
Service Worker初探
编者按:本文作者王若铮,奇舞团前端开发工程师。
本文是奇舞团泛前端分享会Service Worker初探的一次记录,是对360扫地机器人App内嵌web页面使用Service Worker优化的一次总结。
本文所有代码示例均已提交到github,地址1
Service Worker是什么
Service Worker是渐进式web应用(pwa)的核心技术。
通过注册之后,可以独立于浏览器在后台运行,控制我们的一个或者多个页面。如果我们的页面在多个窗口中打开,Service Worker不会重复创建。
就算浏览器关闭之后,Service worker也同样运行。但是浏览器是不会允许Service Worker一直处于工作状态。因为随着用户打开越来越多的注册了Service Worker的页面,性能肯定会收到影响。在后面的生命周期中,我们会一起探讨Service Worker的运行原理。
Service Worker是客户端和服务端的代理层,客户端向服务器发送的请求,都可以被Service Worker拦截,并且可以修改请求,返回响应。

同时也会在用户离线的时候正常工作,当浏览器发送请求,Service Worker检测到离线状态的时候,可以直接返回缓存数据和提前准备好的离线页面。
进一步来讲,用户关闭了所有的页面,Service Worker同样可以和服务器通信。完成尚未完成的数据请求,可以确保用户的任何操作都可以发送到服务器。
Service Worker的优势
1. 支持离线访问
传统的web页面,在每次访问的时候,都会去请求服务器的资源。在使用Service Worker之后,第一次访问的时候,可以将我们的静态资源缓存下来,下次访问的时候可以通过Service Worker返回缓存,就可以支持离线访问了。
2. 加载速度快
页面资源缓存之后,不需要依赖网络加载服务器资源。无论用户是否具有良好的的网络状态,甚至在离线的情况下,都可以瞬间加载我们的web页面。
3. 离线状态下的可用性
在不追求返回结果的数据请求中,可以使用Service Worker进行代理。当客户端从离线转为在线的时候,就算已经关闭了页面。Service Worker也能够帮助我们继续发送代理的请求。无论,用户是在线、离线还是网络不稳定的时候,借助Service Worker都能够提供一个相对完整的用户体验。
安全策略
由于serviceworker功能强大,可以修改任何通过它的请求,因此需要对其进行一定的安全限制。
1. 使用https或者localhost本地域名的页面才可以使用Service Worker
正常情况下,只有使用https的页面才能够注册Service Worker。为了方便我们的开发和调试,在开发的过程中,可以使用localhost来使用Service Worker。一旦把应用部署到服务器之后,必须使用https保证Service Worker的正常工作。
2. Service Worker的作用域
每个Service Worker都有一个有限的控制范围。这个范围就是通过放置Service Worker的js文件的目录决定的,也就是Service Worker所在目录以及所有的子目录。
也可以通过注册Service Worker的时候传入一个scope选项,用来覆盖默认的作用域。但是,只能将作用域的范围缩小,不能将它扩大。换句话来说,scope的值,必须是Service Worker所在目录或者是子目录。
navigator.serviceWorker.register('serviceworker.js', { scope: '/' })
如何使用
下面我们根据一个简单的示例,看一下Service Worker是如何运行的。
在浏览器环境下,我们可以通过navigator.serviceWorker.register注册一个Service Worker。register方法的第一个参数是Service Worker的js文件的地址,第二个参数是规定了Service Worker的作用域。
window.onload = function() {
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('./serviceworker.js', { scope: '/' })
}
}
注册之后,Service Worker可以独立于浏览器在后台运行,来控制我们的页面。如果我们的页面在多个窗口中打开,Service Worker不会重复创建,在不同窗口中的页面,均由一个Service Worker统一管理。
下面我们创建一下serviceworker.js文件。
在这里,监听了两个事件。在install事件中,我们将一个离线页面缓存进来。在fetch事件中,如果资源请求失败的话,使用刚才缓存的离线页面。这样,我们的web应用就会在离线状态下,加载这个离线页面了。
self.addEventListener('install', function(event) {
event.waitUntil(
caches.open('cache').then((cache) => {
return cache.add('./offline.html')
})
)
})
self.addEventListener('fetch', function(event) {
event.respondWith(
fetch(event.request).catch(() => {
return caches.match('./offline.html')
})
)
})
请注意,我们刚刚提到过Service Worker的安全策略只允许我们在Https或者localhost下注册它,所以我们一定要开启一个本地服务器来运行我们的代码示例。
下面,我们对于刚才的例子做一个小小的改动。我们新建一个new_offline.html文件,将serviceworker.js中的offline.html替换为new_offline.html。如果你刚才已经运行过上一版的代码,你就会发现,页面并没有发生改变,在离线状态下,页面依然是旧版的offline.html。
当我们关闭所有运行代码的标签页之后再次打开,我们就会惊奇的发现,页面更新了。想要搞明白这些问题,我们必须要了解Service Worker的生命周期。
生命周期
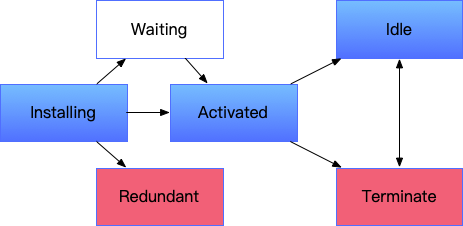
在注册Service Worker之后,Service Worker会马上进去installing的生命周期进行安装,同时会进入Service Worker的install事件中。如果在installing中,有任何资源加载失败,都会导致安装失败,Service Worker会直接进入废弃状态。
在安装成功之后,在正常情况下,会进入Activated状态,同时会进入Service Worker的activate事件中。当activate中的代码执行完成后,Service Worker会进入Idle的状态。
只有在这个状态下,fetch、sync、message的一系列事件事件才能够正常监听。所以,有的时候我们发现,在页面第一次加载,fetch中的逻辑并没有生效,那是因为Service Worker在注册完成之前,我们的数据请求早已经加载完成了。
同时,在这个状态下。Service Worker是否工作也和这些事件绑定在一起。当某个Service Worker中的这些事件被触发,Service Worker将被唤醒,处理事件,然后终止。这样,就会防止当浏览器加载越来越多的Service Worker的页面导致浏览器卡顿的问题。
回到安装的时候,如果当前的页面已经存在了一个激活的Service Worker的时候,在新的Service Worker安装完成,会进入Waiting状态。如果页面所有的标签页全部关闭之后,或者导航到一个不在控制范围内的页面。再次打开新的Service Worker才会生效。
CacheStorage API
在Service Worker中,我们通常使用CacheStorage来管理缓存。
CacheStorage是一种全新的缓存层,让我们对缓存具有完全的控制权。和Cookie一样,都是具有同源策略的。
CacheStorage为我们提供了一系列的api来操作缓存。这些api都是基于Promise的,所有方法的返回值都是一个Promise。
caches.open(cacheName) => Primose
CacheStorage是可以分组的,可以通过这个方法传入cacheName来打开一个分组。如果没有这个分组,那就会创建。最终返回当前的cache,一般情况下,基于这个cache来操作缓存。
caches.keys() => Primose
这个方法可以获取所有的缓存名称的列表。
cache.addAll(url[])
通过open方法拿到目标cache,之后可以调用addAll,传入一个url列表之后,会将这些url全部缓存下来。
cache.put(url)
如果我们要添加单个缓存可以使用cache.put方法
cache.add(key, value)
在缓存一个请求数据的时候,我们希望将缓存和当前的请求想匹配的话。不单单是匹配url,还要匹配请求参数以及是POST还是GET甚至是匹配请求头的时候,可以使用cache.put方法,第一个参数是key,这里的key可以是一个Request对象,当我们去查询缓存的时候,只有当key完全相等的时候才能够匹配。第二个参数value,必须是一个Response的结构。
cache.delete(key)
已经不需要的缓存可以通过cache.delete方法进行删除。
cache.match(url | Requst) | caches.match(url | Requst)
在查询相关的缓存的时候,通过match方法,传入url或者Request。究竟传入什么参数,取决于如何添加的缓存。如果在具体的cache上调用这个方法,就是在当前缓存下去查找,如果在window.caches下调用,就是在全局缓存中匹配。
CacheStorage和http缓存的关系

在发送http请求的时候,请求会先到达Service Worker。在Service Worker中,使用CacheStorage来查询是否具有可用的缓存。
如果没有,浏览器先会检测Cache-Control是否使用当前的浏览器缓存,这就是我们常说的强缓存。
如果浏览器缓存已过期,请求正式到达服务器。再去判断资源的ETag和Last-Modified有没有发生变化,决定是否使用服务器缓存。
CacheStorage不能取代过去的HTTP缓存。CacheStorage因为Service Worker的作用域问题,只能控制范围内的缓存,无法控制cdn和在其他域下的接口数据。
缓存模式
缓存模式主要探讨了一个关于缓存利用率和更新的权衡问题。如果缓存利用率高了的话,代码更新速度必然受到影响。
我们先来看一下第一种,缓存优先,在没有缓存的情况下请求网络资源。这是一种高效、省流量的方法。但是资源的更新可能会收到影响。这种模式通常适用于不会更新的静态资源,比如图片和代码库。
self.addEventListener('fetch', (event) => {
event.respondWith(
caches.open('cache-name').then((cache) => {
return cache.match(event.request).then((cacheResponse) => {
return cacheResponse || fetch(event.request).then((networkResponse) => {
cache.put(event.request, networkResponse.clone())
return networkResponse
})
})
})
)
})
第二种模式是,缓存优先,频繁更换资源。这是一种高效的方案。并且在第二次加载的时候显示可用的最新版本。带宽消耗和使用缓存一样。
self.addEventListener('fetch', (event) => {
event.respondWith(
caches.open('cache-name').then((cache) => {
return caches.match(event.request).then((cacheResponse) => {
const fetchPromise = fetch(event.request).then((networkResponnse) => {
cache.put(event.request, networkResponnse)
return networkResponnse
})
return cacheResponse || fetchPromise
})
})
)
})
第三种模式是,网络优先,失败的时候使用缓存。加载时间较慢,总是展示最新的文件。在请求失败的情况下,使用的缓存也不一定是正在请求资源的缓存,同样也可以是其他的缺省资源。就像第一个代码示例一样,在html请求失败的情况下,我们可以返回一个断网页面。在图片请求失败的情况下,我们可以提供一个默认图片
self.addEventListener('fetch', (event) => {
event.respondWith(
caches.open('cache-name').then((cache) => {
return fetch(event.request).then((networkResponse) => {
cache.put(event.request, networkResponse.clone())
return networkResponse
}).cache(() => {
return cache.match(event.request)
})
})
)
})
基于版本控制的缓存模式。
在版本控制的缓存模式下,可以既提高缓存效率,又能解决版本更新不及时的问题。我们通过一个示例来阐述这种模式。
首先,还是要在浏览器环境下注册Service Worker。和以往有所不同的是我们监听了controllerchange事件,当Service Worker发生变化的时候,就重载页面,完成页面的及时更新。
if (process.env.NODE_ENV === 'production' && 'serviceWorker' in navigator) {
window.addEventListener('load', function () {
if (!navigator.serviceWorker.controller) {
try {
navigator.serviceWorker.register('serviceworker.js')
} catch (err) {
throw Error(err)
}
}
navigator.serviceWorker.addEventListener('controllerchange', () => {
window.location.reload()
})
})
}
对于Service Worker,我们将对没有过期的资源永远使用缓存,对于过期的资源,加载网络资源并更新缓存。缓存是否过期的判断依据使用,那就是版本号。下面,我们通过四个步骤借助webpack来完成这件事情。借助webpack的目的是,更加方便的获取静态资源列表,已经通过package.json的version字段来设置我们的版本号。

1. 定义资源版本号
首先我们要在serviceworker.js中定义一些变量。cacheKey就是一个特定字符串和VERSION拼接的字符串,作为缓存名称来使用。VERSION、CACHE_LIST就需要借助webpack的插件帮助我们完成替换。
// serviceworker.js
const VERSION = self.__VERSION__
const cacheKey = 'cache-' + VERSION
const CACHE_LIST = self.__WEBPACK_INJECT_CACHE_LIST__
下面我们再来看一下webpack插件的配置,ServiceWorkerPlugin是我们的自定义插件。
// webpack.config.js
const fs = require('fs')
const path = require('path')
class ServiceWorkerPlugin {
apply (compiler) {
compiler.hooks.emit.tap('ServiceWorkerPlugin', async (compilation) => {
const packageJson = fs.readFileSync(path.resolve(__dirname, './package.json'))
const version = JSON.parse(packageJson).version
const assetKeys = Object.keys(compilation.assets)
let source = compilation.assets['serviceworker.js'].source().toString()
source = source.replace('self.__WEBPACK_INJECT_CACHE_LIST__', JSON.stringify(assetKeys))
source = source.replace('self.__VERSION__', JSON.stringify(version))
compilation.assets['serviceworker.js'] = {
source: () => source,
size: () => source.length
}
})
}
}
module.exports = {
...
plugins: [
new ServiceWorkerPlugin()
]
}
在ServiceWorkerPlugin插件中,我们通过webpack的compilation.assets拿到所有的静态资源,通过package.json获取版本号,替换到我们的serviceworker.js文件中。
2. 根据版本号缓存所有静态资源
我们需要在Service Worker的安装事件中,缓存所有的静态资源。self.skipWaiting方法让当前新版本的Service Worker跳过等待。
self.addEventListener('install', function (event) {
event.waitUntil(
caches.open(cacheKey)
.then((_cache) => _cache.addAll(CACHE_LIST))
.then(self.skipWaiting())
)
})
3. 删除过期资源,self.clients.claim方法可以让当前的Service Worker立刻掌控页面,实现页面的及时更新。
self.addEventListener('activate', function (event) {
event.waitUntil(
caches.keys().then((keys) => (
Promise.all(
keys.filter((key) => key !== cacheKey)
.map((key) => caches.delete(key))
)
)).then(() => {
self.clients.claim()
})
)
})
4. 使用未过期的缓存
self.addEventListener('fetch', function (event) {
if (CACHE_LIST.find((cache) => {
return event.request.url.endsWith(cache)
})) {
event.respondWith(
caches.match((event.request)).then((cachedResponse) => (
cachedResponse || fetch(event.request)
))
)
}
})
使用后台同步保证离线功能
客户端和web在用户的角度看来,有一个很大的区别是,在客户端执行了一些操作,比如发布文章。就算在断网状态下,用户也不会担心自己编辑的内容丢失。如果在一般的web页面,所有的数据只会跟随浏览器的关闭而消失。
在Service Worker的支持下,我们可以页面上注册一个同步事件发送到Service Worker。在Service Worker中完胜数据请求。
这样,就不需要担心用户数据丢失的问题了。即使用户在断网的状态下发送的数据请求,当设备重新联网的时候,Service Worker会自动帮助我们完成发送。
下面我们就来看一下,如何使用具体代码来实现这个功能。
需要注意的是,我们需要在Service Worker的ready事件中去绑定按钮的点击事件,来确保用户点击的时候,Service Worker已经准备好了。
然后我们通过registration.sync.register('send-messages')来发送给同步事件。send-messages只是当前事件的一个标识。在Service Worker中可以使用它来判断应该处理什么样的逻辑。
事件标识是唯一的,如果Service Worker正在处理或者还没有处理完成一个标识的时候,使用这个已有的标识再次注册sync事件,那么这个事件将会被忽略。如果我们不想让新的操作被忽略,可以在事件后边加上递增ID,例如send-messages1。
// html
<button id="submit">发送请求</button>
// js
window.onload = function() {
navigator.serviceWorker.register('./serviceworker.js')
navigator.serviceWorker.ready.then((registration) => {
document.getElementById('submit').addEventListener('click', () => {
registration.sync.register('send-messages')
})
})
}
在Service Worker中,注册了一个同步事件,通过event.tag拿到我们刚才发送的标识。来处理发送信息的操作。
如果发送信息失败,这个同步事件过一段时间将会再次尝试发送。当event.lastChance属性为true时,将会放弃尝试。在chrome浏览器中测试,一共会发送三次,第一次到第二次的间隔为5分钟,第二次到第三次的间隔为10分钟。
function sendMessages() {
return fetch('http://localhost:3000/').then((response) => {
return response.json()
}).then((data) => {
console.log(data.errCode === 0)
return data.errCode === 0 ? Promise.resolve() : Promise.reject()
})
}
self.addEventListener('sync', (event) => {
if (event.tag === 'send-messages') {
event.waitUntil(
sendMessages().catch(() => {
if (event.lastChance) {
console.log('不会再次尝试请求了')
}
return Promise.reject()
})
)
}
})
下面,我们可以写一个简单服务器,用来尝试这个例子。
const express = require('express')
const app = express()
const port = 3000
app.use((req, res, next) => {
res.header('Access-Control-Allow-Origin', '*');
res.header('Access-Control-Allow-Methods', '*');
next();
});
app.get('/', (req, res) => {
const response = { errCode: 0 };
const date = new Date();
const hour = date.getHours();
const minutes = date.getMinutes();
const second = date.getSeconds();
const time = `${hour}:${minutes}:${second}`;
console.log('请求成功!参数:', req.query, '返回值:', response, '时间:', time)
res.send(response)
})
app.listen(port, () => console.log(`Example app listening on port ${port}!`))
在断网的时候,点击按钮,服务器不会收到请求。当设备恢复网络的时候,服务器会马上收到请求。我们可以将返回值的errCode修改为1,尝试下Service Worker是否会发送多次请求。
sync事件的数据传递
上面的例子中,展示了如何使用Service Worker来代理数据请求。但是大部分的数据请求都是需要参数的,那么如何将参数传递到Service Worker呢。
1. 使用标识传递参数
对于一些简单参数而言,可以直接使用标示来传递。这样的话,事件标示就有两个组成部分,第一个部分是标识类型,规定了Service Worker的同步事件采取什么样的代码逻辑,第二个部分就是参数。这两个部分使用"_"进行分割。
// 浏览器环境
navigator.serviceWorker.ready.then((registration) => {
document.getElementById('submit').addEventListener('click', () => {
const content = document.getElementById('content').value
registration.sync.register(`send-messages_${content}`)
})
})
// Service Worker
function sendMessages(content) {
return fetch(`http://localhost:3000/?content=${content}`).then((response) => {
return response.json()
}).then((data) => {
console.log(data.errCode === 0)
return data.errCode === 0 ? Promise.resolve() : Promise.reject()
})
}
self.addEventListener('sync', (event) => {
if (event.tag.startsWith('send-messages')) {
const content = event.tag.split('_')[1]
event.waitUntil(
sendMessages(content).catch(() => {
if (event.lastChance) {
console.log('不会再次尝试请求了')
}
return Promise.reject()
})
)
}
})
2. 使用indexedDB传递参数
Service Worker环境中,除了CacheStorage外,也可以使用基于浏览器的本地数据库indexedDB。
indexedDB是一个基于浏览器的本地数据库,操作indexedDB基本可以分为4个步骤。
打开数据库
启动事务
打开对象存储
在对象存储中完成操作
通过代码的形式来展示一下如何操作indexedDB。
// 定义global对象 因为indexedDB的代码需要在浏览器和Service Worker两个环境下运行
const _global = typeof window === 'undefined' ? self : window
// 打开数据库
// 如果indexedDB已经存在,window.indexedDB.open方法不会重新创建,只会打开那个已经创建好的数据库。window.indexedDB.open方法的第二个个参数是数据库版本号。
// onupgradeneeded只会在数据库版本升级的时候执行,用来创建对象存储。
const openDataBase = function () {
return new Promise((resolve, reject) => {
const request = _global.indexedDB.open('conent-db', 1)
request.onupgradeneeded = (event) => {
const db = event.target.result
if (!db.objectStoreNames.contains('list')) {
db.createObjectStore('list', {
keyPath: 'id',
autoIncrement: true
})
}
}
request.onerror = (err) => reject(err)
request.onsuccess = (event) => resolve(event.target.result)
})
}
// 启动事务
const openObjectStore = async function (storeName, mode) {
const db = await openDataBase()
return db.transaction(storeName, mode).objectStore(storeName)
}
_global.db = {
set: async function (content) {
// 打开数据存储
const objectStore = await openObjectStore('list', 'readwrite')
// 新增数据
return objectStore.add({ content })
},
getAll: async function () {
// 打开数据存储
const objectStore = await openObjectStore('list')
return new Promise((resolve) => {
const data = []
// 根据游标查询数据
// 我们在创建数据库的时候使用autoIncrement设置自增主键,所以需要通过游标查询所有的数据
objectStore.openCursor().onsuccess = function (event) {
const cursor = event.target.result
if (!cursor) {
return resolve(data)
} else {
data.push(cursor.value)
cursor.continue()
}
}
})
},
clear: async function (ids) {
// 打开数据存储
const objectStore = await openObjectStore('list', 'readwrite')
// 清空对象
return objectStore.clear()
}
}
在浏览器环境下,调用刚才封装的indexedDB的set方法完成对数据参数的存储
document.getElementById('submit').addEventListener('click', async () => {
const content = document.getElementById('content').value
await db.set(content)
registration.sync.register(`send-messages`)
})
在Service Worker中,获取到所有的content,通过Promise.all全部发送。成功之后清除数据。
self.addEventListener('sync', (event) => {
if (event.tag === 'send-messages') {
event.waitUntil(
self.db.getAll().then((contents) => {
return Promise.all(
contents.map(({ content }) => {
return sendMessages(content)
})
)
}).then(() => {
return self.db.clear()
})
)
}
})
这样我们就完成了使用indexedDB传递参数了。
总结
本文介绍了Service Worker的基本概念和特性,并且从缓存和后台发送请求两个方面阐述了如何优化我们的项目。
其实Service Worker的优化能力不仅仅是这些,相信它还有更加强大的作用等着我们一起来挖掘!
文内链接
https://github.com/wrz199306/ServiceWorkerDemo
后记
如果你喜欢探讨技术,或者对本文有任何的意见或建议,非常欢迎加鱼头微信好友一起探讨,当然,鱼头也非常希望能跟你一起聊生活,聊爱好,谈天说地。鱼头的微信号是:krisChans95 也可以扫码关注公众号,订阅更多精彩内容。