
终于有人把用户画像的流程、方法讲明白了
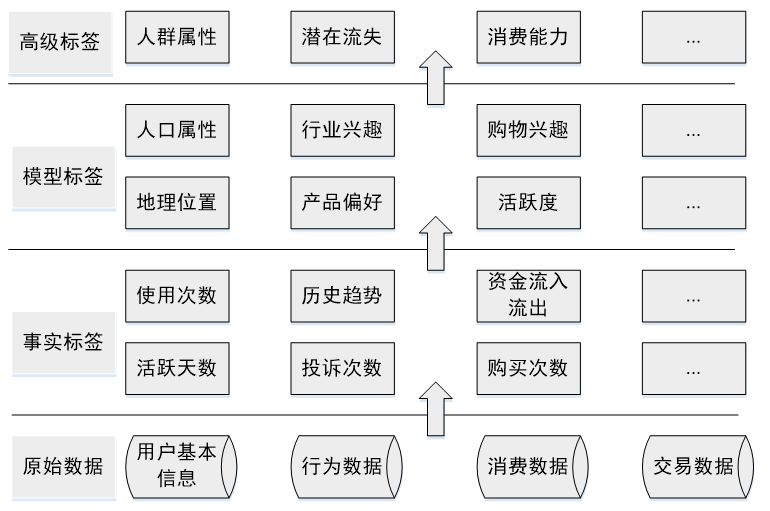
导读:用户标签是个性化推荐、计算广告、金融征信等众多大数据业务应用的基础,它是原始的用户行为数据和大数据应用之间的桥梁,本文会介绍用户标签的构建方法,也就是用户画像技术。



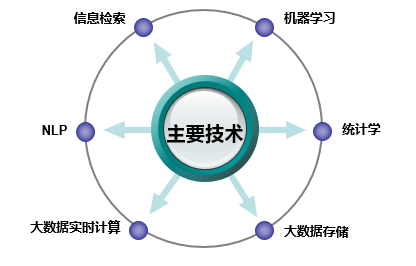
一个是画像的目标,也就是画像的效果评估标准; 另一个是可用于画像的数据。

人口标签:性别、年龄、地域、教育水平、出生日期、职业、星座 兴趣特征:兴趣爱好、使用App/网站、浏览/收藏内容、互动内容、品牌偏好、产品偏好 社会特征:婚姻状况、家庭情况、社交/信息渠道偏好 消费特征:收入状况、购买力水平、已购商品、购买渠道偏好、最后购买时间、购买频次
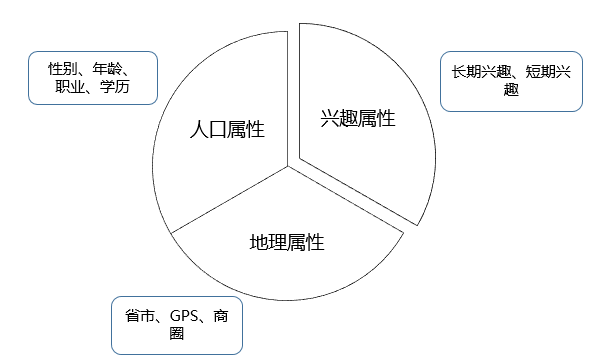
第一类是人口属性,这一类标签比较稳定,一旦建立很长一段时间基本不用更新,标签体系也比较固定; 第二类是兴趣属性,这类标签随时间变化很快,标签有很强的时效性,标签体系也不固定; 第三类是地理属性,这一类标签的时效性跨度很大,如GPS轨迹标签需要做到实时更新,而常住地标签一般可以几个月不用更新,所用的挖掘方法和前面两类也大有不同,如图10-6所示。



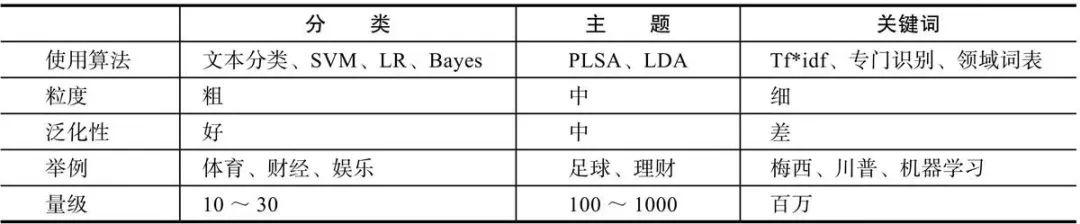
例如用户在购物网上点击查看了一双“Nike AIR MAX跑步鞋”,如果用单个商品作为粒度,画像的粒度就过细,结果是只知道用户对“Nike AIR MAX跑步鞋”有兴趣,在进行商品推荐时,也只能给用户推荐这双鞋; 而如果用大品类作为粒度,如“运动户外”,将无法发现用户的核心需求是买鞋,从而会给用户推荐所有的运动用品,如乒乓球拍、篮球等,这样的推荐缺乏准确性,用户的点击率就会很低。





评论