
面试官:请说说 B 树与 B+ 树的原理及区别?
之前在网上看到过一些B树与B+树的区别然后主要是针对定义来陈述,分分钟看的我快要冬眠,然后在一次面试遇到该没问题没回答上来一首凉凉送 给自己,今天老老实实的分享自己对B树,B+树浅显理解,若望指出不足。
B树的原理
动态查找树主要包括:二叉搜索树,平衡二叉树,红黑树,B树,B-树时间复杂度O(log2N),通过对树高度的降低可以提升查找效率
尤其是在大量数据进行存储的时候会存储到外部 磁盘,通过对外部磁盘的读取时需要快速的查找到对应的位置,所以需要一种高效的外部数据结构。
B树:就是为了存储设备或者磁盘设计的一种平衡查找树
辨析1:B树与红黑树的区别
B树的节点可以有很多孩子节点,红黑树是一种近似平衡的二叉搜索树即每个节点只有两个孩子
一颗含有N个节点的B树和红黑树的高度是一样的O(lgn)。
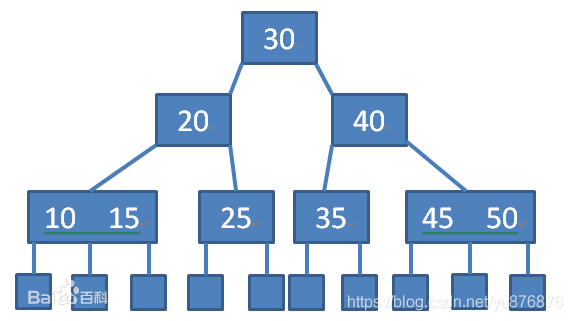
B树的定义
对于一颗M阶的B树
树中的每个节点最多有m个孩子 除了根节点和叶子节点外,其他节点最少含有m/2(取上限)个孩子 若根节点不是叶子节点,则根节点最少含有两个孩子 所以叶子节点都在同一层,叶子节点不包含任何关键字信息
B树的类型与节点定义
struct BTNode
{
int keyNum ; //实际关键字的个数
PBTNode parent;//指向父亲节点
PBTNode *ptr ;
keyType *key ; //关键字向量
}
B树的插入操作
B树的插入
若B树中已存在需要插入的键值时,用新的键值替换旧值; 若B树中不存在这个值,则在叶子节点进行插入操作;
具体插入过程如下
对于高度为h的m阶B树,新节点一般插在第h层。
若该节点中关键码个数小于m-1,则直接插入 若该节点中关键码个数等于m-1,则节点分裂。以中间的关键码为界,
将节点一分为二,产生一个新的节点,并将中间关键码插入到父节点中。
重复上述过程,最坏情况一直分裂高根节点,则B树就会增加一层。
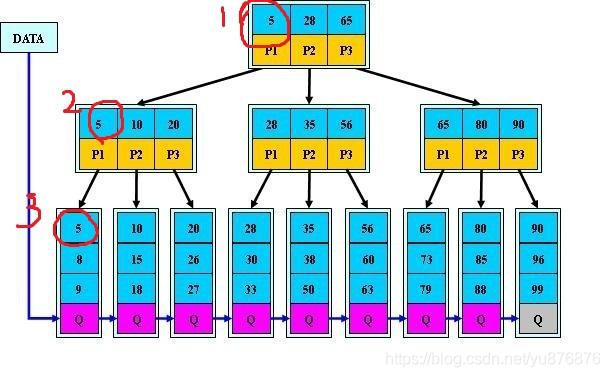
B+树的插入操作
B+树插入
1.若为空树直接插入
2.对于叶子结点: 根据key找到叶子结点,对叶子结点进行插入操作。插入后如果当前叶子结点的key值数b不大于m-1,则插入结束。
反之,将这个叶子结点分成左右两个叶子结点进行操作,左叶子结点包含前m/2个记录,右叶子结点包含剩下的记录key,将第m/2+1个记录的key进位到父结点中,(父结点必须是索引类型的结点)
进位到父结点的key,进位的key左孩子指向左结点,右孩子指向右结点。
3.对于索引结点: 如果当前结点的key个数小于等于m-1,插入结束。
反之,将这个索引类型的结点分成两个索引结点,左索引结点包含前(m-1)/2个数据,右结点包含m-(m-1)/2个数据
将第m/2个key进位到父结点中,进位的key左孩子指向左结点,右孩子指向右结点
剖析2:为什么B+树比B树更适合做系统的数据库索引和文件索引
1)B+树的磁盘读写代价更低
因为B+树内部结点没有指向关键字具体信息的指针,内部结点相对B树小
2)B+树的查询更加稳定
因为非终端结点并不是指向文件内容的结点,仅仅是作为叶子结点的关键字索引,因此所有的关键字查询都会走一条从根节点到叶子结点的路径。即s所有关键字查询的长度是一样的,查询效率稳定。
原文:blog.csdn.net/yu876876/article/details/84896789
正文结束
1.心态崩了!税前2万4,到手1万4,年终奖扣税方式1月1日起施行~
