
基于OpenCV的实时面部识别
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
人脸识别
“面部识别”名称本身就是一个非常全面的定义,面部识别是通过数字媒体作为输入来识别或检测人脸的技术执行过程。
人脸识别的准确性可以提供高质量的输出,而不是忽略影响其的问题因素。在这里,要确保运行我们的模型,必须确保在本地系统中安装了库。
pip install face_recognition
如果在 face_recognition库的安装过程中遇到一些问题或错误,可以点击以下链接:https://www.youtube.com/watch?v=xaDJ5xnc8dc
人脸识别本身无法提供清晰的输出,因此出现了OpenCV实现的概念。

预先录制的视频中的人脸识别输出示例。
OpenCV
OpenCV是python中一个著名的库,用于实时应用程序。OpenCV在计算机世界中就像树的根一样非常重要。
face_recognition中的OpenCV对我们训练为输入的面部图像进行聚类和特征提取。它以图像中的地标为目标,以迭代方式在计算机视觉的深度学习方法中训练它们。
在本地系统中安装OpenCV
pip install opencv-python
使用深度学习算法,OpenCV检测可作为聚类,相似性检测和图像分类的表示。
为什么我们使用OpenCV作为实时Face_Recognition中的关键工具?
人类可以轻松检测到面部,但是我们如何训练机器识别面部?OpenCV在这里填补了人与计算机之间的空白,并充当了计算机的愿景。
以一个实时的例子为例,当一个人遇到新朋友时,他会记住这些人的脸,以备将来识别。一个人的大脑反复训练后端的人脸。因此,当他看到那个人的脸时,他说:“嗨,约翰!你好吗?”。
对面部的识别和可以为计算机提供与人类相同的思维方式。
OpenCV是计算机视觉中的重要工具。如果我们使用OpenCV,则遵循以下步骤:
• 通过输入提取数据。
• 识别图像中的面部。
• 提取独特的特征,以建立预测思想。
• 该特定人的性格特征,如鼻子,嘴巴,耳朵,眼睛和面部主要特征。
• 实时人脸识别中人脸的比较。
• 识别出的人脸的最终输出。
使用OpenCV python的Face_Recognition:
代码下载:https://github.com/eazyciphers/deep-machine-learning-tutors/tree/master/Real-Time Face RecognitionGitHub
导入所有软件包:
import face_recognitionimport cv2import numpy as np
加载并训练图像:
# Load a sample picture and learn how to recognize it.Jithendra_image = face_recognition.load_image_file("jithendra.jpg")Jithendra_face_encoding = face_recognition.face_encodings(Jithendra_image)[0]# Load a sample picture and learn how to recognize it.Modi_image = face_recognition.load_image_file("Modi.jpg")Modi_face_encoding = face_recognition.face_encodings(Modi_image)[0]
人脸编码:
# Create arrays of known face encodings and their namesknown_face_encodings = [Jithendra_face_encoding,Modi_face_encoding,]known_face_names = ["Jithendra","Modi"]
主要方法:
当实时人脸识别为true时,它将检测到人脸并按照代码中的以下步骤操作:
• 抓取实时视频中的一帧。
• 将图像从BGR颜色(OpenCV使用的颜色)转换为RGB颜色(face_recognition使用的颜色)
• 在实时视频的帧中找到所有面部和面部编码。
• 循环浏览此视频帧中的每个面孔,并检查该面孔是否与现有面孔匹配。
• 如果一个人脸无法识别现有人脸,则将输出视为未知或未知。
• 识别后,否则在识别出的脸部周围画一个方框。
• 用其名称标记识别的面部。
• 识别后显示结果图像。
退出:
# Hit 'q' on the keyboard to quit!
if cv2.waitKey(1) & 0xFF == ord('q'):
break
释放摄像头的手柄:
# Release handle to the webcam
video_capture.release()
cv2.destroyAllWindows()
输入和输出
在训练过程中提供给模型的样本输入…。
输入

用于训练代码的样本图像

样本输入图像进行训练
输出:
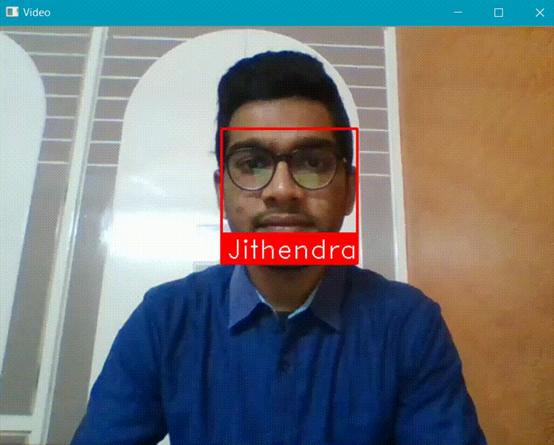
记录输出
代码参考:https : //github.com/eazyciphers/deep-machine-learning-tutors
参考文献:
https://www.pyimagesearch.com/2018/09/24/opencv-face-recognition/
https://www.superdatascience.com/blogs/opencv-face-recognition
https://zh.wikipedia.org/wiki/Facial_recognition_system
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~