
【开放源代码】集齐转评赞!微博点赞详细信息抓取
点击上方 月小水长 并 设为星标,第一时间接收干货推送
微博的转评赞都是构成微博社交关系网络的重要组成部分,其中转发和评论都在之前的推送中发布过。
今天就来补齐赞的信息,并开放源代码,以李医生的最后一条微博为例子。
https://m.weibo.cn/detail/4467107636950632#attitude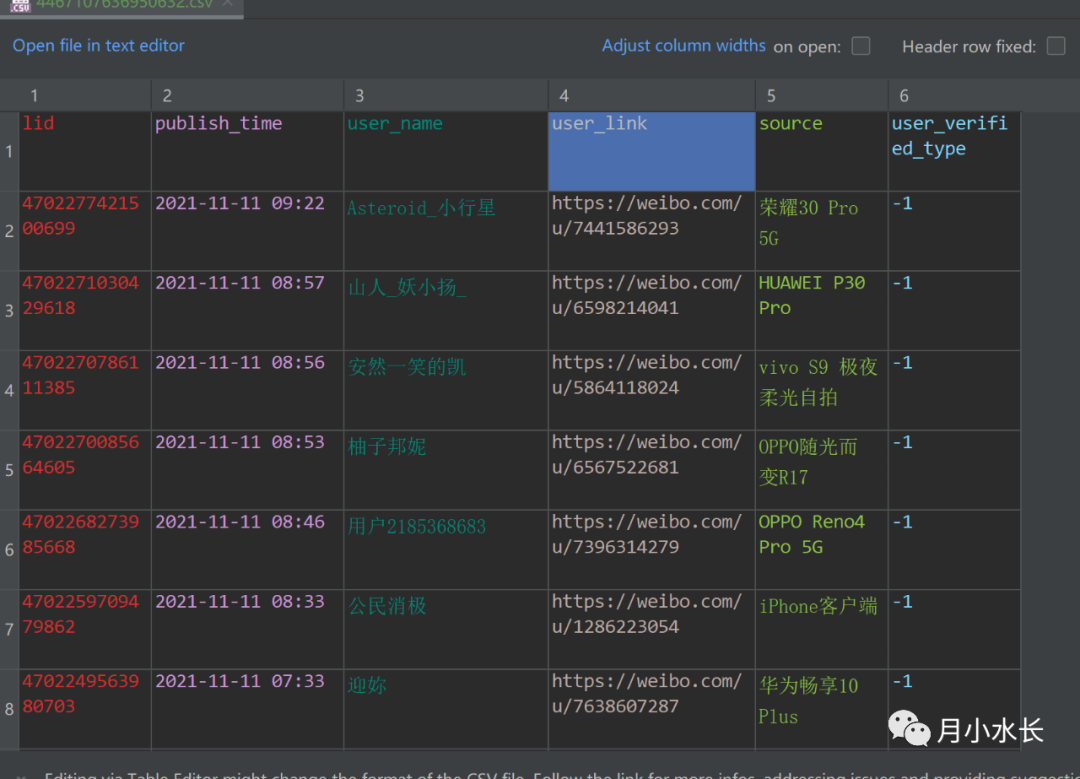
verified_dict = {-1: '普通用户',0: '名人',1: '政府',2: '',3: '媒体',220: ''}
https://m.weibo.cn/api/attitudes/showhttps://m.weibo.cn/detail/4467107636950632#attitudedef __init__(self, wid, page=1, cookie=None, proxies=None):self.wid = widself.page = pageif cookie:self.cookie = cookieself.proxies = proxiesself.initConfig()self.got_likes = []self.got_likes_num = 0self.written_likes_num = 0if not os.path.exists(self.like_folder):os.mkdir(self.like_folder)self.result_file = os.path.join(self.like_folder, f'{self.wid}.csv')
if __name__ == '__main__':WeiboLikeSpider(wid='4467107636950632', cookie='你的 cookie').run()
# 每个 request 休眠 8 s= 8# 每个 request 连接超时 8 s= 8# 每翻 5 页保存一次= 5# 结果 csv 文件所在的文件夹like_folder = 'like'
评论