
在元宇宙里克隆真人?Unity元宇宙的背后竟是游戏宅

新智元报道
新智元报道
编辑:好困 袁榭
【新智元导读】在大批企业抢位元宇宙、苦思如何将真实世界VR化又如何变现的当下,从服务游戏宅做起的Unity公司,技术力与商业经验已经足以在游戏引擎中,支撑一个人、物都高拟真的实景世界克隆版了。



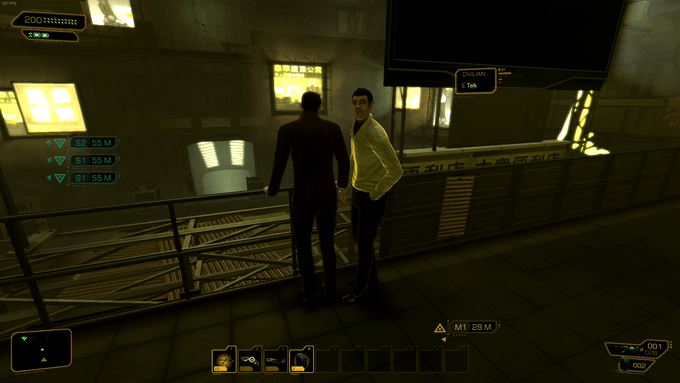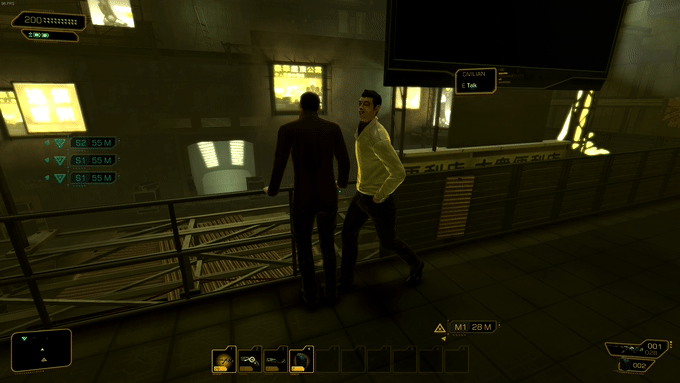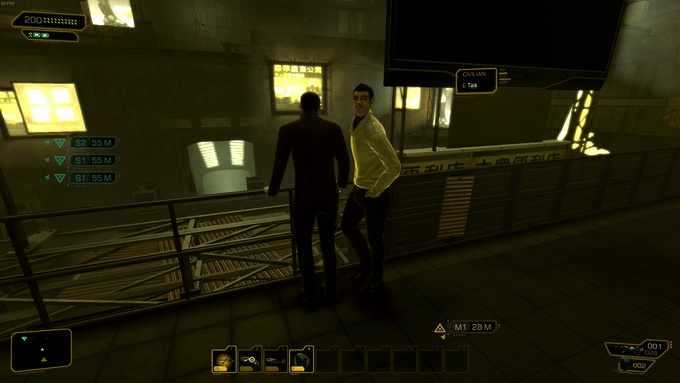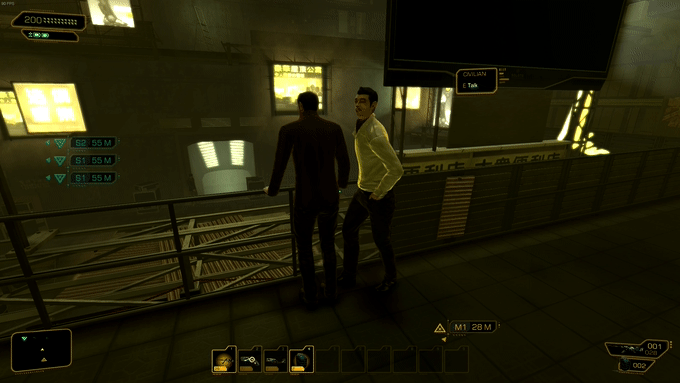







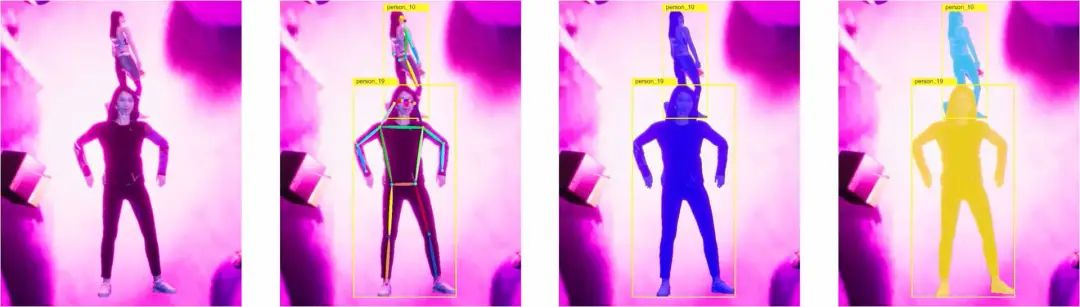
28个不同年龄和种族的3D人体模型,不同的服装(21,952个独特的服装纹理);
39个动画短片,具有完全随机的人体姿态、体型等;
完全参数化的照明(位置、颜色、角度和强度)和拍摄(位置、视场、焦距)设置;
一组物体基元,作为分散注意力的物体和具有不同质地的遮挡物;
一组来自COCO未标记的1600张自然图像,作为物体的背景和纹理。

4个具有不同服装颜色的三维人体模型示例;
8个动画剪辑的例子,具有完全随机化的人体姿态等等;
一组来自Unity Perception软件包的529张自然的杂货物品图片,作为物体的背景和纹理。


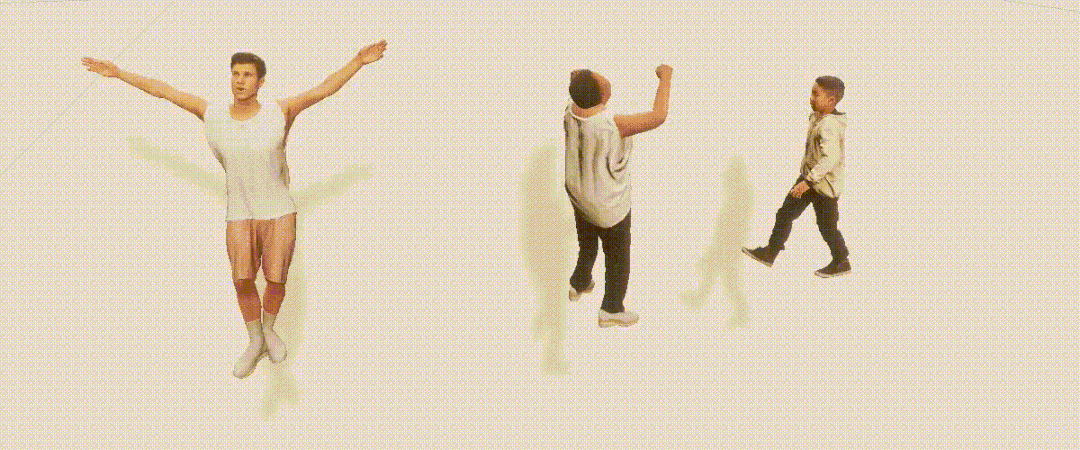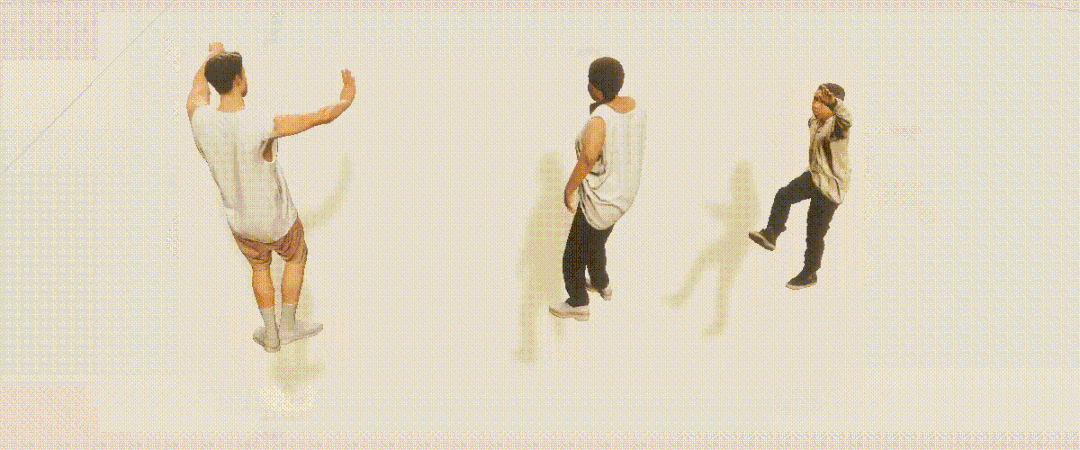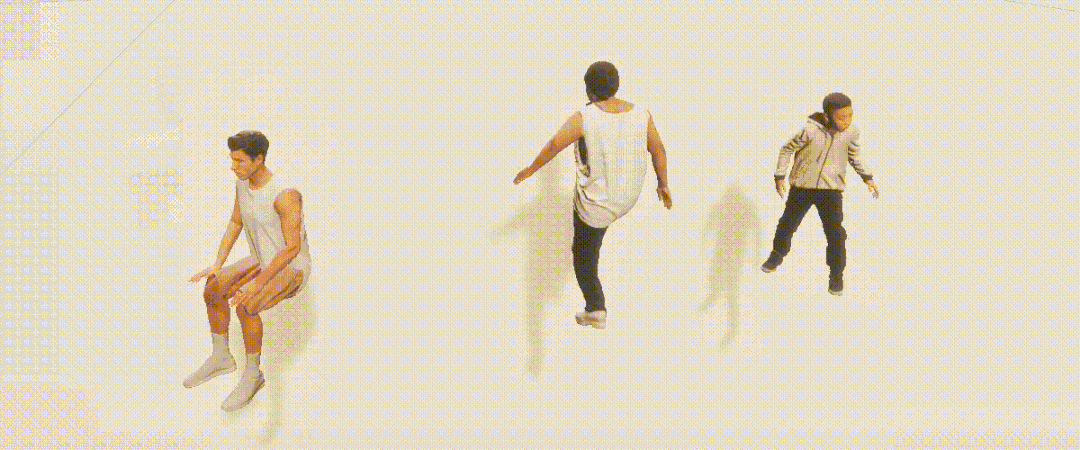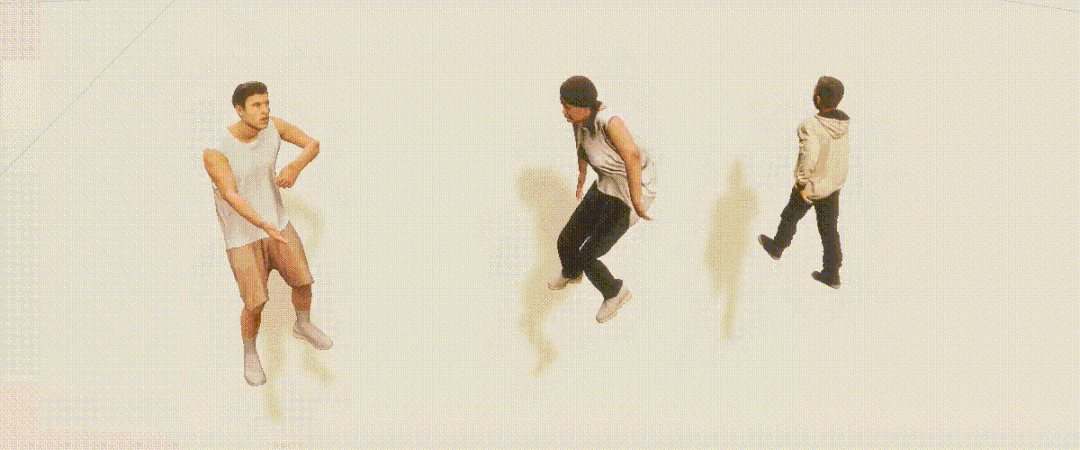


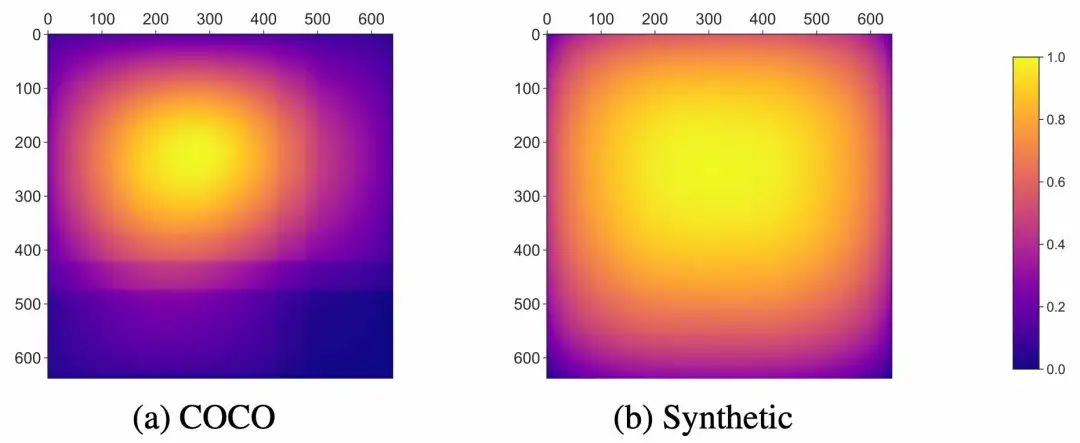
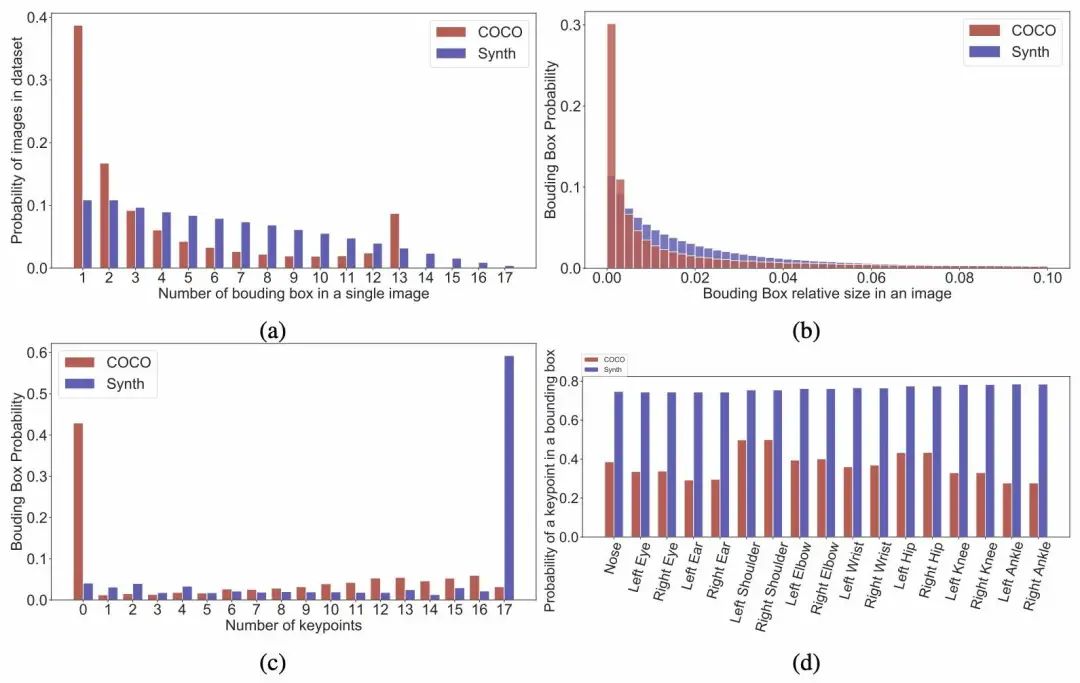
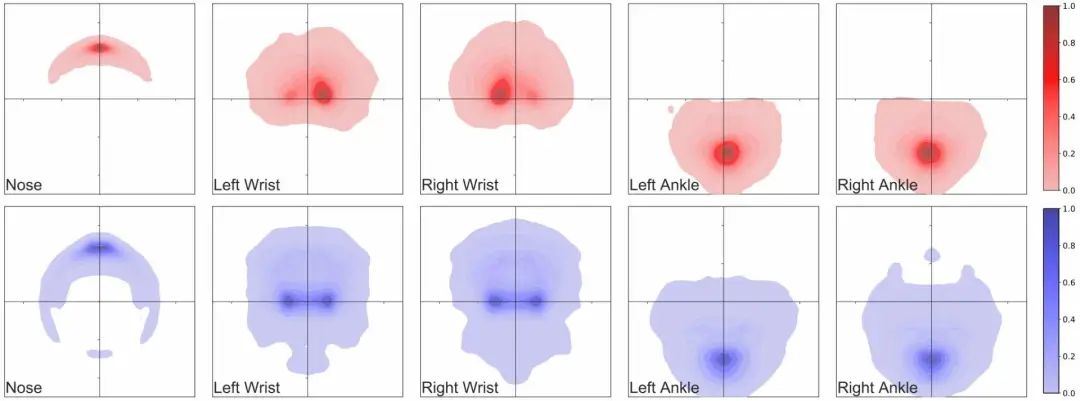
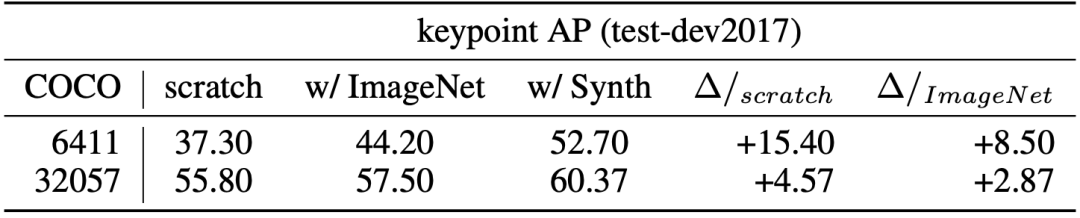
PeopleSansPeople的姿势分布包含了COCO中的姿势分布; PeopleSansPeople的合成姿势分布比COCO更广泛; 在COCO中,大多数人是正面朝向的,导致了点的密度与「手性」的不对称,而这在PeopleSansPeople的合成数据中是没有的。



评论