
谈谈Redis的各种集群方案、及优缺点对比
你知道的越多,不知道的就越多,业余的像一棵小草!
成功路上并不拥挤,因为坚持的人不多。
编辑:业余草
blog.csdn.net/Seky_fei
推荐:https://www.xttblog.com/?p=5231
在服务开发中,单机都会存在单点故障的问题,及服务部署在一台服务器上,一旦服务器宕机服务就不可用,所以为了让服务高可用,分布式服务就出现了,将同一服务部署到多台机器上,即使其中几台服务器宕机,只要有一台服务器可用服务就可用。
Redis 也是一样,为了解决单机故障引入了主从模式,但主从模式存在一个问题:master 节点故障后服务,需要人为的手动将 slave 节点切换成为 master 节点后服务才恢复。Redis 为解决这一问题又引入了哨兵模式,哨兵模式能在 master 节点故障后能自动将 slave 节点提升成 master 节点,不需要人工干预操作就能恢复服务可用。但是主从模式、哨兵模式都没有达到真正的数据 sharding 存储,每个 Redis 实例中存储的都是全量数据,所以 Redis cluster 就诞生了,实现了真正的数据分片存储。但是由于 Redis cluster 发布得比较晚(2015 年才发布正式版 ),各大厂等不及了,陆陆续续开发了自己的 Redis 数据分片集群模式,比如:Twemproxy、Codis 等。
主从模式
Redis 单节点虽然有通过 RDB 和 AOF 持久化机制能将数据持久化到硬盘上,但数据是存储在一台服务器上的,如果服务器出现硬盘故障等问题,会导致数据不可用,而且读写无法分离,读写都在同一台服务器上,请求量大时会出现 I/O 瓶颈。
为了避免单点故障 和 读写不分离,Redis 提供了复制(replication)功能实现 master 数据库中的数据更新后,会自动将更新的数据同步到其他 slave 数据库上。
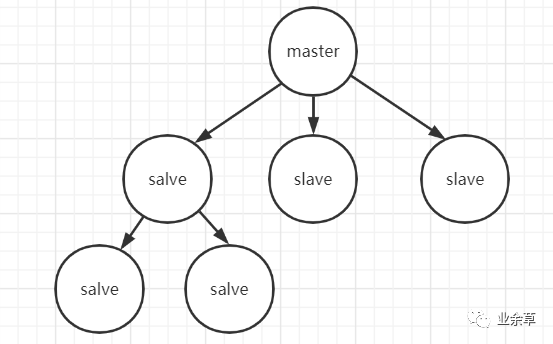
如上 Redis 主从结构特点:一个 master 可以有多个 slave 节点;slave 节点可以有 slave 节点,从节点是级联结构。
主从模式优缺点
「优点:」 主从结构具有读写分离,提高效率、数据备份,提供多个副本等优点。 「不足:」 最大的不足就是主从模式不具备自动容错和恢复功能,主节点故障,集群则无法进行工作,可用性比较低,从节点升主节点需要人工手动干预。
普通主从
普通的主从模式,当主数据库崩溃时,需要手动切换从数据库成为主数据库:
在从数据库中使用 SLAVE NO ONE命令将从数据库提升成主数据继续服务。启动之前崩溃的主数据库,然后使用 SLAVEOF命令将其设置成新的主数据库的从数据库,即可同步数据。
哨兵模式
第一种主从同步/复制的模式,当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用,这时候就需要哨兵模式登场了。哨兵模式是从 Redis 的 2.6 版本开始提供的,但是当时这个版本的模式是不稳定的,直到 Redis 的 2.8 版本以后,这个哨兵模式才稳定下来。
哨兵模式核心还是主从复制,只不过在相对于主从模式在主节点宕机导致不可写的情况下,多了一个**竞选机制:**从所有的从节点竞选出新的主节点。竞选机制的实现,是依赖于在系统中启动一个 sentinel 进程。
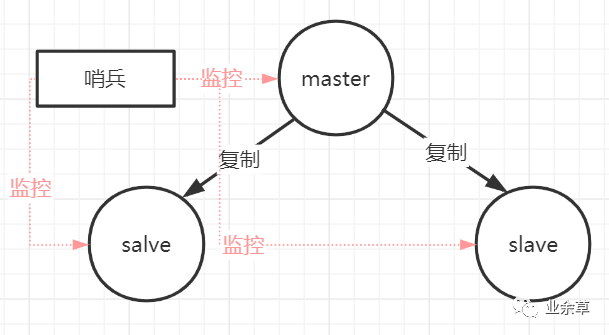
如上图,哨兵本身也有单点故障的问题,所以在一个一主多从的 Redis 系统中,可以使用多个哨兵进行监控,哨兵不仅会监控主数据库和从数据库,哨兵之间也会相互监控。每一个哨兵都是一个独立的进程,作为进程,它会独立运行。

哨兵模式的作用:
监控所有服务器是否正常运行:通过发送命令返回监控服务器的运行状态,处理监控主服务器、从服务器外,哨兵之间也相互监控。
故障切换:当哨兵监测到 master 宕机,会自动将 slave 切换成 master,然后通过「发布订阅模式」通知其他的从服务器,修改配置文件,让它们切换 master。同时那台有问题的旧主也会变为新主的从,也就是说当旧的主即使恢复时,并不会恢复原来的主身份,而是作为新主的一个从。
哨兵实现原理
哨兵在启动进程时,会读取配置文件的内容,通过如下的配置找出需要监控的主数据库:
sentinel monitor master-name ip port quorum
# master-name 是主数据库的名字
# ip 和 port 是当前主数据库地址和端口号
# quorum 表示在执行故障切换操作前,需要多少哨兵节点同意。
这里之所以只需要连接主节点,是因为通过主节点的 info 命令,获取从节点信息,从而和从节点也建立连接,同时也能通过主节点的 info 信息知道新增从节点的信息。
一个哨兵节点可以监控多个主节点,但是并不提倡这么做,因为当哨兵节点崩溃时,同时有多个集群切换会发生故障。哨兵启动后,会与主数据库建立两条连接。
订阅主数据库 _sentinel_:hello频道以获取同样监控该数据库的哨兵节点信息定期向主数据库发送 info命令,获取主数据库本身的信息。
跟主数据库建立连接后会定时执行以下三个操作:
每隔 10s 向 master 和 slave 发送 info 命令。作用是获取当前数据库信息,比如发现新增从节点时,会建立连接,并加入到监控列表中,当主从数据库的角色发生变化进行信息更新。
每隔 2s 向主数据里和从数据库的
_sentinel_:hello频道发送自己的信息。作用是将自己的监控数据和哨兵分享。每个哨兵会订阅数据库的_sentinel:hello频道,当其他哨兵收到消息后,会判断该哨兵是不是新的哨兵,如果是则将其加入哨兵列表,并建立连接。每隔 1s 向所有主从节点和所有哨兵节点发送 ping 命令,作用是监控节点是否存活。
主观下线和客观下线
哨兵节点发送 ping 命令时,当超过一定时间(down-after-millisecond)后,如果节点未回复,则哨兵认为主观下线。主观下线表示当前哨兵认为该节点已经下面,如果该节点为主数据库,哨兵会进一步判断是够需要对其进行故障切换,这时候就要发送命令(SENTINEL is-master-down-by-addr)询问其他哨兵节点是否认为该主节点是主观下线,当达到指定数量(quorum)时,哨兵就会认为是客观下线。
当主节点客观下线时就需要进行主从切换,主从切换的步骤为:
选出领头哨兵。 领头哨兵所有的 slave 选出优先级最高的从数据库。优先级可以通过 slave-priority 选项设置。 如果优先级相同,则从复制的命令偏移量越大(即复制同步数据越多,数据越新),越优先。 如果以上条件都一样,则选择 run ID 较小的从数据库。
选出一个从数据库后,哨兵发送 slave no one 命令升级为主数据库,并发送slaveof 命令将其他从节点的主数据库设置为新的主数据库。
哨兵模式优缺点
优点
哨兵模式是基于主从模式的,解决可主从模式中master故障不可以自动切换故障的问题。不足-问题
(1)是一种中心化的集群实现方案:始终只有一个 Redis 主机来接收和处理写请求,写操作受单机瓶颈影响。(2)集群里所有节点保存的都是全量数据,浪费内存空间,没有真正实现分布式存储。数据量过大时,主从同步严重影响 master 的性能。(3)Redis 主机宕机后,哨兵模式正在投票选举的情况之外,因为投票选举结束之前,谁也不知道主机和从机是谁,此时 Redis 也会开启保护机制,禁止写操作,直到选举出了新的 Redis 主机。
主从模式或哨兵模式每个节点存储的数据都是全量的数据,数据量过大时,就需要对存储的数据进行分片后存储到多个 Redis 实例上。此时就要用到 Redis Sharding 技术。
各大厂的 Redis 集群方案
Redis 在 3.0 版本前只支持单实例模式,虽然 Redis 的开发者 Antirez 早在博客上就提出在 Redis 3.0 版本中加入集群的功能,但 3.0 版本等到 2015 年才发布正式版。各大企业等不急了,在 3.0 版本还没发布前为了解决 Redis 的存储瓶颈,纷纷推出了各自的 Redis 集群方案。这些方案的核心思想是把数据分片(sharding)存储在多个 Redis 实例中,每一片就是一个 Redis 实例。
客户端分片
客户端分片是把分片的逻辑放在 Redis 客户端实现,(比如:jedis 已支持 Redis Sharding 功能,即 ShardedJedis),通过 Redis 客户端预先定义好的路由规则(使用一致性哈希),把对 Key 的访问转发到不同的 Redis 实例中,查询数据时把返回结果汇集。这种方案的模式如图所示。
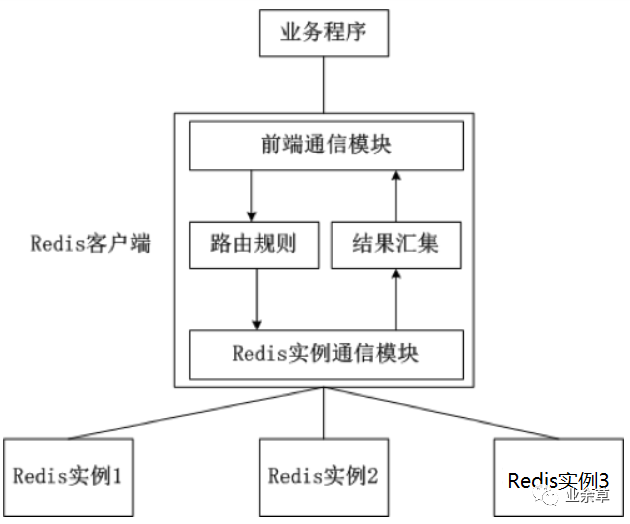
客户端分片的优缺点:
优点:客户端 sharding 技术使用 hash 一致性算法分片的好处是所有的逻辑都是可控的,不依赖于第三方分布式中间件。服务端的 Redis 实例彼此独立,相互无关联,每个 Redis 实例像单服务器一样运行,非常容易线性扩展,系统的灵活性很强。开发人员清楚怎么实现分片、路由的规则,不用担心踩坑。
一致性哈希算法:
是分布式系统中常用的算法。比如,一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的 hash 方法,将数据映射到具体的节点上,如 mod(key,d),key 是数据的 key,d 是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了。
一致性哈希算法解决了普通余数 Hash 算法伸缩性差的问题,可以保证在上线、下线服务器的情况下尽量有多的请求命中原来路由到的服务器。
实现方式:一致性 hash 算法,比如 MURMUR_HASH 散列算法、ketamahash 算法。比如 Jedis 的 Redis Sharding 实现,采用一致性哈希算法(consistent hashing),将 key 和节点 name 同时 hashing,然后进行映射匹配,采用的算法是 MURMUR_HASH。
采用一致性哈希而不是采用简单类似哈希求模映射的主要原因是当增加或减少节点时,不会产生由于重新匹配造成的 rehashing。一致性哈希只影响相邻节点 key 分配,影响量小。
不足
这是一种静态的分片方案,需要增加或者减少 Redis 实例的数量,需要手工调整分片的程序。 运维成本比较高,集群的数据出了任何问题都需要运维人员和开发人员一起合作,减缓了解决问题的速度,增加了跨部门沟通的成本。 在不同的客户端程序中,维护相同的路由分片逻辑成本巨大。比如:java 项目、PHP 项目里共用一套 Redis 集群,路由分片逻辑分别需要写两套一样的逻辑,以后维护也是两套。
客户端分片有一个最大的问题就是,服务端 Redis 实例群拓扑结构有变化时,每个客户端都需要更新调整。如果能把客户端分片模块单独拎出来,形成一个单独的模块(中间件),作为客户端 和 服务端连接的桥梁就能解决这个问题了,此时「代理分片」就出现了。
代理分片
Redis 代理分片用得最多的就是 Twemproxy,由 Twitter 开源的 Redis 代理,其基本原理是:通过中间件的形式,Redis 客户端把请求发送到 Twemproxy,Twemproxy 根据路由规则发送到正确的 Redis 实例,最后 Twemproxy 把结果汇集返回给客户端。
Twemproxy 通过引入一个代理层,将多个 Redis 实例进行统一管理,使 Redis 客户端只需要在 Twemproxy 上进行操作,而不需要关心后面有多少个 Redis 实例,从而实现了 Redis 集群。
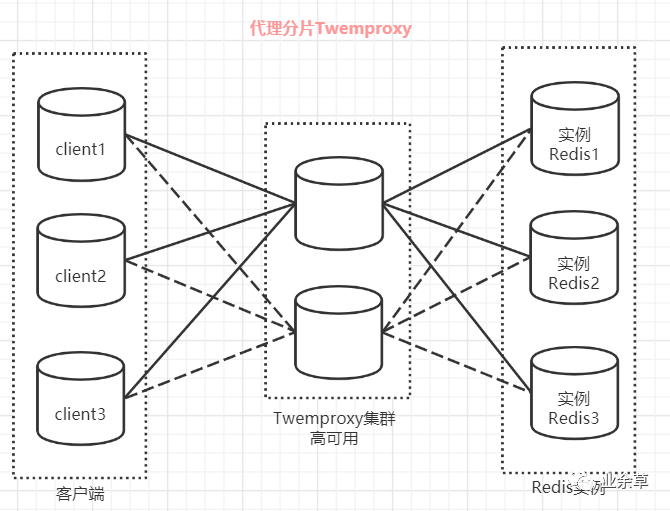
「Twemproxy 的优点:」
客户端像连接 Redis 实例一样连接 Twemproxy,不需要改任何的代码逻辑。 支持无效 Redis 实例的自动删除。 Twemproxy 与 Redis 实例保持连接,减少了客户端与 Redis 实例的连接数。
「Twemproxy 的不足:」
由于 Redis 客户端的每个请求都经过 Twemproxy 代理才能到达 Redis 服务器,这个过程中会产生性能损失。 没有友好的监控管理后台界面,不利于运维监控。 Twemproxy 最大的痛点在于,无法平滑地扩容/缩容。对于运维人员来说,当因为业务需要增加 Redis 实例时工作量非常大。
「Twemproxy 作为最被广泛使用、最久经考验、稳定性最高的 Redis 代理,在业界被广泛使用。」
Codis
Twemproxy 不能平滑增加 Redis 实例的问题带来了很大的不便,于是豌豆荚自主研发了 Codis,一个支持平滑增加 Redis 实例的 Redis 代理软件,其基于 Go 和 C 语言开发,并于 2014 年 11 月在 GitHub 上开源:https://github.com/CodisLabs/codis。
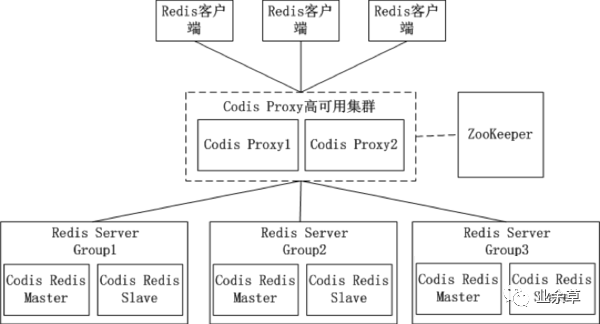
在 Codis 的架构图中,Codis 引入了 Redis Server Group,其通过指定一个主 CodisRedis 和一个或多个从 CodisRedis,实现了 Redis 集群的高可用。当一个主 CodisRedis 挂掉时,Codis 不会自动把一个从 CodisRedis 提升为主 CodisRedis,这涉及数据的一致性问题(Redis 本身的数据同步是采用主从异步复制,当数据在主 CodisRedis 写入成功时,从 CodisRedis 是否已读入这个数据是没法保证的),需要管理员在管理界面上手动把从 CodisRedis 提升为主 CodisRedis。
如果手动处理觉得麻烦,豌豆荚也提供了一个工具 Codis-ha,这个工具会在检测到主 CodisRedis 挂掉的时候将其下线并提升一个从 CodisRedis 为主 CodisRedis。
Codis 中采用预分片的形式,启动的时候就创建了 1024 个 slot,1 个 slot 相当于 1 个箱子,每个箱子有固定的编号,范围是 1~1024。slot 这个箱子用作存放 Key,至于 Key 存放到哪个箱子,可以通过算法crc32(key)%1024获得一个数字,这个数字的范围一定是 1~1024 之间,Key 就放到这个数字对应的 slot。例如,如果某个 Key 通过算法crc32(key)%1024得到的数字是 5,就放到编码为 5 的 slot(箱子)。1 个 slot 只能放 1 个 Redis Server Group,不能把 1 个 slot 放到多个 Redis Server Group 中。1 个 Redis Server Group 最少可以存放 1 个 slot,最大可以存放 1024 个 slot。因此,Codis 中最多可以指定 1024 个 Redis Server Group。
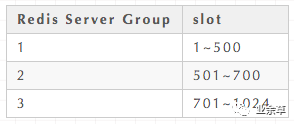
Codis 最大的优势在于支持平滑增加(减少)Redis Server Group(Redis 实例),能安全、透明地迁移数据,这也是 Codis 有别于 Twemproxy 等静态分布式 Redis 解决方案的地方。Codis 增加了 Redis Server Group 后,就牵涉到 slot 的迁移问题。例如,系统有两个 Redis Server Group,Redis Server Group 和 slot 的对应关系如下。

当增加了一个 Redis Server Group,slot 就要重新分配了。Codis 分配 slot 有两种方法:
第一种:通过 Codis 管理工具 Codisconfig 手动重新分配,指定每个 Redis Server Group 所对应的 slot 的范围,例如:可以指定 Redis Server Group 和 slot 的新的对应关系如下。
第二种:通过 Codis 管理工具 Codisconfig 的 rebalance 功能,会自动根据每个 Redis Server Group 的内存对 slot 进行迁移,以实现数据的均衡。
Redis Cluster
Redis 的哨兵模式虽然已经可以实现高可用,读写分离 ,但是存在几个方面的不足:
哨兵模式下每台 Redis 服务器都存储相同的数据,很浪费内存空间;数据量太大,主从同步时严重影响了 master 性能。 哨兵模式是中心化的集群实现方案,每个从机和主机的耦合度很高,master 宕机到 slave 选举 master 恢复期间服务不可用。 哨兵模式始终只有一个 Redis 主机来接收和处理写请求,写操作还是受单机瓶颈影响,没有实现真正的分布式架构。
Redis 在 3.0 上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的数据。cluster 模式为了解决单机 Redis 容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS 不受限于单机,可受益于分布式集群高扩展性。Redis Cluster 是一种服务器 Sharding 技术(分片和路由都是在服务端实现),「采用多主多从,每一个分区都是由一个 Redis 主机和多个从机组成,片区和片区之间是相互平行的」。Redis Cluster 集群采用了 P2P 的模式,完全去中心化。
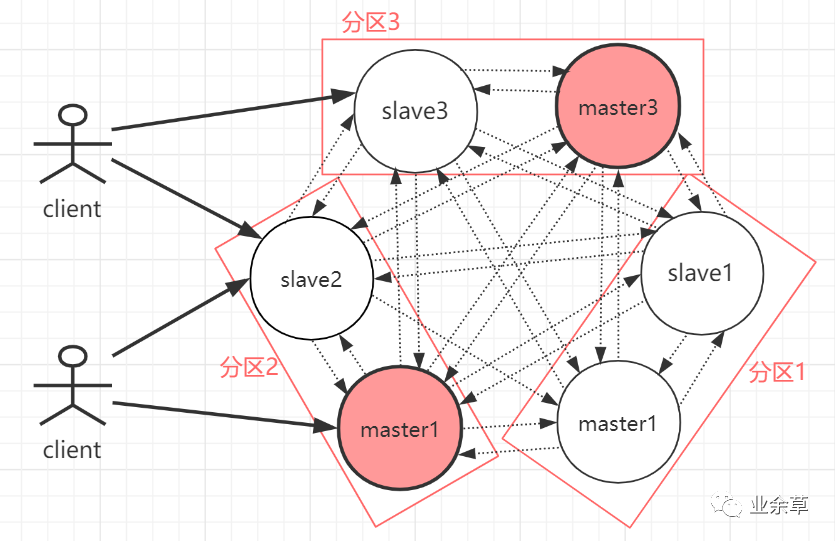
如上图,官方推荐,集群部署至少要 3 台以上的 master 节点,最好使用 3 主 3 从六个节点的模式。Redis Cluster 集群具有如下几个特点:
集群完全去中心化,采用多主多从;所有的 redis 节点彼此互联(PING-PONG 机制),内部使用二进制协议优化传输速度和带宽。 客户端与 Redis 节点直连,不需要中间代理层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。 每一个分区都是由一个 Redis 主机和多个从机组成,分片和分片之间是相互平行的。 每一个 master 节点负责维护一部分槽,以及槽所映射的键值数据;集群中每个节点都有全量的槽信息,通过槽每个 node 都知道具体数据存储到哪个 node 上。
「Redis cluster 主要是针对海量数据 + 高并发 + 高可用的场景,海量数据,如果你的数据量很大,那么建议就用 Redis cluster,数据量不是很大时,使用 sentinel 就够了。Redis cluster 的性能和高可用性均优于哨兵模式。」
Redis Cluster 采用虚拟哈希槽分区而非一致性 hash 算法,预先分配一些卡槽,所有的键根据哈希函数映射到这些槽内,每一个分区内的 master 节点负责维护一部分槽以及槽所映射的键值数据。