
微博架构组面试:类微博点赞系统设计

离面试微博架构组已经过去好几个月了。由于时间冲突,等到了谈钱不伤感情之后的offer环节,已经是入职现在的公司两天之后了,面子薄的我 只好和微博遗憾擦肩而过,一直对微博的Redis抗量机制贼有兴趣,可惜仍无缘一见。如果当初交流过的那几位微博大佬有幸看到本文,兄弟这厢有礼了。
Part1少见的代码Review环节
当N轮面试都结束之后,被老哥告知,最后的最后,需要写个代码Demo。二选一:
近期的Github项目 一个指定题目的系统设计( 类微博点赞 ),并给出demo。
挺好,实际Review下候选人的系统设计思路和代码风格是一个对候选人很好的认知方式,以防招到纯面试人才,大家都省心。
所以还是建议大伙平时保持一定的代码量,多做些系统设计,以免成为传说中的"纯面试人才",遇到这种实操面试着急上火。
当然,为了更好的一展风'菜',我选了指定题目重0开始。
本篇给大家整理一下这最后一个"代码Review环节",我是怎么应对的。
需要说明的是,这只是一个面试demo,离正式的系统设计还差很远,只是给大家提供个应对这种面试场景的思路。同时也给大家提供一个平时做系统设计的操作模板。
Part2类微博点赞系统分析
2.1系统概述
$ 系统需求
实现一个类微博的点赞服务,满足性能和持续扩展的需要。
$ 调用量预估
点赞请求 1w/s ;访问请求 20w/s
2.2功能概述
$ 点赞功能
支持对某条微博点赞,每条微博只能被每人赞一次。
$ 查询功能
支持查询某人是否赞过某条微博
Part3类微博点赞系统设计
3.1系统部署设计
首先通过系统部署图直观的规划整个系统的功能模块组成:
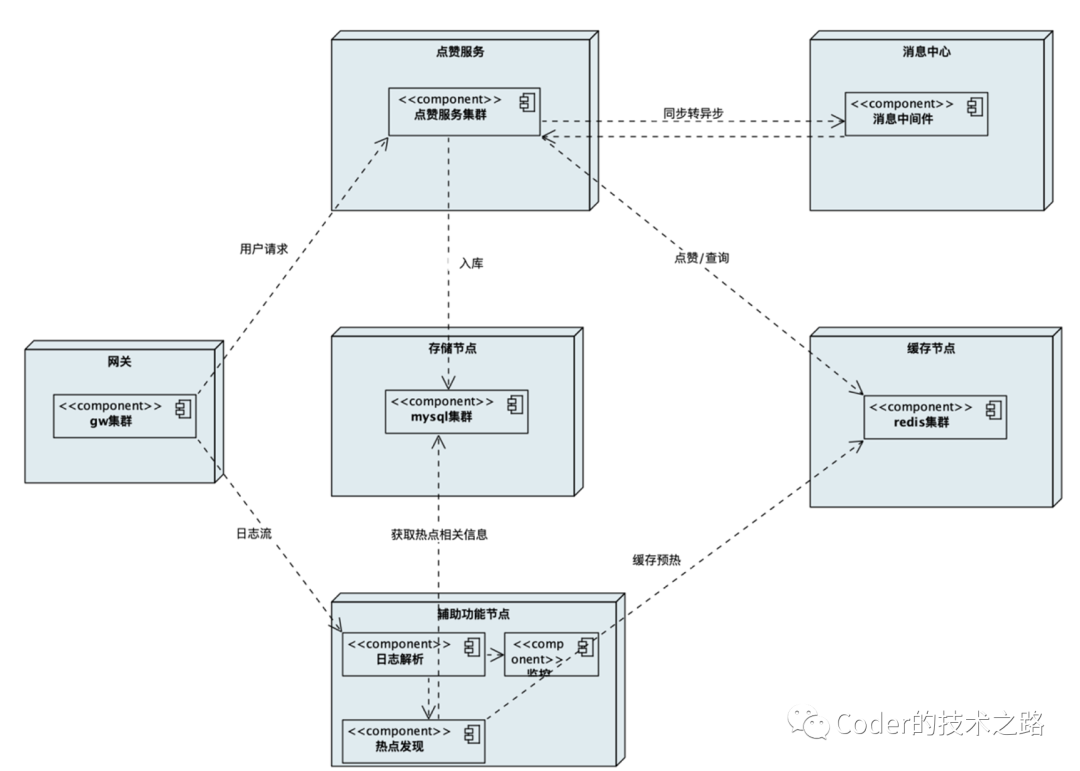
在整个系统场景中,参与者包括:
网关 -- 有用来接收和分发用户请求 点赞服务 -- 用来处理用户点赞逻辑 存储节点 -- 用来存储用户的点赞信息 缓存节点 -- 用来支撑大量并发的读请求 消息中心 -- 提高系统吞吐 其他 -- 日志等辅助功能
3.2功能模块设计
从上面的系统需求和功能需求我们可以看到,整个点赞服务是一个读多写少的场景,只看写的话,并发量也是比较大的,而且,需要考虑业务增长带来的并发量和数据规模的增长。
所以,对于在线服务,设计时需要考虑压力分流,同时兼顾分流的可扩展性。对于存储服务,需要考虑和库表容量和新老数据拆分。
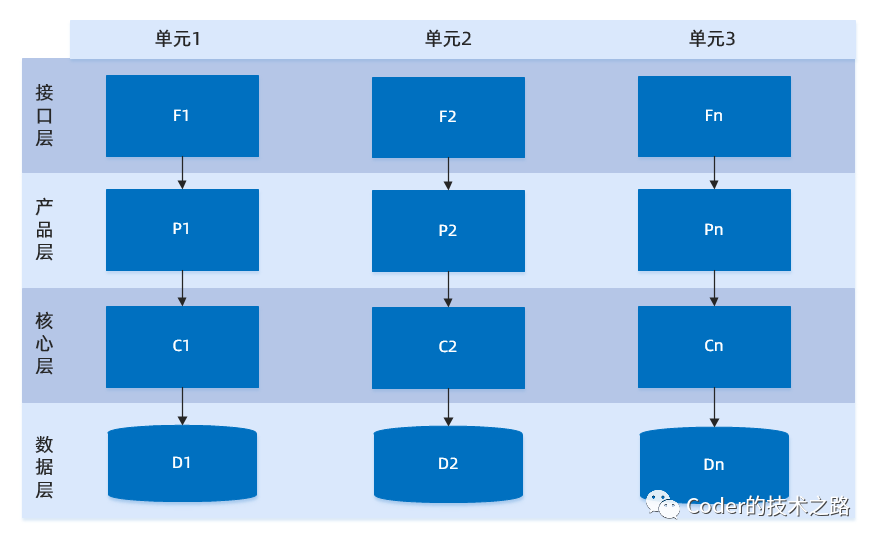
服务部署设计
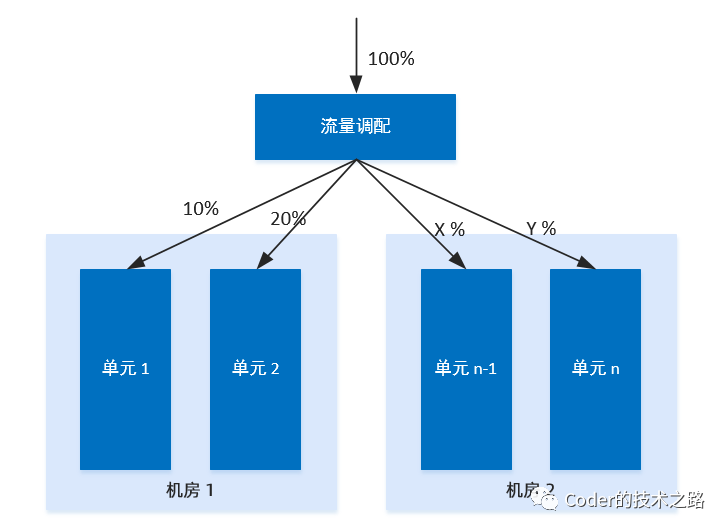
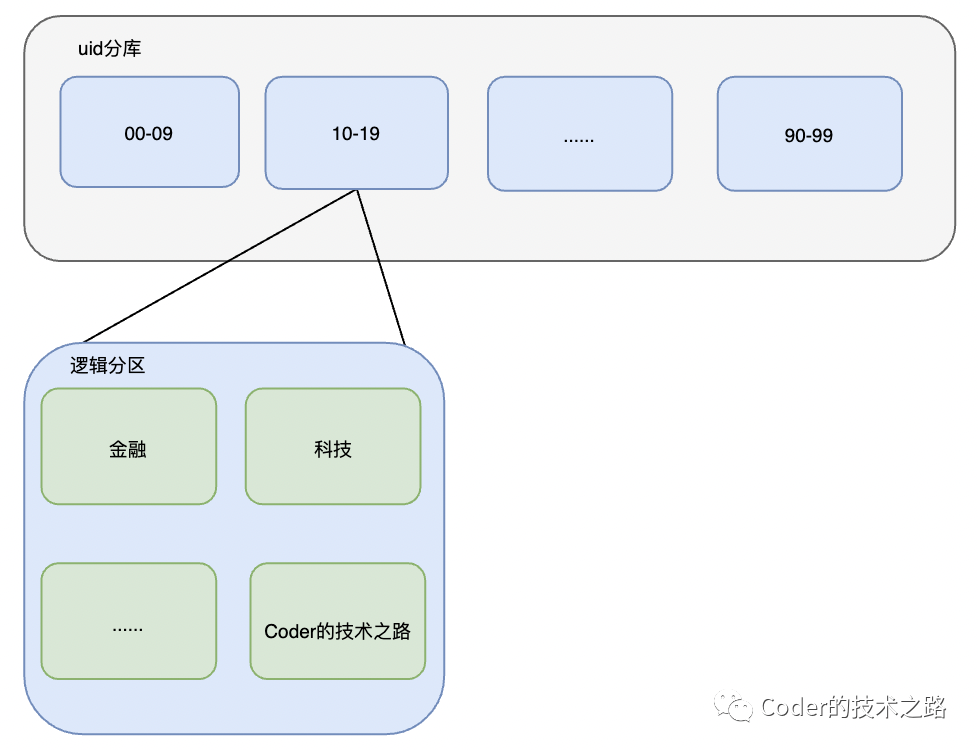
逻辑部署:借鉴蚂蚁单元化思想。将服务器在物理机房上进行逻辑机房部署:暂定5组逻辑机房,分别称为room00 ~ room04 , 每个逻辑机房分别处理uid固定两位为 00-19 20-39 40-59 60-79 80-99 范围内的用户请求。
<<< 左右滑动见更多 >>>
例 :uid : 1100xxxxx06 ,固定最后两位为路由位,则该用户请求落在room01的逻辑机房内的随机一台机器进行处理。
分析:假设用户分布和请求均匀,则,每个逻辑机房需要承载的读写请求并发量降为传统部署方式的1/5。每个逻辑机房又可以构建互备机房,满足机房容灾时的流量切换
存储设计
整体方案:数据存储考虑微博的时效性,设计为冷热数据分离,近期的微博热数据存储在mysql集群中,时间未半年前的旧数据,迁移至历史库,历史库考虑使用大数据操作支持良好的hbase存储。
冷热数据路由方案:微博创建时,将时间戳打入微博id,并固定其位置;在查询请求下发时,依赖解析微博id中的时间戳信息,得到冷热数据查询路由策略。
热数据部署:数据库分片按上述uid路由位 拆分为百库百表。
例:uid : 1100xxxxx06 ,微博ID则为,[xxxxxx时间戳xxxx06x] ,查询时,若时间戳是在一个月之内,则走mysql06库的06表;若时间戳在一个月之前,则走历史表。
分析:对于之前预估的1w/s写请求,此种拆分方法,即使是实时调用,单表的写并发也会降将为100/s。
缓存设计
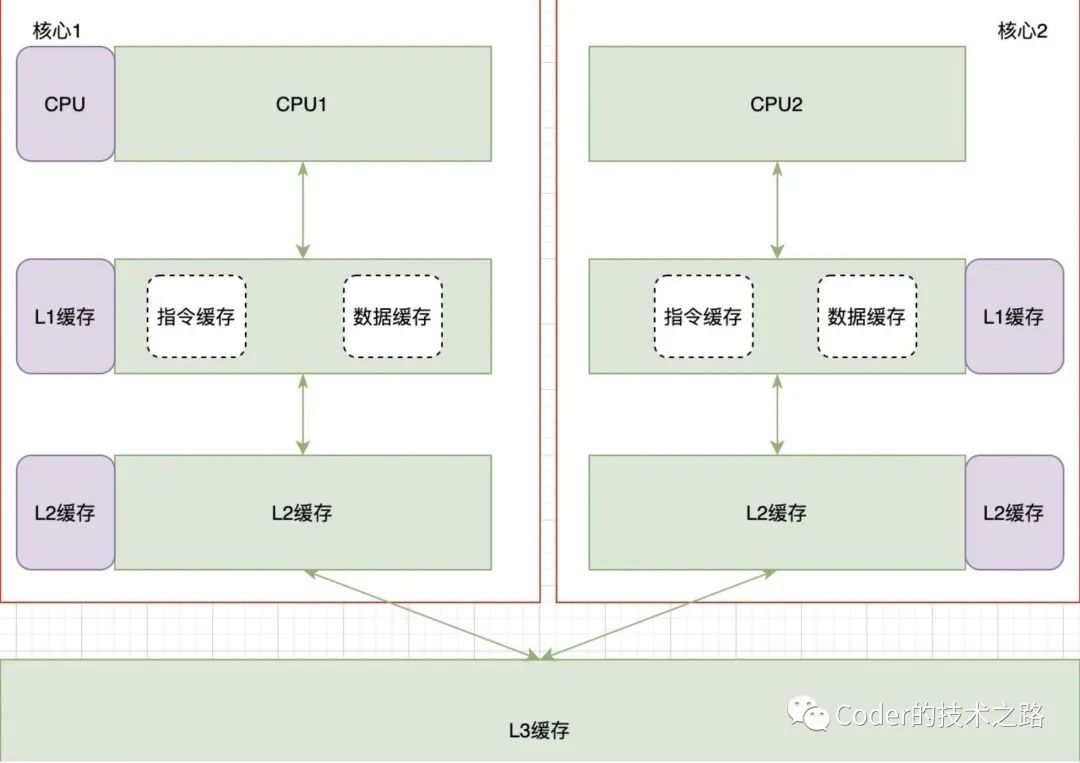
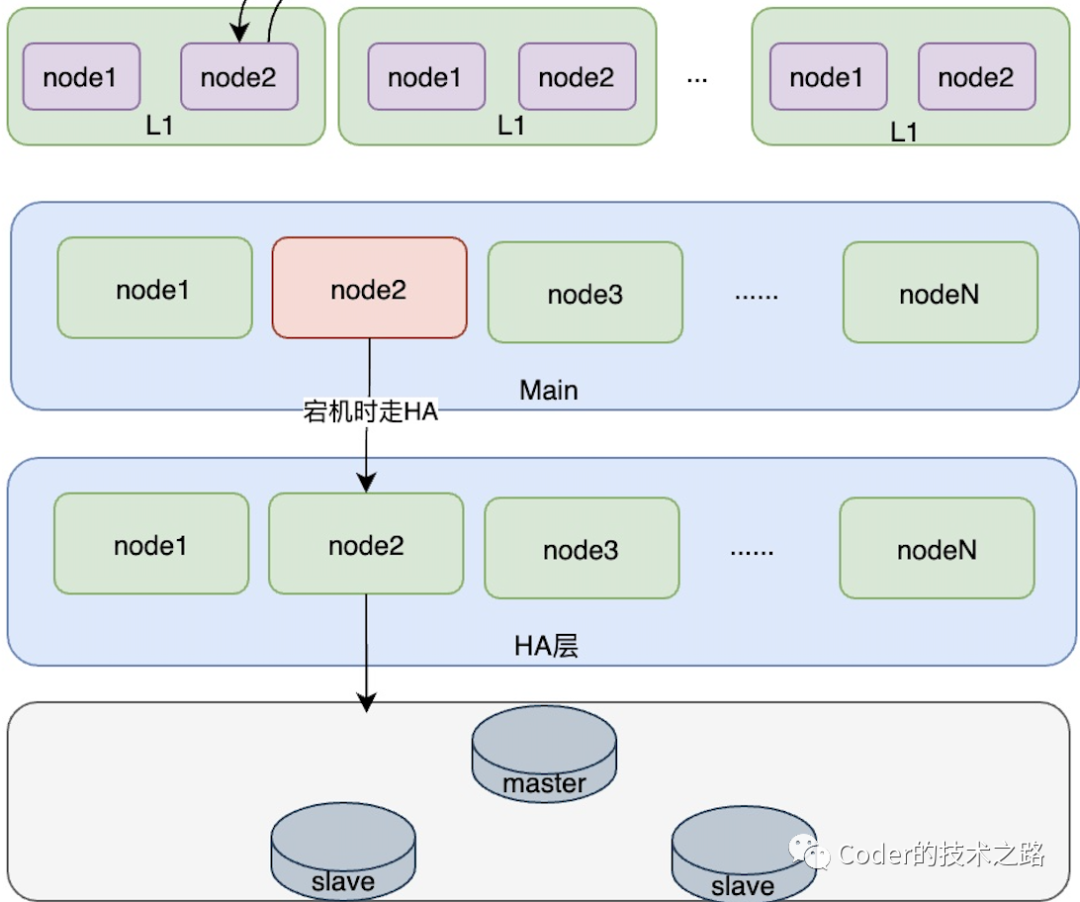
采用类CPU架构的多层缓存设计越新、越热的数据存储在离用户最近的L1层,用最小的代价来达到最大效果。
在L1下方另外设计两个缓存层,分别是主缓存层和高可用缓存层,存储全量数据。为什么不用一致性hash的集群方式呢?是因为一致性hash在某节点宕机时,会有缓存漂移和数据冗余,并且顺序下游节点会在短时间内承受宕机节点的所有压力,对微博的顺发流量场景是不友好的。
限流,防击穿设计
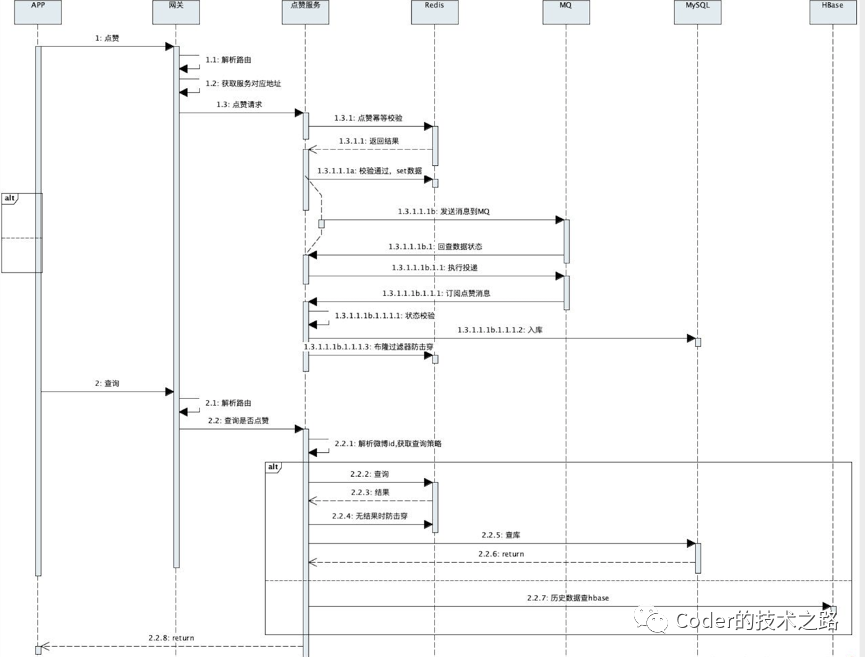
防击穿:查询用户对某微博的点赞信息时,先查缓存,如果缓存查询无结果,则需要经过布隆过滤器的校验,防止不存在的key查询数据库造成击穿。
限流:集群限流 + 单机限流(请求数 /cpu /load )
增长应对
按uid分库后,数据量达到上限时,可以按微博类型等业务特定维度进行二次逻辑拆分
容灾、故障转移
服务方面:因为采用单元化逻辑机房的方式,在路由分发时可以统一控制缓存方面:见’缓存设计‘部分,因为设计了main集群和HA集群,当main中的节点宕机时,会通过HA集群对应位置的节点应对故障。
吞吐量优化
可以考虑利用消息中间件,将同步写转为异步写,进一步提高系统吞吐量,通过事务消息的回查机制保证用户的操作行为不会丢失。
3.3整体交互流程设计
Part4点赞服务代码Demo
没骗你们吧,当时确实是写了demo的。
当然,也只能称为demo,因为各个地方的设计都还很糙,只能算思路,离真实实施还有不小距离。
计划后面有时间了把它在github上维护一下,一步步扩展成一个像样的东西,有兴趣的小伙伴到时候可以一起玩玩。
推荐👉 :周志明老师的又一神书!发现宝藏!