
从 BIO 到 NIO,再到 AIO
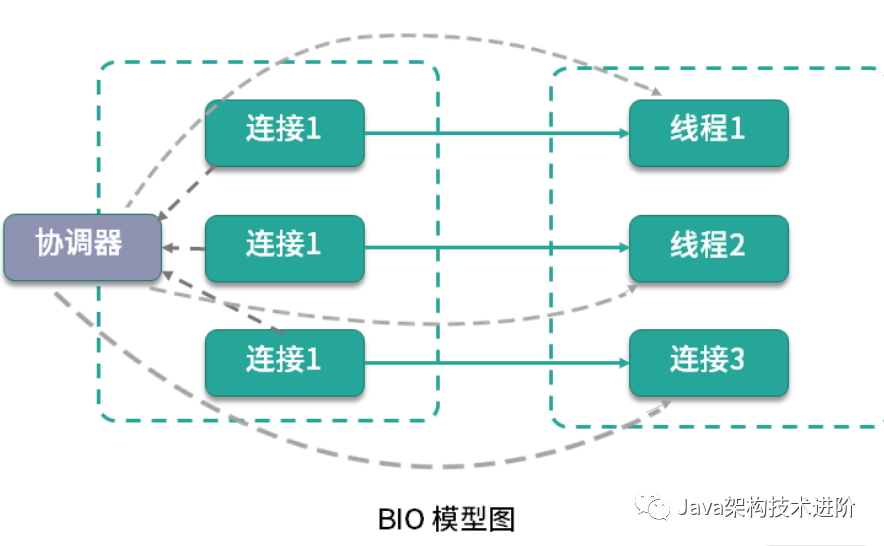
BIO 模型,每当有一个连接到来,经过协调器的处理,就开启一个对应的线程进行接管。如果连接有 1000 条,那就需要 1000 个线程。
线程资源是非常昂贵的,除了占用大量的内存,还会占用非常多的 CPU 调度时间,所以 BIO 在连接非常多的情况下,效率会变得非常低。
为什么 NIO 的性能就能够比传统的阻塞 I/O 性能高呢?
Java 的 NIO,在 Linux 上底层是使用 epoll 实现的。epoll 是一个高性能的多路复用 I/O 工具,改进了 select 和 poll 等工具的一些功能
epoll 的数据结构是直接在内核上进行支持的,通过 epoll_create 和 epoll_ctl 等函数的操作,可以构造描述符(fd)相关的事件组合(event)。
fd 每条连接、每个文件,都对应着一个描述符,比如端口号。内核在定位到这些连接的时候,就是通过 fd 进行寻址的。
event 当 fd 对应的资源,有状态或者数据变动,就会更新 epoll_item 结构。在没有事件变更的时候,epoll 就阻塞等待,也不会占用系统资源;一旦有新的事件到来,epoll 就会被激活,将事件通知到应用方。
BIO 的读写操作是阻塞的,线程的整个生命周期和连接的生命周期是一样的,而且不能够被复用。
当服务的连接增多,考虑到整个服务器的资源调度和资源利用率等因素,NIO 就有了显著的效果,NIO 非常适合高并发场景。
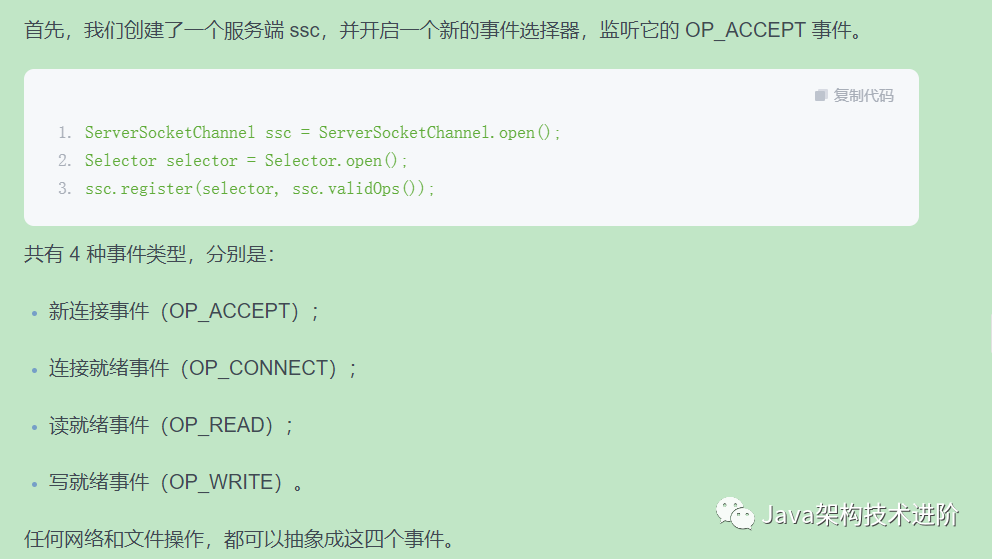
接下来,在 while 循环里,使用 select 函数,阻塞在主线程里。所谓阻塞,就是操作系统不再分配 CPU 时间片到当前线程中,所以 select 函数是几乎不占用任何系统资源的。
一旦有新的事件到达,比如有新的连接到来,主线程就能够被调度到,程序就能够向下执行。这时候,就能够根据订阅的事件通知,持续获取订阅的事件。
由于注册到 selector 的连接和事件可能会有多个,所以这些事件也会有多个。我们使用安全的迭代器循环进行处理,在处理完毕之后,将它删除。
关于 epoll 还会有一个面试题,相对于 select,epoll 有哪些改进?
epoll 不再需要像 select 一样对 fd 集合进行轮询,也不需要在调用时将 fd 集合在用户态和内核态进行交换;
应用程序获得就绪 fd 的事件复杂度,epoll 是 O(1),select 是 O(n);
select 最大支持约 1024 个 fd,epoll 支持 65535个;
select 使用轮询模式检测就绪事件,epoll 采用通知方式,更加高效。
如果事件不删除的话,或者漏掉了某个事件的处理,会有什么后果?
由于每次判断都会有事件,就会造成select线程的频繁唤醒,进而造成CPU的使用飙升。
op_write
这个事件是表示写就绪的,当底层的缓冲区有空闲,这个事件就会一直发生,浪费占用 CPU 资源。所以,我们一般是不注册 OP_WRITE 的。
为什么我在使用 NIO 时,使用 Channel 进行读写,socket 的操作依然是阻塞的?NIO 的作用主要体现在哪里?
NIO 只负责对发生在 fd 描述符上的事件进行通知。事件的获取和通知部分是非阻塞的,但收到通知之后的操作,却是阻塞的,即使使用多线程去处理这些事件,它依然是阻塞的。
AIO 更近一步,将这些对事件的操作也变成非阻塞的
AIO 是 Java 1.7 加入的,理论上性能会有提升,但实际测试并不理想。这是因为,AIO主要处理对数据的自动读写操作。这些操作的具体逻辑,假如不放在框架中,也要放在内核中,并没有节省操作步骤,对性能的影响有限。而 Netty 的 NIO 模型加上多线程处理,在这方面已经做得很好,编程模式也比AIO简单。
所以,市面上对 AIO 的实践并不多,在采用技术选型的时候,一定要谨慎
