
来源 | TechFlow(ID:techflow2019)不知道大家有没有过这样的经历,有时候我们聊天聊到了某个商品,没过多久,一些电商类APP就推荐了相关商品。比如有一次我和老婆刚聊了某个话题,知乎没过几分钟就给了一个弹窗,如何看待XX……我当时的第一反应是很惊讶,觉得有点不可思议,就好像发现自家的机器人会说话一样。但转念就有点不爽,觉得这货是不是在偷听我说话。后来打开APP一查,果然,知乎这货不知道什么时候申请了麦克风的权限。再一看,其实并不止知乎,拥有麦克风权限的还有很多。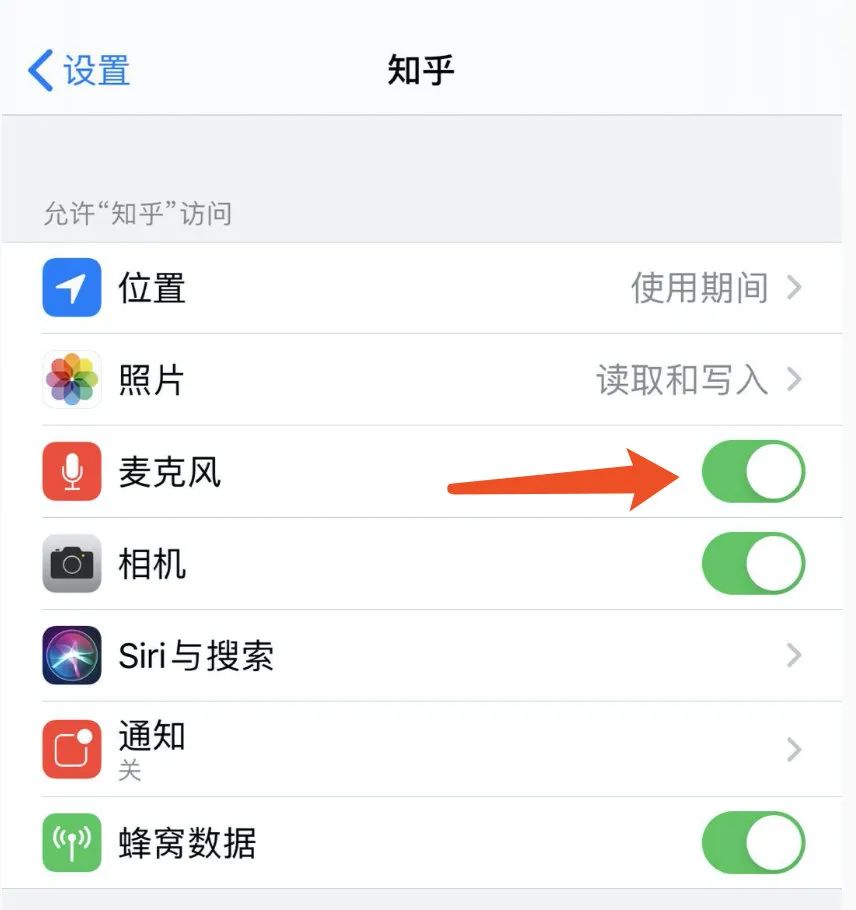 我去网上一搜,关键词知乎 偷听能搜出来很多,不止有知乎,还有一些其他著名的APP。很多人带节奏,还有一些无良公众号写文章,说这些巨头公司正在侵犯用户的隐私,在“耳奸”用户。还有些人畅想未来,说这些公司可以通过偷窥用户的喜好给用户定制他们看到的信息,从而操控人们的思想……虽然这些话有些危言耸听,但是是不是可以实锤这些APP偷偷摸摸搞一些小动作呢?冷静下来稍微一想,我就放弃了这个想法。其实原因也很简单,我们可以从操作系统和算法两个角度得到同样的结论。
我去网上一搜,关键词知乎 偷听能搜出来很多,不止有知乎,还有一些其他著名的APP。很多人带节奏,还有一些无良公众号写文章,说这些巨头公司正在侵犯用户的隐私,在“耳奸”用户。还有些人畅想未来,说这些公司可以通过偷窥用户的喜好给用户定制他们看到的信息,从而操控人们的思想……虽然这些话有些危言耸听,但是是不是可以实锤这些APP偷偷摸摸搞一些小动作呢?冷静下来稍微一想,我就放弃了这个想法。其实原因也很简单,我们可以从操作系统和算法两个角度得到同样的结论。

操作系统
从操作系统层面来说,不管你代码怎么写的,所有的程序肯定都是要受到操作系统调度的。不论是线程也好、进程也罢,莫不如此。我们假设某一个APP偷偷设计了一个小动作,在后台录音监听用户的日常。但是录音并不是代码运行就可以完成的,它需要调取硬件——麦克风。也就是说必须要获取麦克风的权限,这一步是非常敏感的操作,现在的手机系统都对此做了非常强的限制,如果在后台录音,一定会有明显的状态提示。拿苹果举例,会是这样: 看到左上角的红点了吗,只要是后台的进程开启了录音,那么一定会有这个提示。因为获取麦克风录音这是一个系统级的服务,应用程序自己是没有驱动也没有办法访问麦克风的,必须要通过调用操作系统提供的接口,这一步是无论如何绕不过去的。安卓我不是非常清楚,但是据说也有相关的限制。只要我们亲自试一下,很容易发现,这是不可能办到的。除非这些APP厂商有能力把苹果的系统给黑了,这显然也是不现实的。因为这些APP在提交APP store的时候都会有严格的审核和检测,并不是厂商想怎么实现功能就怎么实现的,有很多的限制条件。另外一点就是电池的电量,对于手机来说,像是摄像头、麦克风这些硬件都是非常耗电的。大家如果打过长时间的微信电话应该都有体会,这些APP在后台偷听其实和我们打微信电话是一样的,都需要大量耗电,录音超过半个小时一定会开始发热,这也是不可能不被我们注意到的。并且对于苹果用户来说,苹果的系统的多进程其实很多时候是伪后台。当一个进程挂起在后台超过一定时间就会直接被操作系统kill,我们虽然看起来它还在后台,但其实早就不在运行了。据说安卓这两年也加强了后台进程的管理,但是具体的执行情况我不是很了解,毕竟也没怎么使用过,大家如果知道可以在评论区留言补充。所以到这里,我们从操作系统这一条路就直接把APP偷听的可能性给堵死了,另外我们也可以从算法层面分析一下这么做的得失。
看到左上角的红点了吗,只要是后台的进程开启了录音,那么一定会有这个提示。因为获取麦克风录音这是一个系统级的服务,应用程序自己是没有驱动也没有办法访问麦克风的,必须要通过调用操作系统提供的接口,这一步是无论如何绕不过去的。安卓我不是非常清楚,但是据说也有相关的限制。只要我们亲自试一下,很容易发现,这是不可能办到的。除非这些APP厂商有能力把苹果的系统给黑了,这显然也是不现实的。因为这些APP在提交APP store的时候都会有严格的审核和检测,并不是厂商想怎么实现功能就怎么实现的,有很多的限制条件。另外一点就是电池的电量,对于手机来说,像是摄像头、麦克风这些硬件都是非常耗电的。大家如果打过长时间的微信电话应该都有体会,这些APP在后台偷听其实和我们打微信电话是一样的,都需要大量耗电,录音超过半个小时一定会开始发热,这也是不可能不被我们注意到的。并且对于苹果用户来说,苹果的系统的多进程其实很多时候是伪后台。当一个进程挂起在后台超过一定时间就会直接被操作系统kill,我们虽然看起来它还在后台,但其实早就不在运行了。据说安卓这两年也加强了后台进程的管理,但是具体的执行情况我不是很了解,毕竟也没怎么使用过,大家如果知道可以在评论区留言补充。所以到这里,我们从操作系统这一条路就直接把APP偷听的可能性给堵死了,另外我们也可以从算法层面分析一下这么做的得失。

算法层面
在很多不懂行的人眼里,算法无所不能,人工智能那是真的智能,就真的和有一个人住在手机里偷听一样。显然那是不现实的,算法也好,机器学习深度学习的模型也罢,本质上也是程序。只要是程序不管看起来多智能,本质上仍然是遵循已经制定好的模式。我这么说大家可能get不到,我们不妨来思考这么一个问题,从麦克风读入的声音数据,怎么转化成APP所需要的数据呢?直接从语音进行分析是比较困难的,常规的做法都是先通过语音识别算法转成文本,之后再对文本进行内容分析。因为我们文本分析的算法和手段都比较多,而直接分析语音则比较困难。并且我们语音分析现在也已经比较成熟了,国内顶尖的是科大讯飞, 大家可以试试科大讯飞的讯飞输入法里面的语音转文字的功能,识别速度和准确率都还不错。但问题是如果是偷偷录音的话,是很难保证收音效果的,不用想肯定充满了杂音。在这种情况下是很难保证语音识别之后的文本质量,退一步来说即使不存在这个问题,所有的文字都能识别准确,但是其中有价值的内容太少了。因为我们生活中大部分说的话都是闲言碎语,有价值的含量并不高。比如就拿电商APP来说好了,我们日常用语当中又有多少是我们感兴趣的商品意图呢?这些意图又怎么识别呢?这些都是问题。即使能够识别,又该怎么计算呢?是在用户本地计算吗,还是上传到云端呢?本地计算显然是不行的,因为深度学习模型的运算量不小,只靠手机的性能十有八九是不够的。如果传到云端呢?语音文件算法不算很大,但是日积月累消耗的流量也是不小的,用户真的不会察觉吗?以目前业内的情况来说,算法对于用户兴趣的识别准确率远远没有大家想象的高。再加上噪音的折损,脏数据的干扰,最终得到的准确率是非常非常低的,低到几乎完全不能用的地步。你们要是不信去买个天猫精灵回来试试看就知道了,天猫精灵在我家已经被我叫做笨猫精灵了,它完全意识不到还应对得很开心。而且这些APP完全根本不需要用这样下作的方法就可以知道我们是谁,我们对什么内容感兴趣。比如淘宝有你所有的消费记录,还有你的地理位置信息,知道你在哪里你的消费能力怎么样。甚至还可以从你的行为上推断出你有没有车有没有房,你在哪里上班。这些信息获取的渠道都是正当合法的,既然通过合法的信息就能猜到你大概喜欢什么样的,又何必去铤而走险呢?

风险
虽然我们分析已经有了结论,但是仍然免不了问一句,假使以后科技发展,使得我们对于用户的语音识别以及兴趣识别可以做得更加准确,会产生这样的情况吗?其实也是不会的,这里面的道理也很好理解。对于大公司而言,对于用户的数据的保密程度是非常高的,比大家想得还要严格。之前在阿里的时候,就连自己的数据都是不能随意查的,除非有正当的工作需要,否则被发现了都是要承担责任的。之所以会这么严格,一方面是国家社会的要求,另外一方面这和公司自己的利益也是一致的。一旦偷听这种事情曝光,带来的负面影响对公司的股价以及形象的伤害是非常非常大的,像是阿里这样的公司,股价一有波动至少是数十亿美元的损失。别说偷听猜不透我们的喜好,即使能猜透又能带来多少的利润呢?双十一、双十二搞搞促销不香吗?正当的钱都挣不过来,为什么要走歪路?当今互联网的大公司都是掌控着媒体的力量的,真要敢这么搞,不是给竞争对手送炮弹吗?所以你看说起来有鼻子有眼,但其实根本经不住推敲和分析,生活中这样的事情很多,稍不留心很容易就被忽悠了。希望大家生活中遇到事情的时候能多想一想,不要被别有用心的人忽悠了。END
《大厂逆袭之路》第一期系列文
 下载APP
下载APP