
【实战】基于 babel 和 postcss 查找项目中的无用模块
背景
昊昊是业务线前端工程师(专业页面仔),我是架构组工具链工程师(专业工具人),有一天昊昊和说我他维护的项目中没用到的模块太多了,其实可以删掉的,但是现在不知道哪些没用,就不敢删,问我是不是可以做一个工具来找出所有没有被引用的模块。毕竟是专业的工具人,这种需求难不倒我,于是花了半天多实现了这个工具。
这个工具是一个通用的工具,node 项目、前端项目都可以用它来查找没有用到的模块,而且其中模块遍历器的思路可以应用到很多别的地方。所以我整理了实现思路,写了这篇文章。
思路分析
目标是找到项目中所有没用到的模块。项目中总有几个入口模块,代码会从这些模块开始打包或者运行。我们首先要知道所有的入口模块。
有了入口模块之后,分析入口模块的用到(依赖)了哪些模块,然后再从用到的模块分析依赖,这样递归的进行分析,直到没有新的依赖。这个过程中,所有遍历到的模块就是用到的,而没有被遍历到的就是没有用到的,就是我们要找的可以删除的模块。
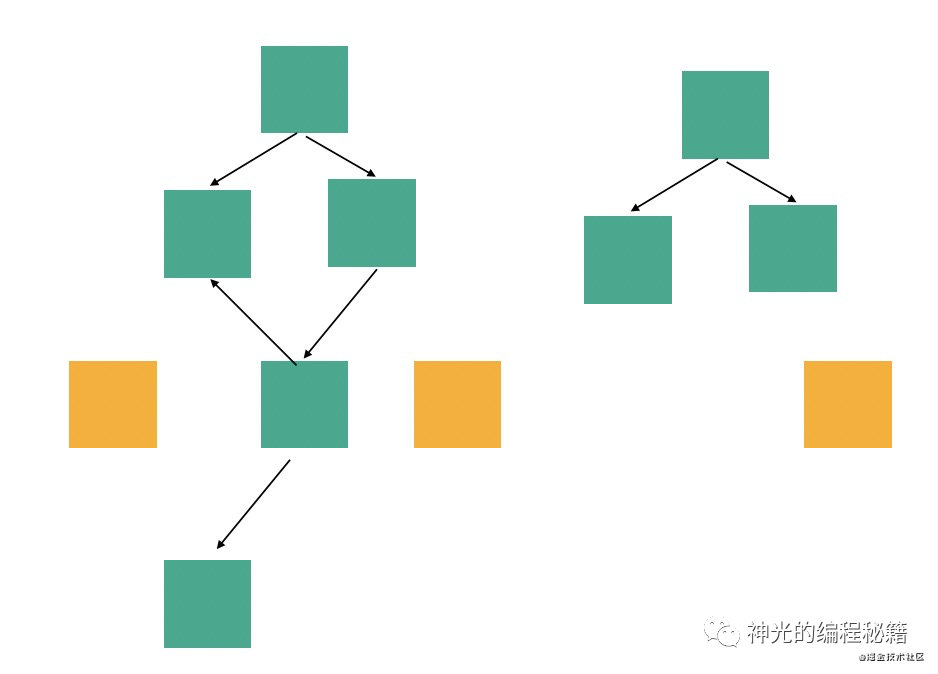
我们可以在遍历的过程中把模块信息和模块之间的关系以对象和对象的关系保存,构造成一个依赖图(因为可能有一个模块被两个模块依赖,甚至循环依赖,所以是图)。之后对这个依赖图的数据结构的分析就是对模块之间依赖关系的分析。我们这个需求只需要保存遍历到的模块路径就可以,可以不生成依赖图。
遍历到不同的模块要找到它依赖的哪些模块,对于不同的模块有不同的分析依赖的方式:
js、ts、jsx、tsx 模块根据 es module 的 import 或者 commonjs 的 require 来确定依赖 css、less、scss 模块根据 @import 和 url() 的语法来确定依赖
而且拿到了依赖的路径也可能还要做一层处理,因为比如 webpack 可以配置 alias,typescript 可以配置 paths,还有 monorepo 的路径也有自己的特点,这些路径解析规则是我们要处理的,处理之后才能找到模块真实路径是啥。
经过从入口模块开始的依赖分析,对模块图完成遍历,把用到的模块路径保存下来,然后用所有模块路径过滤掉用到的,剩下的就是没有使用的模块。
思路大概这样,我们来实现一下:
代码实现
模块遍历
我们要写一个模块遍历器,传入当前模块的路径和处理模块内容的回调函数,处理过程如下:
尝试补全路径,因为 .js、.json、.tsx 等可以省略后缀名 根据路径获得模块的类型 如果是 js 模块,用遍历 js 的方式进行处理 如果是 css 模块,用遍历 css 的方式进行处理
const MODULE_TYPES = {
JS: 1 << 0,
CSS: 1 << 1,
JSON: 1 << 2
};
function getModuleType(modulePath) {
const moduleExt = extname(modulePath);
if (JS_EXTS.some(ext => ext === moduleExt)) {
return MODULE_TYPES.JS;
} else if (CSS_EXTS.some(ext => ext === moduleExt)) {
return MODULE_TYPES.CSS;
} else if (JSON_EXTS.some(ext => ext === moduleExt)) {
return MODULE_TYPES.JSON;
}
}
function traverseModule (curModulePath, callback) {
curModulePath = completeModulePath(curModulePath);
const moduleType = getModuleType(curModulePath);
if (moduleType & MODULE_TYPES.JS) {
traverseJsModule(curModulePath, callback);
} else if (moduleType & MODULE_TYPES.CSS) {
traverseCssModule(curModulePath, callback);
}
}
js 模块遍历
遍历 js 模块需要分析其中的 import 和 require 依赖。我们使用 babel 来做:
读取文件内容 根据后缀名是 .jsx、.tsx 等来决定是否启用 typescript、jsx 的 parse 插件 使用 babel parser 把代码转成 AST 使用 babel traverse 对 AST 进行遍历 处理 ImportDeclaration 和 CallExpression 的 AST,从中提取依赖路径 对依赖路径进行处理,变成真实路径之后,继续遍历该路径的模块
代码如下:
function traverseJsModule(curModulePath, callback) {
const moduleFileContent = fs.readFileSync(curModulePath, {
encoding: 'utf-8'
});
const ast = parser.parse(moduleFileContent, {
sourceType: 'unambiguous',
plugins: resolveBabelSyntaxtPlugins(curModulePath)
});
traverse(ast, {
ImportDeclaration(path) {
const subModulePath = moduleResolver(curModulePath, path.get('source.value').node);
if (!subModulePath) {
return;
}
callback && callback(subModulePath);
traverseModule(subModulePath, callback);
},
CallExpression(path) {
if (path.get('callee').toString() === 'require') {
const subModulePath = moduleResolver(curModulePath, path.get('arguments.0').toString().replace(/['"]/g, ''));
if (!subModulePath) {
return;
}
callback && callback(subModulePath);
traverseModule(subModulePath, callback);
}
}
})
}
css 模块遍历
遍历 css 模块需要分析 @import 和 url()。我们使用 postcss 来做:
读取文件内容 根据文件路径是 .less、.scss 来决定是否启用 less、scss 的语法插件 使用 postcss.parse 把文件内容转成 AST 遍历 @import 节点,提取依赖路径 遍历样式声明(declaration),过滤出 url() 的值,提取依赖路径 对依赖路径进行处理,变成真实路径之后,继续遍历该路径的模块
代码如下:
function traverseCssModule(curModulePath, callback) {
const moduleFileConent = fs.readFileSync(curModulePath, {
encoding: 'utf-8'
});
const ast = postcss.parse(moduleFileConent, {
syntaxt: resolvePostcssSyntaxtPlugin(curModulePath)
});
ast.walkAtRules('import', rule => {
const subModulePath = moduleResolver(curModulePath, rule.params.replace(/['"]/g, ''));
if (!subModulePath) {
return;
}
callback && callback(subModulePath);
traverseModule(subModulePath, callback);
});
ast.walkDecls(decl => {
if (decl.value.includes('url(')) {
const url = /.*url\((.+)\).*/.exec(decl.value)[1].replace(/['"]/g, '');
const subModulePath = moduleResolver(curModulePath, url);
if (!subModulePath) {
return;
}
callback && callback(subModulePath);
}
} )
}
模块路径处理
不管是 css 还是 js 模块都要在提取了路径之后进行处理:
支持自定义路径解析逻辑,让用户可以根据需要定制路径解析的规则 过滤掉 node_modules 下的模块,不需要分析 补全路径的后缀名 如果遍历过的模块则跳过遍历,避免循环依赖
代码如下:
const visitedModules = new Set();
function moduleResolver (curModulePath, requirePath) {
if (typeof requirePathResolver === 'function') {// requirePathResolver 是用户自定义的路径解析逻辑
const res = requirePathResolver(dirname(curModulePath), requirePath);
if (typeof res === 'string') {
requirePath = res;
}
}
requirePath = resolve(dirname(curModulePath), requirePath);
// 过滤掉第三方模块
if (requirePath.includes('node_modules')) {
return '';
}
requirePath = completeModulePath(requirePath);
if (visitedModules.has(requirePath)) {
return '';
} else {
visitedModules.add(requirePath);
}
return requirePath;
}
这样我们就完成了分析出的依赖路径到它真实的路径的转换。
路径补全
写代码的时候是可以省略掉一些文件的后缀(.js、.tsx、.json 等)的,我们要实现补全的逻辑:
如果已经有后缀名了,则跳过 如果是目录,则尝试查找 index.xxx 的文件,找到了则返回该路径 如果是文件,则尝试补全 .xxx 的后缀,找到了则返回该路径 没有找到则报错:module not found
const JS_EXTS = ['.js', '.jsx', '.ts', '.tsx'];
const JSON_EXTS = ['.json'];
function completeModulePath (modulePath) {
const EXTS = [...JSON_EXTS, ...JS_EXTS];
if (modulePath.match(/\.[a-zA-Z]+$/)) {
return modulePath;
}
function tryCompletePath (resolvePath) {
for (let i = 0; i < EXTS.length; i ++) {
let tryPath = resolvePath(EXTS[i]);
if (fs.existsSync(tryPath)) {
return tryPath;
}
}
}
function reportModuleNotFoundError (modulePath) {
throw chalk.red('module not found: ' + modulePath);
}
if (isDirectory(modulePath)) {
const tryModulePath = tryCompletePath((ext) => join(modulePath, 'index' + ext));
if (!tryModulePath) {
reportModuleNotFoundError(modulePath);
} else {
return tryModulePath;
}
} else if (!EXTS.some(ext => modulePath.endsWith(ext))) {
const tryModulePath = tryCompletePath((ext) => modulePath + ext);
if (!tryModulePath) {
reportModuleNotFoundError(modulePath);
} else {
return tryModulePath;
}
}
return modulePath;
}
按照上面的思路,我们实现了模块的遍历,找到了所有的用到的模块。
过滤出无用模块
上面我们找到了所有用到的模块,接下来只要用所有的模块过滤掉用到的模块,就是没有用到的模块。
我们封装一个 findUnusedModule 的方法。
传入参数:
entries(入口模块数组) includes(所有模块的 glob 表达式) resolveRequirePath(自定义路径解析逻辑) cwd(解析模块的根路径)
返回一个对象,包含:
all (所有模块) used(用到的模块) unused(没用到的模块)
处理过程:
合并参数和默认参数 基于 cwd 处理 includes 的模块路径 根据 includes 的 glob 表达式找出所有的模块 以所有 entires 为入口进行遍历,记录用到的模块 过滤掉用到的模块,求出没有用到的模块
const defaultOptions = {
cwd: '',
entries: [],
includes: ['**/*', '!node_modules'],
resolveRequirePath: () => {}
}
function findUnusedModule (options) {
let {
cwd,
entries,
includes,
resolveRequirePath
} = Object.assign(defaultOptions, options);
includes = includes.map(includePath => (cwd ? `${cwd}/${includePath}` : includePath));
const allFiles = fastGlob.sync(includes).map(item => normalize(item));
const entryModules = [];
const usedModules = [];
setRequirePathResolver(resolveRequirePath);
entries.forEach(entry => {
const entryPath = resolve(cwd, entry);
entryModules.push(entryPath);
traverseModule(entryPath, (modulePath) => {
usedModules.push(modulePath);
});
});
const unusedModules = allFiles.filter(filePath => {
const resolvedFilePath = resolve(filePath);
return !entryModules.includes(resolvedFilePath) && !usedModules.includes(resolvedFilePath);
});
return {
all: allFiles,
used: usedModules,
unused: unusedModules
}
}
这样,我们封装的 findUnusedModule 能够完成最初的需求:查找项目下没有用到的模块。
测试功能
我们来测试一下效果,用这个目录作为测试项目:
const { all, used, unused } = findUnusedModule({
cwd: process.cwd(),
entries: ['./demo-project/fre.js', './demo-project/suzhe2.js'],
includes: ['./demo-project/**/*'],
resolveRequirePath (curDir, requirePath) {
if (requirePath === 'b') {
return path.resolve(curDir, './lib/ssh.js');
}
return requirePath;
}
});
结果如下:

成功的找出了没有用到的模块!(可以把代码拉下来跑一下试试)
思考
我们实现了一个模块遍历器,它可以对从某一个模块开始遍历。基于这个遍历器我们实现了查找无用模块的需求,其实也可以用它来做别的分析需求,这个遍历的方式是通用的。
我们知道 babel 可以用来做两件事情:
代码的转译:从 es next、typescript 等代码转译成目标环境支持的 js 静态分析:对代码内容做分析,比如类型检查、lint 等,不生成代码
这个模块遍历器也可以做同样的事情:
静态分析:分析模块间的依赖关系,构造依赖图,完成一些分析功能 打包:把依赖图中每一个模块用相应的代码模版打印成目标代码
总结
我们先分析了需求:找出项目中没用到的模块。这需要实现一个模块遍历器。
模块遍历要对 js 模块和 css 模块做不同的处理:js 模块分析 import 和 require,css 分析 url() 和 @import。
之后要对分析出的路径做处理,变成真实路径。要处理 node_modules、webpack alias、typescript 的 types 等情况,我们暴露了一个回调函数给开发者自己去扩展。
实现了模块遍历之后,只要指定所有的模块、入口模块,那么我们就可以找出用到了哪些模块,没用到哪些模块。
经过测试,符合我们的需求。
这个模块遍历器是通用的,可以用来做各种静态分析,也可以做后续的代码打印做成一个打包器。
代码的 github 地址在这,感兴趣可以拉下来跑跑,学会写模块遍历器还是挺有帮助的。
彩蛋
当时给昊昊介绍这个功能的时候,写了一份实现思路的文档,也贴在这里吧:
昊昊: 光哥,整体的思路是什么样的啊,一上来就看代码比较乱
我:模块是一个图的结构,指定从某个入口开始遍历,其实这是一个 dfs 的过程,但是有循环引用,要通过记录处理过的模块来解决。递归遍历这个图,处理到的模块就是用到的。
昊昊:dfs 一个模块,怎么确定子模块呢?
我:不同的模块有不同的处理方式,比如 js 模块,就要通过 import 或者 require 来确定子模块,而 css 则要通过 @import 和 url() 来确定。但是这些只是提取路径,这个路径还是不可用的,还需要转换成真实路径,要有一个 resolve path 的过程。
昊昊:resolve path 都做啥啊?
我:就是处理 alias、过滤 node_modules 下的模块,因为我们这里用不到,然后根据当前模块的路径确定子模块的绝对路径。还要暴露出一个钩子函数去让用户能够自定义 require path 的 resolve 逻辑。
昊昊:就是那个 requireRequirePath 么?
我:对的,那个就是暴露出去让用户自定义 path resolve 逻辑的钩子。
昊昊:我大体明白流程了?
我:说说看
昊昊:项目的模块构成依赖图,我们要确定没有用到的模块,那就要先找出用到的模块,之后把它们过滤掉。用到的模块要用几个入口模块开始做 dfs,遍历不同的模块有不同的提取 require path 的方式,提取出来以后还要对 path 进行 resolve,得到真实路径,然后递归进行子模块的处理。这样遍历完一遍就能确定用到了哪些。同时还要处理循环引用问题,因为毕竟模块是一个图,进行 dfs 会有环在。
我:对的,棒棒的。