
如何实现删除重复记录并且只保留一条?
点击上方 泥瓦匠 关注我!

最近,在做题库系统,由于在题库中添加了重复的试题,所以需要查询出重复的试题,并且删除掉重复的试题只保留其中1条,以保证考试的时候抽不到重复的题。
一、单个字段的操作
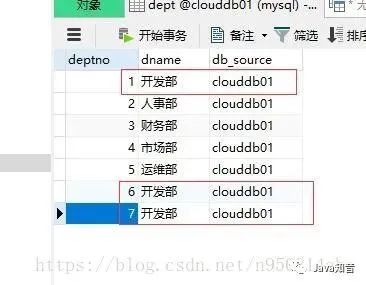
分组介绍
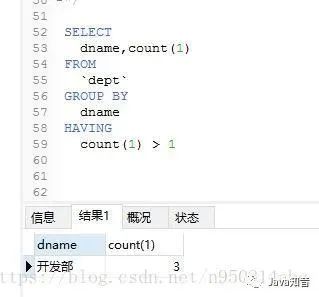
Select 重复字段 From 表 Group By 重复字段 Having Count(*)>1GROUP BY <列名序列>
HAVING <组条件表达式>
1. 查询全部重复的数据
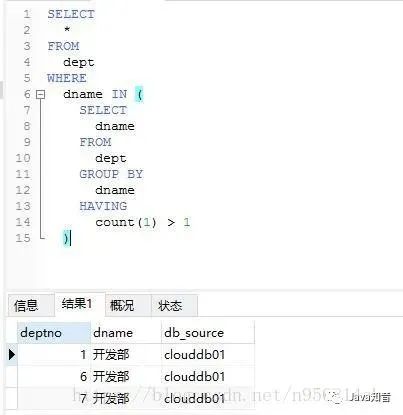
Select * From 表 Where 重复字段 In (Select 重复字段 From 表 Group By 重复字段 Having Count(*)>1)2. 删除全部重复试题
DELETEFROMdeptWHEREdname IN (SELECTdnameFROMdeptGROUP BYdnameHAVINGcount(1) > 1)
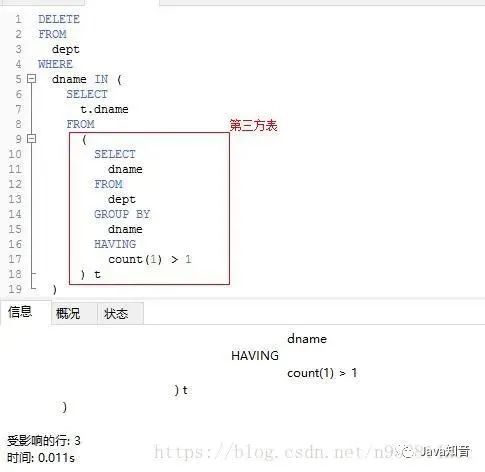
3. 查询表中多余重复试题(根据depno来判断,除了rowid最小的一个)
a. 第一种方法
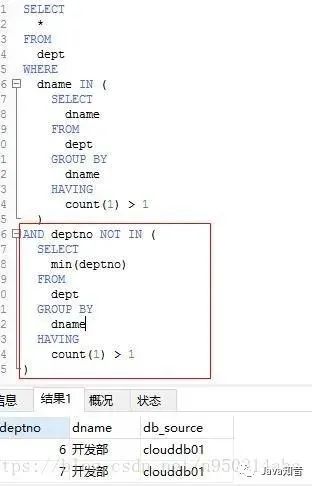
SELECT*FROMdeptWHEREdname IN (SELECTdnameFROMdeptGROUP BYdnameHAVINGCOUNT(1) > 1)AND deptno NOT IN (SELECTMIN(deptno)FROMdeptGROUP BYdnameHAVINGCOUNT(1) > 1)
b. 第二种方法
SELECT *FROMdeptWHEREdeptno NOT IN (SELECTdt.minnoFROM(SELECTMIN(deptno) AS minnoFROMdeptGROUP BYdname) dt)
c. 补充第三种方法
SELECT*FROMtable_name AS taWHEREta.唯一键 <> ( SELECT max( tb.唯一键 ) FROM table_name AS tb WHERE ta.判断重复的列 = tb.判断重复的列 );
4. 删除表中多余重复试题并且只留1条
a. 第一种方法:
DELETEFROMdeptWHEREdname IN (SELECTt.dnameFROM(SELECTdnameFROMdeptGROUP BYdnameHAVINGcount(1) > 1) t)AND deptno NOT IN (SELECTdt.mindeptnoFROM(SELECTmin(deptno) AS mindeptnoFROMdeptGROUP BYdnameHAVINGcount(1) > 1) dt)
b. 第二种方法(与上面查询的第二种方法对应,只是将select改为delete)
DELETEFROMdeptWHEREdeptno NOT IN (SELECTdt.minnoFROM(SELECTMIN(deptno) AS minnoFROMdeptGROUP BYdname) dt)
c. 补充第三种方法(评论区推荐的一种方法)
DELETEFROMtable_name AS taWHEREta.唯一键 <> (SELECTt.maxidFROM( SELECT max( tb.唯一键 ) AS maxid FROM table_name AS tb WHERE ta.判断重复的列 = tb.判断重复的列 ) t);
二、多个字段的操作
DELETEFROMdeptWHERE(dname, db_source) IN (SELECTt.dname,t.db_sourceFROM(SELECTdname,db_sourceFROMdeptGROUP BYdname,db_sourceHAVINGcount(1) > 1) t)AND deptno NOT IN (SELECTdt.mindeptnoFROM(SELECTmin(deptno) AS mindeptnoFROMdeptGROUP BYdname,db_sourceHAVINGcount(1) > 1) dt)
# 总结
在经常查询的字段上加上索引
将*改为你需要查询出来的字段,不要全部查询出来
小表驱动大表用IN,大表驱动小表用EXISTS。IN适合的情况是外表数据量小的情况,而不是外表数据大的情况,因为IN会遍历外表的全部数据,假设a表100条,b表10000条那么遍历次数就是100*10000次,而exists则是执行100次去判断a表中的数据是否在b表中存在,它只执行了a.length次数。至于哪一个效率高是要看情况的,因为in是在内存中比较的,而exists则是进行数据库查询操作的。

往期推荐
下方二维码关注我

技术草根,坚持分享 编程,算法,架构
评论