
23.kafka心中的事件溯源

1 楔子
早些年,我还在学校学习DB的时候,设计表结构是件非常严肃和讲究范式的事。那时天是蓝的水是绿的,存储系统很昂贵,程序员还是一个体面的职业,大学生对生活充满了期望,即使找不到工作,去科技市场卖光盘也能获得一笔不错的收入。那时数据存储以企业ERP为主,程序员为了把尽可能多的数据塞入到狭小的存储空间中,往往需要亲手榨干最后一滴脑汁,尽可能把表字段设计成正交的。
后来,互联网兴起,大学生扩招,存储便宜了,房价也上涨了。为了支撑越来越多的OLTP线上业务查询,人们开始接受在DB表中冗余部分数据,同时索引也越建越多,以便缩短从用户点击鼠标到看到数据之间的响应延时。
后来,移动互联火热,研究僧扩招,京牌京户成为传说。为了帮老板挣到二房的钱,微服务和996兴起。单一的MySQL存储已经不能满足我们的服务热情,我们会额外提供Cache加速数据读取,提供Index方便全文检索,提供汇总数据方便领导做PPT。并且由于PM学历稳步提高,他们的思维也更加开阔,不再拘泥于从国人身上抄袭。为了满足各类思想实验,程序员必须能以更快更敏捷的方式提供数据逻辑。时至今日,996已经逐渐不能满足人民日益增长的物质文化需要,997开始发出时代的呐喊,逐渐成为主流。
这中间遇到的一个千古难题是:如何保证MySQL, Redis, ElasticSearch, Hive等不同平台的数据一致性?一代又一代的程序员用自己的发量证明这根本可能是一个NP问题:2PC既慢又脆弱,TCC对业务逻辑要求太高,Cache Aside只能勉强解决缓存一致性问题。
看着手上逐渐失去效用的维生素E乳,程序员突然觉得,是不是应该对自己好一点?
程序员满含热泪,跪在佛像面前,请大师解惑。大师递给程序员一张纸条,上书三个大字:fit your life。程序员恍然大悟,抬头问大师:『您的意思是要我健身?』。大师说:『你误会了,我的意思是说你们平时用的Kafka,配合Event Sourcing(事件溯源),就能很好的解决现在的问题,但关键是FIT』
FIT = Future + Isolation + Transaction
2 Future:对未来的自己好一点
简单设计的DB一般只保存数据项的当前状态值,而Event Sourcing(事件溯源)构架,则以记录event的方式,把数据项的完整更迭历史保存下来。这样,我们不仅可以查到的数据的当前状态值,而且可以通过完整历史,重演数据项的变化过程。
这项技术,以前多用户于金融领域,毕竟金融需要审计的嘛。后来,被引入到微服务设计模式中,但是,由于实现复杂,且思考方式迥异于常人,口号响亮,应者了了。
但是,在加入Kafka之后,一切都不一样了。上一期文章《22.神说,kafka其实是个数据库》中,简单提到过这一点,当时我把它称为事件流(event stream)。这里重新引用一下:
事件流(event stream)提供了一种新的思路:以Kafka为例,应用server将操作以事件的方式追加log到消息队列中,待修改的DB, Cache和Index分别在不同的消费组内消费相同的event log。如果在消费过程中,其中某一个进程crash了,则等待进程重启后,从最后一次消费的offset处继续消费就可以了。
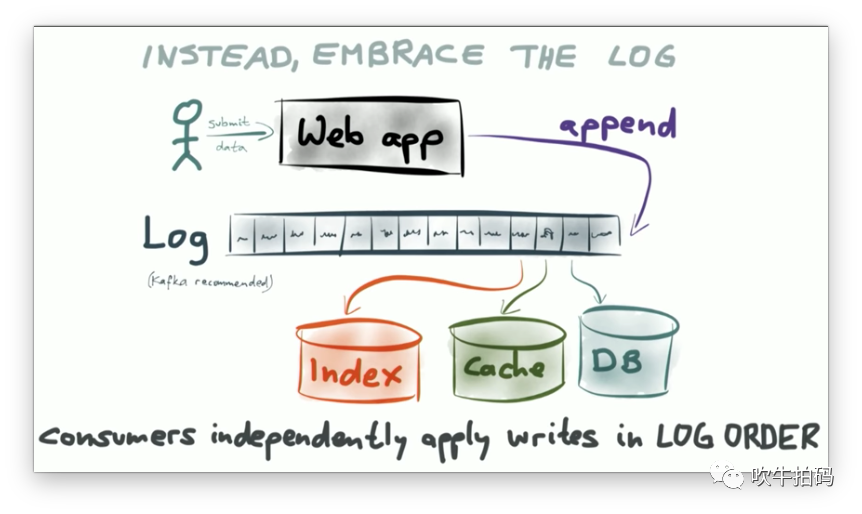
上图中的Index, Cache, DB,我们有时把它们统称为Materialized Views(物化视图),它们是同一数据的不同展示形式,用于支持不同的查询。
Event Sourcing优点之一是:对于重要数据,我们可以在Kafka中保存完整的历史更迭记录。在未来任意时刻,无论PM提出什么新需求,都可以通过编写新的代码,并重新订阅这一主题而生成想要的结果,同时对系统的其它部分毋需任何改动和影响。
而对于没那么重要的数据,比如崩溃日志,也许我们只需要保存最近7天的数据,确保运维安全就可以了。这样,万一上线的代码有bug,或者消费进程意外崩溃了,7天的数据可以给我们留出足够的时间修复bug,并重新跑一遍近期的数据,拿到正确的结果。
3 Isolation:读写分离
看到这里,你也许会觉得Isolation对标读写分离有些怪怪的,其实我也觉得怪怪的。读写分离在中国一般指MySQL写走主库,而读走从库。在本篇文章中,读写分离的等价物实际上是CQRS(Command Query Responsibility Segregation)。
但是,我仍然愿意把它称为Isolation,因为它能帮我凑出一个单词FIT来。在任何时候,让人们容易记忆,比表述准确要重要的多。而且,反正我的文章也几乎没写过什么正经的东西,凑合看吧。
读写分离的重点是:读不关心写,写操作毋需为读操作做索引优化。
这太重要了。现行的微服务架构中,一个初看很美,静看心痛,细看白头的问题是:读和写都依赖同一台MySQL数据库,为了支撑越来越复杂的查询逻辑,不断的往数据表上加索引。而索引越来越多的问题至少包括:
因为数据落库需要同步修改索引,写入的TPS越来越低。
索引挤占了大量本来可以存储数据的磁盘空间,结果本来可以存1T的数据,现在只能存500G了。
随着数据量变大,线上创建新索引越来越耗时,为了不影响线上业务,我们有时需要请出在线DDL工具,比如gh-ost。
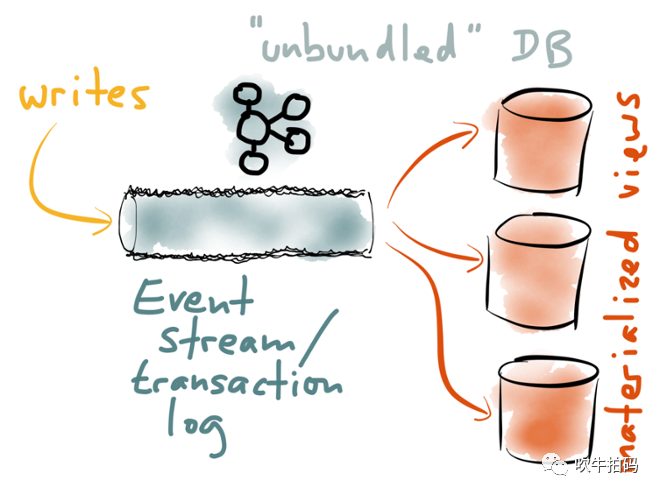
鲁迅说,专注的女孩子最美。在读写分离架构中,我们通过不同的Materialized Views(物化视图)支持不同的读业务,前置Kafka的作用只有收集事件流,因此可以独立优化,互不干扰。
4 Transaction:代替2PC
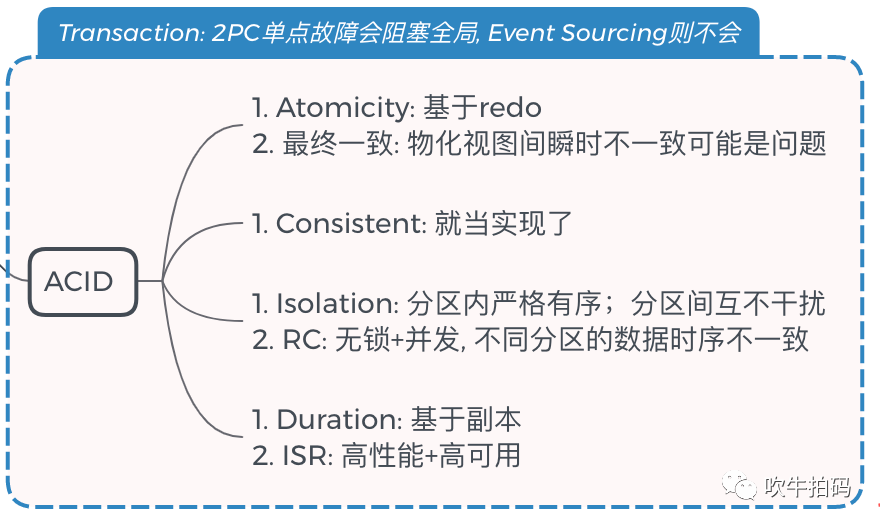
好吧,我承认我吹小牛了,2PC(两阶段提交)是非常重要原子提交协议,不是随随便便出来某一个路人Kafka就可以代替的。
但是,如果手动编码的话,2PC的性能和稳定性也是出了名的感时花溅泪。
延伸阅读《19.分布式事务之2PC:两阶段结婚》
基于Kafka的Event Sourcing架构,提供了一个以最终一致性为目标的高性能 &高可用的解决方案。废话不说,上图为敬。关于Kafka事务实现的更多细节可移步上一期文章《22.神说,kafka其实是个数据库》。
你不会以为最终一致性比线性一致性慢,对吧?
5 又挽救了一个程序员的发量
听完大师的讲述,程序员豁然开朗,感觉一条康庄大道出现在面前。程序员含着热泪转身走出大殿,后面大师默默地收起手里的剃刀,暗叹一声:『这个月的招人计划又完不成了』。突然,大师仿佛想起了什么,跑到大殿门口,对着已经走出大门的程序员高喊:『施主,看完记得点关注啊~』