数据异常分析找不到原因,注意这些!
共
1410字,需浏览
3分钟
·
2020-08-25 02:37
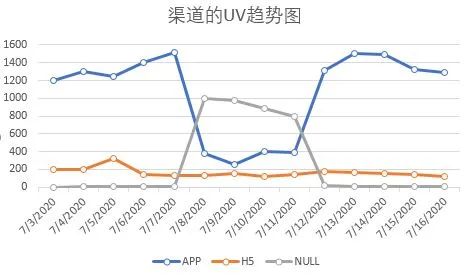
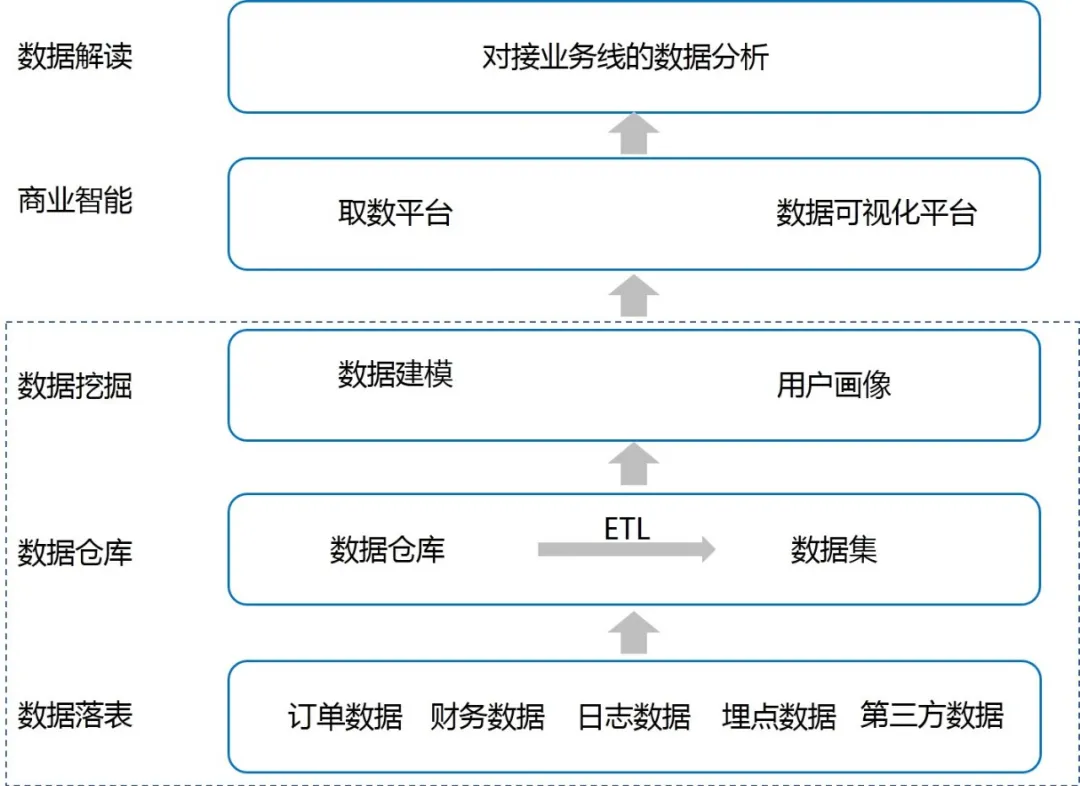
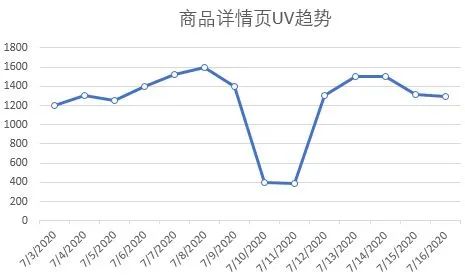
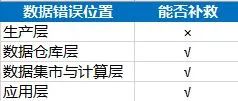
现在工作中数据分析技能需求日益增长,运营人员,HR,产品经理等都要会数据分析。你是否经历过指标异常了,分析找了半天找不到原因在哪里,各个方面都排查了,然后跟老板反馈说“我也没找到具体原因”,老板冷冰冰的眼神看着你,“要你何用”,你心中有苦说不出。其实你可能忽略了一个数据分析的基础:数据是要准确的,在分析异常之前一定要先确认数据是否准确。如同盖楼一样,地基有问题,楼盖的再高再好看是不稳定。场景1:上周业务线的流量环比上上周下降10%,对比另外2条业务线都是上涨10%,现在是暑期旅游热度逐渐起来,不太符合趋势,然后根据之前的分析框架,从流量来源以及效率方面都做了检查,没有找到原因。最后想起来没有先去数据层上确认下是否正常,最终定位到常用口径中有个筛选字段渠道中出现了20%左右的空值导致进行筛选条件时部分记录被过滤掉。场景2:这周在看产线的漏斗结果时,发现APP渠道订单转化率环比下跌30%, 在漏斗流程中是填写页到提交订单环节丢失的。由于前面case的经验,我有点怀疑数据的准确性了。理论上不会有这么大的波动的;我先找提交失败报错数量没有明显变化,推测可能是数据异常,然后询问产品经理最近有无什么变动,得知是最近是在做小程序页面测试,导致APP上订单被记在小程序渠道上。作为数据终端的使用方,我们有时是不知道这个数据是怎么来的,使用上难免有黑盒子的感觉。需要对一般互联网企业的数据生产流程有基础了解以及数据错误的预判。从最上游生产环境中产生数据源表层,到数据仓库对数据进行抽取,转换和清洗(也就是ETL)成结构化的基础数据表的形式,然后数据仓库再串联各类维表形成业务方使用的专项数据表,数据表开放给各个业务方以及分析师们使用。那么涉及到生产环节1个,加工环节有2个,使用环节1个,都会有产生脏数据的可能性。A: 看具体异常数据前,一定要先确认自己的取数口径是否正确;-数据敏感度。也就是凭经验和对数据的直觉,这个往玄乎里说就是第六感,接地气的意思就是你每天接触这个数据,知道数据的变动背后的业务含义,当它异常时,你是会察觉出来的,后面会单独有帖子来分享跟数据敏感度相关话题。-交叉确认值。那么如果承认自己无法确定这个异常,那么需要额外的信息来降低这个不确定性。我们可以找其它数据源交叉比对的方式来判断这个数据是否异常;举个例子:你可以百度上的尺子功能来测量两个点之间的距离(地铁站到售票处的距离)是否如别人说的那么近2公里左右。-趋势变化数据;可以做一张这一值的趋势图,如果一直很平稳突然有个较大的拐点(环比下降50%以上),那就很有可能是错误值。A: 那么由于数据对于工作中决策很重要,这一数据脏了,还能补救吗?答案是因数据供应链中的位置而异;也可以通过这个图对数据进行归类,生产层上的是不可再生数据,其它层面是属于再生数据。
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报


 下载APP
下载APP