
从B+树到LSM树,及LSM树在HBase中的应用

Hi,我是王知无,一个大数据领域的原创作者。
放心关注我,获取更多行业的一手消息。
前言
在有代表性的关系型数据库如MySQL、SQL Server、Oracle中,数据存储与索引的基本结构就是我们耳熟能详的B树和B+树。而在一些主流的NoSQL数据库如HBase、Cassandra、LevelDB、RocksDB中,则是使用日志结构合并树(Log-structured Merge Tree,LSM Tree)来组织数据。本文先由B+树来引出对LSM树的介绍,然后说明HBase中是如何运用LSM树的。
回顾B+树
为什么在RDBMS中我们需要B+树(或者广义地说,索引)?一句话:减少寻道时间。在存储系统中广泛使用的HDD是磁性介质+机械旋转的,这就使得其顺序访问较快而随机访问较慢。使用B+树组织数据可以较好地利用HDD的这种特点,其本质是多路平衡查找树。下图是一棵高度为3的4路B+树示例。
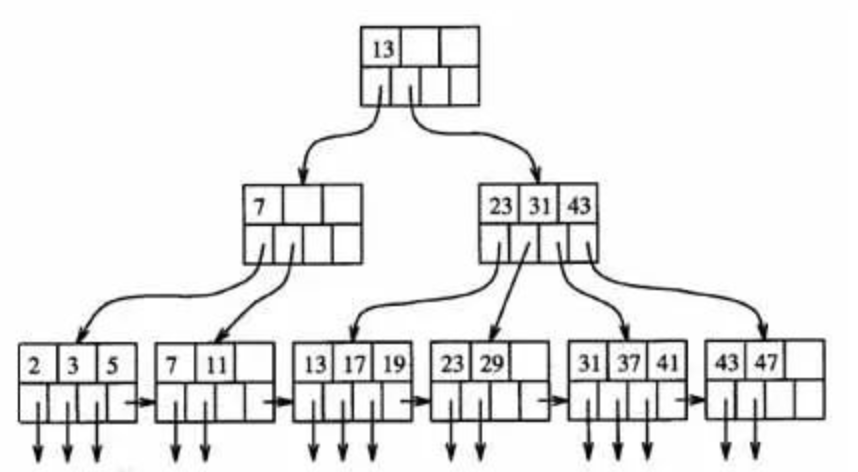
与普通B树相比,B+树的非叶子节点只有索引,所有数据都位于叶子节点,并且叶子节点上的数据会形成有序链表。B+树的主要优点如下:
结构比较扁平,高度低(一般不超过4层),随机寻道次数少; 数据存储密度大,且都位于叶子节点,查询稳定,遍历方便; 叶子节点形成有序链表,范围查询转化为顺序读,效率高。相对而言B树必须通过中序遍历才能支持范围查询。
当然,B+树也不是十全十美的,它的主要缺点有两个:
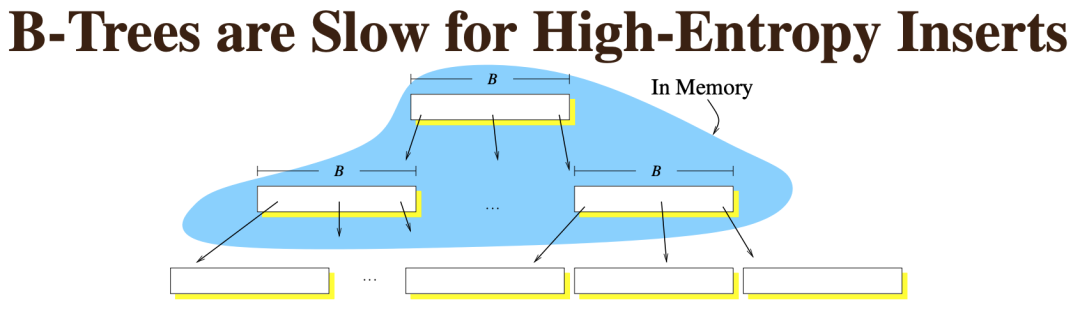
如果写入的数据比较离散,那么寻找写入位置时,子节点有很大可能性不会在内存中,最终会产生大量的随机写,性能下降。下图来自TokuDB的PPT,说明了这一点。
如果B+树已经运行了很长时间,写入了很多数据,随着叶子节点分裂,其对应的块会不再顺序存储,而变得分散。这时执行范围查询也会变成随机读,效率降低了。
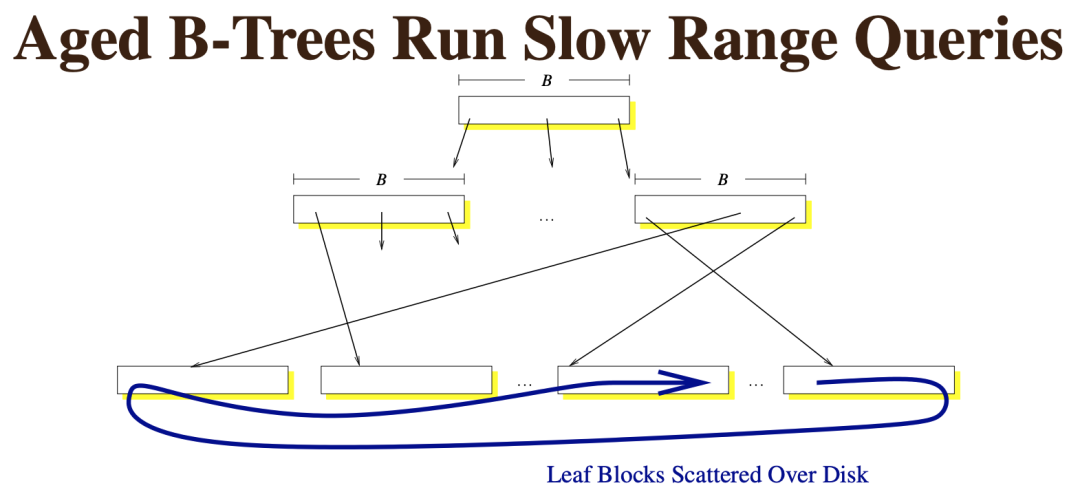
可见,B+树在多读少写(相对而言)的情境下比较有优势,在多写少读的情境下就不是很有威力了。当然,我们可以用SSD来获得成倍提升的读写速率,但成本同样高昂,对海量存储集群而言不太可行。日志结构合并树(LSM Tree)就是作为B+树的替代方案产生的。
认识LSM树
LSM树实际上不是一棵树,而是2个或者多个树或类似树的结构(注意这点)的集合。下图示出最简单的有2个结构的LSM树。
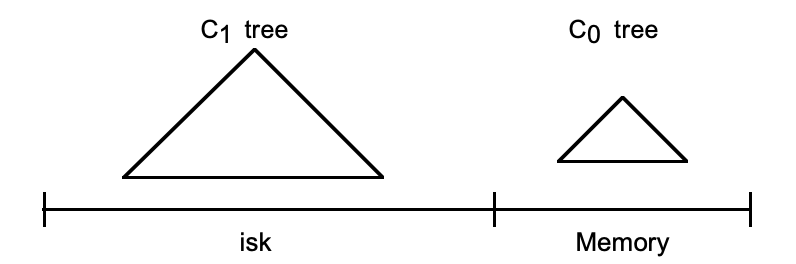
(上图中,少了一个字母D)
在LSM树中,最低一级也是最小的C0树位于内存里,而更高级的C1、C2...树都位于磁盘里。数据会先写入内存中的C0树,当它的大小达到一定阈值之后,C0树中的全部或部分数据就会刷入磁盘中的C1树,如下图所示。
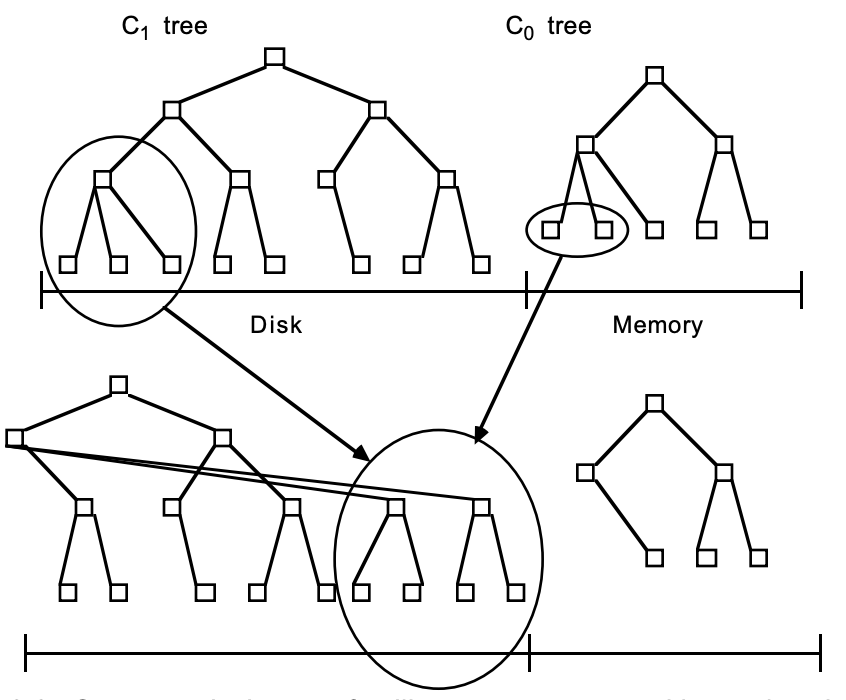
由于内存的读写速率都比外存要快非常多,因此数据写入C0树的效率很高。并且数据从内存刷入磁盘时是预排序的,也就是说,LSM树将原本的随机写操作转化成了顺序写操作,写性能大幅提升。不过,它的tradeoff就是牺牲了一部分读性能,因为读取时需要将内存中的数据和磁盘中的数据合并。总体上来讲这种tradeoff还是值得的,因为:
可以先读取内存中C0树的缓存数据。内存的效率很高,并且根据局部性原理,最近写入的数据命中率也高。 写入数据未刷到磁盘时不会占用磁盘的I/O,不会与读取竞争。读取操作就能取得更长的磁盘时间,变相地弥补了读性能差距。
在实际应用中,为了防止内存因断电等原因丢失数据,写入内存的数据同时会顺序在磁盘上写日志,类似于我们常见的预写日志(WAL),这就是LSM这个词中Log一词的来历。另外,如果有多级树的话,低级的树在达到大小阈值后也会在磁盘中进行合并,如下图所示。
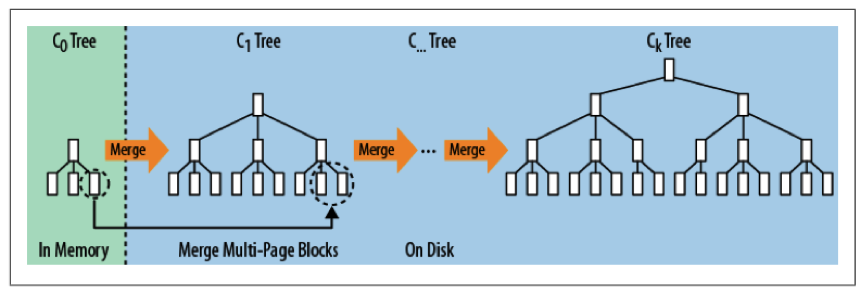
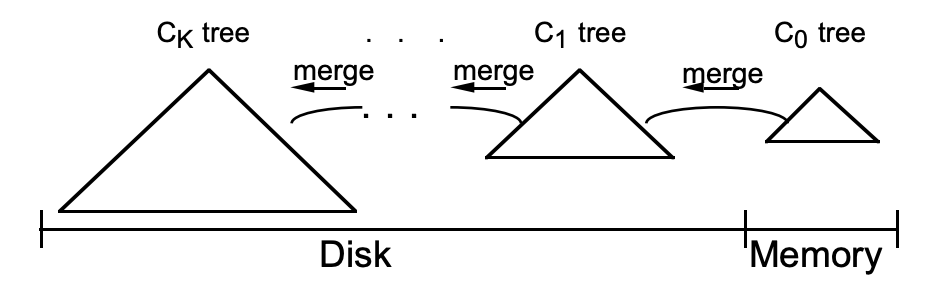
下面以HBase为例来简要讲解LSM树是如何发挥其作用的。
HBase中的LSM树
在之前的学习中,我们已经了解HBase的读写流程与MemStore的作用。MemStore作为列族级别的写入和读取缓存,它就是HBase中LSM树的C0层。并且它确实也没有采用树形结构来存储,而是采用了跳表——一种替代自平衡BST的结构。MemStore Flush的过程,也就是LSM树中C0层刷写到C1层的过程,而LSM中的日志对应到HBase自然就是HLog了。
为了方便理解,再次祭出之前用过的HBase读写流程简图。
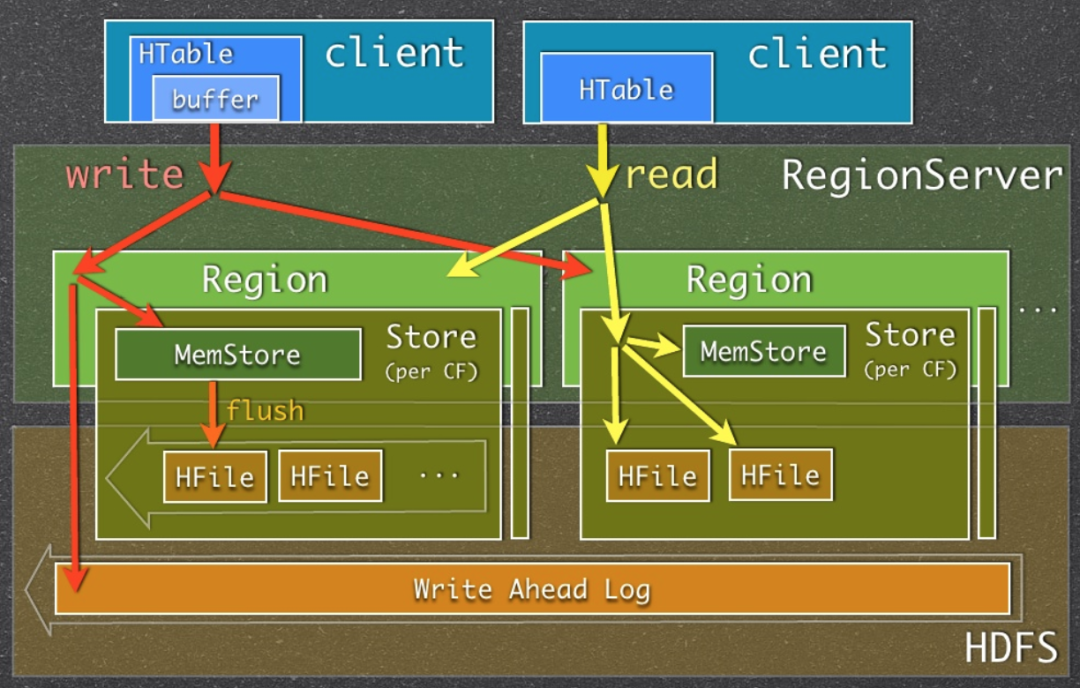
HFile就是LSM树中的高层实现。从逻辑上来讲,它是一棵满的3层B+树,从上到下的3层索引分别是Root index block、Intermediate index block和Leaf index block,对应到下面的Data block就是HFile的KeyValue结构了。HFile V2索引结构的图示如下:
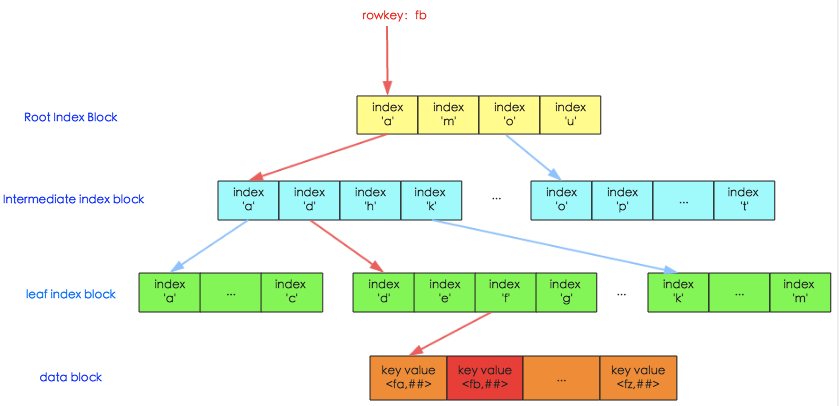
我们已经知道,HFile过多会影响读写性能,因此高层LSM树的合并即对应HFile的合并(Compaction)操作。合并操作又分别Minor和Major Compaction,由于Major Compaction涉及整个Region,对磁盘压力很大,因此要尽量避免。
HBase为了提升LSM结构下的随机读性能,还引入了布隆过滤器(建表语句中可以指定),对应HFile中的Bloom index block,其结构图如下所示。
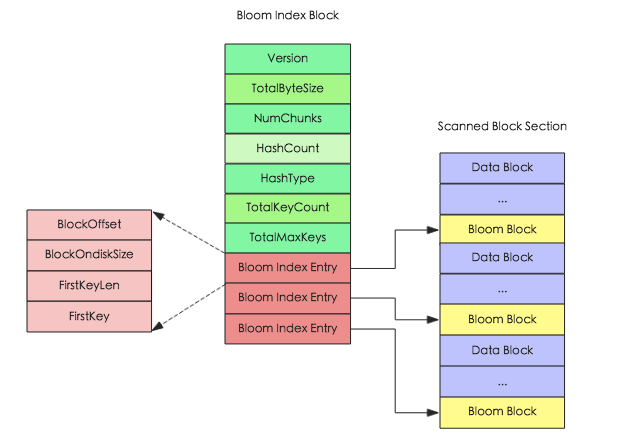
通过布隆过滤器,HBase就能以少量的空间代价,换来在读取数据时非常快速地确定是否存在某条数据,效率进一步提升。
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!

2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)