
Elasticsearch 聚合性能优化六大猛招
1、问题引出
默认情况下,Elasticsearch 已针对大多数用例进行了优化,确保在写入性能和查询性能之间取得平衡。我们将介绍一些聚合性能优化的可配置参数,其中部分改进是以牺牲写入性能为代价的。目标是将聚合优化招数汇总到一个易于消化的短文中,为大家的 Elasticsearch 集群聚合性能优化提供一些指导。
2、聚合实战问题
问题1:1天的数据 70W,聚合2次分桶正常查询时间是 200ms左右, 增加了一个去重条件, 就10-13秒了,有优化的地方不?
问题2:请问在很多 terms 聚合的情况下,怎样优化检索?我的场景在无聚合时,吞吐量有 300,在加入 12 个聚合字段后,吞吐量不到20。
问题3:哪位兄弟 帮忙发一个聚合优化的链接,我这个聚合 几千万 就好几秒了?
3、认知前提
3.1 Elasticsearch 聚合是不严格精准的
原因在于:数据分散到多个分片,聚合是每个分片的取 Top X,导致结果不精准。
可以看一下之前的文章:Elasticsearch 聚合数据结果不精确,怎么破?
3.2 从业务层面规避全量聚合
聚合结果的精准性和响应速度之间是相对矛盾的。
正常业务开发,产品经理往往要求:
第一:快速秒级或者毫秒级聚合响应。
第二:聚合结果精准。
殊不知,二者不可兼得。
遇到类似两者都要兼得的需求,建议从架构选型和业务层面做规避处理。
3.3 刷新频率
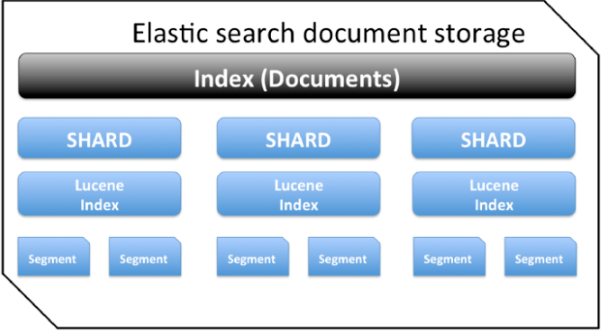
如下图所示,Elasticsearch 中的 1 个索引由一个或多个分片组成,每个分片包含多个segment(段),每一个段都是一个倒排索引。
在 lucene 中,为了实现高索引速度,使用了segment 分段架构存储。一批写入数据保存在一个段中,其中每个段最终落地为磁盘中的单个文件。
如下图所示,将文档插入 Elasticsearch 时,它们会被写入缓冲区中,然后在刷新时定期从该缓冲区刷新到段中。刷新频率由 refresh_interval 参数控制,默认每1秒发生一次。也就是说,新插入的文档在刷新到段(内存中)之前,是不能被搜索到的。
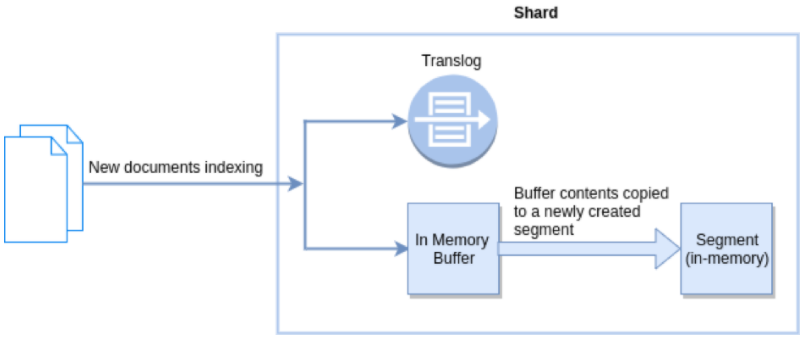
刷新的本质是:写入数据由内存 buffer 写入到内存段中,以保证搜索可见。
来看个例子,加深对 refresh_inteval 的理解,注释部分就是解读。
PUT test_0001/_doc/1
{
"title":"just testing"
}
# 默认一秒的刷新频率,秒级可见(用户无感知)
GET test_0001/_search
DELETE test_0001
# 设置了60s的刷新频率
PUT test_0001
{
"settings": {
"index":{
"refresh_interval":"60s"
}
}
}
PUT test_0001/_doc/1
{
"title":"just testing"
}
# 60s后才可以被搜索到
GET test_0001/_search
关于是否需要实时刷新:
如果新插入的数据需要近乎实时的搜索功能,则需要频繁刷新。
如果对最新数据的检索响应没有实时性要求,则应增加刷新间隔,以提高数据写入的效率,从而应释放资源辅助提高查询性能。
关于刷新频率对查询性能的影响:
由于每刷新一次都会生成一个 Lucene 段,刷新频率越小就意味着同样时间间隔,生成的段越多。
每个段都要消耗句柄和内存。
每次查询请求都需要轮询每个段,轮询完毕后再对结果进行合并。
也就意味着:refresh_interval 越小,产生的段越多,搜索反而会越慢;反过来说,加大 refresh_interval,会相对提升搜索性能。
4、聚合性能优化猛招
4.1 启用 eager global ordinals 提升高基数聚合性能
适用场景:高基数聚合。
高基数聚合场景中的高基数含义:一个字段包含很大比例的唯一值。
global ordinals 中文翻译成全局序号,是一种数据结构,应用场景如下:
基于 keyword,ip 等字段的分桶聚合,包含:terms聚合、composite 聚合等。
基于text 字段的分桶聚合(前提条件是:fielddata 开启)。
基于父子文档 Join 类型的 has_child 查询和 父聚合。
global ordinals 使用一个数值代表字段中的字符串值,然后为每一个数值分配一个 bucket(分桶)。
global ordinals 的本质是:启用 eager_global_ordinals 时,会在刷新(refresh)分片时构建全局序号。这将构建全局序号的成本从搜索阶段转移到了数据索引化(写入)阶段。
创建索引的同时开启:eager_global_ordinals。
PUT my-index-000001
{
"mappings": {
"properties": {
"tags": {
"type": "keyword",
"eager_global_ordinals": true
}
}
}
}
注意:开启 eager_global_ordinals 会影响写入性能,因为每次刷新时都会创建新的全局序号。为了最大程度地减少由于频繁刷新建立全局序号而导致的额外开销,请调大刷新间隔 refresh_interval。
动态调整刷新频率的方法如下:
PUT my-index-000001/_settings
{
"index": {
"refresh_interval": "30s"
}
}
该招数的本质是:以空间换时间。
4.2 插入数据时对索引进行预排序
Index sorting (索引排序)可用于在插入时对索引进行预排序,而不是在查询时再对索引进行排序,这将提高范围查询(range query)和排序操作的性能。
在 Elasticsearch 中创建新索引时,可以配置如何对每个分片内的段进行排序。
这是 Elasticsearch 6.X 之后版本才有的特性。
Index sorting 实战举例:
PUT my-index-000001
{
"settings": {
"index": {
"sort.field": "cur_time",
"sort.order": "desc"
}
},
"mappings": {
"properties": {
"cur_time": {
"type": "date"
}
}
}
}
如上示例是在:创建索引的设置部分设置待排序的字段:cur_time 以及 排序方式:desc 降序。
注意:预排序将增加 Elasticsearch 写入的成本。在某些用户特定场景下,开启索引预排序会导致大约 40%-50% 的写性能下降。
也就是说,如果用户场景更关注写性能的业务,开启索引预排序不是一个很好的选择。
4.3 使用节点查询缓存
节点查询缓存(Node query cache)可用于有效缓存过滤器(filter)操作的结果。如果多次执行同一 filter 操作,这将很有效,但是即便更改过滤器中的某一个值,也将意味着需要计算新的过滤器结果。
例如,由于 “now” 值一直在变化,因此无法缓存在过滤器上下文中使用 “now” 的查询。
那怎么使用缓存呢?通过在 now 字段上应用 datemath 格式将其四舍五入到最接近的分钟/小时等,可以使此类请求更具可缓存性,以便可以对筛选结果进行缓存。
关于 datemath 格式及用法,举个例子来说明:
以下的示例,无法使用缓存。
PUT index/_doc/1
{
"my_date": "2016-05-11T16:30:55.328Z"
}
GET index/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"my_date": {
"gte": "now-1h",
"lte": "now"
}
}
}
}
}
}
但是,下面的示例就可以使用节点查询缓存。
GET index/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"my_date": {
"gte": "now-1h/m",
"lte": "now/m"
}
}
}
}
}
}
上述示例中的“now-1h/m” 就是 datemath 的格式。
更细化点说,如果当前时间 now 是:16:31:29,那么range query 将匹配 my_date 介于:15:31:00 和 15:31:59 之间的时间数据。
同理,聚合的前半部分 query 中如果有基于时间查询,或者后半部分 aggs 部分中有基于时间聚合的,建议都使用 datemath 方式做缓存处理以优化性能。
4.4 使用分片请求缓存
聚合语句中,设置:size:0,就会使用分片请求缓存缓存结果。
size = 0 的含义是:只返回聚合结果,不返回查询结果。
GET /my_index/_search
{
"size": 0,
"aggs": {
"popular_colors": {
"terms": {
"field": "colors"
}
}
}
}
4.5 拆分聚合,使聚合并行化
这里有个认知前提:Elasticsearch 查询条件中同时有多个条件聚合,这个时候的多个聚合不是并行运行的。
这里就有疑问:是不是可以通过 msearch 拆解多个聚合为单个子语句来改善响应时间?
什么意思呢,给个 Demo,toy_demo_003 数据来源:
示例一:常规的多条件聚合实现
如下响应时间:15 ms。
POST toy_demo_003/_search
{
"size": 0,
"aggs": {
"hole_terms_agg": {
"terms": {
"field": "has_hole"
}
},
"max_aggs":{
"max":{
"field":"size"
}
}
}
}
示例二:msearch 拆分多个语句的聚合实现
如下响应时间:9 ms。
POST _msearch
{"index" : "toy_demo_003"}
{"size":0,"aggs":{"hole_terms_agg":{"terms":{"field":"has_hole"}}}}
{"index" : "toy_demo_003"}
{"size":0,"aggs":{"max_aggs":{"max":{"field":"size"}}}}
来个对比验证吧:

蓝色:类似示例一,单个query 中包含多个聚合,聚合数分别是:1,2,5,10。
红色:类似示例二,multi_search 拆解多个聚合,拆分子句个数分别为:1,2,5,10。
横轴:蓝色对应聚合个数;红色对应子句个数;
纵轴:响应时间,响应时间越短、性能越好。
初步结论是:
默认情况下聚合不是并行运行。
当为每个聚合提供自己的查询并执行 msearch 时,性能会有显著提升。
尤其在 10 个聚合的场景下,性能提升了接近 2 倍。
因此,在 CPU 资源不是瓶颈的前提下,如果想缩短响应时间,可以将多个聚合拆分为多个查询,借助:msearch 实现并行聚合。
4.6 将聚合中的查询条件移动到 query 子句部分
示例一:
POST my_index/_search
{
"size": 0,
"aggregations": {
"1": {
"filter": {
"match": {
"search_field": "text"
}
},
"aggregations": {
"items": {
"top_hits": {
"size": 100,
"_source": {
"includes": "field1"
}
}
}
}
},
"2": {
"filter": {
"match": {
"search_field": "text"
}
},
"aggregations": {
"items": {
"top_hits": {
"size": 100,
"_source": {
"includes": "field2"
}
}
}
}
}
}
}
示例二:
{
"query": {
"bool": {
"filter": [
{
"match": {
"search_field": "text"
}
}
]
}
},
"size": 0,
"aggregations": {
"1": {
"top_hits": {
"size": 100,
"_source": {
"includes": "field1"
}
}
},
"2": {
"top_hits": {
"size": 100,
"_source": {
"includes": "field2"
}
}
}
}
}
示例一和示例二的本质区别:
第二个查询已将此过滤器提取到较高级别,这应使聚合共享结果。
如下对比实验表明,由于 Elasticsearch 自身做了优化,示例一(蓝色)和示例二(红色)响应时间基本一致。

更多验证需要结合业务场景做一下对比验证,精简起见,推荐使用第二种。
5、更多优化参考
官方关于检索性能优化同样适用于聚合
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-search-speed.html
分片数设置多少合理?
https://www.elastic.co/cn/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
堆内存大小设置?
https://www.elastic.co/cn/blog/a-heap-of-trouble
禁用 swapping
https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-configuration-memory.html
6、小结
本文的六大猛招出自:Elastic 原厂咨询架构师 Alexander 以及 Coolblue 公司的软件开发工程师 Raoul Meyer。
六大猛招中的 msearch 并行聚合方式,令人眼前一亮,相比我在业务实战中用的多线程方式实现并行,要“高级”了许多。
我结合自己的聚合优化实践做了翻译和扩展,希望对大家的聚合性能优化有所帮助。
欢迎留言写下您的聚合优化实践和思考。
和你一起,死磕 Elastic!
参考
https://qbox.io/blog/refresh-flush-operations-elasticsearch-guide
https://alexmarquardt.com/how-to-tune-elasticsearch-for-aggregation-performance/
https://www.elastic.co/cn/blog/index-sorting-elasticsearch-6-0
《Elasticsearch 源码解析与优化实战》
推荐
中国最大的 Elastic 非官方公众号
点击查看“阅读原文”,和全球近1000 位 Elastic 爱好者一起每日精进 ELK 技能!