
为什么数组的下标从 0 开始?
数组,作为技术同学一定不会陌生。天天和它打交道,闭着眼都认识它。
首先,我们来复习下数组的定义
数组是一组连续内存空间存储的具有相同类型的数据,整个排列像一条线一样,是一种线性表数据结构。
那么,问题来了,数组的下标为什么要从 0 开始?从 1 开始行不行?

端好你的小茶杯,开始进入正题
数组之所以广泛使用,是因为它支持随机访问。
什么叫随机访问?
数据在内存中都是按顺序存放的,通过下标直接触达到某一个元素存放的位置。
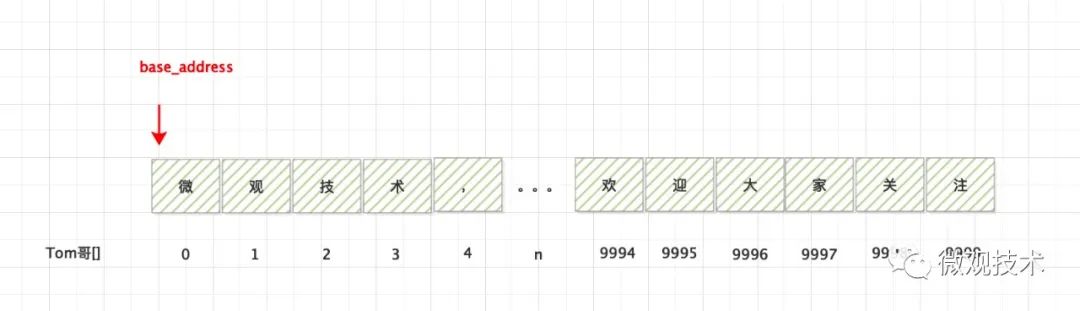
base_address,表示数组的首地址 n,表示偏移量 data_size,表示数组类型的字节数
① 读取上面数组的 【0】位置的 `微`
② 读取上面数组的 【9999】位置的 `注`
由于基于计算的内存地址读取数据,上面两种情况的耗费的时间是一样,时间复杂度为 O(1)
注意:想要使用随机访问,一定要满足两个条件: 1、连续的内存空间 2、相同类型的数据
知识补充:
与随机访问对应的是顺序访问
顺序访问:链表在内存中不是按顺序存放的,而是通过指针连在一起,访问某一元素,必须从链头开始顺着指针才能找到某一个元素。
突然,一个奇怪的念头冒了出来,假如我们将数组的首个下标从 1 开始 ,会怎么样?
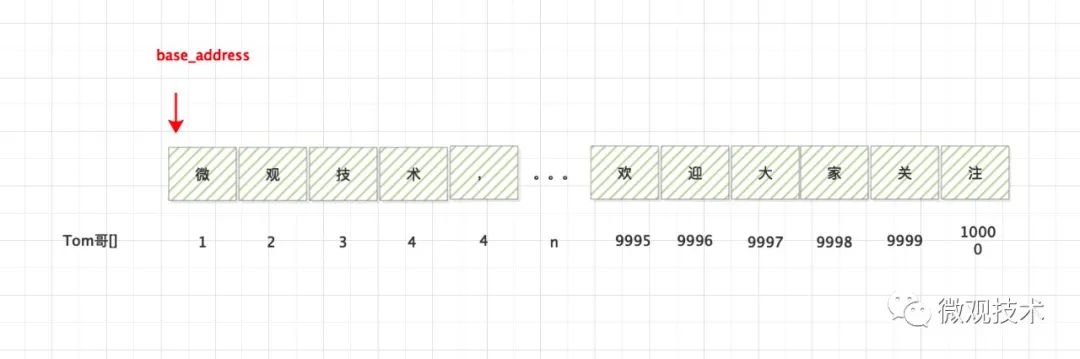
我们读取 下标为n 的数据
与上面的公式的区别,多了一次 n-1 操作
虽然也能读取数组中的值,但是多了一次减法的指令运算。

数组是一个最基础、最简单的数据结构。要知道我们的上层API内部很多都会依赖于数组,而互联网应用又讲究一个高并发,一言不合就是千万级QPS,如此高频的访问量,这个冗余的减运算 就会放大无数倍,产生巨大的性能损耗。
这样说,可能大家感受不一定明显!!!
”我在马路边捡到一分钱,把它交到警察叔叔手里边“。现在再有一分钱,你还会捡吗,估计很多人都看不上眼,但要是全国人民每人给你一分钱呢
14亿 * 1分钱 = 1400万 人民币

是不是可以立马辞职,回家躺平了!
量变引发质变,做软件开发,我们一定要考虑将性能优化到极致,骨子里透着工匠精神。

【超赞】技术架构的战略和战术原则

愚蠢的领导对程序员的“潜规则“!!

聊聊redis分布式锁的8大坑
评论