
一个合格的中级前端工程师需要掌握的技能笔记(中)
Github来源:一个合格的中级前端工程师需要掌握的技能 | 求星星 ✨ | 给个❤️关注,❤️点赞,❤️鼓励一下作者
大家好,我是魔王哪吒,很高兴认识你~~
哪吒人生信条:如果你所学的东西 处于喜欢 才会有强大的动力支撑。
每天学习编程,让你离梦想更新一步,感谢不负每一份热爱编程的程序员,不论知识点多么奇葩,和我一起,让那一颗四处流荡的心定下来,一直走下去,加油,2021加油!欢迎关注加我vx:xiaoda0423,欢迎点赞、收藏和评论
不要害怕做梦,但是呢,也不要光做梦,要做一个实干家,而不是空谈家,求真力行。
前言
如果这篇文章有帮助到你,给个❤️关注,❤️点赞,❤️鼓励一下作者,接收好挑战了吗?文章公众号首发,关注 程序员哆啦A梦 第一时间获取最新的文章
JavaScript模块
性能
在原型链上查找属性比较耗时,对性能有副作用,这在性能要求苛刻的情况下很重要。另外,试图访问不存在的属性时会遍历整个原型链。
遍历对象的属性时,原型链上的每个可枚举属性都会被枚举出来。要检查对象是否具有自己定义的属性,而不是其原型链上的某个属性,则必须使用所有对象从 Object.prototype 继承的 hasOwnProperty
JavaScript中的相等性判断
抽象(非严格)相等比较 ( ==)严格相等比较 ( ===): 用于Array.prototype.indexOf,Array.prototype.lastIndexOf, 和case-matching同值零: 用于 %TypedArray%和ArrayBuffer构造函数、以及Map和Set操作, 并将用于ES2016/ES7中的String.prototype.includes同值: 用于所有其他地方
严格相等
===
var num = 0;
var obj = new String("0");
var str = "0";
var b = false;
console.log(num === num); // true
console.log(obj === obj); // true
console.log(str === str); // true
console.log(num === obj); // false
console.log(num === str); // false
console.log(obj === str); // false
console.log(null === undefined); // false
console.log(obj === null); // false
console.log(obj === undefined); // false
非严格相等 ==
var num = 0;
var obj = new String("0");
var str = "0";
var b = false;
console.log(num == num); // true
console.log(obj == obj); // true
console.log(str == str); // true
console.log(num == obj); // true
console.log(num == str); // true
console.log(obj == str); // true
console.log(null == undefined); // true
// both false, except in rare cases
console.log(obj == null);
console.log(obj == undefined);
并发模型与事件循环
JavaScript有一个基于事件循环的并发模型,事件循环负责执行代码、收集和处理事件以及执行队列中的子任务。这个模型与其它语言中的模型截然不同,比如 C 和 Java。
运行时概念-可视化描述
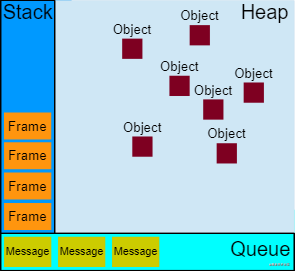
堆
对象被分配在堆中,堆是一个用来表示一大块内存区域的计算机术语。
队列
一个 JavaScript 运行时包含了一个待处理消息的消息队列。每一个消息都关联着一个用以处理这个消息的回调函数。
函数的处理会一直进行到执行栈再次为空为止;然后事件循环将会处理队列中的下一个消息(如果还有的话)。
内存管理
JavaScript是在创建变量(对象,字符串等)时自动进行了分配内存,并且在不使用它们时“自动”释放。释放的过程称为垃圾回收。
内存生命周期
分配你所需要的内存 使用分配到的内存(读、写) 不需要时将其释放\归还
JavaScript 的内存分配
示例:
var n = 123; // 给数值变量分配内存
var s = "azerty"; // 给字符串分配内存
var o = {
a: 1,
b: null
}; // 给对象及其包含的值分配内存
// 给数组及其包含的值分配内存(就像对象一样)
var a = [1, null, "abra"];
function f(a){
return a + 2;
} // 给函数(可调用的对象)分配内存
// 函数表达式也能分配一个对象
someElement.addEventListener('click', function(){
someElement.style.backgroundColor = 'blue';
}, false);
var d = new Date(); // 分配一个 Date 对象
var e = document.createElement('div'); // 分配一个 DOM 元素
var s = "azerty";
var s2 = s.substr(0, 3); // s2 是一个新的字符串
// 因为字符串是不变量,
// JavaScript 可能决定不分配内存,
// 只是存储了 [0-3] 的范围。
var a = ["ouais ouais", "nan nan"];
var a2 = ["generation", "nan nan"];
var a3 = a.concat(a2);
// 新数组有四个元素,是 a 连接 a2 的结果
垃圾回收:
引用计数垃圾收集 标记-清除算法
对象原型
理解对象的原型(可以通过Object.getPrototypeOf(obj)或者已被弃用的__proto__属性获得)与构造函数的prototype属性之间的区别是很重要的。前者是每个实例上都有的属性,后者是构造函数的属性。也就是说,Object.getPrototypeOf(new Foobar())和Foobar.prototype指向着同一个对象。
Object.prototype.valueOf()valueOf() 方法返回指定对象的原始值。
语法
object.valueOf()
返回值
返回值为该对象的原始值。
示例:
// Array:返回数组对象本身
var array = ["ABC", true, 12, -5];
console.log(array.valueOf() === array); // true
// Date:当前时间距1970年1月1日午夜的毫秒数
var date = new Date(2013, 7, 18, 23, 11, 59, 230);
console.log(date.valueOf()); // 1376838719230
// Number:返回数字值
var num = 15.26540;
console.log(num.valueOf()); // 15.2654
// 布尔:返回布尔值true或false
var bool = true;
console.log(bool.valueOf() === bool); // true
// new一个Boolean对象
var newBool = new Boolean(true);
// valueOf()返回的是true,两者的值相等
console.log(newBool.valueOf() == newBool); // true
// 但是不全等,两者类型不相等,前者是boolean类型,后者是object类型
console.log(newBool.valueOf() === newBool); // false
// Object:返回对象本身
var obj = {name: "张三", age: 18};
console.log( obj.valueOf() === obj ); // true
Object.is()
Object.is() 方法判断两个值是否为同一个值。
语法
Object.is(value1, value2);
示例:
Object.is('foo', 'foo'); // true
Object.is(window, window); // true
Object.is('foo', 'bar'); // false
Object.is([], []); // false
var foo = { a: 1 };
var bar = { a: 1 };
Object.is(foo, foo); // true
Object.is(foo, bar); // false
Object.is(null, null); // true
// 特例
Object.is(0, -0); // false
Object.is(0, +0); // true
Object.is(-0, -0); // true
Object.is(NaN, 0/0); // true
函数
在 JavaScript中,函数是头等(first-class)对象,因为它们可以像任何其他对象一样具有属性和方法。
IIFE是在函数声明后立即调用的函数表达式。
函数生成器声明 (
function*语句)
function* name([param[, param[, ...param]]]) { statements }
函数生成器表达式 (
function*表达式)
function* [name]([param] [, param] [..., param]) { statements }
JavaScript 数据类型和数据结构
最新的 ECMAScript 标准定义了 8 种数据类型:
6 种原始类型,使用 typeof 运算符检查:
undefined:typeof instance === "undefined"
Boolean:typeof instance === "boolean"
Number:typeof instance === "number"
String:typeof instance === "string
BigInt:typeof instance === "bigint"
Symbol :typeof instance === "symbol"
null:typeof instance === "object"。
Object:typeof instance === "object"。
JavaScript 中的类型包括:
Number(数字)
String(字符串)
Boolean(布尔)
Function(函数)
Object(对象)
Symbol(ES2015 新增)
JavaScript 中的类型应该包括这些:
Number(数字)
String(字符串)
Boolean(布尔)
Symbol(符号)(ES2015 新增)
Object(对象)
Function(函数)
Array(数组)
Date(日期)
RegExp(正则表达式)
null(空)
undefined(未定义)
表达式和运算符
function*
function* 关键字定义了一个 generator 函数表达式。
yield
暂停和恢复 generator 函数。
yield*
委派给另外一个generator函数或可迭代的对象。
值属性
Infinity
NaN
undefined
globalThis
Function 属性
eval()
isFinite()
isNaN()
parseFloat()
parseInt()
decodeURI()
decodeURIComponent()
encodeURI()
encodeURIComponent()
基本对象
Object
Function
Boolean
Symbol
错误对象
Error
AggregateError
EvalError
InternalError
RangeError
ReferenceError
SyntaxError
TypeError
URIError
Numbers & dates
Number
BigInt
Math
Date
文本处理
String RegExp
索引集合类
Array
Int8Array
Uint8Array
Uint8ClampedArray
Int16Array
Uint16Array
Int32Array
Uint32Array
Float32Array
Float64Array
BigInt64Array
BigUint64Array
Keyed collections
Map
Set
WeakMap
WeakSet
WeakMap
WeakMap 对象是一组键/值对的集合,其中的键是弱引用的。其键必须是对象,而值可以是任意的。
WeakSet
WeakSet 对象允许你将弱保持对象存储在一个集合中。
结构化数据
ArrayBuffer
SharedArrayBuffer
Atomics
DataView
JSON
控制抽象化
Promise
Generator
GeneratorFunction
AsyncFunction
反射
Reflect
Proxy
Generator
生成器对象是由一个 generator function 返回的,并且它符合可迭代协议和迭代器协议。
语法
function* gen() {
yield 1;
yield 2;
yield 3;
}
let g = gen();
// "Generator { }"
方法
Generator.prototype.next()
返回一个由 yield表达式生成的值。
Generator.prototype.return()
返回给定的值并结束生成器。
Generator.prototype.throw()
向生成器抛出一个错误。
一个无限迭代器
function* idMaker(){
let index = 0;
while(true)
yield index++;
}
let gen = idMaker(); // "Generator { }"
console.log(gen.next().value);
// 0
console.log(gen.next().value);
// 1
console.log(gen.next().value);
// 2
// ...
Generator.prototype.next()
next() 方法返回一个包含属性 done 和 value 的对象。该方法也可以通过接受一个参数用以向生成器传值。
语法
gen.next(value)
使用 next()方法
function* gen() {
yield 1;
yield 2;
yield 3;
}
var g = gen(); // "Generator { }"
g.next(); // "Object { value: 1, done: false }"
g.next(); // "Object { value: 2, done: false }"
g.next(); // "Object { value: 3, done: false }"
g.next(); // "Object { value: undefined, done: true }"
向生成器传值
第一次调用没有记录任何内容,因为生成器最初没有产生任何结果。
function* gen() {
while(true) {
var value = yield null;
console.log(value);
}
}
var g = gen();
g.next(1);
// "{ value: null, done: false }"
g.next(2);
// 2
// "{ value: null, done: false }"
Proxy
Proxy 对象用于创建一个对象的代理,从而实现基本操作的拦截和自定义
语法
const p = new Proxy(target, handler)
const handler = {
get: function(obj, prop) {
return prop in obj ? obj[prop] : 37;
}
};
const p = new Proxy({}, handler);
p.a = 1;
p.b = undefined;
console.log(p.a, p.b); // 1, undefined
console.log('c' in p, p.c); // false, 37

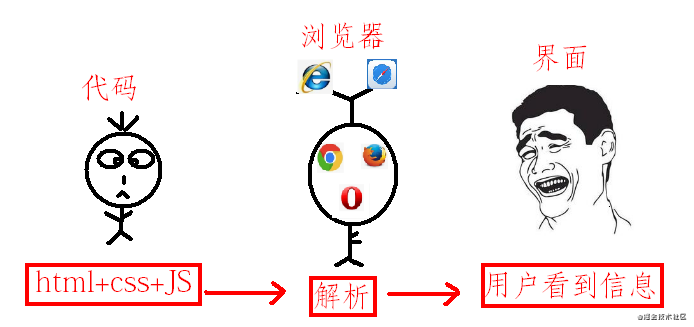
构造函数-实例-原型之间的关系
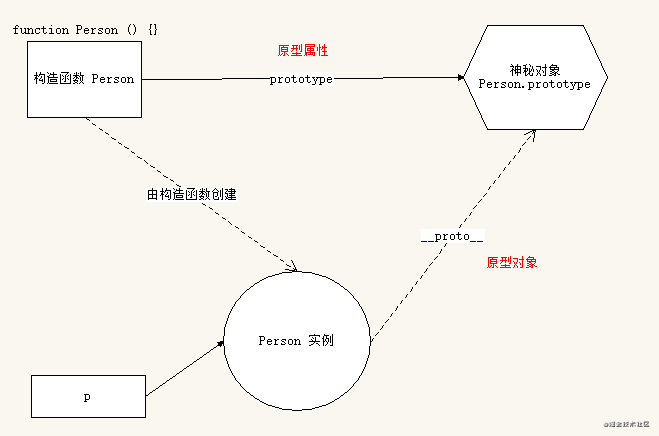
作用域
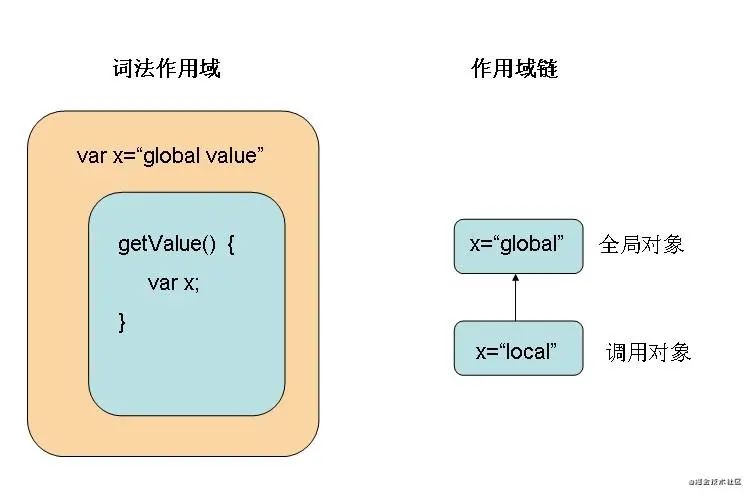
普通类型的存储方式

引用类型的存储方式
函数柯里化是一个为多参函数实现递归降解
示例:

map方法

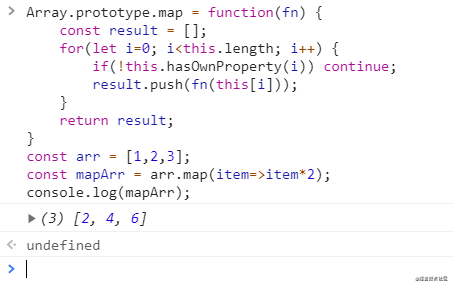
filter方法

reduce方法

every方法

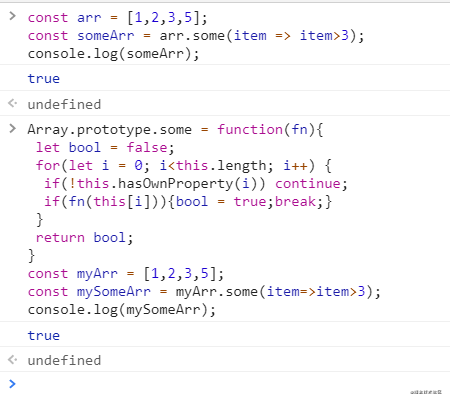
some方法
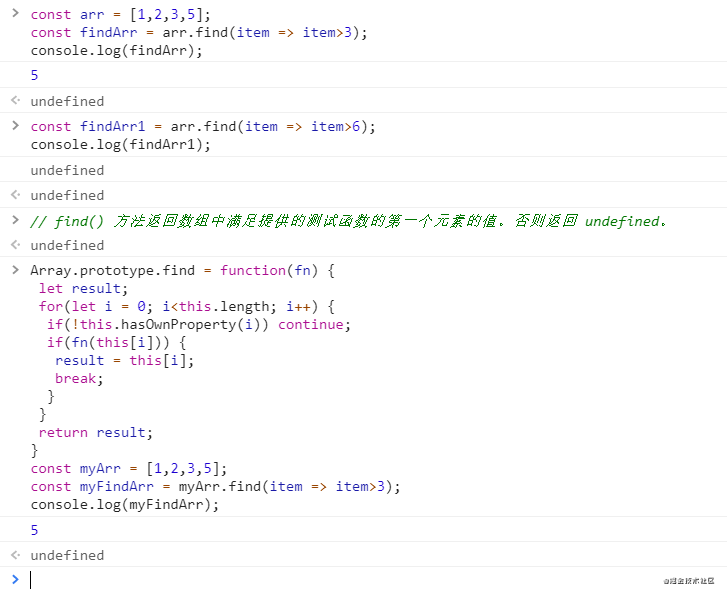
find方法
数组扁平化
利用ES6语法flat(num)方法将数组拉平。使用递归...。
HTTP模块
HTTP是一种能够获取如 HTML 这样的网络资源的 protocol(通讯协议)。它是在 Web 上进行数据交换的基础,是一种 client-server 协议,也就是说,请求通常是由像浏览器这样的接受方发起的。一个完整的Web文档通常是由不同的子文档拼接而成的,像是文本、布局描述、图片、视频、脚本等等。
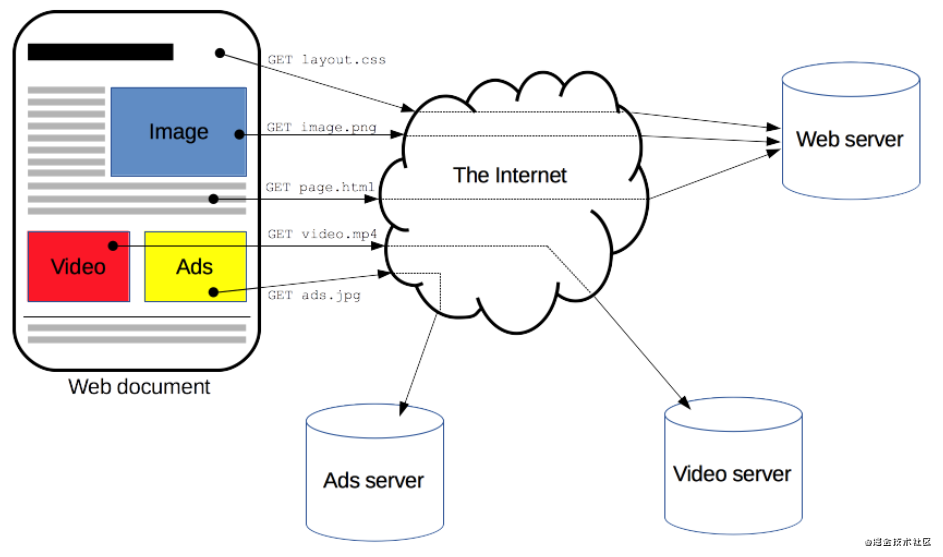
客户端和服务端通过交换各自的消息(与数据流正好相反)进行交互。由像浏览器这样的客户端发出的消息叫做 requests,被服务端响应的消息叫做 responses。
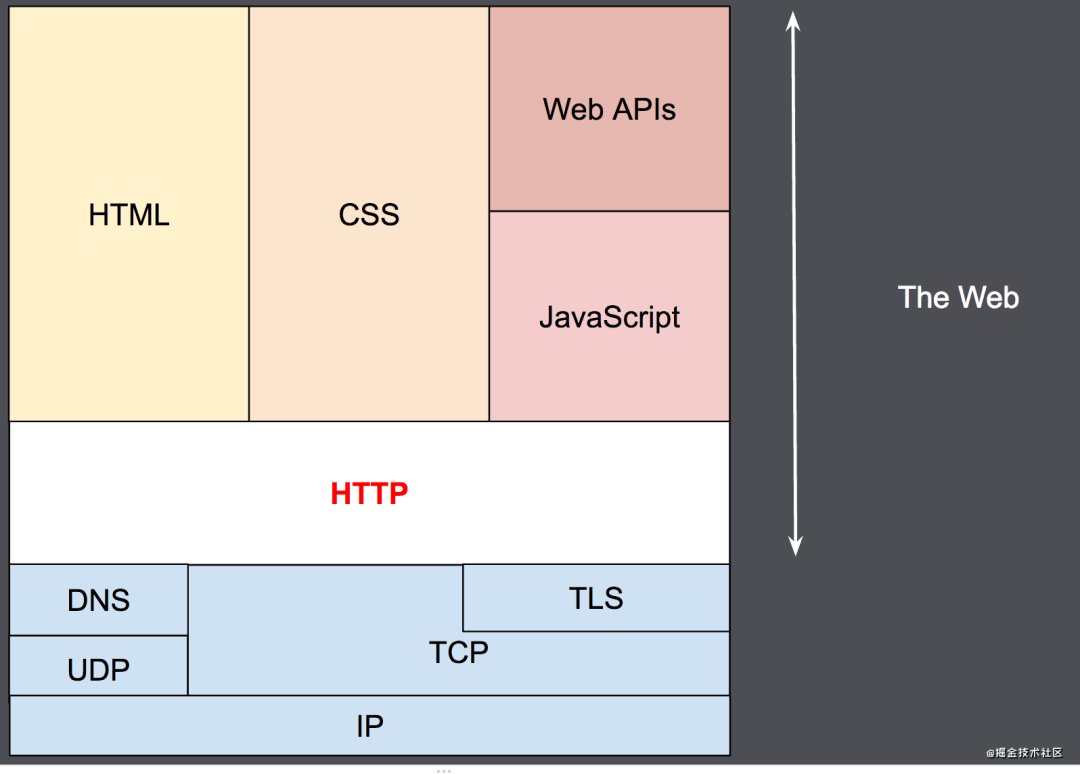
HTTP是一种可扩展的协议。它是应用层的协议,通过TCP,或者是TLS-加密的TCP连接来发送,理论上任何可靠的传输协议都可以使用。
基于
HTTP的组件系统
HTTP是一个client-server协议:请求通过一个实体被发出,实体也就是用户代理。大多数情况下,这个用户代理都是指浏览器,当然它也可能是任何东西,比如一个爬取网页生成维护搜索引擎索引的机器爬虫。
每一个发送到服务器的请求,都会被服务器处理并返回一个消息,也就是response。在这个请求与响应之间,还有许许多多的被称为proxies的实体,他们的作用与表现各不相同,比如有些是网关,还有些是caches等。
实际上,在一个浏览器和处理请求的服务器之间,还有路由器、调制解调器等许多计算机。由于Web的层次设计,那些在网络层和传输层的细节都被隐藏起来了。HTTP位于最上层的应用层。虽然底层对于分析网络问题非常重要,但是大多都跟对HTTP的描述不相干。
客户端:
user-agent
user-agent 就是任何能够为用户发起行为的工具。这个角色通常都是由浏览器来扮演。一些例外情况,比如是工程师使用的程序,以及Web开发人员调试应用程序。
浏览器总是作为发起一个请求的实体,他永远不是服务器(虽然近几年已经出现一些机制能够模拟由服务器发起的请求消息了)。
要展现一个网页,浏览器首先发送一个请求来获取页面的HTML文档,再解析文档中的资源信息发送其他请求,获取可执行脚本或CSS样式来进行页面布局渲染,以及一些其它页面资源(如图片和视频等)。然后,浏览器将这些资源整合到一起,展现出一个完整的文档,也就是网页。浏览器执行的脚本可以在之后的阶段获取更多资源,并相应地更新网页。
一个网页就是一个超文本文档。也就是说,有一部分显示的文本可能是链接,启动它(通常是鼠标的点击)就可以获取一个新的网页,使得用户可以控制客户端进行网上冲浪。浏览器来负责发送HTTP请求,并进一步解析HTTP返回的消息,以向用户提供明确的响应。
Web服务端
在上述通信过程的另一端,是由Web Server来服务并提供客户端所请求的文档。Server只是虚拟意义上代表一个机器:它可以是共享负载(负载均衡)的一组服务器组成的计算机集群,也可以是一种复杂的软件,通过向其他计算机(如缓存,数据库服务器,电子商务服务器 ...)发起请求来获取部分或全部资源。
Server 不一定是一台机器,但一个机器上可以装载的众多Servers。在HTTP/1.1 和Host头部中,它们甚至可以共享同一个IP地址。
代理(Proxies)
在浏览器和服务器之间,有许多计算机和其他设备转发了HTTP消息。由于Web栈层次结构的原因,它们大多都出现在传输层、网络层和物理层上,对于HTTP应用层而言就是透明的,虽然它们可能会对应用层性能有重要影响。还有一部分是表现在应用层上的,被称为代理(Proxies)。代理(Proxies)既可以表现得透明,又可以不透明(“改变请求”会通过它们)。代理主要有如下几种作用:
缓存(可以是公开的也可以是私有的,像浏览器的缓存) 过滤(像反病毒扫描,家长控制...) 负载均衡(让多个服务器服务不同的请求) 认证(对不同资源进行权限管理) 日志记录(允许存储历史信息)
HTTP的基本性质
HTTP 是简单的
虽然下一代HTTP/2协议将HTTP消息封装到了帧(frames)中,HTTP大体上还是被设计得简单易读。HTTP报文能够被人读懂,还允许简单测试,降低了门槛,对新人很友好。
HTTP 是可扩展的
在 HTTP/1.0 中出现的 HTTP headers 让协议扩展变得非常容易。只要服务端和客户端就新 headers 达成语义一致,新功能就可以被轻松加入进来。
HTTP 是无状态,有会话的
HTTP是无状态的:在同一个连接中,两个执行成功的请求之间是没有关系的。这就带来了一个问题,用户没有办法在同一个网站中进行连续的交互,比如在一个电商网站里,用户把某个商品加入到购物车,切换一个页面后再次添加了商品,这两次添加商品的请求之间没有关联,浏览器无法知道用户最终选择了哪些商品。而使用HTTP的头部扩展,HTTP Cookies就可以解决这个问题。把Cookies添加到头部中,创建一个会话让每次请求都能共享相同的上下文信息,达成相同的状态。
注意,HTTP本质是无状态的,使用Cookies可以创建有状态的会话。
HTTP和连接
一个连接是由传输层来控制的,这从根本上不属于HTTP的范围。HTTP并不需要其底层的传输层协议是面向连接的,只需要它是可靠的,或不丢失消息的(至少返回错误)。在互联网中,有两个最常用的传输层协议:TCP是可靠的,而UDP不是。因此,HTTP依赖于面向连接的TCP进行消息传递,但连接并不是必须的。
在客户端(通常指浏览器)与服务器能够交互(客户端发起请求,服务器返回响应)之前,必须在这两者间建立一个 TCP 链接,打开一个 TCP 连接需要多次往返交换消息(因此耗时)。HTTP/1.0 默认为每一对 HTTP 请求/响应都打开一个单独的 TCP 连接。当需要连续发起多个请求时,这种模式比多个请求共享同一个 TCP 链接更低效。
为了减轻这些缺陷,HTTP/1.1引入了流水线(被证明难以实现)和持久连接的概念:底层的TCP连接可以通过Connection头部来被部分控制。HTTP/2则发展得更远,通过在一个连接复用消息的方式来让这个连接始终保持为暖连接。
为了更好的适合HTTP,设计一种更好传输协议的进程一直在进行。Google就研发了一种以UDP为基础,能提供更可靠更高效的传输协议QUIC
HTTP 能控制什么
可以被HTTP控制的常见特性:
缓存
文档如何缓存能通过HTTP来控制。服务端能告诉代理和客户端哪些文档需要被缓存,缓存多久,而客户端也能够命令中间的缓存代理来忽略存储的文档。
开放同源限制
为了防止网络窥听和其它隐私泄漏,浏览器强制对Web网站做了分割限制。只有来自于相同来源的网页才能够获取网站的全部信息。这样的限制有时反而成了负担,HTTP可以通过修改头部来开放这样的限制,因此Web文档可以是由不同域下的信息拼接成的(某些情况下,这样做还有安全因素考虑)。
认证
一些页面能够被保护起来,仅让特定的用户进行访问。基本的认证功能可以直接通过HTTP提供,使用Authenticate相似的头部即可,或用HTTP Cookies来设置指定的会话。
代理和隧道
通常情况下,服务器和/或客户端是处于内网的,对外网隐藏真实 IP 地址。因此 HTTP 请求就要通过代理越过这个网络屏障。但并非所有的代理都是 HTTP 代理。例如,SOCKS协议的代理就运作在更底层,一些像 FTP 这样的协议也能够被它们处理。
会话
使用HTTP Cookies允许你用一个服务端的状态发起请求,这就创建了会话。虽然基本的HTTP是无状态协议。这很有用,不仅是因为这能应用到像购物车这样的电商业务上,更是因为这使得任何网站都能轻松为用户定制展示内容了。
HTTP流
当客户端想要和服务端进行信息交互时(服务端是指最终服务器,或者是一个中间代理),过程表现为下面几步:
打开一个TCP连接:TCP连接被用来发送一条或多条请求,以及接受响应消息。客户端可能打开一条新的连接,或重用一个已经存在的连接,或者也可能开几个新的TCP连接连向服务端。 发送一个HTTP报文:HTTP报文(在HTTP/2之前)是语义可读的。在HTTP/2中,这些简单的消息被封装在了帧中,这使得报文不能被直接读取,但是原理仍是相同的。
GET / HTTP/1.1
Host: xxx.org
Accept-Language: fr
读取服务端返回的报文信息:
HTTP/1.1 200 OK
Date: Sat, 09 Oct xxx 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "xxx-7449-xxx"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (here comes the 29769 bytes of the requested web page)
关闭连接或者为后续请求重用连接。
当HTTP流水线启动时,后续请求都可以不用等待第一个请求的成功响应就被发送。然而HTTP流水线已被证明很难在现有的网络中实现,因为现有网络中有很多老旧的软件与现代版本的软件共存。因此,HTTP流水线已被在有多请求下表现得更稳健的HTTP/2的帧所取代。
HTTP报文
HTTP/1.1以及更早的HTTP协议报文都是语义可读的。在HTTP/2中,这些报文被嵌入到了一个新的二进制结构,帧。帧允许实现很多优化,比如报文头部的压缩和复用。即使只有原始HTTP报文的一部分以HTTP/2发送出来,每条报文的语义依旧不变,客户端会重组原始HTTP/1.1请求。因此用HTTP/1.1格式来理解HTTP/2报文仍旧有效。
有两种HTTP报文的类型,请求与响应,每种都有其特定的格式。
请求
HTTP请求的一个例子:
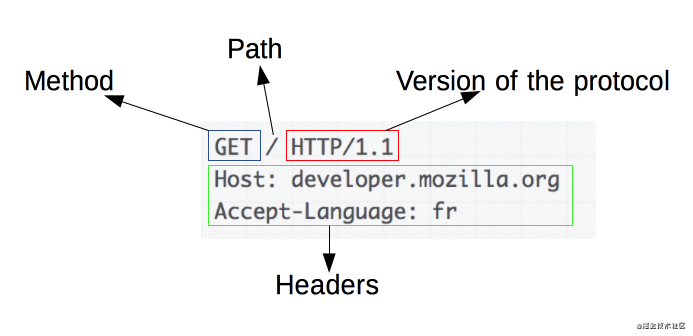
请求由以下元素组成:
一个 HTTP的method,经常是由一个动词像GET, POST或者一个名词像OPTIONS,HEAD来定义客户端的动作行为。通常客户端的操作都是获取资源(GET方法)或者发送HTML form表单值(POST方法),虽然在一些情况下也会有其他操作。要获取的资源的路径,通常是上下文中就很明显的元素资源的 URL,它没有protocol(http://),domain(xxxx.xxx.org),或是TCP的port(en-US)(HTTP一般在80端口)。HTTP协议版本号。为服务端表达其他信息的可选头部 headers。对于一些像 POST这样的方法,报文的body就包含了发送的资源,这与响应报文的body类似。
响应
HTTP响应的一个例子:
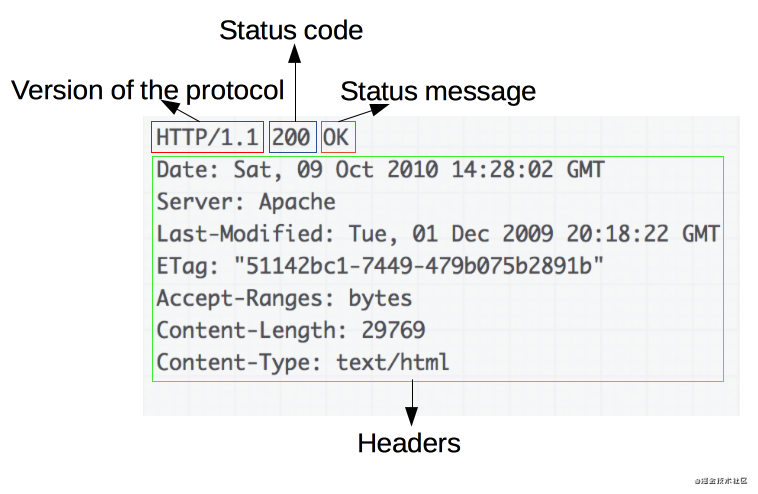
响应报文包含了下面的元素:
HTTP协议版本号。 一个状态码( status code),来告知对应请求执行成功或失败,以及失败的原因。一个状态信息,这个信息是非权威的状态码描述信息,可以由服务端自行设定。 HTTP headers,与请求头部类似。可选项,比起请求报文,响应报文中更常见地包含获取的资源 body。
基于
HTTP的APIs
基于HTTP的最常用API是XMLHttpRequest API,可用于在user agent和服务器之间交换数据。现代Fetch API提供相同的功能,具有更强大和灵活的功能集。
另一种API,即服务器发送的事件,是一种单向服务,允许服务器使用HTTP作为传输机制向客户端发送事件。使用EventSource接口,客户端打开连接并建立事件句柄。客户端浏览器自动将到达HTTP流的消息转换为适当的Event对象,并将它们传递给专门处理这类type事件的句柄,如果有这么个句柄的话。但如果相应的事件处理句柄根本没有建立,那就交给onmessage (en-US)事件处理程序处理。
HTTP是一种简单可扩展的协议,其Client-Server的结构以及轻松扩展头部信息的能力使得HTTP可以和Web共同发展。
即使HTTP/2为了提高性能将HTTP报文嵌入到帧中这一举措增加了复杂度,但是从Web应用的角度看,报文的基本结构没有变化,从HTTP/1.0发布起就是这样的结构。会话流依旧简单,通过一个简单的 HTTP message monitor就可以查看和纠错。
HTTP缓存
通过复用以前获取的资源,可以显著提高网站和应用程序的性能。Web 缓存减少了等待时间和网络流量,因此减少了显示资源表示形式所需的时间。通过使用 HTTP缓存,变得更加响应性。
不同种类的缓存
缓存是一种保存资源副本并在下次请求时直接使用该副本的技术。当 web 缓存发现请求的资源已经被存储,它会拦截请求,返回该资源的拷贝,而不会去源服务器重新下载。这样带来的好处有:缓解服务器端压力,提升性能(获取资源的耗时更短了)。对于网站来说,缓存是达到高性能的重要组成部分。缓存需要合理配置,因为并不是所有资源都是永久不变的:重要的是对一个资源的缓存应截止到其下一次发生改变(即不能缓存过期的资源)。
缓存的种类有很多,其大致可归为两类:私有与共享缓存。共享缓存存储的响应能够被多个用户使用。私有缓存只能用于单独用户。本文将主要介绍浏览器与代理缓存,除此之外还有网关缓存、CDN、反向代理缓存和负载均衡器等部署在服务器上的缓存方式,为站点和 web 应用提供更好的稳定性、性能和扩展性。
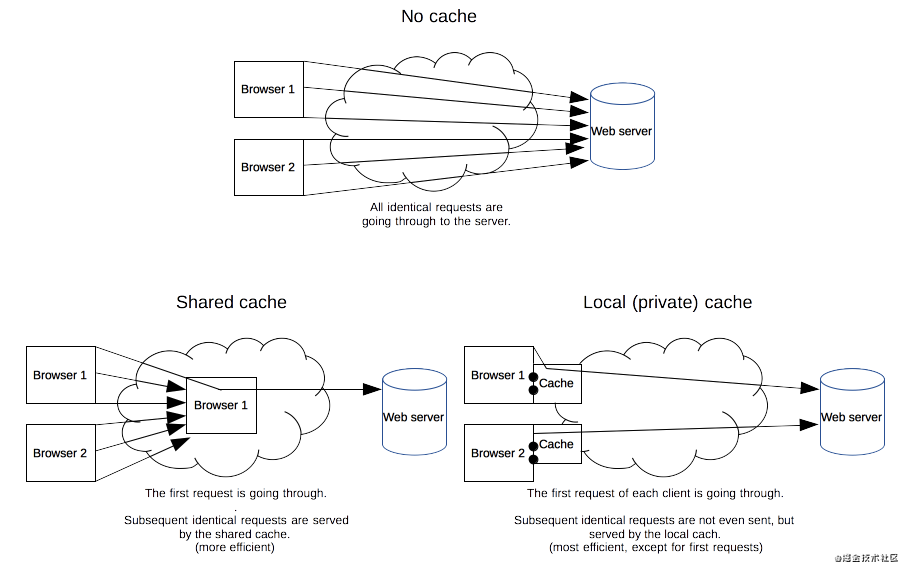
(私有)浏览器缓存
私有缓存只能用于单独用户。你可能已经见过浏览器设置中的“缓存”选项。浏览器缓存拥有用户通过 HTTP 下载的所有文档。这些缓存为浏览过的文档提供向后/向前导航,保存网页,查看源码等功能,可以避免再次向服务器发起多余的请求。它同样可以提供缓存内容的离线浏览。
(共享)代理缓存
共享缓存可以被多个用户使用。例如,ISP 或你所在的公司可能会架设一个 web 代理来作为本地网络基础的一部分提供给用户。这样热门的资源就会被重复使用,减少网络拥堵与延迟。
缓存操作的目标
虽然 HTTP 缓存不是必须的,但重用缓存的资源通常是必要的。然而常见的 HTTP 缓存只能存储 GET 响应,对于其他类型的响应则无能为力。缓存的关键主要包括request method和目标URI(一般只有GET请求才会被缓存)。普遍的缓存案例:
一个检索请求的成功响应: 对于 GET请求,响应状态码为:200,则表示为成功。一个包含例如HTML文档,图片,或者文件的响应。 永久重定向: 响应状态码:301。 错误响应: 响应状态码:404 的一个页面。 不完全的响应: 响应状态码 206,只返回局部的信息。 除了 GET 请求外,如果匹配到作为一个已被定义的cache键名的响应。
针对一些特定的请求,也可以通过关键字区分多个存储的不同响应以组成缓存的内容。
缓存控制
Cache-control 头
HTTP/1.1定义的 Cache-Control 头用来区分对缓存机制的支持情况, 请求头和响应头都支持这个属性。通过它提供的不同的值来定义缓存策略。
没有缓存
缓存中不得存储任何关于客户端请求和服务端响应的内容。每次由客户端发起的请求都会下载完整的响应内容。
Cache-Control: no-store
缓存但重新验证
如下头部定义,此方式下,每次有请求发出时,缓存会将此请求发到服务器(译者注:该请求应该会带有与本地缓存相关的验证字段),服务器端会验证请求中所描述的缓存是否过期,若未过期(注:实际就是返回304),则缓存才使用本地缓存副本。
Cache-Control: no-cache
私有和公共缓存
"public" 指令表示该响应可以被任何中间人(译者注:比如中间代理、CDN等)缓存。若指定了"public",则一些通常不被中间人缓存的页面(译者注:因为默认是private)(比如 带有HTTP验证信息(帐号密码)的页面 或 某些特定状态码的页面),将会被其缓存。
而 "private" 则表示该响应是专用于某单个用户的,中间人不能缓存此响应,该响应只能应用于浏览器私有缓存中。
Cache-Control: private
Cache-Control: public
过期
过期机制中,最重要的指令是 "max-age=<seconds>",表示资源能够被缓存(保持新鲜)的最大时间。相对Expires而言,max-age是距离请求发起的时间的秒数。针对应用中那些不会改变的文件,通常可以手动设置一定的时长以保证缓存有效,例如图片、css、js等静态资源。
Cache-Control: max-age=31536000
验证方式
当使用了 "must-revalidate" 指令,那就意味着缓存在考虑使用一个陈旧的资源时,必须先验证它的状态,已过期的缓存将不被使用。
Cache-Control: must-revalidate
Pragma 头
Pragma 是HTTP/1.0标准中定义的一个header属性,请求中包含Pragma的效果跟在头信息中定义Cache-Control: no-cache相同,但是HTTP的响应头没有明确定义这个属性,所以它不能拿来完全替代HTTP/1.1中定义的Cache-control头。通常定义Pragma以向后兼容基于HTTP/1.0的客户端。
理论上来讲,当一个资源被缓存存储后,该资源应该可以被永久存储在缓存中。由于缓存只有有限的空间用于存储资源副本,所以缓存会定期地将一些副本删除,这个过程叫做缓存驱逐。另一方面,当服务器上面的资源进行了更新,那么缓存中的对应资源也应该被更新,由于HTTP是C/S模式的协议,服务器更新一个资源时,不可能直接通知客户端更新缓存,所以双方必须为该资源约定一个过期时间,在该过期时间之前,该资源(缓存副本)就是新鲜的,当过了过期时间后,该资源(缓存副本)则变为陈旧的。驱逐算法用于将陈旧的资源(缓存副本)替换为新鲜的,注意,一个陈旧的资源(缓存副本)是不会直接被清除或忽略的,当客户端发起一个请求时,缓存检索到已有一个对应的陈旧资源(缓存副本),则缓存会先将此请求附加一个If-None-Match头,然后发给目标服务器,以此来检查该资源副本是否是依然还是算新鲜的,若服务器返回了 304 (Not Modified)(该响应不会有带有实体信息),则表示此资源副本是新鲜的,这样一来,可以节省一些带宽。若服务器通过 If-None-Match 或 If-Modified-Since判断后发现已过期,那么会带有该资源的实体内容返回。
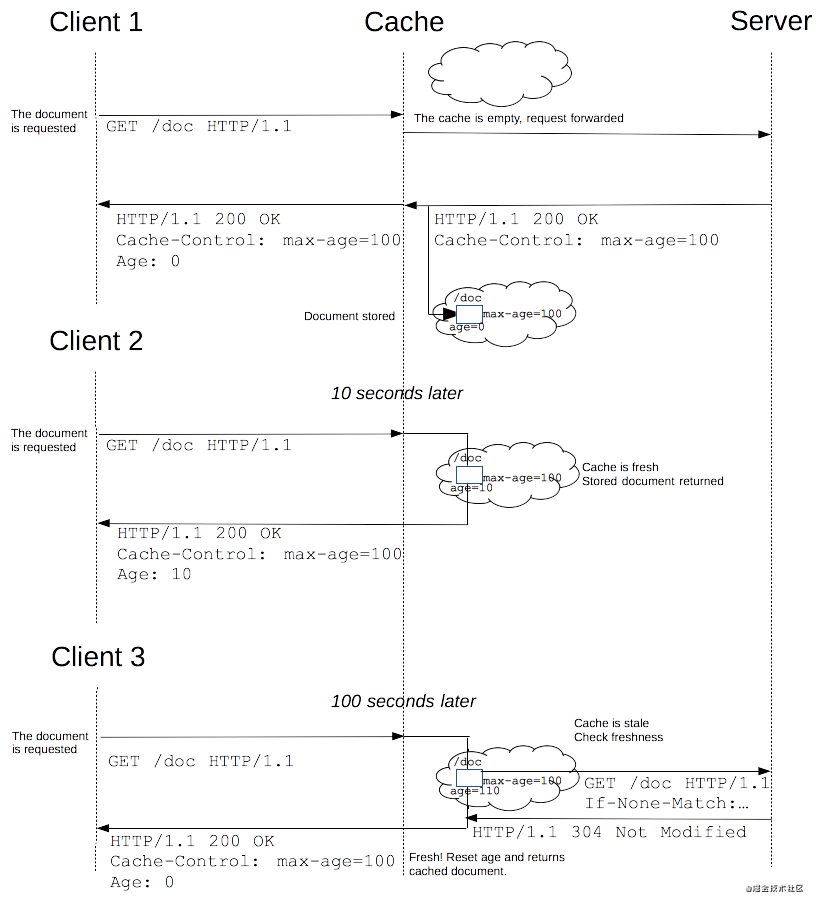
对于含有特定头信息的请求,会去计算缓存寿命。比如Cache-control: max-age=N的头,相应的缓存的寿命就是N。通常情况下,对于不含这个属性的请求则会去查看是否包含Expires属性,通过比较Expires的值和头里面Date属性的值来判断是否缓存还有效。如果max-age和expires属性都没有,找找头里的Last-Modified信息。如果有,缓存的寿命就等于头里面Date的值减去Last-Modified的值除以10
缓存失效时间计算公式如下:
expirationTime = responseTime + freshnessLifetime - currentAge
上式中,responseTime 表示浏览器接收到此响应的那个时间点。
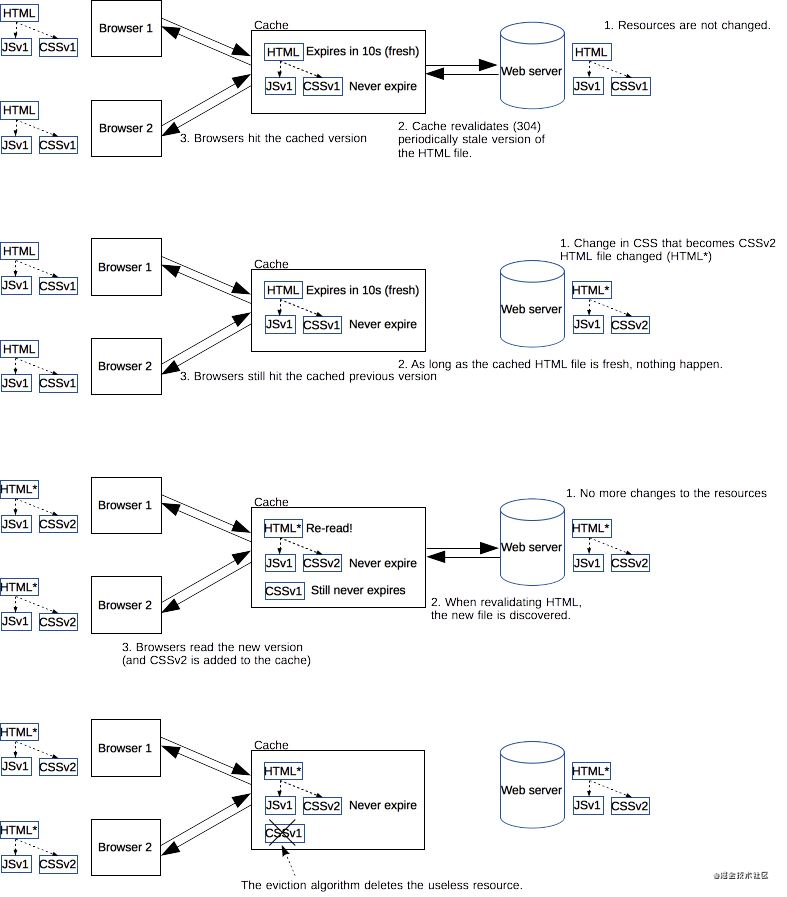
改进资源
我们使用缓存的资源越多,网站的响应能力和性能就会越好。为了优化缓存,过期时间设置得尽量长是一种很好的策略。对于定期或者频繁更新的资源,这么做是比较稳妥的,但是对于那些长期不更新的资源会有点问题。这些固定的资源在一定时间内受益于这种长期保持的缓存策略,但一旦要更新就会很困难。特指网页上引入的一些js/css文件,当它们变动时需要尽快更新线上资源。
web开发者发明了一种被 Steve Souders 称之为 revving 的技术 。不频繁更新的文件会使用特定的命名方式:在URL后面(通常是文件名后面)会加上版本号。加上版本号后的资源就被视作一个完全新的独立的资源,同时拥有一年甚至更长的缓存过期时长。但是这么做也存在一个弊端,所有引用这个资源的地方都需要更新链接。web开发者们通常会采用自动化构建工具在实际工作中完成这些琐碎的工作。当低频更新的资源(js/css)变动了,只用在高频变动的资源文件(html)里做入口的改动。
这种方法还有一个好处:同时更新两个缓存资源不会造成部分缓存先更新而引起新旧文件内容不一致。对于互相有依赖关系的css和js文件,避免这种不一致性是非常重要的。
缓存验证
用户点击刷新按钮时会开始缓存验证。如果缓存的响应头信息里含有"Cache-control: must-revalidate”的定义,在浏览的过程中也会触发缓存验证。另外,在浏览器偏好设置里设置Advanced->Cache为强制验证缓存也能达到相同的效果。
当缓存的文档过期后,需要进行缓存验证或者重新获取资源。只有在服务器返回强校验器或者弱校验器时才会进行验证。
ETags
作为缓存的一种强校验器,ETag 响应头是一个对用户代理(User Agent, 下面简称UA)不透明(译者注:UA 无需理解,只需要按规定使用即可)的值。对于像浏览器这样的HTTP UA,不知道ETag代表什么,不能预测它的值是多少。如果资源请求的响应头里含有ETag, 客户端可以在后续的请求的头中带上 If-None-Match 头来验证缓存。
Last-Modified 响应头可以作为一种弱校验器。说它弱是因为它只能精确到一秒。如果响应头里含有这个信息,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存。
当向服务端发起缓存校验的请求时,服务端会返回 200 ok表示返回正常的结果或者 304 Not Modified(不返回body)表示浏览器可以使用本地缓存文件。304的响应头也可以同时更新缓存文档的过期时间。
Vary 响应
Vary HTTP 响应头决定了对于后续的请求头,如何判断是请求一个新的资源还是使用缓存的文件。
当缓存服务器收到一个请求,只有当前的请求和原始(缓存)的请求头跟缓存的响应头里的Vary都匹配,才能使用缓存的响应。

使用vary头有利于内容服务的动态多样性。例如,使用Vary: User-Agent头,缓存服务器需要通过UA判断是否使用缓存的页面。如果需要区分移动端和桌面端的展示内容,利用这种方式就能避免在不同的终端展示错误的布局。另外,它可以帮助 Google 或者其他搜索引擎更好地发现页面的移动版本,并且告诉搜索引擎没有引入Cloaking。
Vary: User-Agent
因为移动版和桌面的客户端的请求头中的User-Agent不同, 缓存服务器不会错误地把移动端的内容输出到桌面端到用户。
跨源资源共享(
CORS)
跨源资源共享 (CORS) (或通俗地译为跨域资源共享)是一种基于HTTP 头的机制,该机制通过允许服务器标示除了它自己以外的其它origin(域,协议和端口),这样浏览器可以访问加载这些资源。跨源资源共享还通过一种机制来检查服务器是否会允许要发送的真实请求,该机制通过浏览器发起一个到服务器托管的跨源资源的"预检"请求。在预检中,浏览器发送的头中标示有HTTP方法和真实请求中会用到的头。
跨源HTTP请求的一个例子:运行在 http://domain-a.com 的JavaScript代码使用XMLHttpRequest来发起一个到 https://domain-b.com/data.json 的请求。
出于安全性,浏览器限制脚本内发起的跨源HTTP请求。例如,XMLHttpRequest和Fetch API遵循同源策略。这意味着使用这些API的Web应用程序只能从加载应用程序的同一个域请求HTTP资源,除非响应报文包含了正确CORS响应头。
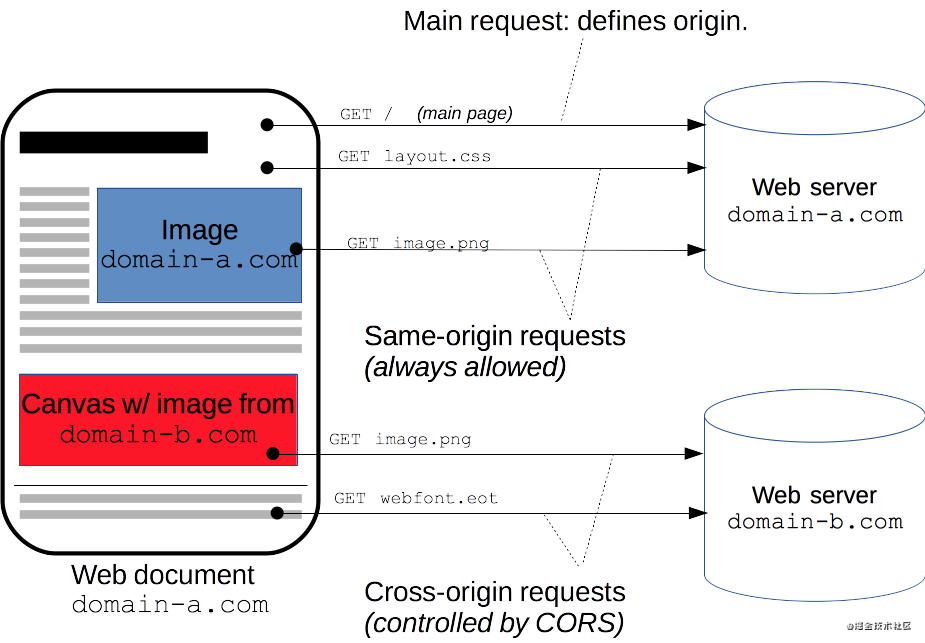
什么情况下需要 CORS ?
前文提到的由 XMLHttpRequest或Fetch发起的跨源HTTP请求。Web字体 (CSS中通过@font-face使用跨源字体资源)WebGL贴图使用 drawImage将Images/video画面绘制到canvas
功能概述
跨源资源共享标准新增了一组 HTTP 首部字段,允许服务器声明哪些源站通过浏览器有权限访问哪些资源。另外,规范要求,对那些可能对服务器数据产生副作用的 HTTP 请求方法(特别是 GET 以外的 HTTP 请求,或者搭配某些 MIME 类型的 POST 请求),浏览器必须首先使用 OPTIONS 方法发起一个预检请求(preflight request),从而获知服务端是否允许该跨源请求。服务器确认允许之后,才发起实际的 HTTP 请求。在预检请求的返回中,服务器端也可以通知客户端,是否需要携带身份凭证(包括 Cookies 和 HTTP 认证相关数据)。
CORS请求失败会产生错误,但是为了安全,在JavaScript代码层面是无法获知到底具体是哪里出了问题。你只能查看浏览器的控制台以得知具体是哪里出现了错误。
跨源资源共享机制的工作原理
Accept
Accept-Language
Content-Language
Content-Type (需要注意额外的限制)
DPR
Downlink
Save-Data
Viewport-Width
Width
Content-Type 的值仅限于下列三者之一:
text/plain
multipart/form-data
application/x-www-form-urlencoded
跨源资源共享机制的工作原理: 使用 XMLHttpRequest 对象。
示例:
var invocation = new XMLHttpRequest();
var url = 'http://xx.other/resources/public-data/';
function callOtherDomain() {
if(invocation) {
invocation.open('GET', url, true);
invocation.onreadystatechange = handler;
invocation.send();
}
}
客户端和服务器之间使用 CORS 首部字段来处理权限:
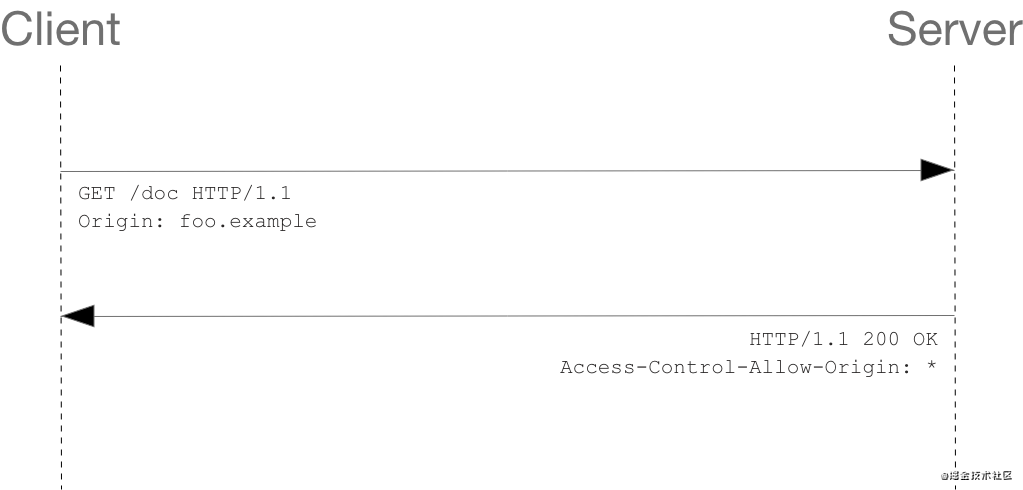
GET /resources/public-data/ HTTP/1.1
Host: bar.other
User-Agent:
Accept:
Accept-Language:
Accept-Encoding:
Accept-Charset:
Connection:
Referer:
Origin:
HTTP/1.1 200 OK
Date:
Server:
Access-Control-Allow-Origin: *
Keep-Alive:
Connection:
Transfer-Encoding:
Content-Type:
预检请求
可以避免跨域请求对服务器的用户数据产生未预期的影响。
OPTIONS /resources/post-here/ HTTP/1.1
Host:
User-Agent:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Origin:
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-Type
HTTP/1.1 200 OK
Date:
Server:
Access-Control-Allow-Origin:
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers:
Access-Control-Max-Age: 86400
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 0
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
预检请求完成之后,发送实际请求。
预检请求中同时携带了下面两个首部字段:
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-Type
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Methods 表明服务器允许客户端使用 POST, GET 和 OPTIONS 方法发起请求。
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
首部字段 Access-Control-Allow-Headers 表明服务器允许请求中携带字段 X-PINGOTHER 与 Content-Type。
附带身份凭证的请求
示例:可以基于 HTTP cookies 和 HTTP 认证信息发送身份凭证。
var invocation = new XMLHttpRequest();
var url = 'http://xxxx.other/resources/credentialed-content/';
function callOtherDomain(){
if(invocation) {
invocation.open('GET', url, true);
//向服务器发送 Cookies
invocation.withCredentials = true;
invocation.onreadystatechange = handler;
invocation.send();
}
}
如果服务器端的响应中未携带 Access-Control-Allow-Credentials: true ,浏览器将不会把响应内容返回给请求的发送者。

附带身份凭证的请求与通配符
对于附带身份凭证的请求,服务器不得设置 Access-Control-Allow-Origin 的值为“*”。
这是因为请求的首部中携带了 Cookie 信息,如果 Access-Control-Allow-Origin 的值为“*”,请求将会失败。而将 Access-Control-Allow-Origin 的值设置为 http://foo.example,则请求将成功执行。
另外,响应首部中也携带了 Set-Cookie 字段,尝试对 Cookie 进行修改。如果操作失败,将会抛出异常。
第三方 cookies
注意在 CORS 响应中设置的 cookies 适用一般性第三方 cookie 策略。
HTTP响应首部字段
Access-Control-Allow-Origin: <origin> | *
其中,origin 参数的值指定了允许访问该资源的外域 URI。对于不需要携带身份凭证的请求,服务器可以指定该字段的值为通配符,表示允许来自所有域的请求。
在跨源访问时,XMLHttpRequest对象的getResponseHeader()方法只能拿到一些最基本的响应头,Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma,如果要访问其他头,则需要服务器设置本响应头。
Access-Control-Expose-Headers 头让服务器把允许浏览器访问的头放入白名单,例如:
Access-Control-Expose-Headers: X-My-Custom-Header, X-Another-Custom-Header
这样浏览器就能够通过getResponseHeader访问X-My-Custom-Header和 X-Another-Custom-Header 响应头了。
指定了preflight请求的结果能够被缓存多久
Access-Control-Max-Age: <delta-seconds>
delta-seconds 参数表示preflight请求的结果在多少秒内有效。
Access-Control-Allow-Credentials
Access-Control-Allow-Credentials 头指定了当浏览器的credentials设置为true时是否允许浏览器读取response的内容。
当用在对preflight预检测请求的响应中时,它指定了实际的请求是否可以使用credentials。请注意:简单 GET 请求不会被预检;如果对此类请求的响应中不包含该字段,这个响应将被忽略掉,并且浏览器也不会将相应内容返回给网页。
Access-Control-Allow-Credentials: true
Access-Control-Allow-Methods 首部字段用于预检请求的响应。其指明了实际请求所允许使用的 HTTP 方法。
Access-Control-Allow-Headers 首部字段用于预检请求的响应。其指明了实际请求中允许携带的首部字段。
Access-Control-Request-Method 首部字段用于预检请求。其作用是,将实际请求所使用的 HTTP 方法告诉服务器。
Access-Control-Request-Headers 首部字段用于预检请求。其作用是,将实际请求所携带的首部字段告诉服务器。
❤️关注+点赞+收藏+评论+转发❤️,原创不易,鼓励笔者创作更好的文章
点赞、收藏和评论
我是Jeskson(达达前端),感谢各位人才的:点赞、收藏和评论,我们下期见!(如本文内容有地方讲解有误,欢迎指出☞谢谢,一起学习了)
我们下期见!
github收录,欢迎Star:https://github.com/webVueBlog/WebFamily