富文本关键字搜索高亮,解决方法及优化(收藏!)
作者:猿猴望月 原文:https://juejin.cn/post/7070688497929043998
去年在冬季面试的时候,被某厂面试官问了这个问题:
如果我们的数据是富文本,现在要加一个搜索功能,怎么样才能完美的实现高亮呢?
当时回答的很粗糙,只答了提取出文字进行搜索,怎么回填原本的样式并没有说清楚。
今天坐在我旁边的小哥开始做MarkDown搜索匹配了,又唤起了我尘封已久的记忆,于是今天就让我们来一起震慑一下面试官吧!
首先能想到的思路是和leetcode的上车问题相关。
有一群乘客,当中一个人在1号站台下车,两个人在2号上车上车,最后求N号站台有多少乘客。
这个问题也可以那么去考虑:在富文本串之中,在遇到开标签就理解为当前的文字“上车”,而遇到闭标签就理解为当前的文字”下车“。
(开标签:<span>、闭标签:</span>)
第一版
首先我们开发一个页面,其中仅包含搜索框和几段富文本的数据

举个🌰,数据第一项为:
今天真是个<span style="text-decoration:underline">好天气</span>
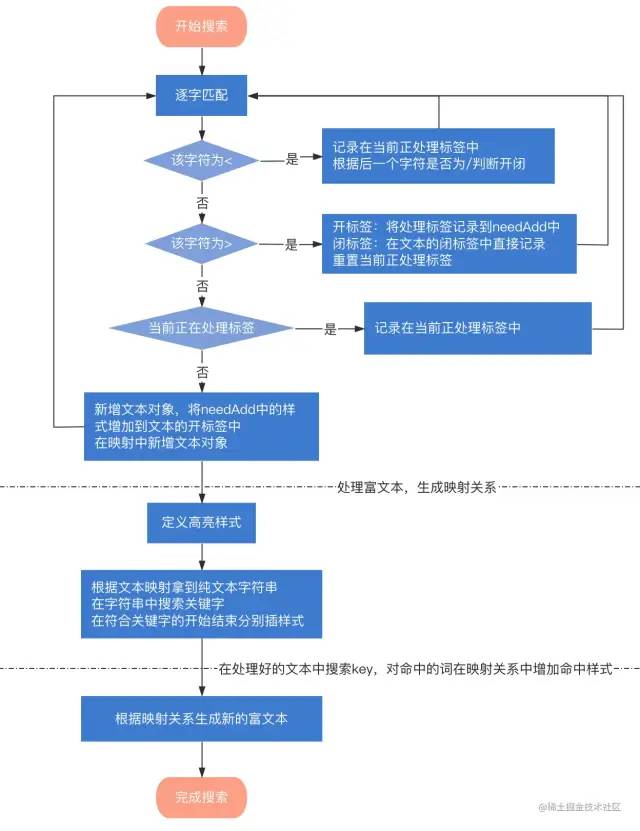
这个时候我们想搜索“好天气”,整体的思路是分为3个部分:
处理富文本,生成标签在字符串位置的映射关系 在处理好的文本中搜索key,对命中的词在映射关系中增加命中样式 根据映射关系生成新的富文本
在其中,我们需要记录一些关键状态值:
currentTag:当前正处理标签 isOpen:当前标签是否是开标签 needAdd: 文本需要增加的开标签 nowText:目前正在处理的文本 textToTagMap:文本与标签的映射,这里提供一下类型
type TextToStyleMap = Array<
{
key: string,
// 从这个字符增加的标签index
up: number[],
// 从这个字符结束的标签index
down: number[]
}
>
让我们简单的画个流程图看一下怎么去做~
codesandbox.io/s/new-smoke…[1]
首版完成!(ps:现在我们搜索用的是正则,在大文本的情况下可能会有性能问题

优化1
看起来好像很完美了?如果我们在这个文本框中搜索“个好”呢?

咦,下划线丢了?
因为我们搜索个好后的富文本结果是
今天真是<em>个<span style="text-decoration:underline">好</em>天气</span>
这里生产出了一个错误的标签不对应的富文本
我们怎么应对这个问题呢?
最简单的方式应该是把强调的样式加在每一个文字上
今天真是<em>个<span style="text-decoration:underline">好</em>天气</span>
⬇️
今天真是<em>个</em><span style="text-decoration:underline"><em>好</em>天气</span>
codesandbox.io/s/upbeat-fe…[2]
简单的改了一下代码之后,我们就修改了这个bug

优化2
这么做了以后,我们会添加许多多余的强调样式标签。比如还是在上面这个例子里,我们如果要搜索『天气』的话,结果会是这样:
今天真是个<span style="text-decoration:underline">好<em>天</em><em>气</em></span>
实际上,天气两个字本身就可以用同一个em标签来包裹,这样可以减少页面中的dom节点树,从而提升性能。
那么,具体该怎么做呢?这里整体的思路就是原本是在同一个文本段里的文本,我们只用一个em标签包裹,只在出现标签的地方添加额外的命中样式标签。
这里需要注意的是,添加命中样式标签的时候,需要添加在最内层,也就是命中样式的开标签要放在所有其他开标签之后,而闭标签则要放在所有其他闭标签之前,这样可以保证命中样式的优先级是最高的,不会被其他标签的样式覆盖。
核心代码逻辑如下:
const match = [...strs.matchAll(reg)].forEach(({ index }) => {
for (let i = 0; i < word.length; i++) {
const letterIndex = i + index;
if (
i === 0 || // 匹配区域区间开始需要有命中样式的开标签
textToTagMap[letterIndex].up.length > 0 || // 当有新的开标签时,需要在内部有命中样式的开标签
textToTagMap[letterIndex - 1].down.length > 0 // 当上一个标签有闭标签时,下一个标签需要有命中样式的开标签
) {
textToTagMap[letterIndex].up.push(emStyleStart);
}
if (
i === word.length - 1 || // 匹配区域结束需要有命中样式的闭标签
textToTagMap[letterIndex].down.length > 0 || // 当有新的闭标签时,需要在内部有命中样式的闭标签
textToTagMap[letterIndex + 1].up.length > 0 // 当下一个标签有开标签时,上一个标签需要有命中样式的闭标签
) {
textToTagMap[letterIndex].down.unshift(emStyleEnd);
}
}
});
最后的成果✌️
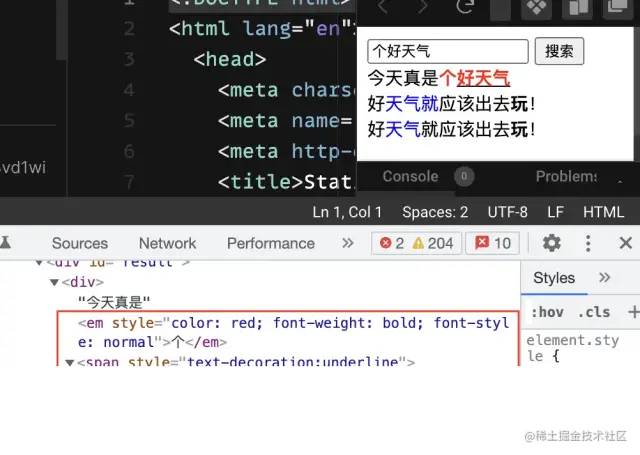
大功告成!
codesandbox.io/s/restless-…[3]
结论
看似完成了?其实还有一些功能没有做,比如局部匹配、多词搜索、emoji匹配等功能,这些就留给大家自己去实现啦
并且,这里的搜索匹配没有考虑转义字符和不合法标签等问题,实际实现起来也需要多加判断
刚刚也提到在大文本的情况下使用正则性能会有问题,那是不是可以考虑把textToTagMap换一种数据格式呢?像是字典树之类
ps:做超大文本量的匹配时也可以选择分片去做,先处理可视区的文字,保证搜索不卡顿
pss:做富文本相关的内容一定要注意防范XSS攻击哦!
参考资料
https://codesandbox.io/s/new-smoke-w5hcjv?file=/index.html: https://link.juejin.cn?target=https%3A%2F%2Fcodesandbox.io%2Fs%2Fnew-smoke-w5hcjv%3Ffile%3D%2Findex.html
[2]https://codesandbox.io/s/upbeat-feynman-qch060?file=/index.html: https://link.juejin.cn?target=https%3A%2F%2Fcodesandbox.io%2Fs%2Fupbeat-feynman-qch060%3Ffile%3D%2Findex.html
[3]https://codesandbox.io/s/restless-pond-9b14j7?file=/index.html: https://link.juejin.cn?target=https%3A%2F%2Fcodesandbox.io%2Fs%2Frestless-pond-9b14j7%3Ffile%3D%2Findex.html
最后
如果你觉得这篇内容对你挺有启发,我想邀请你帮我个小忙:
点个「喜欢」或「在看」,让更多的人也能看到这篇内容
我组建了个氛围非常好的前端群,里面有很多前端小伙伴,欢迎加我微信「sherlocked_93」拉你加群,一起交流和学习
关注公众号「前端下午茶」,持续为你推送精选好文,也可以加我为好友,随时聊骚。