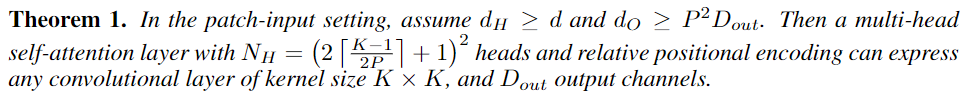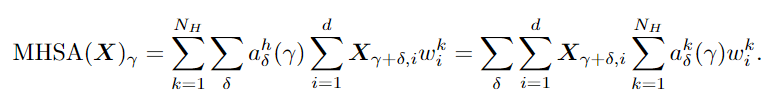Visual Transformer(ViT)在计算机视觉界可以说是风头无两,完全不使用卷积神经网络(CNN) 而只使用自注意力机制的情况下,还可以在各个CV任务上达到sota。研究结果也表明,只要有足够的训练数据时,ViT可以显著地优于基于卷积的神经网络模型。但这并不代表CNN推出了历史舞台,ViT在CIFAR-100等小型数据集上的表现仍然比CNN差。一个比较常见的解释是Transformer更强大的原因在于自注意力机制获得了上下文相关的权重,而卷积只能捕捉局部特征。然而,目前还没有证据证明Transformer是否真的比CNN全方面、严格地好,也就是说,是否CNN的表达能力完全被Transformer包含?之前有学者给出了一些他们的答案,实验表明具有足够数量header的自注意力层可以表示卷积,但它们只关注于注意力层的输入表示为像素的情况,在输入序列非常长时内存成本巨大,这是不实用的。而且在ViT及其大多数变体中,输入是非重叠图像片段(image patch)的表示,而不是像素。卷积操作涉及的像素跨越了patch的边界,ViT 中的一个自注意力层是否可以表示卷积仍然是未知的。来自北大、加利福尼亚大学洛杉矶分校UCLA、微软的研究人员就这个问题进行了研究并给出了一个具有证明、肯定的(affirmative)答案:具有相对位置编码和足够注意力header的ViT层即使在输入是图像补丁的情况下也可以表示任何卷积。https://arxiv.org/abs/2111.01353
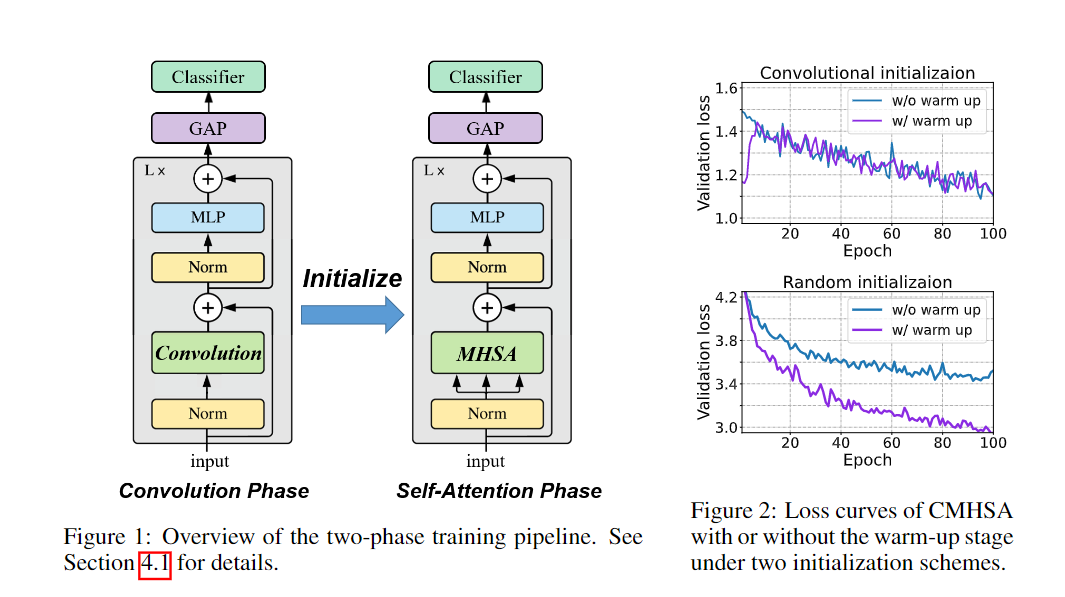
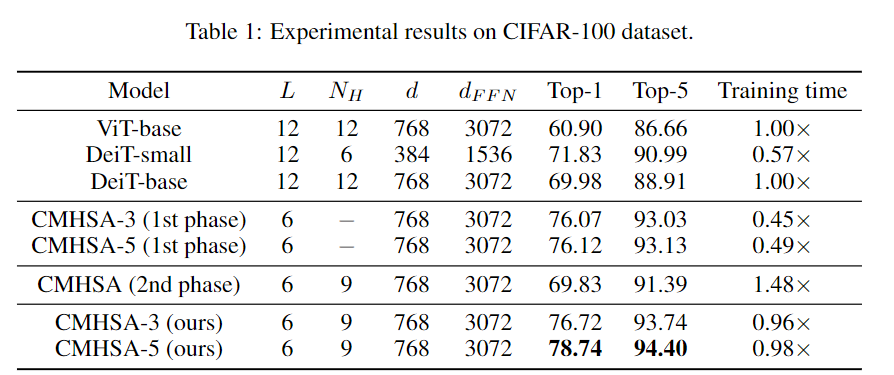
这意味着ViT在小数据集上的性能较差,主要是由于它的泛化性能,而不是表达能力。在理论研究的基础上,文中提出了一种将卷积偏差引入视觉变换器的两阶段训练pipeline,并在低数据环境下进行了实验验证。要考虑ViT中的MHSA(Multi-head Self-Attention)层来表示卷积的问题,作者主要关注输入。图像patch的输入给验证这一结果带来了很大的困难:卷积运算可以在patch边界像素上运行,而Transformer不行。为了解决这一问题,首先需要将来自所有相关patch的信息聚合起来,通过利用相对位置编码和多头机制计算卷积,然后对聚合特征进行线性投影。通过多头机制还原卷积后,另一个问题是header的数量是否会影响最优解。研究人员给出了MHSA层在像素输入和patch输入设置中表示卷积所需的头部数量的较低限制,强调了多头机制的重要性。研究结果清楚地表明了像素输入和patch输入设置之间的区别:即patch输入使自注意力比像素输入需要更少的头来进行卷积,尤其是当k较大时。例如如果具有像素输入的mhsa层需要至少25个header来执行5×5卷积,而具有patch输入的mhsa层只需要9个header。通常,在ViT中,MHSA层中的头部数量很少,例如,VIT-base中只有12个header,因此理论和现实互相印证,与实际情况达成一致。上述理论结果提供了一种允许MHSA层表示卷积的结构。研究人员又提出了一个两阶段的ViT 训练pipeline来进行训练。首先训练ViT的卷积变体,其中mhsa层被k×k卷积层取代,也称之为卷积训练阶段。然后将预训练模型中的权重转移到一个Transformer模型中,并在同一数据集上继续训练模型,称为自注意力训练阶段。pipeline中的一个非常重要的步骤是从良好训练的卷积层中初始化MHSA层。由于卷积的存在,所以不能使用[cls]标记进行分类,而需要通过在最后一层的输出上应用全局平均池,然后使用线性分类器来执行图像分类,和CNN图像分类一样。从直觉来看,在卷积阶段,模型对数据进行卷积神经网络学习,并具有包括局部性和空间不变性在内的诱导偏差,使得学习更加容易。在自注意阶段,该模型从模拟预先训练的CNN开始,逐渐学习到利用CNN的灵活性和强大的自注意表达能力。在实验部分,作者将模型命名为CMHSA-K(卷积MHSA),其中K 为第一阶段训练中卷积核的大小。选取的模型包括ViT-base (直接用Transformer在图像上进行分类)和DeiT(用数据增强和随机正则化来提升ViT性能)。可以看到,两阶段训练pipeline基本上提高了性能,也证明了DeiT的两阶段训练策略很有效。此外文中提出的两阶段训练pipeline模型和DeiT的性能有很大差别,例如,CMHSA-5模型的第1名精度比DeiT-base高出近9%,可以看到pipeline可以在低数据环境下的数据增强和规则化技术上提供进一步的性能增益。并且两个训练阶段都很重要。在相同数量的训练时间下,只接受一个阶段训练的CMHSA总是比接受两个阶段训练的CMHSA表现差。CMHSA(2nd phase)是一个随机初始化的CMHSA,经过400个epoch的训练,其测试精度远低于最终两阶段模型。因此,从第一阶段转移的卷积偏差(convolutional bias)对于模型获得良好的性能至关重要。卷积阶段也有助于加速训练。由于MHSA模块的高计算复杂性,Transformer 的训练通常是耗时的。相比之下,CNNS的训练和推理速度要快得多。在文中提出的训练pipeline中,卷积阶段非常快,虽然自注意力阶段稍慢,但与DeiT-base 相比,仍然可以用更少的时间完成400个训练epoch。最后研究人员指出,由于ViT模型存在一定的限制,目前的方法无法实现任何ViT模型对CNN的模拟。特别是需要足够数量的header(≥9)。对于较小数量的头部来说,不存在精确的映射,即使精确映射不适用,如何从CNN正确初始化VIT也值得研究。参考资料:
https://arxiv.org/abs/2111.01353
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~