
4种 Redis 集群方案介绍+优缺点对比
点击上方“码农突围”,马上关注 这里是码农充电第一站,回复“666”,获取一份专属大礼包 真爱,请设置“星标”或点个“在看”

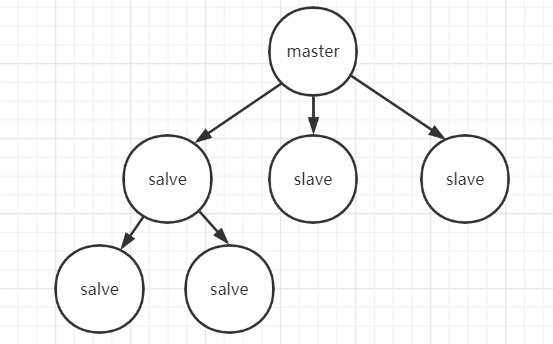
1.主从模式
主从模式优缺点
优点: 主从结构具有读写分离,提高效率、数据备份,提供多个副本等优点。
不足: 最大的不足就是主从模式不具备自动容错和恢复功能,主节点故障,集群则无法进行工作,可用性比较低,从节点升主节点需要人工手动干预。
在从数据库中使用
SLAVE NO ONE命令将从数据库提升成主数据继续服务。启动之前崩溃的主数据库,然后使用SLAVEOF命令将其设置成新的主数据库的从数据库,即可同步数据。
2.哨兵模式
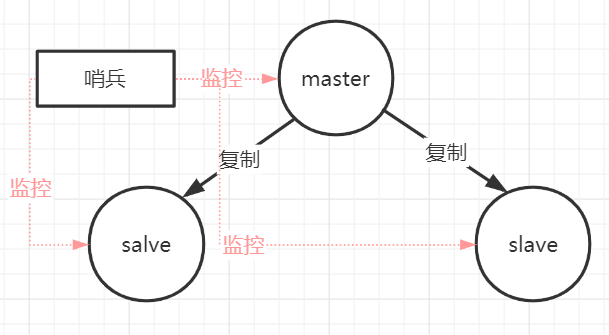
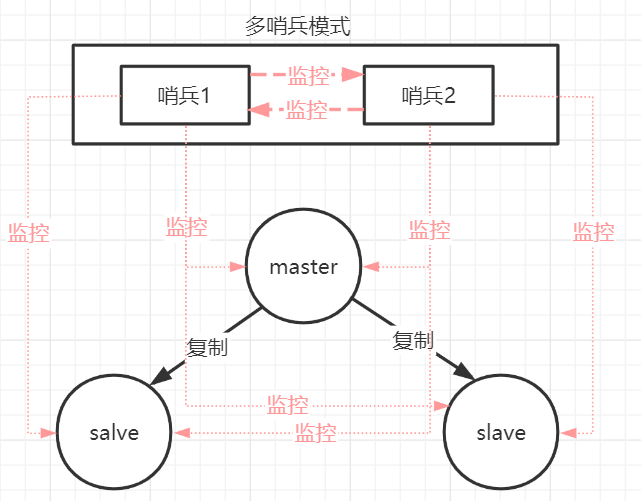
(1)哨兵模式的作用:
(2)哨兵实现原理
sentinel monitor master-name ip port quorum
#master-name是主数据库的名字
#ip和port 是当前主数据库地址和端口号
#quorum表示在执行故障切换操作前,需要多少哨兵节点同意。
订阅主数据库
_sentinel_:hello频道以获取同样监控该数据库的哨兵节点信息定期向主数据库发送info命令,获取主数据库本身的信息。
_sentinel_:hello频道发送自己的信息。作用是将自己的监控数据和哨兵分享。每个哨兵会订阅数据库的_sentinel:hello频道,当其他哨兵收到消息后,会判断该哨兵是不是新的哨兵,如果是则将其加入哨兵列表,并建立连接。(3)主观下线和客观下线
down-after-millisecond)后,如果节点未回复,则哨兵认为主观下线。主观下线表示当前哨兵认为该节点已经下面,如果该节点为主数据库,哨兵会进一步判断是够需要对其进行故障切换,这时候就要发送命令(SENTINEL is-master-down-by-addr)询问其他哨兵节点是否认为该主节点是主观下线,当达到指定数量(quorum)时,哨兵就会认为是客观下线。选出领头哨兵。
领头哨兵所有的slave选出优先级最高的从数据库。优先级可以通过
slave-priority选项设置。如果优先级相同,则从复制的命令偏移量越大(即复制同步数据越多,数据越新),越优先。
如果以上条件都一样,则选择run ID较小的从数据库。
slave no one命令升级为主数据库,并发送slaveof命令将其他从节点的主数据库设置为新的主数据库。(4)哨兵模式优缺点
哨兵模式是基于主从模式的,解决可主从模式中master故障不可以自动切换故障的问题。
是一种中心化的集群实现方案:始终只有一个Redis主机来接收和处理写请求,写操作受单机瓶颈影响。
集群里所有节点保存的都是全量数据,浪费内存空间,没有真正实现分布式存储。数据量过大时,主从同步严重影响master的性能。
Redis主机宕机后,哨兵模式正在投票选举的情况之外,因为投票选举结束之前,谁也不知道主机和从机是谁,此时Redis也会开启保护机制,禁止写操作,直到选举出了新的Redis主机。
3.各大厂的Redis集群方案
(1)客户端分片
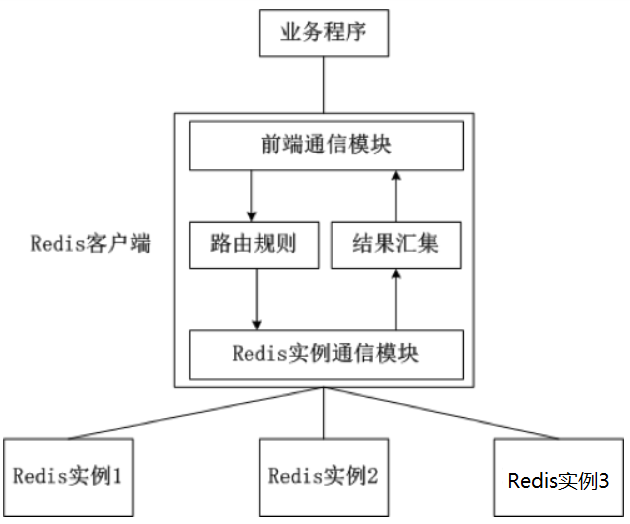
1.一致性哈希算法:
2.实现方式:一致性hash算法,比如MURMUR_HASH散列算法、ketamahash算法
这是一种静态的分片方案,需要增加或者减少Redis实例的数量,需要手工调整分片的程序。
运维成本比较高,集群的数据出了任何问题都需要运维人员和开发人员一起合作,减缓了解决问题的速度,增加了跨部门沟通的成本。
在不同的客户端程序中,维护相同的路由分片逻辑成本巨大。比如:java项目、PHP项目里共用一套Redis集群,路由分片逻辑分别需要写两套一样的逻辑,以后维护也是两套。
(2)代理分片
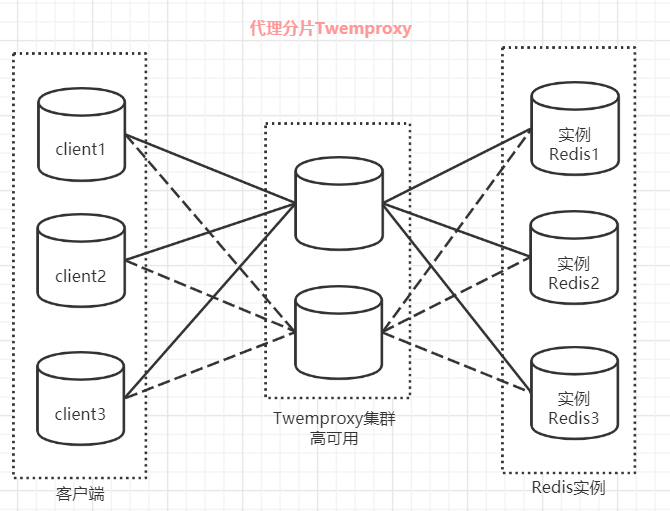
Twemproxy的优点:
客户端像连接Redis实例一样连接Twemproxy,不需要改任何的代码逻辑。
支持无效Redis实例的自动删除。
Twemproxy与Redis实例保持连接,减少了客户端与Redis实例的连接数。
Twemproxy的不足:
由于Redis客户端的每个请求都经过Twemproxy代理才能到达Redis服务器,这个过程中会产生性能损失。
没有友好的监控管理后台界面,不利于运维监控。
Twemproxy最大的痛点在于,无法平滑地扩容/缩容。对于运维人员来说,当因为业务需要增加Redis实例时工作量非常大。
(3)Codis
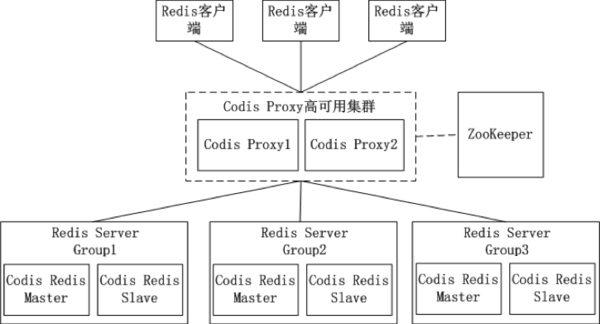
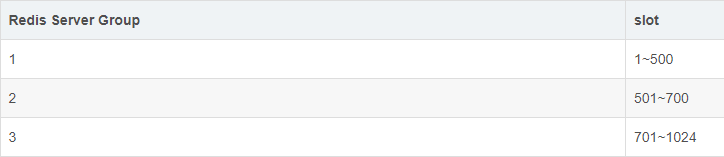
Redis Server Group,其通过指定一个主CodisRedis和一个或多个从CodisRedis,实现了Redis集群的高可用。当一个主CodisRedis挂掉时,Codis不会自动把一个从CodisRedis提升为主CodisRedis,这涉及数据的一致性问题(Redis本身的数据同步是采用主从异步复制,当数据在主CodisRedis写入成功时,从CodisRedis是否已读入这个数据是没法保证的),需要管理员在管理界面上手动把从CodisRedis提升为主CodisRedis。Codis-ha,这个工具会在检测到主CodisRedis挂掉的时候将其下线并提升一个从CodisRedis为主CodisRedis。crc32(key)%1024”获得一个数字,这个数字的范围一定是1~1024之间,Key就放到这个数字对应的slot。crc32(key)%1024”得到的数字是5,就放到编码为5的slot(箱子)。1个slot只能放1个Redis Server Group,不能把1个slot放到多个Redis Server Group中。1个Redis Server Group最少可以存放1个slot,最大可以存放1024个slot。因此,Codis中最多可以指定1024个Redis Server Group。Redis Server Group(Redis实例),能安全、透明地迁移数据,这也是Codis 有别于Twemproxy等静态分布式 Redis 解决方案的地方。Codis增加了Redis Server Group后,就牵涉到slot的迁移问题。Redis Server Group,Redis Server Group和slot的对应关系如下。
4.Redis Cluster
哨兵模式下每台 Redis 服务器都存储相同的数据,很浪费内存空间;数据量太大,主从同步时严重影响了master性能。
哨兵模式是中心化的集群实现方案,每个从机和主机的耦合度很高,master宕机到salve选举master恢复期间服务不可用。
哨兵模式始终只有一个Redis主机来接收和处理写请求,写操作还是受单机瓶颈影响,没有实现真正的分布式架构。
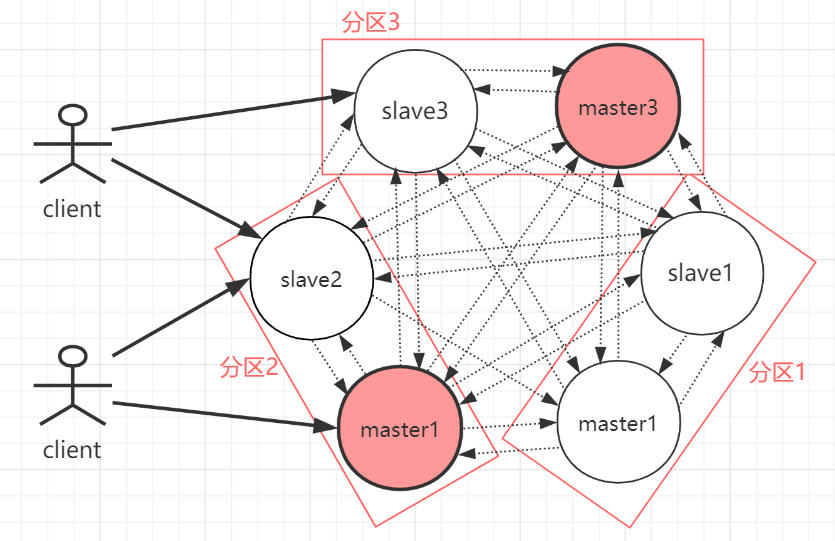
集群完全去中心化,采用多主多从;所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
客户端与 Redis 节点直连,不需要中间代理层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
每一个分区都是由一个Redis主机和多个从机组成,分片和分片之间是相互平行的。
每一个master节点负责维护一部分槽,以及槽所映射的键值数据;集群中每个节点都有全量的槽信息,通过槽每个node都知道具体数据存储到哪个node上。
(完)
码农突围资料链接
1、卧槽!字节跳动《算法中文手册》火了,完整版 PDF 开放下载!
2、计算机基础知识总结与操作系统 PDF 下载
3、艾玛,终于来了!《LeetCode Java版题解》.PDF
4、Github 10K+,《LeetCode刷题C/C++版答案》出炉.PDF欢迎添加鱼哥个人微信:smartfish2020,进粉丝群或围观朋友圈