
Python入门系列24 - 正则表达式(二)
Python入门系列24

正则表达式(二)
本篇阅读时间约为 11分钟。
1
前言
今天继续来介绍一下python的正则表达式,回顾一下上次介绍的re模块整篇文章围绕着re.findall()来进行实例的讲解,也就是所谓的查询操作。为了便于回顾,这里给出链接:python入门系列23 - 正则表达式(一)
2
re模块的sub函数
sub:中文有代替的意思。使用re.sub()可以完成我们对原始字符串的替换操作!
先来看下官方函数的参数解释:
re.sub(pattern, repl, string, count=0, flags=0)
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
flags : 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。(如:re.I 使匹配对大小写不敏感)
一大波实例来袭,做好准备哟!
实例1(替换普通字符):
假设我数学和英文考试都得了60分……然而我并不甘心,上天给了我一次作弊的机会,可以通过程序来替换分数!如何做呢?
import re
words = 'My math scored 60 points,My English has also scored 60 points.'
# 可以看到我的count参数给出的是0# 默认匹配所有60分,修改为100分
new_words = re.sub('60','100',words,0)
print(new_words)
>>> My math scored 100 points,My English has also scored 100 points.同理,若是只想修改数学成绩,则将count参数改为1即可:
实例2(有逻辑的函数替换):
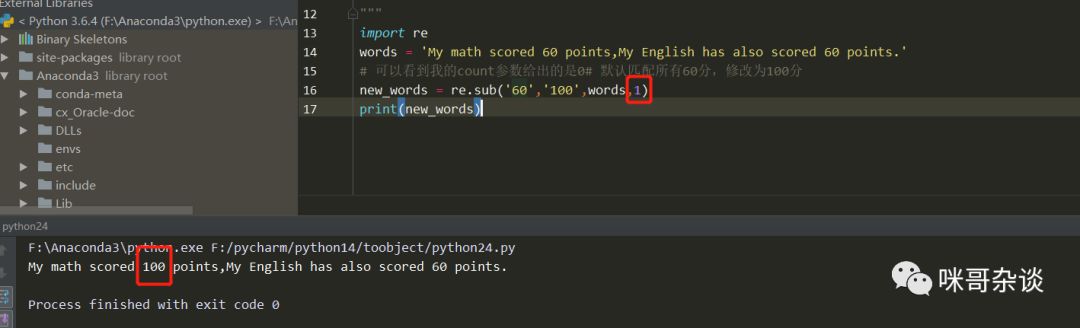
假设我的数学成绩考了85分!emmm相当不错了,但是我依然想让它增加5分,我爱数学!而英语这次考了100分,因为作弊了……为了不让老师察觉,我决定偷偷降低点分数!两种条件,如何才能使用sub函数来完成呢?别忘了我们的repl(replace)参数是可以传递函数的!这也是Python的一个特性,参数可以传递函数,如下:
import re
def modify_score(score):
print(score)
new_socre = score.group()
if int(new_socre) == 85:
return '90'
if int(new_socre) == 100:
return '80'
words = 'My math scored 85 points,My English scored 100 points.That\'s cool!'
new_words = re.sub('\d{2,3}',modify_score,words,0)
print(new_words)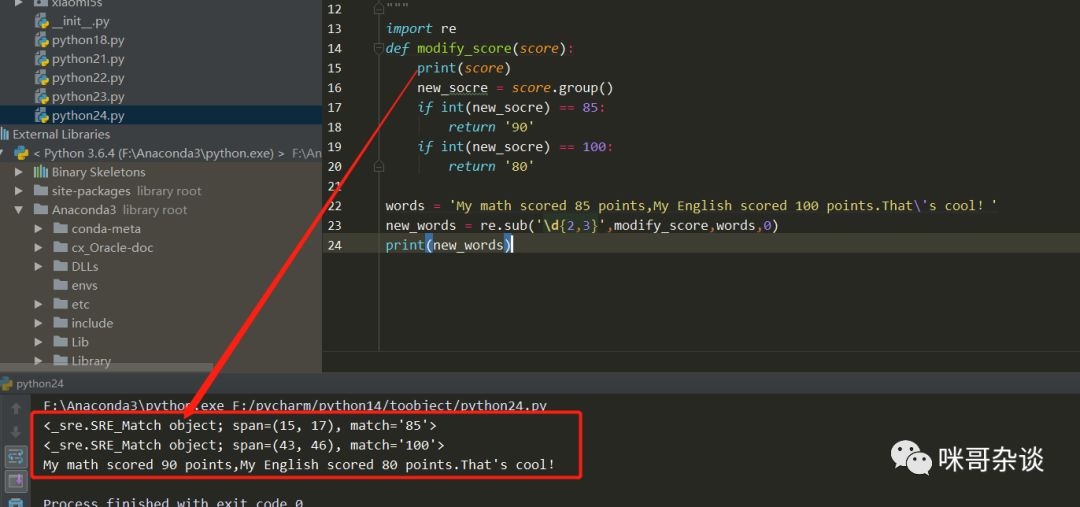
讲解一下:在modify_score中,使用传入score,可以打印输出看下它的类型,这是一种正则的类型,而非字符串类型。此类型要将其内容本身匹配出来,则需要调用它的group()方法,new_score取出来的便是数字形式的字符串。下面的逻辑对比,需要将字符串转换为int型,才可以进行对比操作,否则会报错哟。
综上所述: re.sub()可以轻松的实现字符串的替换,并且可以用函数传递的方式来对原始字符串进行业务逻辑的判断。
3
re模块其它常用函数
1. match
依然是用事例来解释看下:
import re
words = 'My math scored 85 points,My English scored 100 points.That\'s cool!'
new_words = re.match('\d{2,3}',words)
print(new_words)
>>> None上述结果,打印为None,Why???
因为match函数在进行匹配的时候,是从字符串的起始开始进行匹配,若开头的字符串不符合正则表达式,则直接返回None,也就是什么都没匹配到,停止后续匹配。
所以如果修改words,让我们的分数在字符串开头试下:
2. search
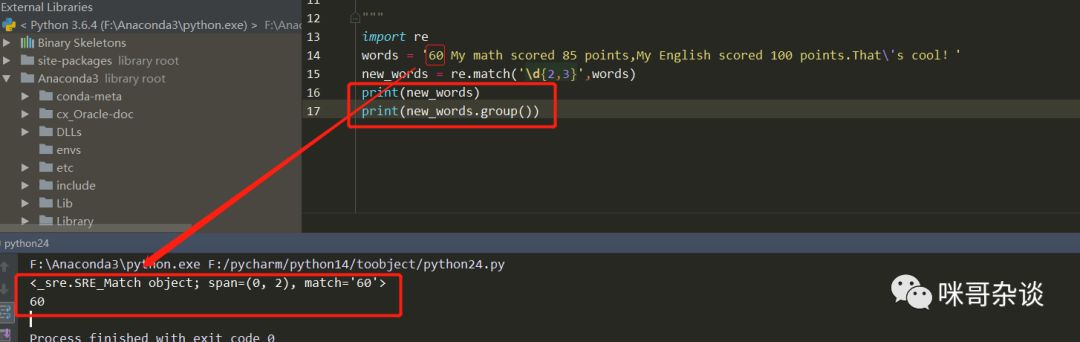
使用search的示例如下:
import re
words = 'My math scored 85 points,My English scored 100 points.That\'s cool!'
new_words = re.search('\d{2,3}',words)
print(new_words)
print(new_words.group())
>>> <_sre.SRE_Match object; span=(15, 17), match='85'>
>>> 85上述结果,打印出了匹配到的对象与值,与match不一样!但是可以看到,search函数只匹配到了一次的,后续分数的100即使符合正则表达式,也不会被匹配到了。
match和search函数是当今市场上各教程类中,写爬虫最常用的两个方法,而实际上这两个函数是需要对匹配后的结果进行group分组处理,才能取出你想要的结果。在上节的小课堂中,全篇讲到的findall方法,则不需要进行group的调用,可以直接将结果以list全面匹配出来,这也是findall和match、search函数最大的区别。
4
group分组
既然提到了group分组,那么就来介绍下,group的具体用法,以及在爬虫中经常会以一种什么样的方式去进行你想要的匹配!
此处以search函数来举例,场景是酱紫的:我自己说了一句话 ,「我在这次考试中,数学分数考了85,英语分数考了100分,这真是太酷了!」。现在需要将「英语分数考了100分」获取到!代码如下:
import re
words = 'My math scored 85 points,My English scored 100 points.That\'s cool!'
new_words1 = re.search('points,\wThat',words)
new_words2 = re.search('points,\w*That',words)
new_words3 = re.search('points,.*That',words)
new_words4 = re.search(',(.*)That',words)
print(new_words1.group())
print(new_words2.group())
print(new_words3.group())
print(new_words4.group())仔细看过代码的同学,肯定会疑惑为什么写了这么多行正则匹配的表达式,莫急莫急,且听我慢慢道来。在不看我下面的解释前,你认为,下面这四个print()会依次打印出什么样的结果呢?
解释:其实new_words1~4是一段非常有逻辑的演变过程。
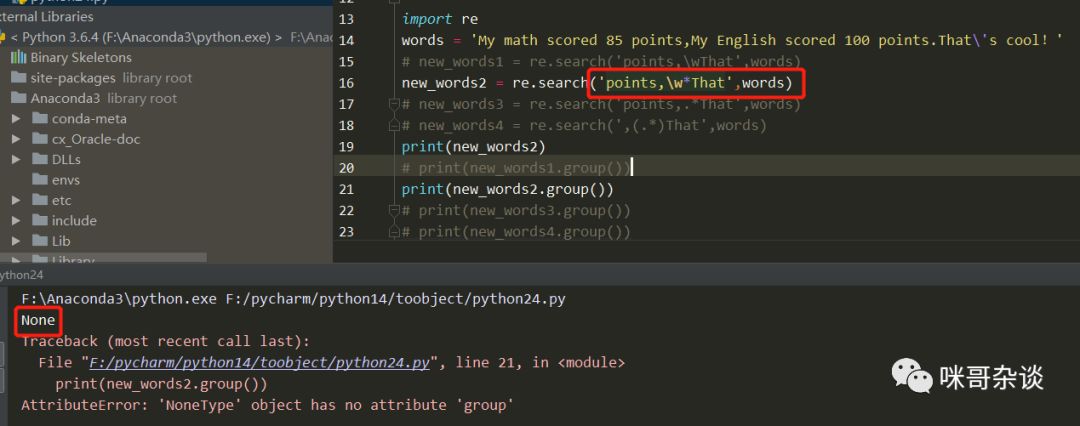
① 先来看new_word1,如果想要匹配我英语分数考了100分这段英文字符,需要先使用普通字符串进行边界的限定,还记得吗?(上节小课堂有说过哦!忘了的话回到文章首处点击链接进行回顾。) 所以使用"ponit, "和"That"进行边界限定,一旦边界限定后,便可以使用元字符来进行内容的匹配,而\w代表的含义是匹配包括下划线的任何单词字符。于是调用如下图:
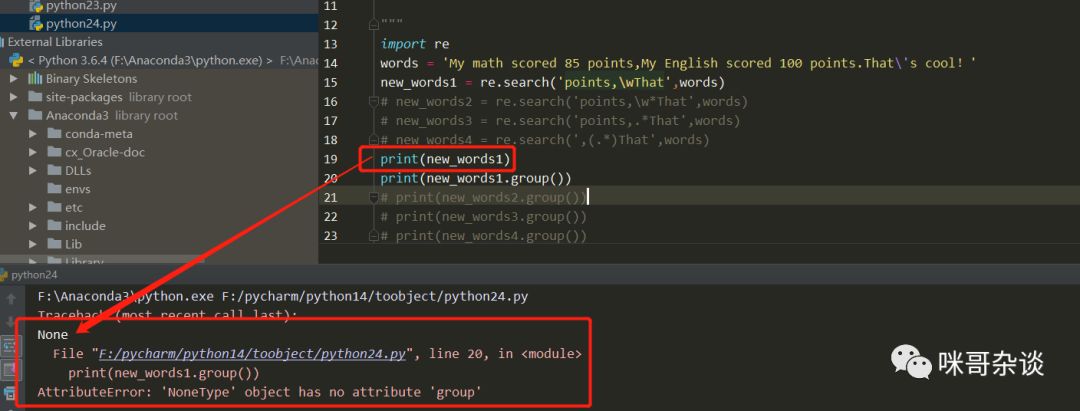
可以看到报错啦,错误说的是None类型没有group方法,因为1中的正则是错误的,没有正确进行匹配,所以最终得到的值是None。理由很简单,因为\w这样的写法只进行了单字符匹配,故然是不行的。如何进行多字符匹配呢?于是有了new_word2。
② 来看new_word2,普通字符的边界限定写法是不变的,在原来的基础上,在\w后面新增*。*的元字符代表的含义是匹配前一个字符0次或n次以上。然后有了下图:
为毛还是报错?然后在反思下,发现。。。哦原来是想匹配的字符串中是包含空格的,而\w是不能匹配到空格字符的,所以这个正则表达式的写法依然不对!再继续,什么元字符可以进行空格和字母的匹配呢?于是有了new_words3。
③ new_words3中使用的是.来进行空格和字母的匹配,点的后面还是使用*来匹配。如下图:
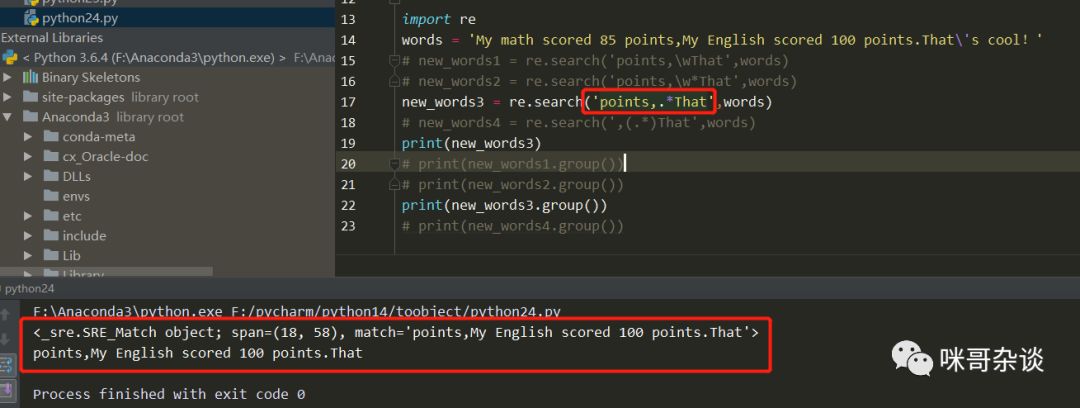
可以看到正确的结果了,终于没有报错了!但是呢,但是呢,但是呢。。。会发现,匹配到的结果却不是我想要的最终结果,它把整个正则表达式的限定边界也匹配到了...于是再次改进,就有了最后的new_words4。
④ new_words4是在③的基础上,除去了边界字符的限定,将.*用小括号扩了起来,此处就是在上节小课堂中提到的分组!而一旦分好组之后,我们便可以通过group将自己定义好的分组提取出来,清理下以上注释掉的代码:
import re
words = 'My math scored 85 points,My English scored 100 points.That\'s cool!'
new_words4 = re.search(',(.*)That',words)
print(new_words4)
print(new_words4.group())
print(new_words4.group(0))
print(new_words4.group(1))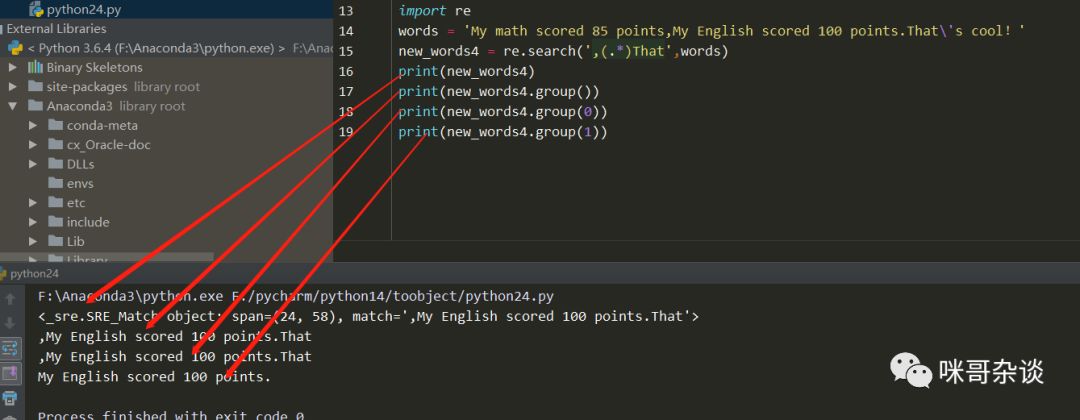
不难发现,其实group()中是可以传递数字的,默认情况下不写等同于0,可以看到上图不写和写0是一个输出结果。这里需要说下,为什么0匹配出来的是整段正则表达式的字符串,而不是我想要的“My English scored 100 points.”这句话。先来看下两段代码:
new_words4 = re.search(',(.*)That',words)new_words5 = re.search('(,(.*)That)',words)实际上,new_words4是等效于new_words5的,在new_words5中默认的正则参数位置是有一层隐形的小括号,也就是最外面的组,所以当我们调用group(0)或者group()实则是指这层组的关系。
若想调用组中组,需要从左到右,数字是从1开始进行调用的,和上面的代码结果图的最后一行是对应上的!
5
总结
到这里,关于Python的正则表达式常用的几点也就介绍完了,为什么要讲述正则呢?因为这是处理字符串文本必不可少的一个强大工具!只要能得心应手的使用它,相信不论是在处理爬虫想要的信息也好,数据清洗时处理也罢,都可以轻松玩转字符串!
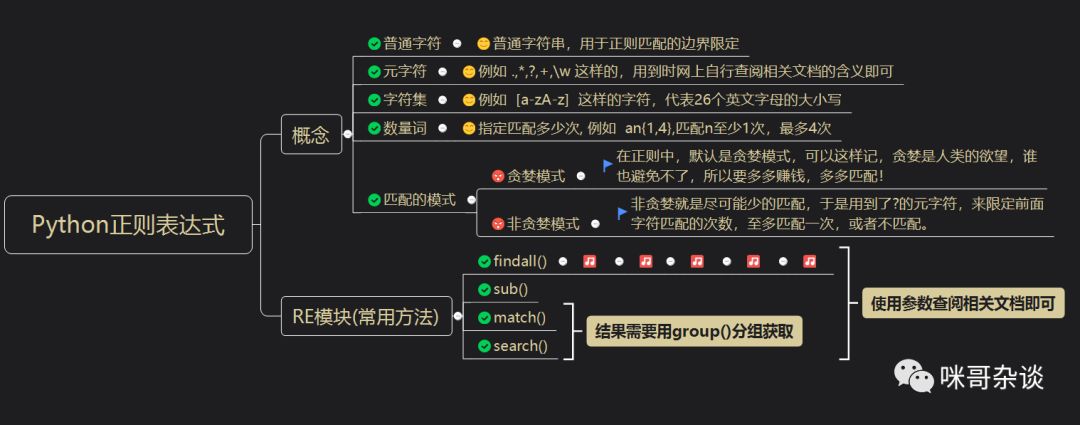
用思维导图来回顾下正表达式的所有常用知识点吧,所谓一图胜过千言万语,毕竟可以来梳理思路:
至此完!