
ONNX初探
0x0. 背景
最近看了一些ONNX的资料,一个最大的感受就是这些资料太凌乱了。大多数都是在介绍ONNX模型转换中碰到的坑点以及解决办法。很少有文章可以系统的介绍ONNX的背景,分析ONNX格式,ONNX简化方法等。所以,综合了相当多资料之后我准备写一篇ONNX相关的文章,希望对大家有用。
0x1. 什么是ONNX?
简单描述一下官方介绍,开放神经网络交换(Open Neural Network Exchange)简称ONNX是微软和Facebook提出用来表示深度学习模型的开放格式。所谓开放就是ONNX定义了一组和环境,平台均无关的标准格式,来增强各种AI模型的可交互性。
换句话说,无论你使用何种训练框架训练模型(比如TensorFlow/Pytorch/OneFlow/Paddle),在训练完毕后你都可以将这些框架的模型统一转换为ONNX这种统一的格式进行存储。注意ONNX文件不仅仅存储了神经网络模型的权重,同时也存储了模型的结构信息以及网络中每一层的输入输出和一些其它的辅助信息。我们直接从onnx的官方模型仓库拉一个yolov3-tiny的onnx模型(地址为:https://github.com/onnx/models/tree/master/vision/object_detection_segmentation/tiny-yolov3/model)用Netron可视化一下看看ONNX模型长什么样子。
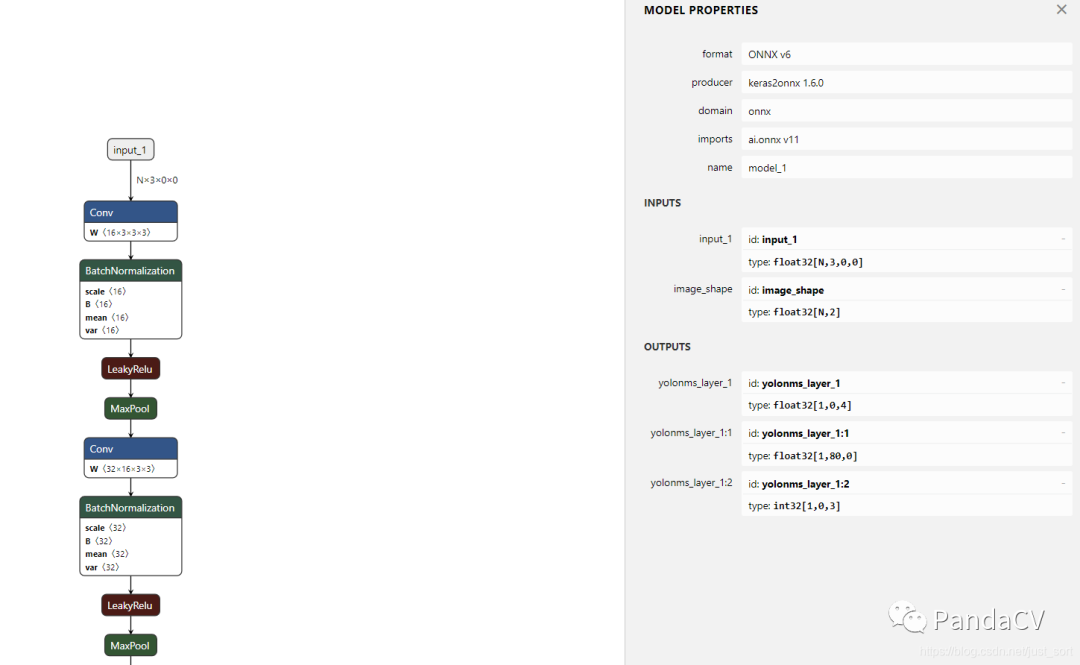
这里我们可以看到ONNX的版本信息,这个ONNX模型是由Keras导出来的,以及模型的输入输出等信息,如果你对模型的输入输出有疑问可以直接看:https://github.com/onnx/models/blob/master/vision/object_detection_segmentation/tiny-yolov3/README.md。
在获得ONNX模型之后,模型部署人员自然就可以将这个模型部署到兼容ONNX的运行环境中去。这里一般还会设计到额外的模型转换工作,典型的比如在Android端利用NCNN部署ONNX格式模型,那么就需要将ONNX利用NCNN的转换工具转换到NCNN所支持的bin和param格式。
但在实际使用ONNX的过程中,大多数人对ONNX了解得并不多,仅仅认为它只是一个完成模型转换和部署工具人而已,我们可以利用它完成模型转换和部署。正是因为对ONNX的不了解,在模型转换过程中出现的各种不兼容或者不支持让很多人浪费了大量时间。这篇文章将从理论和实践2个方面谈一谈ONNX。
0x2. ProtoBuf简介
在分析ONNX组织格式前我们需要了解Protobuf, 如果你比较了解Protobuf可以略过此节。ONNX作为一个文件格式,我们自然需要一定的规则去读取我们想要的信息或者是写入我们需要保存信息。ONNX使用的是Protobuf这个序列化数据结构去存储神经网络的权重信息。熟悉Caffe或者Caffe2的同学应该知道,它们的模型存储数据结构协议也是Protobuf。这个从安装ONNX包的时候也可以看到:

Protobuf是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了 C++、Java、Python 三种语言的 API(摘自官方介绍)。
Protobuf协议是一个以*.proto后缀文件为基础的,这个文件描述了用户自定义的数据结构。如果需要了解更多细节请参考0x7节的资料3,这里只是想表达ONNX是基于Protobuf来做数据存储和传输,那么自然onnx.proto就是ONNX格式文件了,接下来我们就分析一下ONNX格式。
0x3. ONNX格式分析
这一节我们来分析一下ONNX的组织格式,上面提到ONNX中最核心的部分就是onnx.proto(https://github.com/onnx/onnx/blob/master/onnx/onnx.proto)这个文件了,它定义了ONNX这个数据协议的规则和一些其它信息。现在是2021年1月,这个文件有700多行,我们没有必要把这个文件里面的每一行都贴出来,我们只要搞清楚里面的核心部分即可。在这个文件里面以message关键字开头的对象是我们需要关心的。我们列一下最核心的几个对象并解释一下它们之间的关系。
ModelProtoGraphProtoNodeProtoValueInfoProtoTensorProtoAttributeProto
当我们加载了一个ONNX之后,我们获得的就是一个ModelProto,它包含了一些版本信息,生产者信息和一个GraphProto。在GraphProto里面又包含了四个repeated数组,它们分别是node(NodeProto类型),input(ValueInfoProto类型),output(ValueInfoProto类型)和initializer(TensorProto类型),其中node中存放了模型中所有的计算节点,input存放了模型的输入节点,output存放了模型中所有的输出节点,initializer存放了模型的所有权重参数。
我们知道要完整的表达一个神经网络,不仅仅要知道网络的各个节点信息,还要知道它们的拓扑关系。这个拓扑关系在ONNX中是如何表示的呢?ONNX的每个计算节点都会有input和output两个数组,这两个数组是string类型,通过input和output的指向关系,我们就可以利用上述信息快速构建出一个深度学习模型的拓扑图。这里要注意一下,GraphProto中的input数组不仅包含我们一般理解中的图片输入的那个节点,还包含了模型中所有的权重。例如,Conv层里面的W权重实体是保存在initializer中的,那么相应的会有一个同名的输入在input中,其背后的逻辑应该是把权重也看成模型的输入,并通过initializer中的权重实体来对这个输入做初始化,即一个赋值的过程。
最后,每个计算节点中还包含了一个AttributeProto数组,用来描述该节点的属性,比如Conv节点或者说卷积层的属性包含group,pad,strides等等,每一个计算节点的属性,输入输出信息都详细记录在https://github.com/onnx/onnx/blob/master/docs/Operators.md。
0x4. onnx.helper
现在我们知道ONNX是把一个网络的每一层或者说一个算子当成节点node,使用这些Node去构建一个Graph,即一个网络。最后将Graph和其它的生产者信息,版本信息等合并在一起生成一个Model,也即是最终的ONNX模型文件。在构建ONNX模型的时候,https://github.com/onnx/onnx/blob/master/onnx/helper.py这个文件非常重要,我们可以利用它提供的make_node,make_graph,make_tensor等等接口完成一个ONNX模型的构建,一个示例如下:
import onnx
from onnx import helper
from onnx import AttributeProto, TensorProto, GraphProto
# The protobuf definition can be found here:
# https://github.com/onnx/onnx/blob/master/onnx/onnx.proto
# Create one input (ValueInfoProto)
X = helper.make_tensor_value_info('X', TensorProto.FLOAT, [3, 2])
pads = helper.make_tensor_value_info('pads', TensorProto.FLOAT, [1, 4])
value = helper.make_tensor_value_info('value', AttributeProto.FLOAT, [1])
# Create one output (ValueInfoProto)
Y = helper.make_tensor_value_info('Y', TensorProto.FLOAT, [3, 4])
# Create a node (NodeProto) - This is based on Pad-11
node_def = helper.make_node(
'Pad', # node name
['X', 'pads', 'value'], # inputs
['Y'], # outputs
mode='constant', # attributes
)
# Create the graph (GraphProto)
graph_def = helper.make_graph(
[node_def],
'test-model',
[X, pads, value],
[Y],
)
# Create the model (ModelProto)
model_def = helper.make_model(graph_def, producer_name='onnx-example')
print('The model is:\n{}'.format(model_def))
onnx.checker.check_model(model_def)
print('The model is checked!')
这个官方示例为我们演示了如何使用onnx.helper的make_tensor,make_tensor_value_info,make_attribute,make_node,make_graph,make_node等方法来完整构建了一个ONNX模型。需要注意的是在上面的例子中,输入数据是一个一维Tensor,初始维度为[2],这也是为什么经过维度为[1,4]的Pad操作之后获得的输出Tensor维度为[3,4]。另外由于Pad操作是没有带任何权重信息的,所以当你打印ONNX模型时,ModelProto的GraphProto是没有initializer这个属性的。
0x5. onnx-simplifier
原本这里是要总结一些使用ONNX进行模型部署经常碰到一些因为版本兼容性,或者各种框架OP没有对齐等原因导致的各种BUG。但是这样会显得文章很长,所以这里以一个经典的Pytorch转ONNX的reshape问题为例子,来尝试讲解一下大老师的onnx-simplifier是怎么处理的,个人认为这个问题是基于ONNX进行模型部署最经典的问题。希望在解决这个问题的过程中大家能有所收获。
问题发生在当我们想把下面这段代码导出ONNX模型时:
import torch
class JustReshape(torch.nn.Module):
def __init__(self):
super(JustReshape, self).__init__()
def forward(self, x):
return x.view((x.shape[0], x.shape[1], x.shape[3], x.shape[2]))
net = JustReshape()
model_name = 'just_reshape.onnx'
dummy_input = torch.randn(2, 3, 4, 5)
torch.onnx.export(net, dummy_input, model_name, input_names=['input'], output_names=['output'])
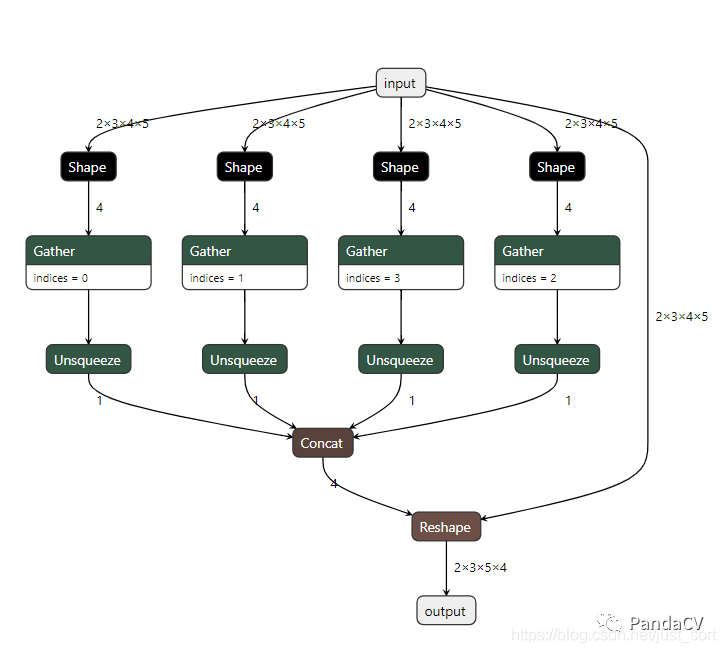
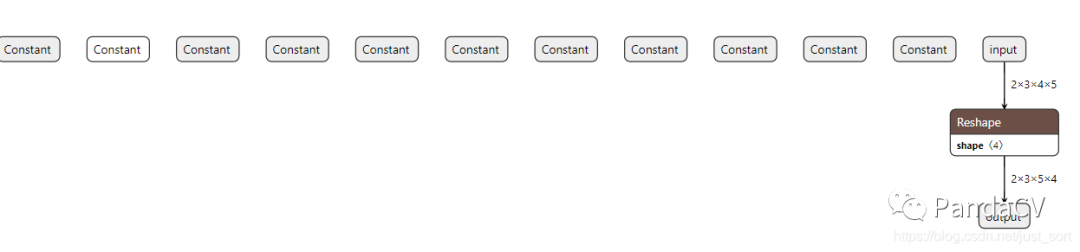
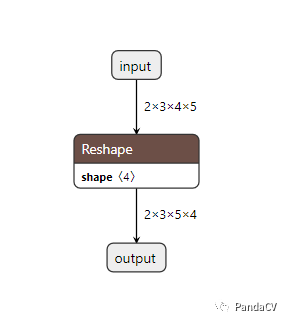
由于这个模型输入维度是固定的,所以我们期望模型是这样的:

但是,即使使用了ONNX的polished工具也只能获得下面的模型:

要解决这个问题,有两种方法,第一种是做一个强制类型转换,将x.shape[0]类似的变量强制转换为常量即int(x.shape[0]),或者使用大老师的onnx-simplifer来解决这一问题。
之前一直好奇onnx-simplifer是怎么做的,最近对ONNX有了一些理解之后也能逐步看懂做法了。我来尝试解释一下。onnx-simplifer的核心思路就是利用onnxruntime推断一遍ONNX的计算图,然后使用常量输出替代冗余的运算OP。主体代码为:
def simplify(model: Union[str, onnx.ModelProto], check_n: int = 0, perform_optimization: bool = True,
skip_fuse_bn: bool = False, input_shapes: Optional[TensorShapes] = None, skipped_optimizers: Optional[Sequence[str]] = None, skip_shape_inference=False) \
-> Tuple[onnx.ModelProto, bool]:
if input_shapes is None:
input_shapes = {}
if type(model) == str:
# 加载ONNX模型
model = onnx.load(model)
# 检查ONNX模型格式是否正确,图结构是否完整,节点是否正确等
onnx.checker.check_model(model)
# 深拷贝一份原始ONNX模型
model_ori = copy.deepcopy(model)
if not skip_shape_inference:
# 获取ONNX模型中特征图的尺寸
model = infer_shapes(model)
input_shapes = check_and_update_input_shapes(model, input_shapes)
if perform_optimization:
model = optimize(model, skip_fuse_bn, skipped_optimizers)
const_nodes = get_constant_nodes(model)
res = forward_for_node_outputs(
model, const_nodes, input_shapes=input_shapes)
const_nodes = clean_constant_nodes(const_nodes, res)
model = eliminate_const_nodes(model, const_nodes, res)
onnx.checker.check_model(model)
if not skip_shape_inference:
model = infer_shapes(model)
if perform_optimization:
model = optimize(model, skip_fuse_bn, skipped_optimizers)
check_ok = check(model_ori, model, check_n, input_shapes=input_shapes)
return model, check_ok
上面有一行:model = infer_shapes(model) 是获取ONNX模型中特征图的尺寸,它的具体实现如下:
def infer_shapes(model: onnx.ModelProto) -> onnx.ModelProto:
try:
model = onnx.shape_inference.infer_shapes(model)
except:
pass
return model
我们保存一下调用了这个接口之后的ONNX模型,并将其可视化看一下:
相对于原始的ONNX模型,现在每一条线都新增了一个shape信息,代表它的前一个特征图的shape是怎样的。
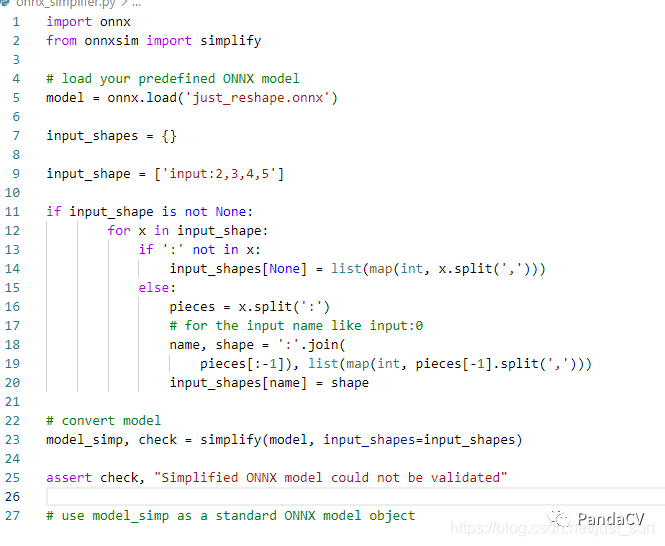
接着,程序使用到了check_and_update_input_shapes接口,这个接口的代码示例如下,它可以用来判断输入的格式是否正确以及输入模型是否存在所有的指定输入节点。
def check_and_update_input_shapes(model: onnx.ModelProto, input_shapes: TensorShapes) -> TensorShapes:
input_names = get_input_names(model)
if None in input_shapes:
if len(input_names) == 1:
input_shapes[input_names[0]] = input_shapes[None]
del input_shapes[None]
else:
raise RuntimeError(
'The model has more than 1 inputs, please use the format "input_name:dim0,dim1,...,dimN" in --input-shape')
for x in input_shapes:
if x not in input_names:
raise RuntimeError(
'The model doesn\'t have input named "{}"'.format(x))
return input_shapes
在这个例子中,如果我们指定input_shapes为:{'input': [2, 3, 4, 5]},那么这个函数的输出也为{'input': [2, 3, 4, 5]}。如果不指定,输出就是{}。验证这个函数的调用代码如下所示:
确定了输入没有问题之后,程序会根据用户指定是否优化ONNX模型进入优化函数,函数定义如下:
def optimize(model: onnx.ModelProto, skip_fuse_bn: bool, skipped_optimizers: Optional[Sequence[str]]) -> onnx.ModelProto:
"""
:model参数: 待优化的ONXX模型.
:return: 优化之后的ONNX模型.
简化之前, 使用这个方法产生会在'forward_all'用到的ValueInfo
简化之后,使用这个方法去折叠前一步产生的常量到initializer中并且消除没被使用的常量
"""
onnx.checker.check_model(model)
onnx.helper.strip_doc_string(model)
optimizers_list = [
'eliminate_deadend',
'eliminate_nop_dropout',
'eliminate_nop_cast',
'eliminate_nop_monotone_argmax', 'eliminate_nop_pad',
'extract_constant_to_initializer', 'eliminate_unused_initializer',
'eliminate_nop_transpose',
'eliminate_nop_flatten', 'eliminate_identity',
'fuse_add_bias_into_conv',
'fuse_consecutive_concats',
'fuse_consecutive_log_softmax',
'fuse_consecutive_reduce_unsqueeze', 'fuse_consecutive_squeezes',
'fuse_consecutive_transposes', 'fuse_matmul_add_bias_into_gemm',
'fuse_pad_into_conv', 'fuse_transpose_into_gemm', 'eliminate_duplicate_initializer'
]
if not skip_fuse_bn:
optimizers_list.append('fuse_bn_into_conv')
if skipped_optimizers is not None:
for opt in skipped_optimizers:
try:
optimizers_list.remove(opt)
except ValueError:
pass
model = onnxoptimizer.optimize(model, optimizers_list,
fixed_point=True)
onnx.checker.check_model(model)
return model
这个函数的功能是对原始的ONNX模型做一些图优化工作,比如merge_bn,fuse_add_bias_into_conv等等。我们使用onnx.save保存一下这个例子中图优化后的模型,可以发现它和优化前的可视化效果是一样的,如下图所示:

这是因为在这个模型中是没有上面列举到的那些可以做图优化的情况,但是当我们打印一下ONNX模型我们会发现optimize过后的ONNX模型多出一些initializer数组:
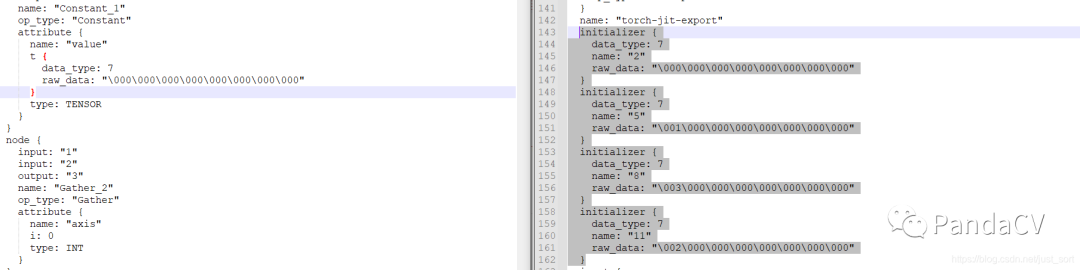
这些数组存储的就是这个图中那些常量OP的具体值,通过这个处理我们就可以调用get_constant_nodes函数来获取ONNX模型的常量OP了,这个函数的详细解释如下:
def get_constant_nodes(m: onnx.ModelProto) -> List[onnx.NodeProto]:
const_nodes = []
# 如果节点的name在ONNX的GraphProto的initizlizer数组里面,它就是静态的tensor
const_tensors = [x.name for x in m.graph.initializer]
# 显示的常量OP也加进来
const_tensors.extend([node.output[0]
for node in m.graph.node if node.op_type == 'Constant'])
# 一些节点的输出shape是由输入节点决定的,我们认为这个节点的输出shape并不是常量,
# 所以我们不需要简化这种节点
dynamic_tensors = []
# 判断是否为动态OP
def is_dynamic(node):
if node.op_type in ['NonMaxSuppression', 'NonZero', 'Unique'] and node.input[0] not in const_tensors:
return True
if node.op_type in ['Reshape', 'Expand', 'Upsample', 'ConstantOfShape'] and len(node.input) > 1 and node.input[1] not in const_tensors:
return True
if node.op_type in ['Resize'] and ((len(node.input) > 2 and node.input[2] not in const_tensors) or (len(node.input) > 3 and node.input[3] not in const_tensors)):
return True
return False
for node in m.graph.node:
if any(x in dynamic_tensors for x in node.input):
dynamic_tensors.extend(node.output)
elif node.op_type == 'Shape':
const_nodes.append(node)
const_tensors.extend(node.output)
elif is_dynamic(node):
dynamic_tensors.extend(node.output)
elif all([x in const_tensors for x in node.input]):
const_nodes.append(node)
const_tensors.extend(node.output)
# 深拷贝
return copy.deepcopy(const_nodes)
在这个例子中,我们打印一下执行这个获取常量OP函数之后,Graph中有哪些OP被看成了常量OP。

获取了模型中所有的常量OP之后,我们需要把所有的静态节点扩展到ONNX Graph的输出节点列表中,然后利用onnxruntme执行一次forward:
def forward_for_node_outputs(model: onnx.ModelProto, nodes: List[onnx.NodeProto],
input_shapes: Optional[TensorShapes] = None) -> Dict[str, np.ndarray]:
if input_shapes is None:
input_shapes = {}
model = copy.deepcopy(model)
# nodes 是Graph中所有的静态OP
add_features_to_output(model, nodes)
res = forward(model, input_shapes=input_shapes)
return res
其中add_features_to_output的定义如下:
def add_features_to_output(m: onnx.ModelProto, nodes: List[onnx.NodeProto]) -> None:
"""
Add features to output in pb, so that ONNX Runtime will output them.
:param m: the model that will be run in ONNX Runtime
:param nodes: nodes whose outputs will be added into the graph outputs
"""
# ONNX模型的graph扩展输出节点,获取所有静态OP的输出和原始输出节点的输出
for node in nodes:
for output in node.output:
m.graph.output.extend([onnx.ValueInfoProto(name=output)])
最后的forward函数就是利用onnxruntime推理获得我们指定的输出节点的值。这个函数这里不进行解释。推理完成之后,进入下一个函数clean_constant_nodes,这个函数的定义如下:
def clean_constant_nodes(const_nodes: List[onnx.NodeProto], res: Dict[str, np.ndarray]):
"""
It seems not needed since commit 6f2a72, but maybe it still prevents some unknown bug
:param const_nodes: const nodes detected by `get_constant_nodes`
:param res: The dict containing all tensors, got by `forward_all`
:return: The constant nodes which have an output in res
"""
return [node for node in const_nodes if node.output[0] in res]
这个函数是用来清洗那些没有被onnxruntime推理的静态节点,但通过上面的optimize逻辑,我们的graph中其实已经不存在这个情况了(没有被onnxruntime推理的静态节点在图优化阶段会被优化掉),因此这个函数理论上是可以删除的。这个地方是为了避免删除掉有可能引发其它问题就保留了。
不过从一些实际经验来看,还是保留吧,毕竟不能保证ONNX的图优化就完全正确,前段时间刚发现了TensorRT图优化出了一个BUG。保留这个函数可以提升一些程序的稳定性。
接下来就是这个onnx-simplifier最核心的步骤了,即将常量节点从原始的ONNX Graph中移除,函数接口为eliminate_const_nodes:
def eliminate_const_nodes(model: onnx.ModelProto, const_nodes: List[onnx.NodeProto],
res: Dict[str, np.ndarray]) -> onnx.ModelProto:
"""
:model参数: 原始ONNX模型
:const_nodes参数: 使用`get_constant_nodes`获得的静态OP
:res参数: 包含所有输出Tensor的字典
:return: 简化后的模型. 所有冗余操作都已删除.
"""
for i, node in enumerate(model.graph.node):
if node in const_nodes:
for output in node.output:
new_node = copy.deepcopy(node)
new_node.name = "node_" + output
new_node.op_type = 'Constant'
new_attr = onnx.helper.make_attribute(
'value',
onnx.numpy_helper.from_array(res[output], name=output)
)
del new_node.input[:]
del new_node.attribute[:]
del new_node.output[:]
new_node.output.extend([output])
new_node.attribute.extend([new_attr])
insert_elem(model.graph.node, i + 1, new_node)
del model.graph.node[i]
return model
运行这个函数之后我们获得的ONNX模型可视化结果是这样子的:
注意,这里获得的ONNX模型中虽然常量节点已经从Graph中断开了,即相当于这个DAG里面多了一些单独的点,但是这些点还是存在的。因此,我们再执行一次optimize就可以获得最终简化后的ONNX模型了。最终简化后的ONNX模型如下图所示:
0x6. 总结
介于篇幅原因,介绍ONNX的第一篇文章就介绍到这里了,后续可能会结合更多实践的经验来谈谈ONNX了,例如OneFlow模型导出ONNX进行部署?。总之,文章很长,谢谢你的观看,希望这篇文章有帮助到你。最后欢迎star大老师的onnx-simplifier。
0x7. 参考资料
【1】https://zhuanlan.zhihu.com/p/86867138 【2】https://oldpan.me/archives/talk-about-onnx 【3】https://blog.csdn.net/chengzi_comm/article/details/53199278 【4】https://www.jianshu.com/p/a24c88c0526a 【5】https://bindog.github.io/blog/2020/03/13/deep-learning-model-convert-and-depoly/ 【6】 https://github.com/daquexian/onnx-simplifier
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。