
全球存储观察|DNA存储发展简史(技术风云录)


每一次技术创新
都需要第一个吃螃蟹的人
坚持再坚持坚持十年二十年冷板凳
甚至三十年,或更久……
我们看看DNA存储发展的历史
或许很惊讶
但或许会看到新的希望
【全球存储观察 | 科技热点关注】
我非常好奇|为何法国人对DNA存储有着浓厚兴趣?
据外媒消息称,法国初创公司Biomemory推出了商业化的DNA存储产品,1KB存储空间需要1000美元。这种DNA卡比标准硬盘贵了了不知道多少倍。1TB硬盘市场零售价也就几百元人民币,几十美元而已。
预计到2030年Biomemory将实现EB级的DNA存储“阵列”。
畅想未来,碳基和硅基将在数据存储领域并驾齐驱了么?
来仔细看看这个DNA存储的消息,如下:

当然,DNA存储由于其高存储密度与低能耗处理等特点,被视为一种极具潜力的存储技术,成为应对数据存储增长挑战的新机遇。只是价格目前不容易普惠,DNA存储的读写成本都不低。
所以,我们可以看到目前全球第一款DNA存储商业化产品售价1Kb就要1000美元,约合人民币8000多元。所以DNA存储绝对昂贵,所以也绝对冷门。你看全球存储界扛把子Dell EMC都从来木有碰过,全球愿意坐冷板凳善于基础研究的IBM也么有碰过,其中的难,是真的难。
尽管如此贵,但法国这家初创公司创始人依然非常憧憬未来。现在1KB要1000美元,2026年100PB,需要花150000美元,2030年1000PB+……业内人士对此评论到,会不会希望越大失望越大。
但是技术进步,确实需要令人难以置信的坚持,真正的创新才会最终出现。
为此,Biomemory在DNA数据存储方面不断取得重大进展。对外透露消息说已经开始建造专为数据中心中的合成DNA数据存储而设计的机器,第一个模型能够自主操作,将于2026年首次亮相。更先进的版本预计在2030年将超过EB级存储。
最近,Biomemory推出了一款B2C产品,以展示其技术的能力和商业准备。这一初始产品不仅证明了Biomemory的技术成熟度,而且还作为探索各种用例的桥梁。
当前,Biomemory实验室规模扩大了两倍,吸引了新的人才,并在行业内建立了战略合作伙伴关系。
随着Biomemory的首款产品DNA卡投放市场,证实了一个事实就是DNA数据存储本身正在迅速发展。
那对于DNA存储的发展,你以为如何呢?
再看看国内DNA存储的发展消息,在2022年左右,天津大学元英进院士带领的合成生物学科研团队创新DNA存储算法,将十幅敦煌壁画存入DNA中,通过实验验证壁画信息在实验室常温下可保存千年。这一算法支持DNA分子成为世界上最可靠的数据存储介质之一,可以让面临老化破损危机的人类文化遗产信息保存千年万年。只是在实验室中实现,并未做产品商业化准备。
从实验室到商业化产品,这之间的距离,做产品的人应该都深有体会。还有很长一段路要走吧。
进一步分析来看,有朋友非常断定地说:存储作为需求会永远存在,但是,这种需求的载体会不断变化。
不过呀,更有兴趣的朋友,不妨可以继续读读下面有关DNA存储发展历史的三篇“老掉牙”文章。
▼ ▼ ▼
技术风云录|基于DNA的存储系统距离我们还有多远?
阿明 全球存储观察 2016-04-30

存储技术的发展,以存储介质的发展所驱动着,年复一年,再年复一年。EMBL-EBI成员、哈佛医学院教授、著名遗传学家George Church的团队一篇有关DNA存储信息的论文,带给了人类新的希望。
从磁带、光盘、磁盘和闪存,每一种存储介质的出现都对存储技术有着划时代的意义,那么近年大家十分关注基于DNA的存储到底距离我们还有多远呢?
首先我们先来摸清楚
DNA存储的定义和概念
DNA存储的原理是为核酸中的碱基赋予二进制值,随后通过微流体芯片对基因序列合成,从而使该序列与相关数据集相匹配。1立方毫米即可存储704TB的数据,相当于数百个硬盘的容量。
DNA存储方式是采用DNA双螺旋结构上有4个核碱基,开发定制代码,DNA数字存储系统首先把硬盘信息中的二进制数翻译成定制代码,然后借助标准DNA合成机器制造出相应的碱基序列。
这一序列并非一个长分子,而是多个重复片段,每一个片段携带一些索引细节,明确各自在整体序列中所处位置。分子生物学实验室用来读取生物体DNA的标准设备可以读取信息,当即呈现在电脑屏幕上。
可见,DNA存储技术的与传统的存储技术不同,传统的电子存储是基于0、1这两个符号的组合,而DNA有A、T、C、G4个碱基,在编码上就比传统的二进制存储多了许多可能。
再看看DNA存储发展历史
实际上,DNA存储与计算的研究已经持续了近30年,来自《数据存储的未来:把宇宙写进DNA里》文章介绍说,早在1986年,麻省理工学院一位被称为科学狂人的科学家Joe Davis就成功将5×7像素的图片编码到DNA中。
1994年 ,美国南加州大学教授雷纳德·阿德勒曼(L.Adleman)博士在《科学》杂志上发表一篇题为《组合问题的生物电脑解决方案》的论文,首次提出分子计算机,即用DNA分子构建电脑的设想。阿德勒曼指出,DNA电脑将采用其本身的“语言”,以四进制系统来编码,与“人工生命”的研究范畴将融合在一起。今后的工程技术人员应该接受更加广泛的科学教育,使自己成为“通才”,全面掌握数学、物理、化学、生物学和计算机科学知识,才能做出更多的发明和创新。
2001年 ,以色列科学家成功研制成世界第一台DNA计算机,它的输出、输入和软硬件全由在活性有机体中储存和处理编码信息的DNA分子组成。虽然该计算机不过一滴水大小,但这已显示出未来DNA计算机的雏形。吉尼斯世界纪录称之为“最小的生物计算设备”。随后几年,以色列科学家对DNA计算机进行了改进,当时的运行速度已高达每秒330万亿次。
2004年 ,来自《南方周末》徐彬的文章报道说,中国上海交大Bio-X生命科学研究中心冯国鄞称已在试管中完成了DNA计算机的雏形研制工作,论文发表在中国《科学通报》49卷第1期英文版上。
2007年 ,日本科学家成功使用细菌DNA储存数据。
2011年 6月,深圳特区报报道称,新加坡南洋理工大学舒建军教授在《物理评论快报》(Physical Review Letters )发表了他的最新研究成果,称他的团队提出了一种通过操纵DNA链能解决基于DNA计算的战略分配问题。在实验模型中,DNA分子用来存储与计算目的相关的信息。当前使用的计算机芯片都是硅计算依靠二进制,即1和0。而通过DNA计算,除了1和0以外,你还可以做的更多。DNA由AGTC四种碱基组成,这可以形成更多的排列。DNA计算将有潜力处理模糊数据,超越数位数据。
2012年 ,台湾国立清华大学和德国一研究所合作,用三文鱼的DNA制造出单次写入、多次读取的存储器。
但是,取得阶段性实质进展的,却是来自英国的一个EMBL-EBI的科学家团队。欧洲生物信息研究所(EMBL-EBI)全称EMBL - European Bioinformatics Institute,是一个非盈利性的学术机构,致力于以信息学手段解答生命科学问题。EMBL-EBI建立于1994年,位于英国剑桥南部的维康信托基因园,是欧洲分子生物学实验室(EMBL,全称EuropeanMolecular Biology Laboratory)的一部分。

2012年9月 ,欧洲生物信息研究所Ewan Birney和哈佛医学院教授、著名遗传学家George Church的团队在Science杂志上发表《Towards practical, high-capacity, low-maintenance information storage in synthesized DNA》即《迈向实用高效能低保养的合成DNA存储信息》文章表示,他们将一本5.34万字的书籍、11张图片和一段Java程序存进了不到一沙克(亿万分之一克)DNA中!有人根据这个比例换算得出,1克DNA将能存储700TB数据,相当于1.4万张蓝光光盘,或233个3TB的硬盘。而George Church教授则表示:“今后,拇指大小的设备或许就能存下整个互联网的信息。”
从EBI官方网站上可以查询到,George Church也是EMBL-EBI的一员,并且还有联系电话。
同样在2013年,阿根廷科学家近日成功将该国国歌旋律以人工基因编码形式植入某种细菌染色体中。
那么,按照George Church的做法,将二进制信息翻译成某个中间代码,再通过微流体芯片对基因序列进行合成,从而使该序列的位置与相关数据集相匹配,方便读取。
George Church基于DNA存储
到底如何实现呢?
来自东方早报的《存储数码信息的DNA》的文章给予了详细介绍,这里摘录如下:
首先, 把电子文件的二进制码(0,1)翻译成三进制码(0,1,2);然后,用由DNA四个碱基(分别以它们的学名首字母A、T、C、G代表)构成的一套特定编码和规则,将二进制码编译成一个DNA码序列。接着,以每25个碱基向后错位的方式,把这个DNA序列切割成若干个含100个碱基的等长片段,直至整个序列的所有内容都获得四个副本(例如:1,2,3,4;2,3,4,1;3,4,1,2;4,1,2,3)。这样一来,当任何一个副本出错时,有另外三个副本可供参考认证,可谓万无一失。为了确定这些等长片段在这个DNA序列中的准确位置,George Church团队给它们各自的首尾加上了索引标识。
用DNA编码编好电子文件后,再用专门设备做DNA合成,信息写录就完成了。取用合成DNA中的信息时,先把合成DNA放入标准化学试剂,然后用DNA测序仪,根据索引标识,将各个片段依序粘接成原DNA码序列,再译回二进制码,形成电子文件,就大功告成了。George Church团队十分谨慎,在编码设计中不惜繁琐,引入多重防错检错机制,为的是保证编辑和解读复原达到零误差。
编码设计好之后 ,George Church团队用了五个不同类型的电子文件做测试:
一段26秒钟长的马丁·路德·金《我有一个梦想》演讲录音;
一篇关于DNA结构的经典学术论文的PDF文件;
莎士比亚十四行诗全篇,一张EBI大楼的彩色照片;
以及一段这次试验使用的软件算法(Huffman编码)。信息总量不大,约739千字节,着重检验编码对不同信息形式、内容以及格式的适用能力。
DNA的存储能力的确惊人,当装着这五个文件的合成DNA的试管送到George Church手中,他看了半天,竟然什么也没找到。还是经同事指点,才发现试管底部那颗灰尘般大小的DNA。
然后, George Church团队用DNA测序仪,把合成DNA中的信息复原为电子文件。结果令人振奋:它与原始电子文件的重合率为100%。不过这100%跟着一段有惊无险的小插曲。在DNA测序时,PDF文件中的两个25碱基小节不见了。
缺了它们,就会出现误差,这是绝对不能容忍的。好在编码为每个小节提供了四个副本,根据副本,编码准确地完成了复原任务。这次歪打正着,证明了该编码防错的优越性能。
还好,George Church团队很快找到了丢失的原因,George Church博士保证,只需稍微修改一下程序,类似问题以后不会再发生了。
George Church团队的论文精华解读
《Towards practical, high-capacity, low-maintenance information storage in synthesized DNA》 的论文中有两个图可以值得研究一下。
一是DNA的数字信息编码图。
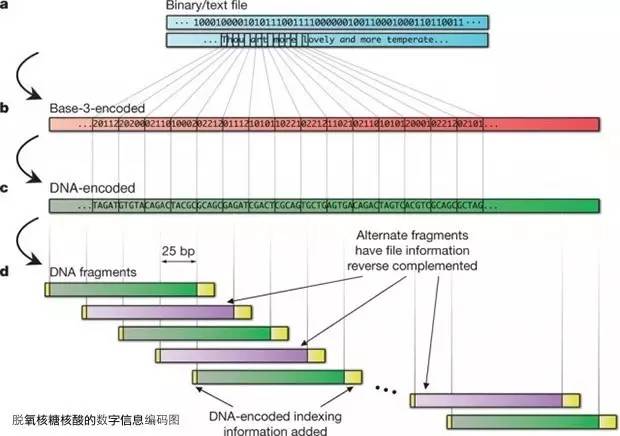
数字信息(a,蓝色)部分,这里的三进制数字的ASCII码是莎士比亚十四行诗第18,采用Huffman编码,转化为(b,红色)用五或六base-3编码代替每个字节。这也是DNA编码的转换在硅片(c,绿色),由不同于之前使用过的三个核苷酸来替换,并确保没有homopolymers同聚物生成。在此基础上形成的大量的副本,产生四倍冗余(d,绿色,采用紫色的备用段反向补充增强数据安全性)。增加了索引DNA编码(黄)的索引基因,也被编码为不重复的DNA核苷酸。
二是,基于DNA的存储的稳定性和Scaling特性描述图
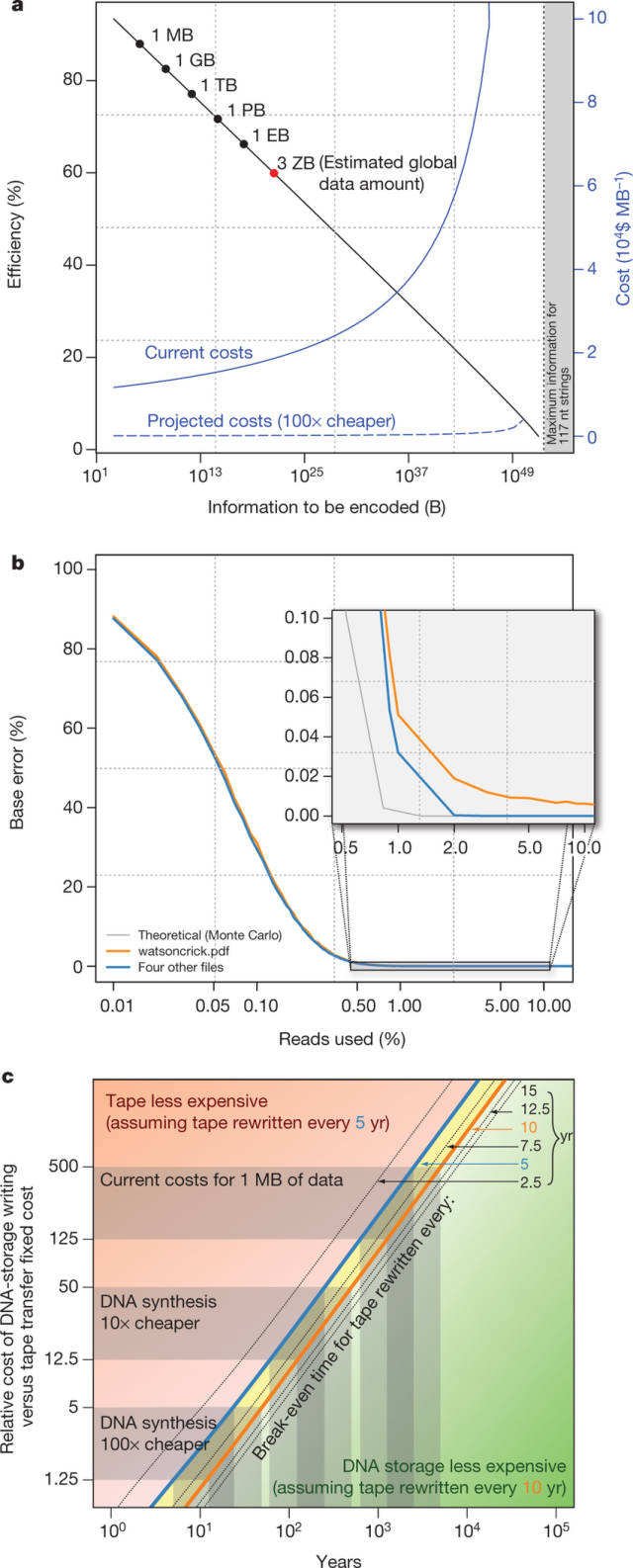
从这个图可以看出,图a表示编码效率情况,即针对存储信息量增加时编码效率和成本变化。×轴表示被编码的信息总数。标注了常见的数据字节容量:
1MB\1GB\1TB\1PB\1EB\3ZB(2014年估计全球数据信息量)……。
黑色Y轴表示的编码效率,测定合成碱可用于数据编码的比例。蓝色的曲线(Y轴从左向右)在当前的综合成本水平上,指出了相应的编码成本的影响。
图b 表示误差率情况,(Y轴)为每个恢复基的误差率,作为测序覆盖的函数。蓝色曲线代表四个文件恢复,无需人工干预:当原始读取率≥2%时使用误差为零。从我们的理论误差率模型的Monte Carlo模拟得到的灰色曲线。橙色曲线代表watsoncrick.pdf文件,需要人工校正:最小可能的误差率为0.0036%。那个盒子所在的区域显示嵌入放大。
图c 表示基于DNA的存储成本的时间表。当每10年数据发生改变,DNA存储的成本效益不错;当每5-10年数据发生改变,DNA存储的成本效益表现才稍差一点;如果每5年甚至更频繁的数据改变,磁带的成本效益还是更佳一下。当然了,有人也提到,倘若存储500年的数据来计算的话,DNA成本效益就更明显表现出来了。
George Church的论文指出,DNA作为存储介质,也有显著的弱点。 一是成本过高。
George Church团队的实验费用高得惊人:每一兆(MB,10的6次方)字节的存储费用是12,400美元,外加测序解读220美元。这是常规磁带存写费用的一百万倍还多。所以,DNA存储必须大大降低成本,才谈得上实际应用。二是信息写读耗时。数码信息编入DNA目前只能由专门的DNA合成设备来做;而从DNA中取读信息,重组复原为数码文件,也很费时。George Church团队用了整整两个星期,才完成五个文件739千字节的复原。三是DNA介质不能重复使用,写录完毕,一般来说不能修改,不能再用。
DNA存储并非可以替代目前所有的磁带存储、光盘存储、磁盘存储或闪存存储,而是为大家提供了一个针对用户大规模的、长期和不经常访问的数字归档的现实技术方向。比如存储期五十年以上,且无需多次存取的信息,DNA介质就很有竞争力了。同时,“未来的DNA计算机在研究逻辑、破译密码、生物医药以及航空航天等领域应用将发挥其独特优势。”那么在DNA存储和DNA计算两个领域交叉发展推进进步的情况下,DNA在存储与计算领域的应用相信在不久的将来会来到我们身边。(阿明整理编辑)
▼ ▼ ▼
太扯了啊!用DNA分子存储数据可保存长达百万年!
全球存储观察 2015-08-19
Dostorage8月19日转发消息:据《独立报》报道,ETH Z rich瑞士联邦技术研究所的科学团队提出了使用DNA分子来存储信息的方法,并提出了一个数学算法可以解码DNA分子上的编码信息。
当该技术成熟应 用后,大概一枚便士硬币的28克(1盎司)左右的DNA分子,能够存储30万TB的信息数据,并且保存长达至少100万年。而目前的存储介质最高保存期限大概为50年左右。
科研团队的Robert Grass博士“随着DNA分子的双螺旋结构的发现,人们发现DNA中的信息编码类似于计算机中采用的二进制编码,二进制编码由0和1组成,而DNA中的信息则由A、C、T、G4种核苷酸排列组成。”
科学家使用了一种机器合成包含数据信息的DNA分子,并将它们加热至71 ,结果这些信息可以保存一周。这等同于在50 的环境下保存信息2000年。
目前商业化该方法还具有较大的难度,因为尚没有经济实惠的方式来生产这种DNA,另外能够读取DNA信息的驱动器显然也不经济。
而且目前科学家能够读取DNA分子中的整块信息,但不能指向特定的DNA信息片段的数据块,相当于能够读取一个全文件,但无法定位读取指定片段,这些都是目前面临的问题。
▼ ▼ ▼
牛逼的DNA硬盘能够让存储技术飞跃100年吗?
全球存储观察 2015-07-24
Dostorage7月24日转载消息:50年前,在仙童半导体公司任职的摩尔提出了著名的“摩尔定律”,指引了21世纪的一场伟大科技革命。
在这50年间,人类获取、处理信息的能力,遵循着摩尔定律冲破天际,但随之而来的一个问题也摆在了人类面前:这么多信息,我们该如何进行存储?

事实上,这个问题自现代计算机诞生以来便如鲠在喉。如今的教科书,更愿意把相关的解决方法统称为“存储技术”。
在计算技术腾飞的这几十年,存储技术一直是一个疲惫的追赶者——其首要原因便是物理限制。与中央处理器(CPU)的硅片介质不同,现代的数据存储一般以磁介质为核心。
顾名思义,就是要通过磁介质磁场行为的“记忆效应”来实现数据存储的功能。这种存储模式无论在尺寸上(数据密度)还是在使用寿命上(保存时间)都大打折扣。
我们现如今使用的机械硬盘、固态硬盘、USB闪存等,其预期寿命都在十年左右,而且个头还不小,一旦数据丢失,造成的损失便无法弥补,维护的成本自然也相当高昂。
近年来,一些存储技术专家把目光投向了仿生学。他们论证道:生命是如此精细和复杂,为了能够无误地繁衍遗传,哪怕是一条蚯蚓,它所携带的信息也足以写满一屋子硬盘。蚯蚓的小身躯到底如何存储这些数据呢?答案便是DNA(脱氧核糖核酸)。
DNA是遗传和基因编码的基本结构,其功能主要是半保留复制(延续生命)以及转录核糖核酸从而合成蛋白质(实现生命功能)。
相比较磁介质存储的“傻大憨粗寿命不长”,DNA存储信息的能力极强——一汤匙DNA所携带的信息,可以存储自人类文明出现以来所有的书籍影音;且由于它特殊的双螺旋紧密结构,物理化学特性稳定,不易被破坏,低温下可保存千百年不变质。
可见,困扰存储技术多年的问题答案,早就被“造物主”写在了我们每个人的身体里。
DNA由四种含氮碱基——A、T、C和G互补配对构成,科学家将数据编码成二进制的数字串,每遇到一个0,就在目标DNA的尾巴上合成一个A—T碱基对;如果是1,就合成一个C—G碱基对。这样一来,整部莎士比亚全集就可以被存储在头发丝大小的“DNA硬盘”中。
每次写完数据,就把“DNA硬盘”放到低温环境中保存。需要读取数据的时候,只需对目标DNA进行测序,将碱基对还原成二进制编码,再完成解码工作,就可以被人类“阅读”了。
当然,以目前的技术来看,“DNA硬盘”还有很多挑战要突破,比如存储(合成)成本太高、读取(测序)速度较慢。
但是,利用DNA来存储数据的确是存储技术的一个光明的发展方向。
随着仿生学的不断进步,用微如发丝的“DNA硬盘”存储记录人类文明的珍贵信息,将不再是一个久远的梦想。(来源:人民日报)
