
【关于 GECToR】 那些你不知道的事
作者:杨夕
论文:GECToR–Grammatical Error Correction: Tag, Not Rewrite
会议:ACL2020
论文下载地址:chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Farxiv.org%2Fpdf%2F2005.12592.pdf#=&zoom=125
论文代码:https://github.com/grammarly/gector
本文链接:https://github.com/km1994/nlp_paper_study
个人介绍:大佬们好,我叫杨夕,该项目主要是本人在研读顶会论文和复现经典论文过程中,所见、所思、所想、所闻,可能存在一些理解错误,希望大佬们多多指正。
先介绍一下,自己为什么会读这一篇文章,主要原因是自己正好 参加了 科大讯飞 举办的 CIEC-CTC 2021 中文文本纠错比赛,然后刚好该比赛的 baseline 就是 ctc_gector,所以就想了读一下该文章,顺便学习一下 文本纠错任务。
【注:手机阅读可能图片打不开!!!】
一、摘要
论文方法:提出了仅使用Transformer编码器的简单有效的GEC序列标注器。
论文思路:
首先是错误的语料库;
其次是有错误和无错误的平行语料库的组合。
系统在综合数据上进行了预训练;
然后分两个阶段进行了微调:
我们设计了自定义的字符级别转换,以将输入字符映射到纠正后的目标。
效果:
我们最好的单模型以及联合模型GEC标注器分别在CoNLL-2014测试集上F0.5达到65.3和66.5,在BEA-2019上F0.5达到72.4和73.6。模型的推理速度是基于Transformer的seq2seq GEC系统的10倍
二、论文背景
2.1 什么是 seq2seq?
背景:由于Seq2Seq在机器翻译等领域的成功应用,把这种方法用到类似的语法纠错问题上也是非常自然的想法。
seq2seq 的输入输出:
机器翻译的输入是源语言(比如英语),输出是另外一个目标语言(比如法语);
语法纠错的输入是有语法错误的句子,输出是与之对应的语法正确的句子;
区别:只在于机器翻译的输入输出是不同的语言而语法纠错的输入输出是相同的语言。
2.2 Transformer 后 的 seq2seq ?
随着 Transformer 在机器翻译领域的成功,主流的语法纠错也都使用了 Transformer 来作为 Seq2Seq 模型的 Encoder 和 Decoder。
当然随着 BERT 等 Pretraining 模型的出现,机器翻译和语法纠错都使用了这些 Pretraining 的 Transformer 模型来作为初始化参数,并且使用领域的数据进行 Fine-Tuning。由于领域数据相对 Pretraining 的无监督数据量太少,最近合成的(synthetic)数据用于 Fine-tuning 变得流行起来。查看一下 nlpprogress 的 GEC 任务 ,排行榜里的方法大多都是使用了BERT 等 Pretraining 的 Seq2Seq 模型。
三、论文动机
3.1 什么是 GEC 系统?
3.1.1 基于 encoder-decoder 模型 GEC 系统
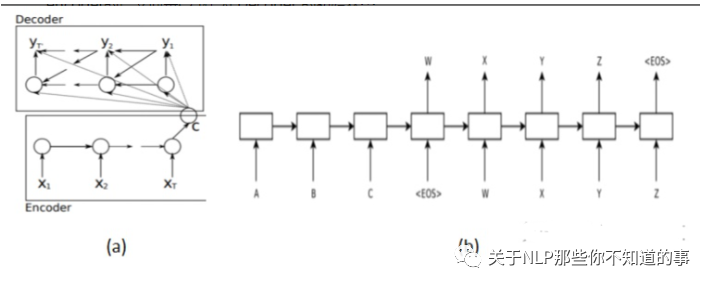
介绍:基于 NMT 自然还是要使用基于encoder-decoder 模型的 Seq2Seq。使用 RNN 作为核心网络;
结构:
用一个 RNN (Encoder)输入句子F编码成一个固定长度的向量;
用另一个 RNN (Decoder)基于该向量进行解码,输出纠正后的句子;
3.1.2 基于 attention 机制 GEC 系统
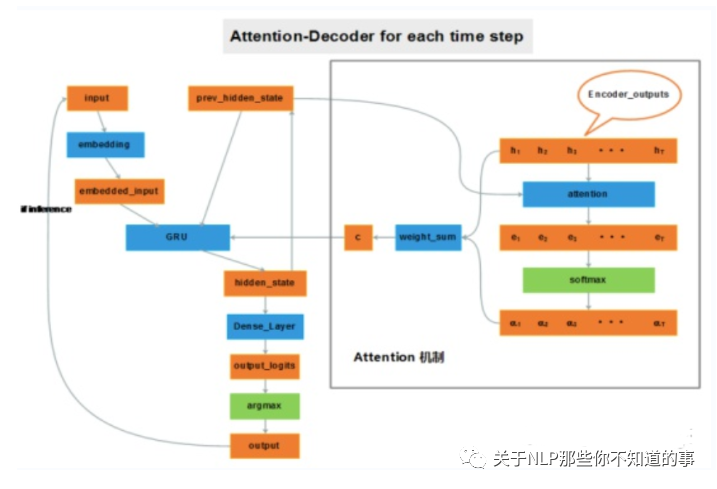
动机:RNN 对长距离依赖的不敏感和“输入的表示”(就是第5个模型中的压紧处理), 输入的表示问题相比于长距离依赖问题更加严重。
eg:想象有两个输入句子,第一个仅包含3个单词,第二个包含100个单词,而encoder居然无差别地将它们都编码成相同长度的向量(比如说50维)。这一做法显然存在问题,长度为100的句子中很多信息可能被忽略了。
介绍:加入attention机制后,如果给 decoder 多提供了一个输入“c”,在解码序列的每一步中都让“c”参与就可以缓解瓶颈问题。输入序列中每个单词对 decoder 在不同时刻输出单词时的帮助作用不一样,所以就需要提前计算一个 attention score 作为权重分配给每个单词,再将这些单词对应的 encoder output 带权加在一起,就变成了此刻 decoder 的另一个输入“c”。
3.1.3 基于 Transformer-NMT 的 GEC 系统
介绍:基于 Transformer-NMT 自然还是要使用基于encoder-decoder 模型的 Seq2Seq。使用 Transformer 作为核心网络;
3.2 NMT-based GEC系统 存在 什么问题?
由于 NMT-based GEC系统 的 核心是 seq2seq 结构,所以在部署的时候会遇到以下问题:
缓慢的推理速度;
需要大量的训练数据;
可解释性,从而使他们需要其他功能来解释更正,例如语法错误类型分类;
四、论文介绍
4.1 论文解决 NMT-based GEC系统 问题的核心是什么?
将GEC任务从序列生成简化到序列标注来解决 NMT-based GEC系统 问题
4.2 GEC 的 训练阶段?
对合成数据进行预训练;
对有错误的平行语料库进行微调;
对有错误和无错误的平行语料库的组合进行微调。
4.3 NMT-based GEC 系统 与 GEC 在预测阶段的区别?
NMT-based GEC 系统:保留字符,删除字符以及在字符之前添加短语;
GEC 系统:解码器是 softmax 层。PIE是一个迭代序列标注 GEC 系统,可预测字符级编辑操作。
4.4 NMT-based GEC 系统 与 GEC 的区别是什么?
开发自定义的 g-transformations:通过字符级编辑以执行语法错误纠正。预测 g-transformations 而不是常规字符可改善 GEC 序列标签系统的通用性。
将微调阶段分为两个阶段:
对仅错误的句子进行微调;
然后对包含有错误和无错误句子的小型高质量数据集进行进一步的微调。
通过在我们的GEC序列标注系统中加入预训练的Transformer编码器,可以实现卓越的性能。在实验中,XLNet和RoBERTa的编码器的性能优于其他三个Transformer编码器(ALBERT,BERT和GPT-2)。
五、论文思路
5.1 Token-level transformations
包含 Basic transformations 和 g-transformations 两种方法。
5.1.1 Basic transformations
保持不变、删除、在目前的 token 后面添加一个 token、将目前的 token 替换为另一个 token
5.1.2 g-transformations
主要是一些具体的任务,比如:改变大小写、将当前的token与下一个token合并、把目前的token分解为两个、单数转复数等等
5.1.3 数据预处理
要将任务作为序列标注问题进行处理,我们需要将每个目标句子从训练/评估集中转换为标记序列,其中每个标记都映射到单个源字符。下面是表3中针对颜色编码的句子对的三步预处理算法的简要说明:
将源句子中的每个字符映射到目标句子中的字符的子序列;
对于列表中的每个映射,需要找到将源字符转换为目标子序列的字符级别转换;
每个源字符仅保留一个转换
注:迭代序列标记方法增加了一个约束,因为我们只能为每个字符使用单个标记。如果有多个转换,我们将采用第一个不是$KEEP标记的转换。
六、Tagging model architecture
GEC序列标注模型是一种编码器,由预训练的 BERT 型 transformer 组成,堆叠有两个线性层,顶部有 softmax 层。
我们始终使用预训练 transformer 的 Base 配置。
Tokenization 取决于特定 transformer 的设计:
BPE被用于RoBERTa;
BERT 使用 WordPiece;
XLNet 则使用 SentencePiece。
为了在字符级别处理信息,我们从编码器表示中获取每个字符的第一个子词,然后将其传递到后续的线性层,这些线性层分别负责错误检测和错误标记。
七、Iterative sequence tagging approach
使用GEC sequence tagger标注修改过的序列,然后再次纠正,以这样的方式进行迭代,保证尽可能地完全纠正句子。由于模型问题,一次迭代只能执行一次编辑,但是很多错误并不能由一次编辑来纠正,所以多次迭代具有相应的科学性。
八、实战
8.1 Requirements
python=3.6
torch==1.3.0
allennlp==0.8.4
python-Levenshtein==0.12.0
transformers==2.2.2
scikit-learn==0.20.0
sentencepiece==0.1.91
overrides==4.1.2
8.2 数据介绍
{"ID": "ID14347228", "source": "优点:反映科目之间的对应关系,便于了解经济业务概况,辩于检查和分析经问济业务;", "target": "优点:反映科目之间的对应关系,便于了解经济业务概况,便于检查和分析经济业务;"}
{"ID": "ID00558239", "source": "明武宗时,宦官刘瑾被施刑,据说割天三夜。", "target": "明武宗时,宦官刘瑾被施以此刑,据说割了三天三夜。"}
{"ID": "ID13767986", "source": "昌江出版集团北京图书中心总编辑、《狼图腾》责任编辑安波舜这样描述自己眼中的姜戎:67“如果他走在任何地方,没有任何人会注意他。”", "target": "长江出版集团北京图书中心总编辑、《狼图腾》责任编辑安波舜这样描述自己眼中的姜戎:67“如果他走在任何地方,没有任何人会注意他。”"}
注:ID 为编号;source 为 错误句子;target 为 纠错后的句子
eg:source 中的 ”优点:反映科目之间的对应关系,便于了解经济业务概况,辩于检查和分析经问济业务;” 加粗的词是错误的
target:“优点:反映科目之间的对应关系,便于了解经济业务概况,便于检查和分析经济业务;”
8.3 操作
8.3.1 安装依赖包
pip install -r requirements.txt
8.3.2 模型训练
将训练集train.json中数据分成两个文件,train.src 和 train.tgt
使用tokenizer.py或其他工具将数据进行分词
使用预处理脚本将数据处理成 gecotr 需要的格式
python utils/preprocess_data.py -s SOURCE -t TARGET -o OUTPUT_FILE
使用stage1_bert_ctc2021.sh训练模型
8.3.3 模型推理
sh run_bert_ctc2021.sh
8.4 代码细节学习
8.4.1 数据分隔
将训练集train.json中数据分成两个文件,train.src和train.tgt,这里并没有写代码,而是通过一些工具进行分隔,所以不做介绍。
分隔后的数据
train.src
优点:反映科目之间的对应关系,便于了解经济业务概况,辩于检查和分析经问济业务;
明武宗时,宦官刘瑾被施刑,据说割天三夜。
昌江出版集团北京图书中心总编辑、《狼图腾》责任编辑安波舜这样描述自己眼中的姜戎:67“如果他走在任何地方,没有任何人会注意他。”
train.tgt
优点:反映科目之间的对应关系,便于了解经济业务概况,便于检查和分析经济业务;
明武宗时,宦官刘瑾被施以此刑,据说割了三天三夜。
长江出版集团北京图书中心总编辑、《狼图腾》责任编辑安波舜这样描述自己眼中的姜戎:67“如果他走在任何地方,没有任何人会注意他。”
8.4.2 数据分词
使用 Bert 中 tokenizer.py 将数据进行分词,调用 函数:
# 功能:对 文件中句子 进行 分词
def segment_for_file(inp_file_name,onp_file_name):
with open(inp_file_name, encoding="utf-8",mode="r") as fr, open(onp_file_name, encoding="utf-8",mode="a+") as fw:
lines = fr.readlines()
for line in tqdm(lines):
line = tokenization.convert_to_unicode(line)
if not line:
print()
continue
tokens = tokenizer.tokenize(line)
line = ' '.join(tokens)
fw.write(f"{line}\n")
分词后的数据:
2 ##2 岁 的 威 廉 - 卡 瓦 略 已 经 为 葡 萄 牙 国 家 队 踢 了 两 场 比 赛 了 , 他 在 20 ##1 ##3 年 11 月 1 ##9 日 葡 萄 牙 客 战 瑞 典 的 生 死 战 中 替 补 出 场 上 演 触 子 秀 。
co ##ls ##pan = \ " 5 \ " style = \ " back ##ground - color : silver ;
...
8.4.3 Token-level transformations 使用预处理脚本将数据处理成 gecotr 需要的格式(训练数据格式)
包含 Basic transformations 和 g-transformations 两种方法。
8.4.3.1 Basic transformations
保持不变、删除、在目前的 token 后面添加一个 token、将目前的 token 替换为另一个 token
8.4.3.2 g-transformations
主要是一些具体的任务,比如:改变大小写、将当前的token与下一个token合并、把目前的token分解为两个、单数转复数等等
8.4.3.3 数据预处理
要将任务作为序列标注问题进行处理,我们需要将每个目标句子从训练/评估集中转换为标记序列,其中每个标记都映射到单个源字符。下面是表3中针对颜色编码的句子对的三步预处理算法的简要说明:
将源句子中的每个字符映射到目标句子中的字符的子序列;
对于列表中的每个映射,需要找到将源字符转换为目标子序列的字符级别转换;
每个源字符仅保留一个转换
注:迭代序列标记方法增加了一个约束,因为我们只能为每个字符使用单个标记。如果有多个转换,我们将采用第一个不是$KEEP标记的转换。
8.4.3.4 操作
$ python utils/preprocess_data.py -s SOURCE -t TARGET -o OUTPUT_FILE --chunk_size 1000000 -m 128
eg:
$ python utils/preprocess_data.py -s train.src -t train.tgt -o train.gecotr --chunk_size 1000000 -m 128
注:
-s:source 文件的位置
-t:target 文件的位置
-o:输出文件的位置
--chunk_size:Dump each chunk size
-m:序列最大长度
举例说明
例子一:
source:'明 武 宗 时 , 宦 官 刘 瑾 被 施 刑 , 据 说 割 天 三 夜 。'
target:'明 武 宗 时 , 宦 官 刘 瑾 被 施 以 此 刑 , 据 说 割 了 三 天 三 夜 。'
>>>
编码:'$STARTSEPL|||SEPR$KEEP 明SEPL|||SEPR$KEEP 武SEPL|||SEPR$KEEP 宗SEPL|||SEPR$KEEP 时SEPL|||SEPR$KEEP ,SEPL|||SEPR$KEEP 宦SEPL|||SEPR$KEEP 官SEPL|||SEPR$KEEP 刘SEPL|||SEPR$KEEP 瑾SEPL|||SEPR$KEEP 被SEPL|||SEPR$KEEP 施SEPL|||SEPR$APPEND_以SEPL__SEPR$APPEND_此 刑SEPL|||SEPR$KEEP ,SEPL|||SEPR$KEEP 据SEPL|||SEPR$KEEP 说SEPL|||SEPR$KEEP 割SEPL|||SEPR$APPEND_了SEPL__SEPR$APPEND_三 天SEPL|||SEPR$KEEP 三SEPL|||SEPR$KEEP 夜SEPL|||SEPR$KEEP 。SEPL|||SEPR$KEEP'
例子二:
source:'昌 江 出 版 集 团 北 京 图 书 中 心 总 编 辑 、 《 狼 图 腾 》 责 任 编 辑 安 波 舜 这 样 描 述 自 己 眼 中 的 姜 戎 :67 “ 如 果 他 走 在 任 何 地 方 , 没 有 任 何 人 会 注 意 他 。”'
target:'长 江 出 版 集 团 北 京 图 书 中 心 总 编 辑 、 《 狼 图 腾 》 责 任 编 辑 安 波 舜 这 样 描 述 自 己 眼 中 的 姜 戎 :67 “ 如 果 他 走 在 任 何 地 方 , 没 有 任 何 人 会 注 意 他 。”'
>>>
编码:'$STARTSEPL|||SEPR$KEEP 昌SEPL|||SEPR$REPLACE_长 江SEPL|||SEPR$KEEP 出SEPL|||SEPR$KEEP 版SEPL|||SEPR$KEEP 集SEPL|||SEPR$KEEP 团SEPL|||SEPR$KEEP 北SEPL|||SEPR$KEEP 京SEPL|||SEPR$KEEP 图SEPL|||SEPR$KEEP 书SEPL|||SEPR$KEEP 中SEPL|||SEPR$KEEP 心SEPL|||SEPR$KEEP 总SEPL|||SEPR$KEEP 编SEPL|||SEPR$KEEP 辑SEPL|||SEPR$KEEP 、SEPL|||SEPR$KEEP 《SEPL|||SEPR$KEEP 狼SEPL|||SEPR$KEEP 图SEPL|||SEPR$KEEP 腾SEPL|||SEPR$KEEP 》SEPL|||SEPR$KEEP 责SEPL|||SEPR$KEEP 任SEPL|||SEPR$KEEP 编SEPL|||SEPR$KEEP 辑SEPL|||SEPR$KEEP 安SEPL|||SEPR$KEEP 波SEPL|||SEPR$KEEP 舜SEPL|||SEPR$KEEP 这SEPL|||SEPR$KEEP 样SEPL|||SEPR$KEEP 描SEPL|||SEPR$KEEP 述SEPL|||SEPR$KEEP 自SEPL|||SEPR$KEEP 己SEPL|||SEPR$KEEP 眼SEPL|||SEPR$KEEP 中SEPL|||SEPR$KEEP 的SEPL|||SEPR$KEEP 姜SEPL|||SEPR$KEEP 戎SEPL|||SEPR$KEEP :SEPL|||SEPR$KEEP 67SEPL|||SEPR$KEEP “SEPL|||SEPR$KEEP 如SEPL|||SEPR$KEEP 果SEPL|||SEPR$KEEP 他SEPL|||SEPR$KEEP 走SEPL|||SEPR$KEEP 在SEPL|||SEPR$KEEP 任SEPL|||SEPR$KEEP 何SEPL|||SEPR$KEEP 地SEPL|||SEPR$KEEP 方SEPL|||SEPR$KEEP ,SEPL|||SEPR$KEEP 没SEPL|||SEPR$KEEP 有SEPL|||SEPR$KEEP 任SEPL|||SEPR$KEEP 何SEPL|||SEPR$KEEP 人SEPL|||SEPR$KEEP 会SEPL|||SEPR$KEEP 注SEPL|||SEPR$KEEP 意SEPL|||SEPR$KEEP 他SEPL|||SEPR$KEEP 。SEPL|||SEPR$KEEP ”SEPL|||SEPR$KEEP'
例子三:
source:'此 片 的 电 视 斑 ( 収 偻 迪 士 尼 频 道 播 版 本 ) 是 从 戏 院 版 剪 接 的 版 本 。'
target:'此 片 的 电 视 版 ( 也 就 是 于 迪 士 尼 频 道 播 出 的 版 本 ) 是 从 戏 院 版 剪 接 的 版 本 。'
>>>
编码:'$STARTSEPL|||SEPR$KEEP 此SEPL|||SEPR$KEEP 片SEPL|||SEPR$KEEP 的SEPL|||SEPR$KEEP 电SEPL|||SEPR$KEEP 视SEPL|||SEPR$KEEP 斑SEPL|||SEPR$REPLACE_版 (SEPL|||SEPR$KEEP 収SEPL|||SEPR$REPLACE_也 偻SEPL|||SEPR$REPLACE_就SEPL__SEPR$APPEND_是SEPL__SEPR$APPEND_于 迪SEPL|||SEPR$KEEP 士SEPL|||SEPR$KEEP 尼SEPL|||SEPR$KEEP 频SEPL|||SEPR$KEEP 道SEPL|||SEPR$KEEP 播SEPL|||SEPR$APPEND_出SEPL__SEPR$APPEND_的 版SEPL|||SEPR$KEEP 本SEPL|||SEPR$KEEP )SEPL|||SEPR$KEEP 是SEPL|||SEPR$KEEP 从SEPL|||SEPR$KEEP 戏SEPL|||SEPR$KEEP 院SEPL|||SEPR$KEEP 版SEPL|||SEPR$KEEP 剪SEPL|||SEPR$KEEP 接SEPL|||SEPR$KEEP 的SEPL|||SEPR$KEEP 版SEPL|||SEPR$KEEP 本SEPL|||SEPR$KEEP 。SEPL|||SEPR$KEEP'
8.4.4 Tagging model architecture
GEC序列标注模型是一种编码器,由预训练的 BERT 型 transformer 组成,堆叠有两个线性层,顶部有 softmax 层。
我们始终使用预训练 transformer 的 Base 配置。
Tokenization 取决于特定 transformer 的设计:
BPE被用于RoBERTa;
BERT 使用 WordPiece;
XLNet 则使用 SentencePiece。
为了在字符级别处理信息,我们从编码器表示中获取每个字符的第一个子词,然后将其传递到后续的线性层,这些线性层分别负责错误检测和错误标记。
"""Basic model. Predicts tags for every token"""
from typing import Dict, Optional, List, Any
import numpy
import torch
import torch.nn.functional as F
from allennlp.data import Vocabulary
from allennlp.models.model import Model
from allennlp.modules import TimeDistributed, TextFieldEmbedder
from allennlp.nn import InitializerApplicator, RegularizerApplicator
from allennlp.nn.util import get_text_field_mask, sequence_cross_entropy_with_logits
from allennlp.training.metrics import CategoricalAccuracy
from overrides import overrides
from torch.nn.modules.linear import Linear
@Model.register("seq2labels")
class Seq2Labels(Model):
"""
This ``Seq2Labels`` simply encodes a sequence of text with a stacked ``Seq2SeqEncoder``, then
predicts a tag (or couple tags) for each token in the sequence.
Parameters
----------
vocab : ``Vocabulary``, required
A Vocabulary, required in order to compute sizes for input/output projections.
text_field_embedder : ``TextFieldEmbedder``, required
Used to embed the ``tokens`` ``TextField`` we get as input to the model.
encoder : ``Seq2SeqEncoder``
The encoder (with its own internal stacking) that we will use in between embedding tokens
and predicting output tags.
calculate_span_f1 : ``bool``, optional (default=``None``)
Calculate span-level F1 metrics during training. If this is ``True``, then
``label_encoding`` is required. If ``None`` and
label_encoding is specified, this is set to ``True``.
If ``None`` and label_encoding is not specified, it defaults
to ``False``.
label_encoding : ``str``, optional (default=``None``)
Label encoding to use when calculating span f1.
Valid options are "BIO", "BIOUL", "IOB1", "BMES".
Required if ``calculate_span_f1`` is true.
label_namespace : ``str``, optional (default=``labels``)
This is needed to compute the SpanBasedF1Measure metric, if desired.
Unless you did something unusual, the default value should be what you want.
verbose_metrics : ``bool``, optional (default = False)
If true, metrics will be returned per label class in addition
to the overall statistics.
initializer : ``InitializerApplicator``, optional (default=``InitializerApplicator()``)
Used to initialize the model parameters.
regularizer : ``RegularizerApplicator``, optional (default=``None``)
If provided, will be used to calculate the regularization penalty during training.
"""
def __init__(self, vocab: Vocabulary,
text_field_embedder: TextFieldEmbedder,
predictor_dropout=0.0,
labels_namespace: str = "labels",
detect_namespace: str = "d_tags",
verbose_metrics: bool = False,
label_smoothing: float = 0.0,
confidence: float = 0.0,
initializer: InitializerApplicator = InitializerApplicator(),
regularizer: Optional[RegularizerApplicator] = None) -> None:
super(Seq2Labels, self).__init__(vocab, regularizer)
self.label_namespaces = [labels_namespace,
detect_namespace]
self.text_field_embedder = text_field_embedder
self.num_labels_classes = self.vocab.get_vocab_size(labels_namespace)
self.num_detect_classes = self.vocab.get_vocab_size(detect_namespace)
self.label_smoothing = label_smoothing
self.confidence = confidence
self.incorr_index = self.vocab.get_token_index("INCORRECT",
namespace=detect_namespace)
self._verbose_metrics = verbose_metrics
self.predictor_dropout = TimeDistributed(torch.nn.Dropout(predictor_dropout))
self.tag_labels_projection_layer = TimeDistributed(
Linear(text_field_embedder._token_embedders['bert'].get_output_dim(), self.num_labels_classes))
self.tag_detect_projection_layer = TimeDistributed(
Linear(text_field_embedder._token_embedders['bert'].get_output_dim(), self.num_detect_classes))
self.metrics = {"accuracy": CategoricalAccuracy()}
initializer(self)
@overrides
def forward(self, # type: ignore
tokens: Dict[str, torch.LongTensor],
labels: torch.LongTensor = None,
d_tags: torch.LongTensor = None,
metadata: List[Dict[str, Any]] = None) -> Dict[str, torch.Tensor]:
# pylint: disable=arguments-differ
"""
Parameters
----------
tokens : Dict[str, torch.LongTensor], required
The output of ``TextField.as_array()``, which should typically be passed directly to a
``TextFieldEmbedder``. This output is a dictionary mapping keys to ``TokenIndexer``
tensors. At its most basic, using a ``SingleIdTokenIndexer`` this is: ``{"tokens":
Tensor(batch_size, num_tokens)}``. This dictionary will have the same keys as were used
for the ``TokenIndexers`` when you created the ``TextField`` representing your
sequence. The dictionary is designed to be passed directly to a ``TextFieldEmbedder``,
which knows how to combine different word representations into a single vector per
token in your input.
lables : torch.LongTensor, optional (default = None)
A torch tensor representing the sequence of integer gold class labels of shape
``(batch_size, num_tokens)``.
d_tags : torch.LongTensor, optional (default = None)
A torch tensor representing the sequence of integer gold class labels of shape
``(batch_size, num_tokens)``.
metadata : ``List[Dict[str, Any]]``, optional, (default = None)
metadata containing the original words in the sentence to be tagged under a 'words' key.
Returns
-------
An output dictionary consisting of:
logits : torch.FloatTensor
A tensor of shape ``(batch_size, num_tokens, tag_vocab_size)`` representing
unnormalised log probabilities of the tag classes.
class_probabilities : torch.FloatTensor
A tensor of shape ``(batch_size, num_tokens, tag_vocab_size)`` representing
a distribution of the tag classes per word.
loss : torch.FloatTensor, optional
A scalar loss to be optimised.
"""
# 由预训练的 BERT 型 transformer 组成
encoded_text = self.text_field_embedder(tokens)
batch_size, sequence_length, _ = encoded_text.size()
mask = get_text_field_mask(tokens)
# 堆叠有两个线性层
logits_labels = self.tag_labels_projection_layer(self.predictor_dropout(encoded_text))
logits_d = self.tag_detect_projection_layer(encoded_text)
# softmax 层
class_probabilities_labels = F.softmax(logits_labels, dim=-1).view(
[batch_size, sequence_length, self.num_labels_classes])
class_probabilities_d = F.softmax(logits_d, dim=-1).view(
[batch_size, sequence_length, self.num_detect_classes])
error_probs = class_probabilities_d[:, :, self.incorr_index] * mask
incorr_prob = torch.max(error_probs, dim=-1)[0]
#if self.confidence > 0:
# FIXME
probability_change = [self.confidence] + [0] * (self.num_labels_classes - 1)
class_probabilities_labels += torch.cuda.FloatTensor(probability_change).repeat(
(batch_size, sequence_length, 1))
output_dict = {"logits_labels": logits_labels,
"logits_d_tags": logits_d,
"class_probabilities_labels": class_probabilities_labels,
"class_probabilities_d_tags": class_probabilities_d,
"max_error_probability": incorr_prob}
if labels is not None and d_tags is not None:
loss_labels = sequence_cross_entropy_with_logits(logits_labels, labels, mask,
label_smoothing=self.label_smoothing)
loss_d = sequence_cross_entropy_with_logits(logits_d, d_tags, mask)
for metric in self.metrics.values():
metric(logits_labels, labels, mask.float())
metric(logits_d, d_tags, mask.float())
output_dict["loss"] = loss_labels + loss_d
if metadata is not None:
output_dict["words"] = [x["words"] for x in metadata]
return output_dict
@overrides
def decode(self, output_dict: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]:
"""
Does a simple position-wise argmax over each token, converts indices to string labels, and
adds a ``"tags"`` key to the dictionary with the result.
"""
for label_namespace in self.label_namespaces:
all_predictions = output_dict[f'class_probabilities_{label_namespace}']
all_predictions = all_predictions.cpu().data.numpy()
if all_predictions.ndim == 3:
predictions_list = [all_predictions[i] for i in range(all_predictions.shape[0])]
else:
predictions_list = [all_predictions]
all_tags = []
for predictions in predictions_list:
argmax_indices = numpy.argmax(predictions, axis=-1)
tags = [self.vocab.get_token_from_index(x, namespace=label_namespace)
for x in argmax_indices]
all_tags.append(tags)
output_dict[f'{label_namespace}'] = all_tags
return output_dict
@overrides
def get_metrics(self, reset: bool = False) -> Dict[str, float]:
metrics_to_return = {metric_name: metric.get_metric(reset) for
metric_name, metric in self.metrics.items()}
return metrics_to_return
参考
GECToR语法纠错算法
GECToR–Grammatical Error Correction: Tag, Not Rewrite翻译
《GECToR -- Grammatical Error Correction: Tag, Not Rewrite》论文笔记
基于神经机器翻译(NMT)的语法纠错