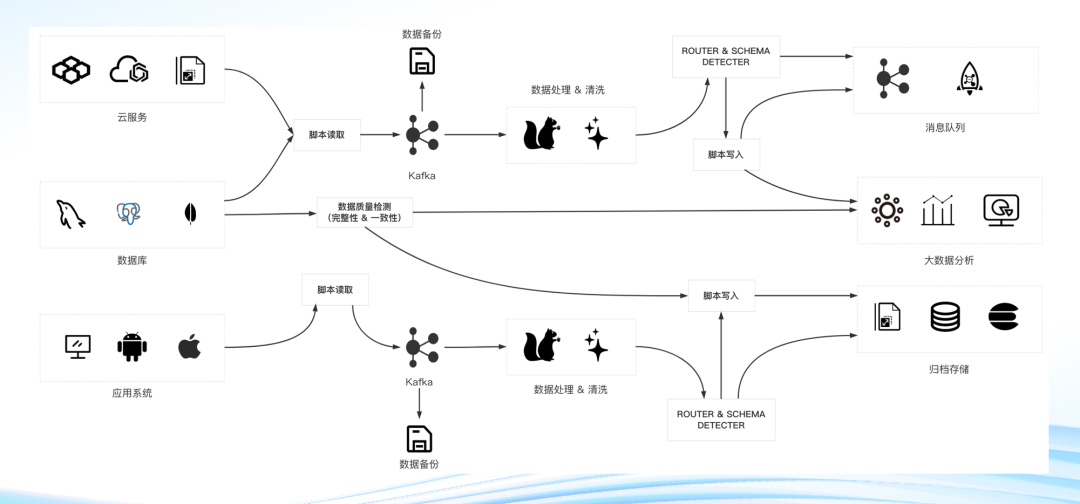
图1
接下来看另一张图,如果把中间部分全部屏蔽掉,这个数据链路变为一款SaaS化的数据接入组件,那它就会非常轻量。
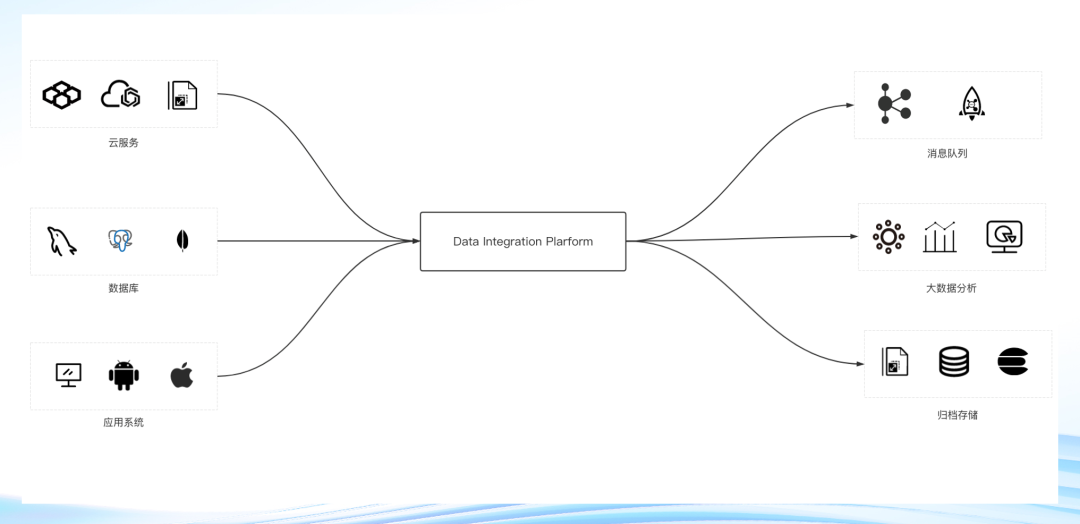
图2
所以在开源生态中,多样的数据源和数据目标,众多开源组件的学习成本,数据链路的搭建和运维是整个数据链路系统主要面对的问题。
企业需要聚焦业务,因此数据链路系统需要:SAAS 化、低代码化、简单易用、稳定可靠、高性能、按量付费。以达到整体上的的降本增效。
我们再回到图1,可以看到,它的缓冲层在业界主要都是 Kafka,然后围绕 Kafka 生态,具有丰富的上下游,那复杂度、学习成本、维护成本这些问题要如何解决呢?继续往下看。
数据链路功能矩阵
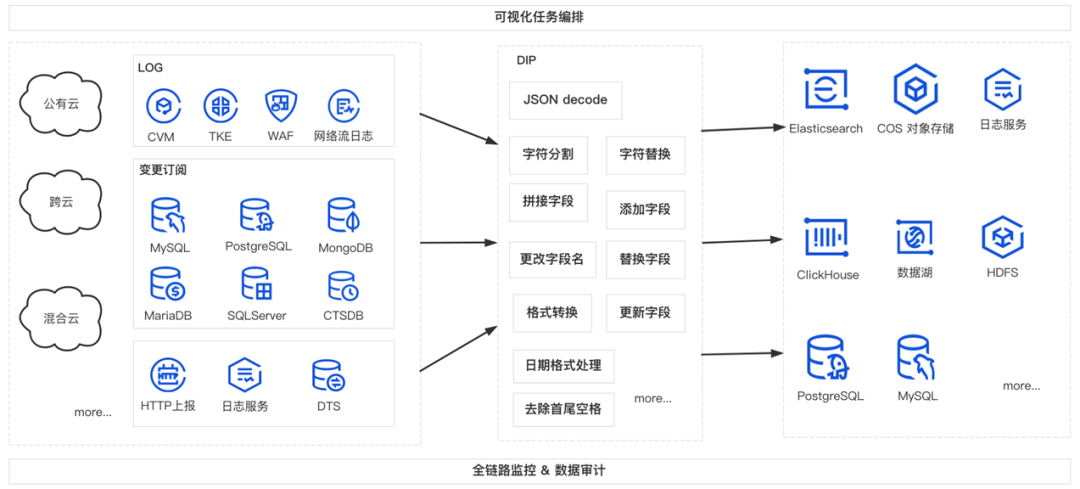
图3

图4
如上图3所示,数据链路由数据源、数据库两部分组成。
数据源
文本日志、CVM、容器、安全等;
数据库
数据库数据、主动上报数据等。
这些数据需要处理上报然后发到下游,在业界更多的是 Filebeat、Flink、Logstash 等社区组件。想要达到图3这张图的效果,就需要图4这一堆组件,这就涉及到上面提到过的问题。所以就衍生出了一个 SaaS化 的数据链路的方案。
Saas化的数据链路方案
CKafka 连接器是腾讯云上 SaaS 化的数据接入和处理解决方案,一站式提供对数据的接入、处理和分发功能。
提供基于 HTTP/TCP 协议的 SDK 协助客户完成数据上报;基于 CDC 机制订阅、存储多款数据库变更信息;简单可配置的数据清洗 (ETL) 能力;丰富的数据分发渠道;打通了混合云/跨云的丰富的数据源(MQ, 数据库,事件等)数据接入。
协助客户低成本搭建数据流转链路,构建数据源和数据处理系统间的桥梁。
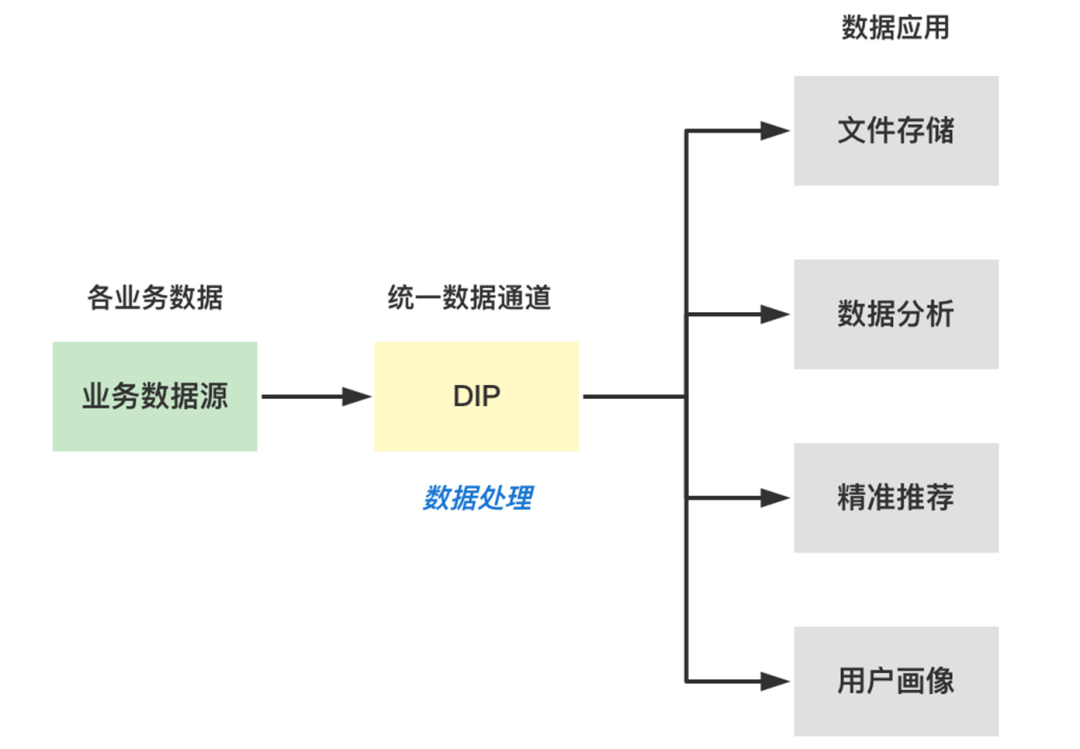
应用场景
数据链路构建
在正常业务当中,用户需要将多种数据源的数据经过客户单采集,实时处理缓冲,传到下游的搜索,这时就可以通过这套链路直接把数据一条链路完全打通,直接把数据源打到下游的存储,这就非常便利了。
在实际业务过程中,用户经常需要将多个数据源的数据汇总到消息队列中,比如业务客户端数据、业务 DB 数据、业务的运行日志数据汇总到消息队列中进行分析处理。正常情况下,需要先将这些数据进行清洗格式化后,再做统一的转储、分析或处理。
CKafka 连接器支持将不同环境(腾讯公有云、用户自建 IDC、跨云、混合云等)的不同数据源(数据库、中间件、日志、应用系统等)的数据集成到公有云的消息队列服务中,以便进行数据的处理和分发。提供了数据聚合、存储、处理、转储的能力,即 数据集成 的能力,将不同的数据源连接到下游的数据目标中。
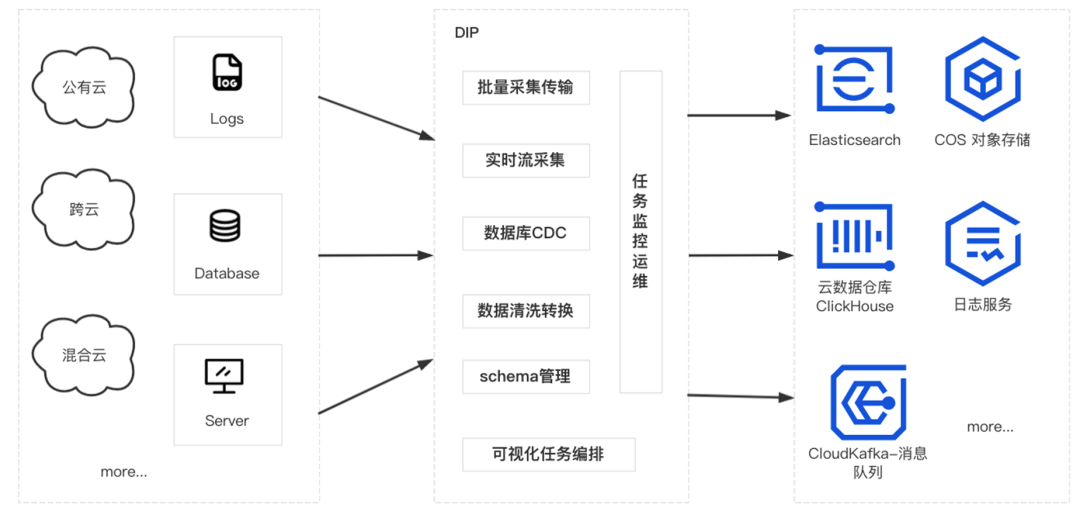
数据接入分发
另外三个场景分别是数据上报、数据库订阅和数据的清理和分发。
客户、业务端或者运维端可能有很多数据需要上报,需要自己搭建一个上报的 Server,但如果使用 Sass 化数据接入产品,它就可以很轻量化的完成数据上报。
数据库订阅和数据的清理分发等功能是一样的原理,需要做的就是把数据从各种数据源很 Saas 化的接进来,然后简单轻量的清洗出去。
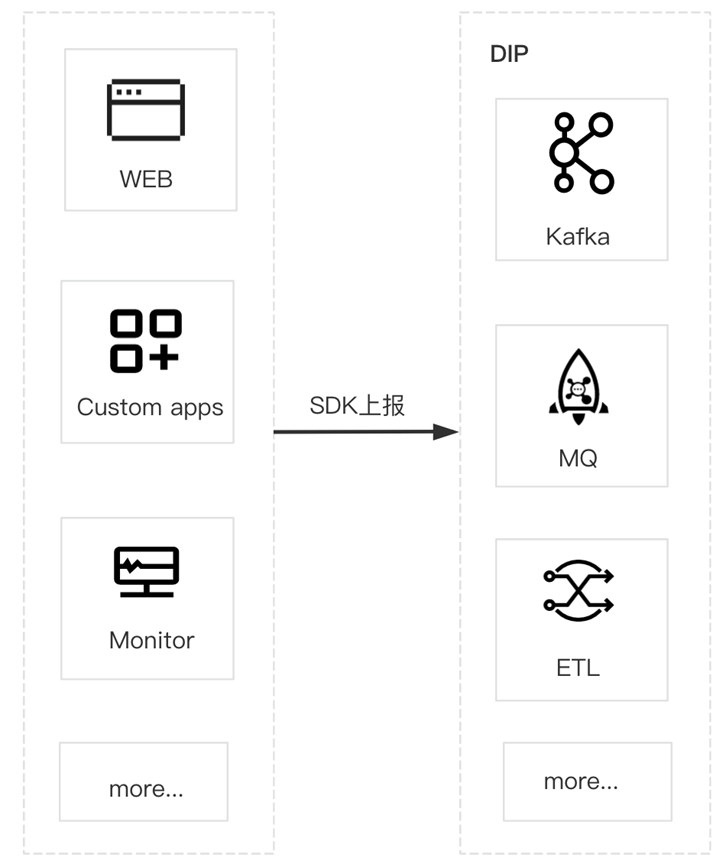
数据上报
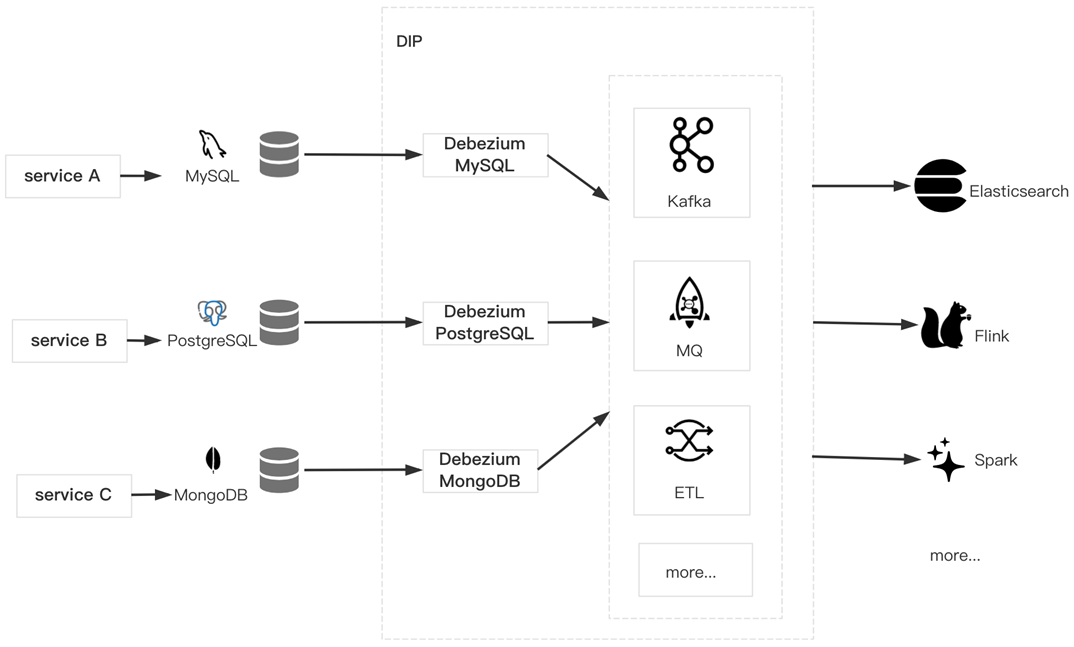
数据库数据订阅

数据库清洗和分发
接下来分享如何从技术上实现轻量级 Saas 化数据链路搭建,会遇到什么问题,业界有什么通用的做法。
技术架构体系的建设
系统架构
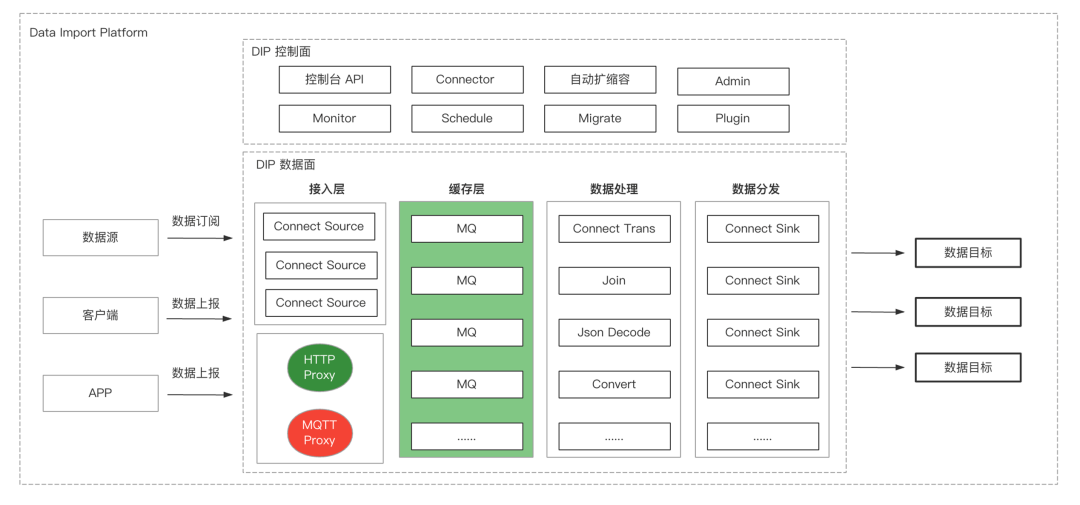
从上图可知,数据链路整体分为4个层面:接入层、缓冲层、数据处理层和数据分发层。
从左到右,在数据面可以看到数据源、客户端、APP,会通过订阅、上报等接口把数据上报到接入层里面;然后接入层会把数据缓冲到缓冲层,缓冲层一般是 MQ,比如 Kafka、Pulsar 等消息队列产品;接着在数据处理层,会处理消费缓存层的数据,把数据经过简单的 ETL 重组、重装、裁剪等等分发到下游的各种数据目标。
控制面会提供一些 API 控制调度监控、扩缩容、管理、运维、迁移等等这些管控面的能力,这时会提供 API 给大家调用,这就是控制面和数据面的大体架构。如果自己去搭建这么一套数据链路的产品也是需要这么多的工作的。
界面化的ETL引擎
在数据处理层一般是通过编码,比如 Logstash 的语法,或者 Python 和 Flink 的 代码,或者 ETL 函数的语法等处理方式。但对用户来说,他可能不需要这么多的功能,也不想投入这么多的学习成本,用户就可以使用 CKafka 连接器,在通过 CKafka 连接器组件处理数据流入流出任务时,通常需要对数据进行简单的清洗操作,比如格式化原始数据,格式化解析特定字段,数据格式转换等。开发者往往需要自己搭建一套数据清洗的服务(ETL)。
如下图所示,从数据进来以后会经过多层的转换存在缓冲层然后再消费到下游,这是数据处理一个体系化的链路图。我们可以提供一个完全界面化的处理引擎来支持 JSON 的简易操作、JSON 的格式化解析、数据的裁剪替换等通用的 ETL 的行为。这个界面化的 ETL 引擎底层是基于 Transform 接口、Interface 等机制来实现的。

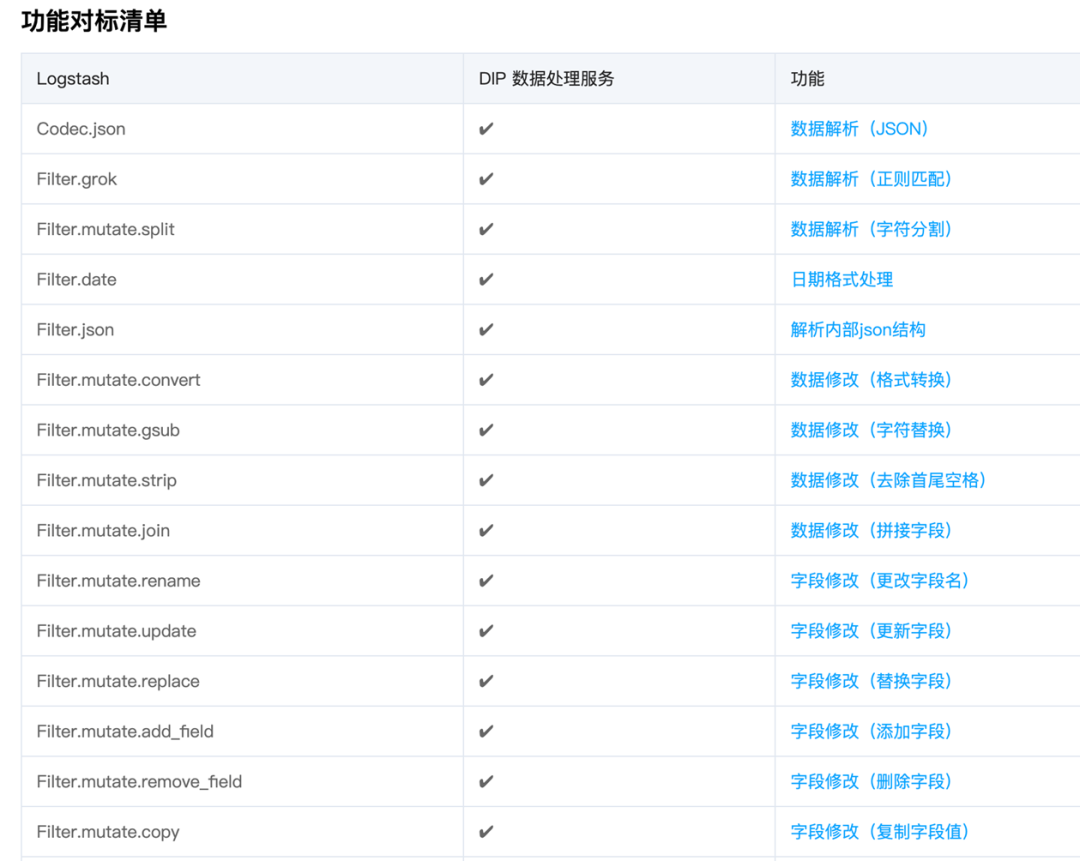
多引擎架构 — Kafka Connector
怎么样来解决整个数据流的连接和接入呢?从研发层面来讲,从进程或者线程的层面,从数据研发数据写到缓冲层再打到下游,整个不同任务的维度是需要调度的,当前的业界没有一种通用的引擎去解决所有问题,所以CKafka连接器方案底层实现的是多引擎的一套架构,那相当于有多套引擎同时并行的提供服务、调度、分布式的迁移和启动、停止、变更等行为。
首先来看引擎1:Kafka Connector,它是 Kafka 社区提供的一款计算调度的产品。这款产品主要解决的问题就是它提供了一个分布式的任务调度的框架,会同时开放出很多 Interface 的接口,会从数据源提供很多插件,比如 JDBC、Syslog、MQTT、MongoDB 等,这些插件会把数据从源端不断的拉到Kafka里面来,然后在下游再对接 HBRSE、S3、Elastic、Cassandra 等一些 Sink 的服务。Kafka Connector 分为两个层面,一个是调度层面,调度层面就整个框架,会提供分布式的部署,分布式的容灾。另一个是跨可用区的部署、跨可用区容灾等,提供各种不同的插件,Source、Sink 等,形成一套数据流。Kafka 引擎一个打通一个引擎,如果开发者自建,可以自己去搭建的,这时候更多要关注稳定性、扩缩容,以及内核问题的及时修复等。
多引擎架构 – Flink Connector
接着看引擎2:Flink Connector,Flink 大家都用的非常熟,其实 Flink Connector 也非常强大,它会提供很多计算框架,其实跟 Kafka Connector 类似,它也提供了很多分布式计算层的服务,也提供了很多Connector和 Extract 函数、UTF 等操作,它的 Connector 会对接各种数据源,也会对接各种 ES,它在数据源会定个数据库的 CDC,更多的是服务类的,比如数据源是 Kafka、DFS、Cassandra 等,这时它会通过内部的分布式调度和处理把数据源打到下游的 ES,这里是一个 Load 的过程,里面有很多算子等的概念。如果用户想要自己去搭建的话是比较复杂的。多引擎架构是为了解决两款技术体系 Flink 和 Connector 具有的不足之处,将两款技术体系融合在一起,进行不同的调度和迁移。从数据源来看,它执行的就是为不同的数据源拿数据,没有缓冲层,直接到下游的 ES,区别在于,如果你需要存或者不需要存,任务的数据量、并行度这些都是我们控制的。
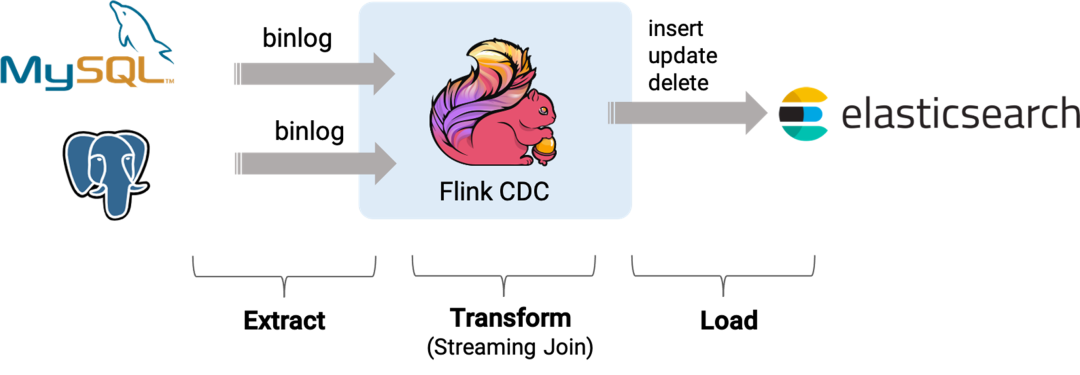
多引擎架构 – MQTT 协议接入
接下来看引擎3:MQTT 协议接入,MQTT 协议是指数据接入平台会提供整个 MQTT 的软件层,各种 Connector端会连接到 MQTT 的整个 Proxy 层,它会提供 MQTT 3、MQTT 5的一流量控制、语音版消息服务等一个体系,也会支持 QS 1、QS 2等,也支持通过 MQTT 把消息打到下游的 Bridge 这些数据桥阶层,转发到 Kafka 或者其他 MQ。
多引擎架构 – HTTP 协议接入
最后看多引擎架构4:支持 HTTP 协议接入,数据能够通过 HTTP 协议从数据源导进来。
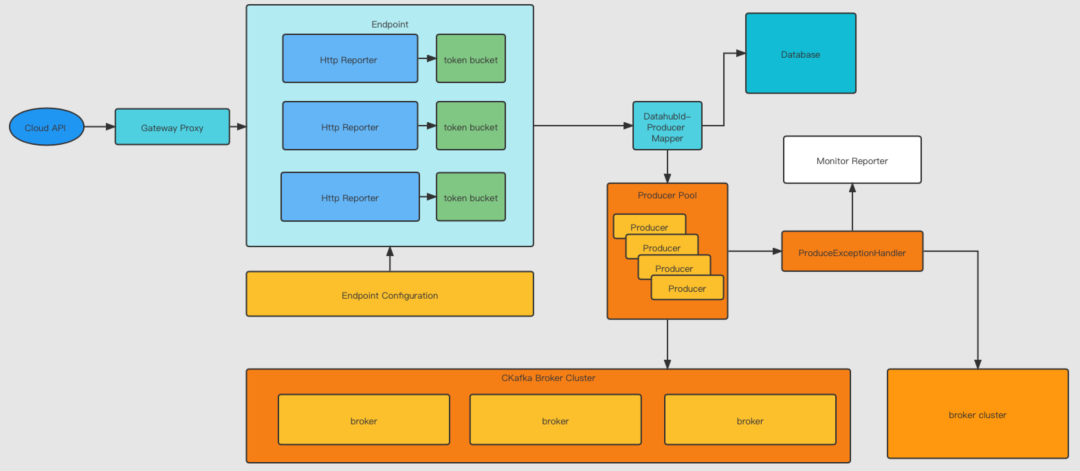
如下图所示,看一下 HTTP 协议的架构,第一层是网关,它有各种 Report,通过接收数据在内部维护 API 连接池,把数据分发到Database、Monitor、Report 等,最终是把数据存到各种 MQ 里面。
从总体来看,CKafka 连接器会提供多种数据流的引擎,Kafka Connector、Flink Connector等,这些对用户都完全屏蔽了,用户用到的只是一个 Saas 化的轻量级组件方案,还可以提供 MQTT 协议和 HTTP 协议,用户可以直接接入,接入后用户就可以非常轻量的解决问题。
客户实践
场景1 – 数据入湖
数据入湖的概念现在非常火,就是把屏蔽底层的各种 HDFS、COS 等持久存储的数据或者异构的数据进行统一查询分析。
客户业务数大部分都存在 MongoDB 里面。有一部分客户行为数据,需要上报后进行分析。客户希望将这些数据统一到数据湖(iceberg)进行分析。
自建链路遇到的问题,链路太长,涉及的组件非常多。大多数组件是分布式部署,扩缩容复杂,维护链路的稳定性,透明监控需要花费大量精力。使用连接器组件后,只需要简单配置,SAAS 化,链路的稳定性,扩缩容依托平台处理。
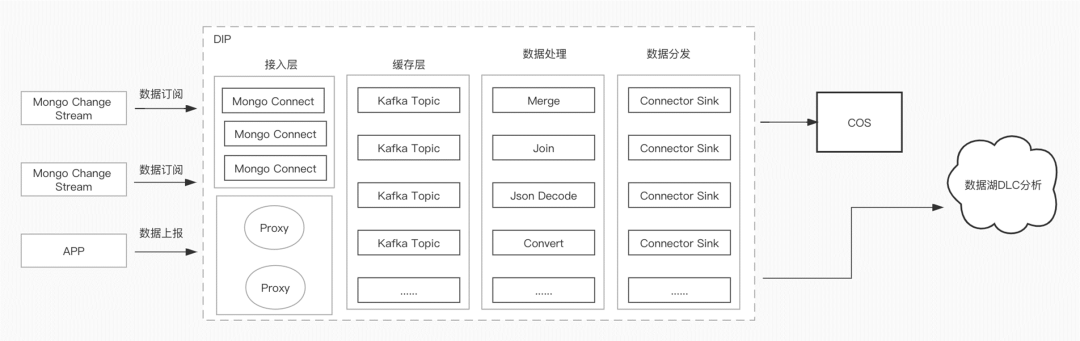
看下面的架构图,有 Mongo 的数据源,在接入层通过 Mongo 的 Connector 去 Mongo 里拿数据,订阅 MongoStream 的数据,需要先把数据存到 Kafka 的 Topic 里,因为原始订阅数据是有 Schema 规范的,这时在 Iceberg 里,是一个存储一个解析的层,所以需要简单的处理,通过Kafka Connector 的 Sink 把数据存到 DLC 里面去。
场景2 – 数据上报和多协议接入
1
数据接入
某教育客户需要将直播课学生上下课、签到、浏览等一些行为信息上传到后台进行分析、处理和检索。数据在后台主要有两种业务逻辑:
自定义代码拿到上报数据,进行对应业务逻辑处理;
原始数据进入 Elasticsearch 进行检索分析。
因开发人力有限,希望有一种方便的数据接入服务,简单快速地完成数据的上报、存储。
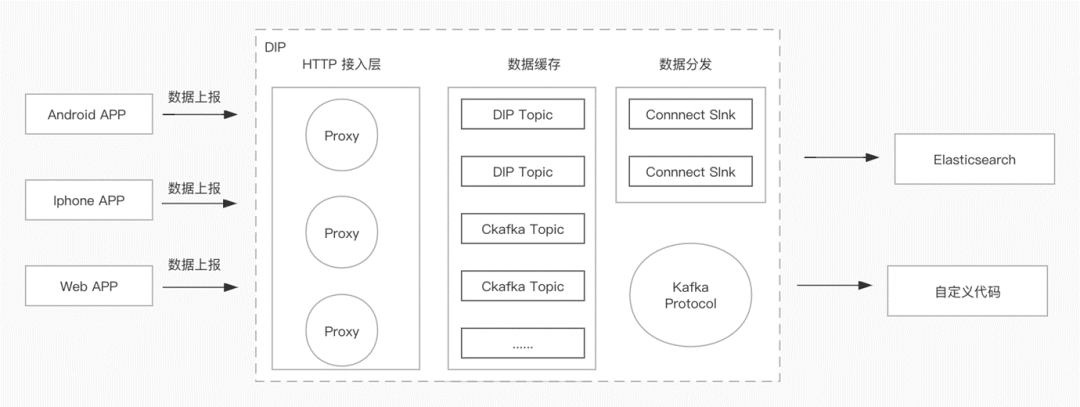
这个客户的数据源是各种客户端,通过数据上报接入到 HTTP 接入层中,然后通过连接器存储,数据分发到ES,然后客户自己的代码去消费。
2
多协议接入
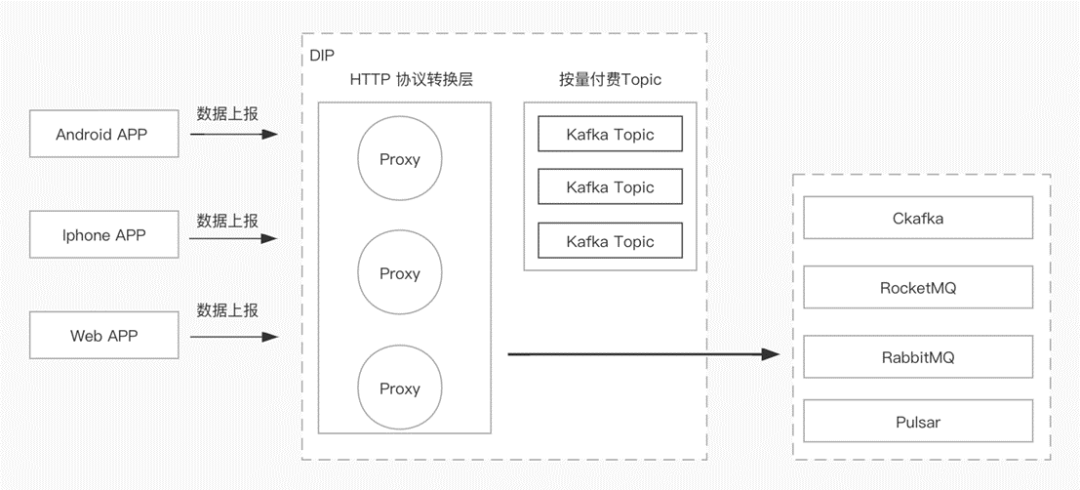
某保险客户的中台团队迁移上云,因下游团队众多,使用多款 MQ 产品(Kafka,RocketMQ,RabbitMQ)。各个 MQ 都是 TCP 协议接入,有各自的 SDK。SDK 学习、使用、以及后续切换成本较高。
基于中台考虑,希望上云后能够通过简单的 HTTP 协议进行接入,屏蔽底层的具体引擎细节。
有三个要求:
简化客户端的使用,最好是HTTP协议。
底层MQ引擎切换对业务无感知。
最好有现成的支持HTTP协议的SDK。
使用连接器组件就解决了非常实际的上报、订阅和分发的场景。
场景3 – 数据库订阅
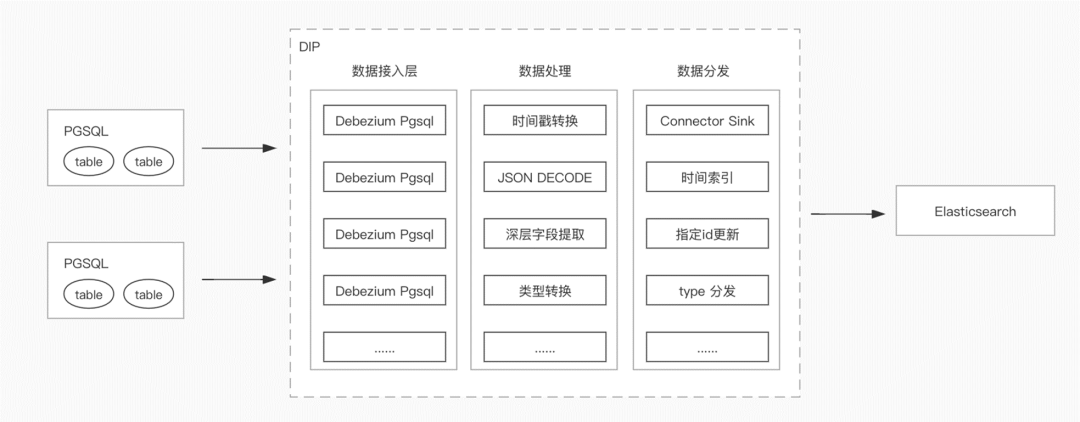
某迅销平台内部多有多套系统并行运行,某套系统存储引擎为 PGSQL。需要将 PGSQL 的变更数据存量导入到 Elasticsearch 里面进行查询。有如下几个需求:
数据写入 ES 的时候需要根据时间分索引;
因为某个数据量大,希望在某个时间区间内只保留某个唯一 ID 标识的最新数据(update);
需要根据不同的表将数据分发到不同的索引里面。
自建的架构:
PGSQL + DebeziumPGSQL+KafkaConnector+Kafka+Logstash+ Elasticsearch
CKafka连接器架构:
PGSQL + 连接器 + Elasticsearch
从上面的架构可以看的出来,使用连接器方案可以将数据链路中的很多细节直接屏蔽,直接打到下游,非常轻量化。
往期
推荐
《Apache Pulsar 技术系列 – 基于不同部署策略和配置策略的容灾保障》
《微服务架构下路由、多活、灰度、限流的探索与挑战》
《TSF微服务治理实战系列(四)——服务安全》
《高并发场景下如何保证系统稳定性》
《微服务上云快速入门指引》
《Apache Pulsar 在微信大流量实时推荐场景下的实践》
《好未来基于北极星的注册中心最佳实践》
《百万级 Topic,Apache Pulsar 在腾讯云的稳定性优化实践》
《预告|ArchSummit 全球架构师峰会杭州站即将盛大开幕》
《千亿级、大规模:腾讯超大 Apache Pulsar 集群性能调优实践》
《云原生时代的Java应用优化实践》
《SpringBoot应用优雅接入北极星PolarisMesh》

扫描下方二维码关注本公众号,
了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!


点个在看你最好看