
最强无监督行人重识别方法 Cluster Contrast ReID,精度超越有监督算法

极市导读
本文提出了无监督Cluster Contrast ReID,在Market1501上跑到了rank-1 94.6%,已经超越了很多有监督的算法。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
介绍
在行人重识别领域,如何获取海量标注数据,提高实际场景的重识别能力是工业界非常关注的一个问题。通常在学术界上公开数据集如Maket1501上训练出来的模型在实际场景上基本是没法用的,都需要在实际场景中采集数据并进行标注。标注需要人工成本和时间周期,在项目比较急的时候重新标注根本来不及,因此无监督的行人重识别方法成为了目前研究的一个热点。
无监督行人重识别已经有很多人在研究了,目前最好的方法是SPCL(葛艺潇:NeurIPS 2020 | 自步对比学习: 充分挖掘无监督学习样本), 在使用了Generalized Mean Pooling (GEM)之后,在Market1501数据集上达到了rank-1 89.5% 的效果,效果很好,但是和有监督的方法,如Resnet50 + Circle loss (https://github.com/layumi/Person_reID_baseline_pytorch#trained-model) rank-1 92.13% 或者 OSNet (https://kaiyangzhou.github.io/deep-person-reid/MODEL_ZOO) 94.2% rank-1相比仍然有一些差距。SPCL提供了一个很强的unsupervised reid pipeline,可以启发我们去进行更深一步的探索。基于此,我们提出了无监督Cluster Contrast ReID,在Market1501上跑到了rank-1 94.6%,已经超越了很多有监督的算法。在其他行人重识别数据集如Duke和MSMT17数据集上,也比最先进无监督re-ID方法mAP提高了7.5%,6.6%。
论文链接:
Cluster Contrast for Unsupervised Person Re-Identification
https://arxiv.org/abs/2103.11568
代码连接:
https://github.com/alibaba/cluster-contrast-reid
方法
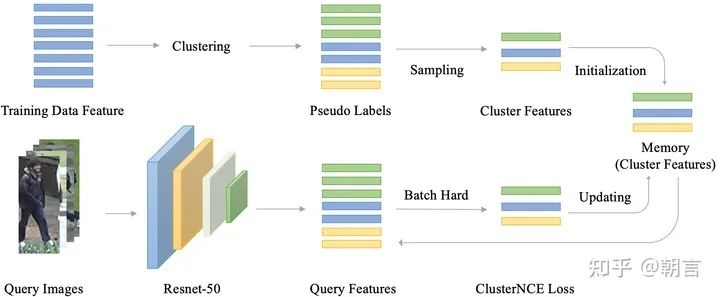
首先来看一下整个无监督reid的pipeline, 大致可以分成三个部分。第一个部分就是特征提取,在每一个epoch开始的时候,通过网络将训练数据集中图片的特征都提取出来。第二部分是聚类,通过传统的聚类方法如DBScan, KNN通过特征把图片聚成不同的类别,每个类别给一个标签,就是用来训练的伪标签。一开始的伪标签是很不准的,在训练的过程中,随着网络的精度越来越高,伪标签也会越来越接近真实标签。第三部分就是图片特征的存储和更新,在网络训练的过程中,随着网络参数的变化,图片的特征也需要进行对应的更新。在训练的时候,我们因为有了伪标签,就能够通过类似于softmax的分类函数来对网络进行训练。因为伪标签在每次聚类的时候都会发生变化,所以无监督reid用的是non-parametric softmax loss。我们用的是moco用的里面的InfoNCE loss来进行训练。
我们发现,图片特征的存储和更新对于网络的训练影响很大。一个最简单的直觉就是,在一个行人重识别数据集中,不同的人拥有的图片数量是不一样的,如果按照训练的图片来更新feature的话,拥有大量图片的人的feature将会滞后更新,从而有害网络优化。所以ClusterContrast的核心思想就是,我们不再是从图片的层面上去更新特征和计算loss, 而是从人的维度去更新和计算loss。无论一个人有多少张图片,对于网络训练来说,他们都是一视同仁的,都是用同一个速度去更新特征。在无监督reid中,每个人都被聚类成一个cluster,所以我们的方法叫做ClusterContrast。具体可以参加下图:
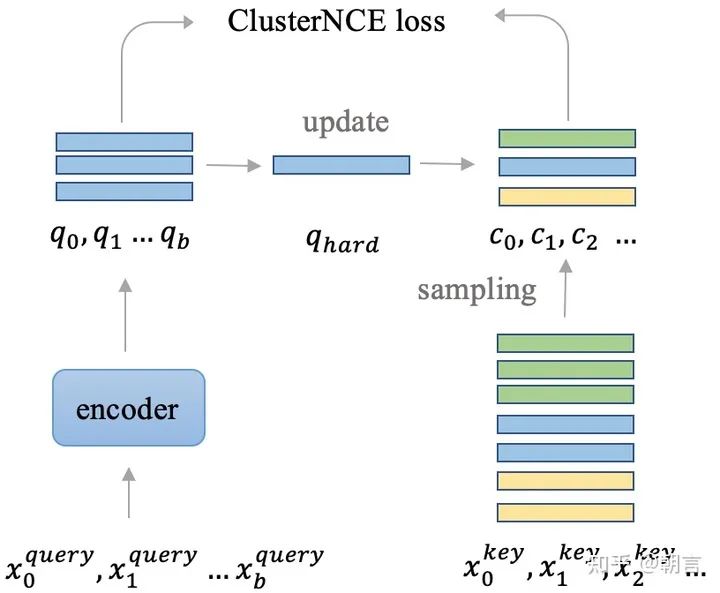
在这张图中,相同颜色的图片是属于同一个人的。对于一个人,不管他有多少张图片,我们只会从里面选一张图片的feature存起来。怎么选这一张图片也是有很大的讲究的?就像batch hard triplet loss一样,我们发现选择和之前存起来的feature最不相似的feature效果最好,这样能够让网络去挖掘一些难样本。和之前的方法的对比可以参见下图:
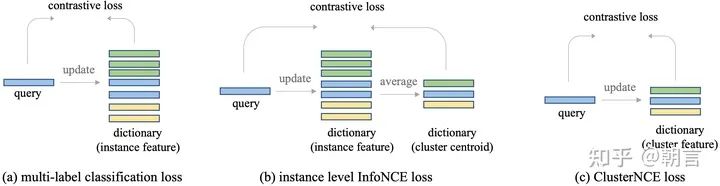
我们可以看到ClusterContrast非常简洁,使用了最少的显存,取得了最好的效果。
结果
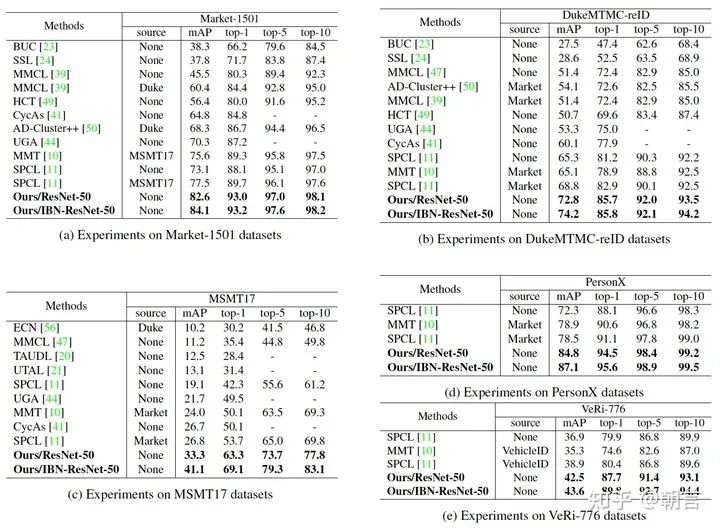
我们在各个数据集上,包括车辆重识别数据集上都大大超越了现有的无监督重识别方法。为了公平比较,我们在图表中并没有使用一些常见的提点方法如 Generalized Mean Pooling (GEM), reranking。用了GEM之后网络性能能进一步提升,能够超越很多有监督的方法:
Market1501
| Method | mAP | Rank-1 | Rank-5 | Rank-10 |
|---|---|---|---|---|
| ClusterContrast | 84.1 | 93.2 | 97.6 | 98.1 |
| ClusterContrast + GEM | 87.0 | 94.6 | 98.2 | 98.8 |
DukeMTMC
| Method | mAP | Rank-1 | Rank-5 | Rank-10 |
|---|---|---|---|---|
| ClusterContrast | 74.2 | 85.8 | 92.1 | 94.2 |
| ClusterContrast + GEM | 76.0 | 86.8 | 93.1 | 94.7 |
总结
我们提出了Cluster Contrast 方法,核心就是在人的维度上去进行特征的提取和更新,从而将特征的更新速度与图片数量进行解耦,让算法工程师能够在ID的层面对模型进行调优。Custer Contrast超越了现有的所有无监督行人重识别方法,无监督域自适应行人重识别方法和相当一部分有监督的方法。Cluster Contrast简洁且效果好,代码已经开源,希望我们的方法能够带给广大重识别研究者一些启发,让行人重识别更好的落地在实际场景中。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“何恺明”获取何恺明顶会分享资源~
YOLO教程:YOLO系列(从V1到V5)模型解读|YOLO算法最全综述:从YOLOv1到YOLOv5
实操教程:使用Transformer来做物体检测?DETR模型完整指南|PyTorch编译并调用自定义CUDA算子的三种方式
算法技巧(trick):半监督深度学习训练和实现|8点PyTorch提速技巧汇总
最新CV竞赛:2021 高通人工智能应用创新大赛|CVPR 2021 | Short-video Face Parsing Challenge

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
