
从0开始学RAG之RAG-Fusion
原文地址:https://zhuanlan.zhihu.com/p/684994205
类型: 技术分享
本文为 @lucas大叔 投稿原创转载!如有侵权,麻烦告知删除!
基本原理
RAG-Fusion可以认为是MultiQueryRetriever的进化版,如下图所示,RAG-Fusion首先根据原始question从不同角度生成多个版本的新question,用以提升question的质量;然后针对每个question进行向量检索,到此步为止都是MultiQueryRetriever的功能;与之不同的是,RAG-Fusion在喂给LLM生成答案之前增加了一个排序的步骤。
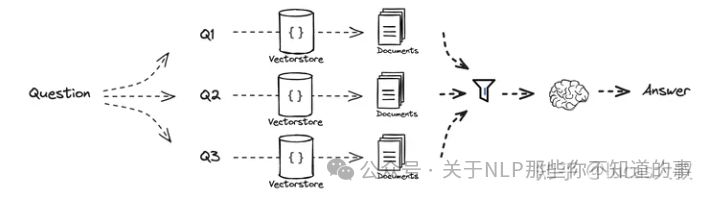
排序包含两个动作,一是独立对每个question检索返回的内容根据相似度排序,确定每个返回chunk在各自候选集中的位置,相似度越高排名越靠前。二是对所有question 返回的内容利用RRF(Reciprocal Rank Fusion)综合排序,RRF排序原理如下图所示。
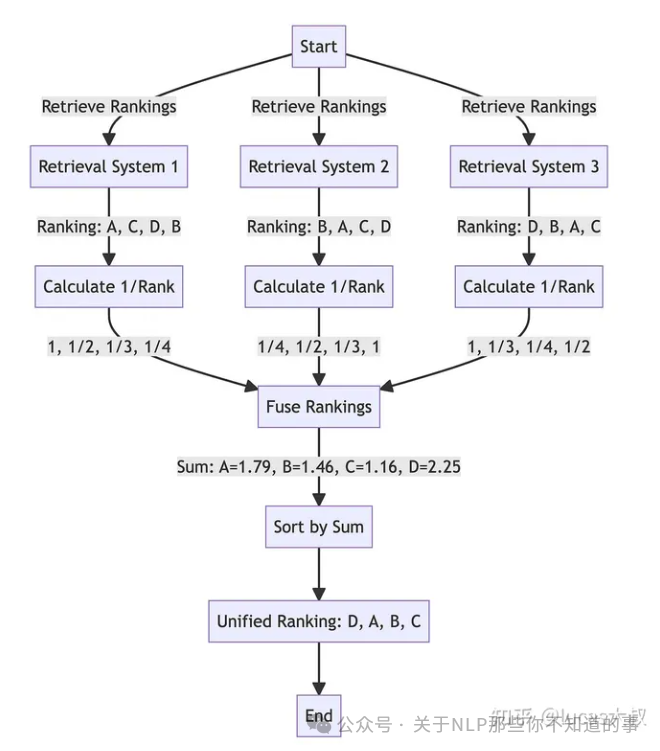
RRF score的计算公式非常简单:

其中,rank是按照距离排序的文档在各自集合中的排名,k是常数平滑因子,一般取k=60。RRF将不同检索器的结果综合评估得到每个chunk的统一得分。
代码实践
首先,导入必要的packages
import torch
from langchain.load import dumps, loads
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain import PromptTemplate
from langchain import HuggingFacePipeline
from transformers import AutoTokenizer, pipeline, AutoModelForCausalLM
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains.llm import LLMChain
from langchain_core.output_parsers import StrOutputParser然后做一些准备工作,编写加载embedding模型、LLM和文件的函数。
def load_embedding(embed_path):
embeddings = HuggingFaceEmbeddings(
model_name=embed_path,
model_kwargs={"device": "cuda"},
encode_kwargs={"normalize_embeddings": True},
)
return embeddings
def load_llm(model_path):
tokenizer = AutoTokenizer.from_pretrained(
model_path,
device_map="auto",
trust_remote_code=True,
torch_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
trust_remote_code=True,
device_map="auto",
)
model_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
return_full_text=True,
)
llm = HuggingFacePipeline(pipeline=model_pipeline)
return llm
def load_data(data_file):
loader = PyPDFLoader(data_file)
documents = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(separators=["。"], chunk_size=512, chunk_overlap=32)
texts_chunks = text_splitter.split_documents(documents)
return texts_chunks编写retrieval_and_rank()函数,对query利用similarity_search_with_score()在向量库中检索,返回候选chunk和相应的score。对每个query返回的内容,根据score降序排列,最终得到list[list]结构的候选答案集。
def retrieval_and_rank(queries):
all_results = {}
for query in queries:
if query:
search_results = vectorstore.similarity_search_with_score(query)
results = []
for res in search_results:
content = res[0].page_content
score = res[1]
results.append((content, score))
all_results[query] = results
document_ranks = []
for query, doc_score_list in all_results.items():
ranking_list = [doc for doc, _ in sorted(doc_score_list, key=lambda x: x[1], reverse=True)]
document_ranks.append(ranking_list)
return document_ranks编写reciprocal_rank_fusion()函数,利用上面的RRF score计算公式计算每个候选chunk的融合得分。
def reciprocal_rank_fusion(document_ranks, k=60):
fused_scores = {}
for docs in document_ranks:
for rank, doc in enumerate(docs):
doc_str = dumps(doc)
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
fused_scores[doc_str] += 1 / (rank + k)
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
return reranked_results编写main()函数。指定模型和文件路径,依次加载embedding模型、LLM和文件。创建向量库vectorstore,用于后续检索。
基于prompt模板,利用LLM为query生成3个相关问题。典型实现是把生成的相关问题作为输入调用retrieval_and_rank()函数,也可以连同原始query一起扔给retrieval_and_rank()函数,视实际场景效果验证是否增加原始query。内部排序过的结果用RRF算法再统一计算得分排序。
接下来是常规操作,将RRF排序后的内容作为上下文,调用LLMChain验证回答的效果。
if __name__ == "__main__":
data_file = "../data/中华人民共和国证券法(2019修订).pdf"
model_path = "/data/models/Baichuan2-13B-Chat"
embed_path = "/data/models/bge-large-zh-v1.5"
embeddings = load_embedding(embed_path)
llm = load_llm(model_path)
docs = load_data(data_file)
vectorstore = Chroma.from_documents(docs, embeddings)
template = """You are a helpful assistant that generates multiple search queries based on a single input query. \n
Generate multiple search queries related to: {question} \n
Output (3 queries):"""
prompt_rag_fusion = PromptTemplate.from_template(template)
generate_query_chain = (
prompt_rag_fusion
| llm
| StrOutputParser()
| (lambda x: x.split("\n"))
)
query = "公司首次公开发行新股,应当符合哪些条件?"
queries = generate_query_chain.invoke({"question": query})
all_results = retrieval_and_rank(queries)
reranked_results = reciprocal_rank_fusion(all_results)
# ----------------- 构造提示模板 ----------------- #
template = """你是一名智能助手,根据上下文回答用户的问题,不需要回答额外的信息或捏造事实。
已知内容:
{context}
问题:
{question}
"""
prompt = PromptTemplate(template=template, input_variables=["context", "question"])
# ----------------- 验证效果 ----------------- #
chain = LLMChain(llm=llm, prompt=prompt)
result = chain.run(context=reranked_results, question=query)
print(result)写在最后
RAG-Fusion虽然可以通过生成多个相关query改善query质量,个人理解对缺少上下文信息或关键元素的短query作用比较大,对表述相对完整的query实属鸡肋。反而可能会因为改写query检索到其他角度的信息,造成答案无效信息增多显得冗长,甚至得出错误的答案。此时,加入原始query会对生成答案的正确性有一定改善。
RAG各种技巧、方法层出不穷,每种技巧有其适用的场景,需要根据实际应用场景灵活选择、大胆魔改!☺