
卧槽!用户画像详解来了


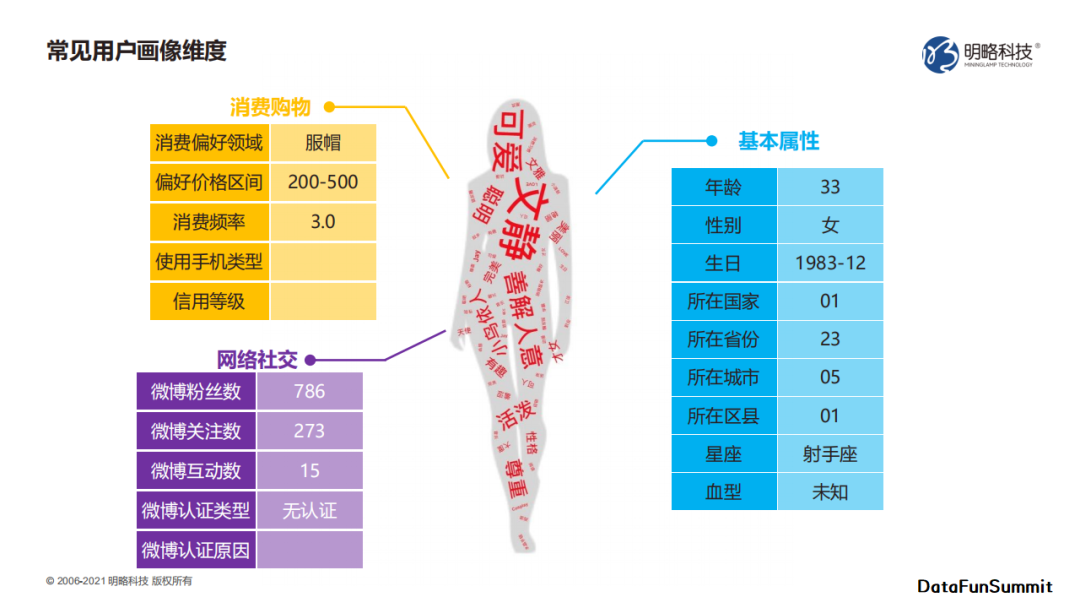

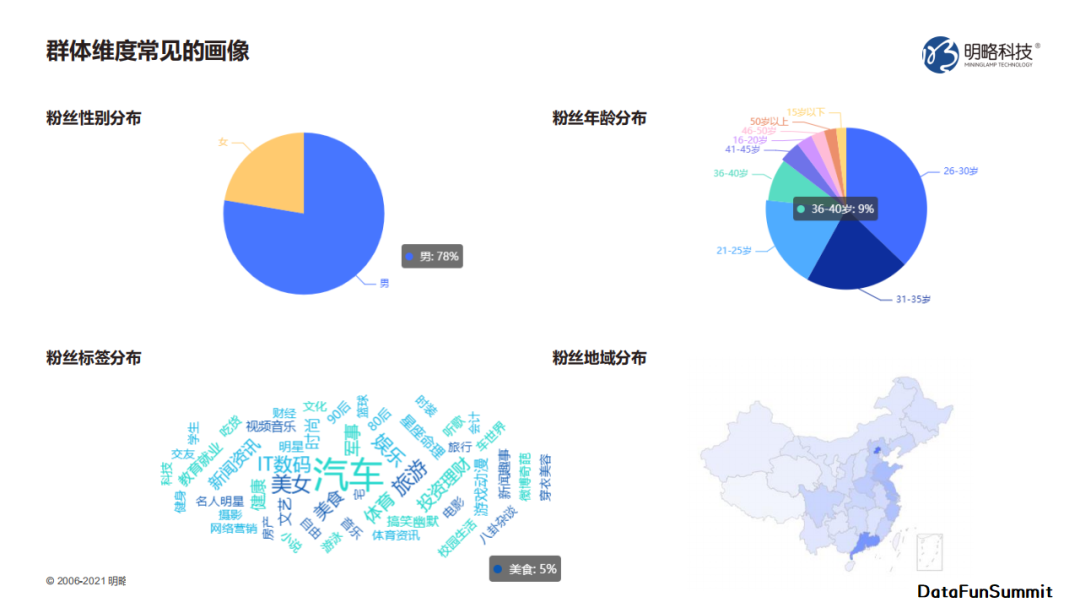

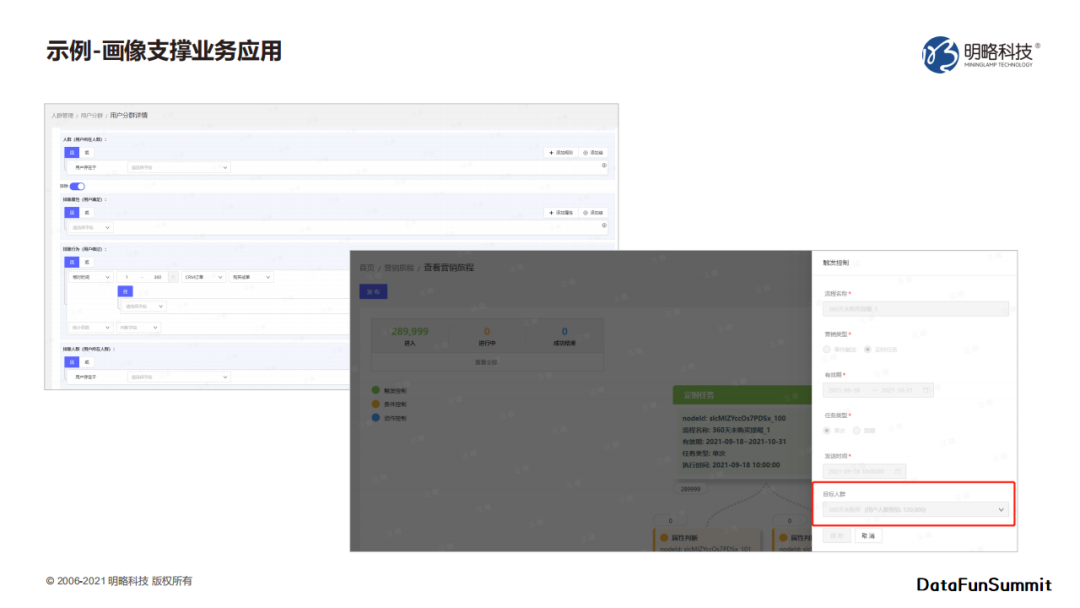
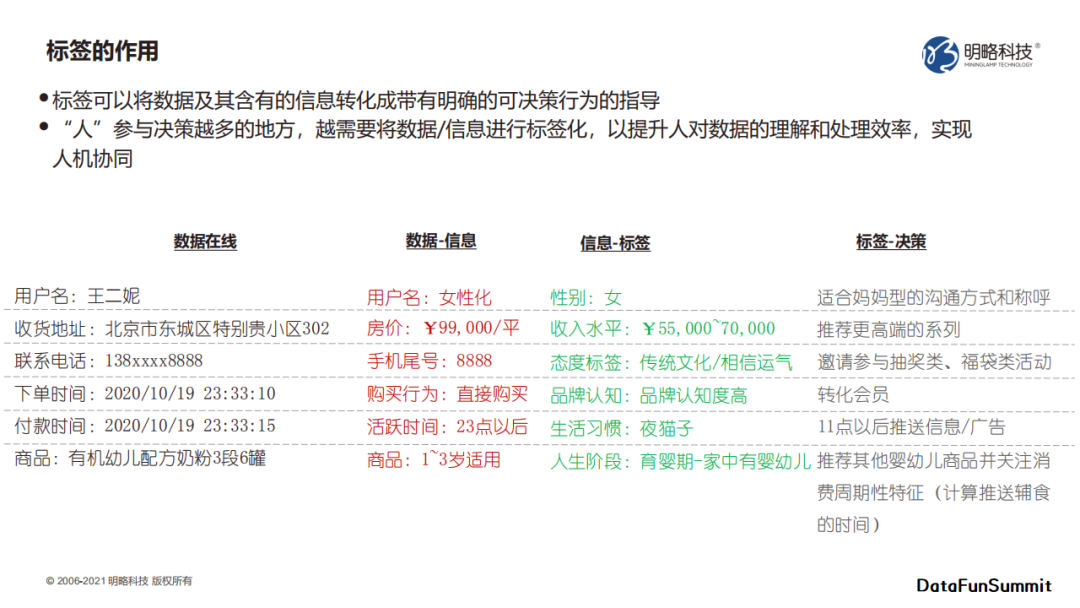
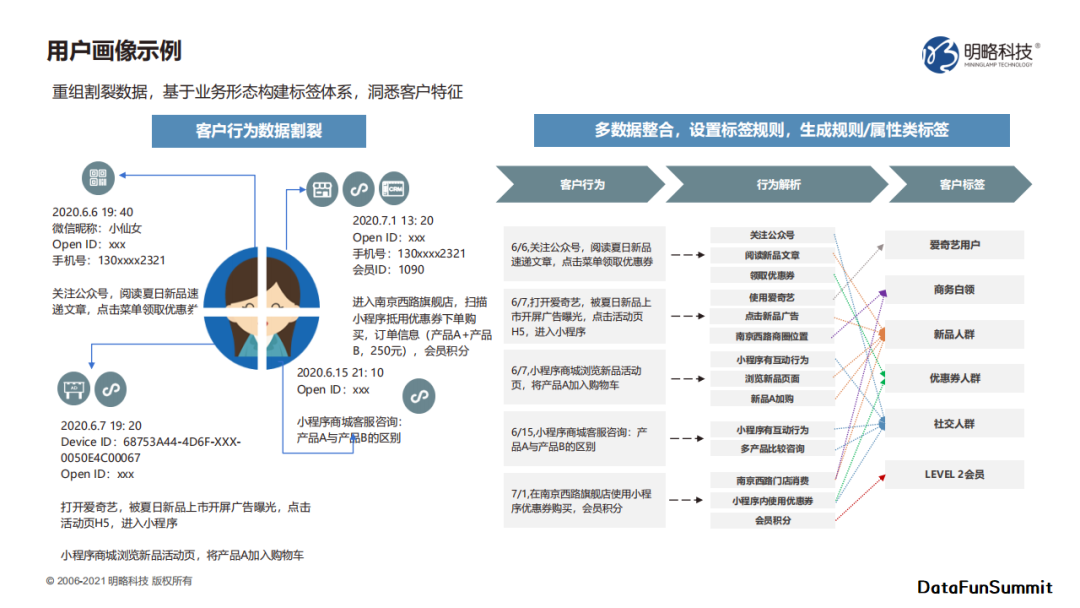
标签可以将数据及其含有的信息转化成带有明确的可决策行为的指导。
人参与决策越多的地方,越需要将信息数据进行标签化,以提升人对数据的理解和处理效率,实现人机协同。

第一步:明确问题和目的是什么,用数据解决问题也不例外;
第二步:梳理现有条件,从中锁定问题的关键点;
第三步:确认分析的维度,即确定分析的对象以及分析角度;
第四步:确定分析方法,例如,求解一道三角形相关的几何体,明确分析对象是三角形,下一步应该考虑用哪个定理去分析它;
第五步:圈选,圈定数据来得到结果,把思路都理顺之后,只需把题干中条件数往公式定理中一带,就能得出最后的结论,算出答案。
第一步:明确带目标的场景。所谓带目标的场景,指的是,设计标签体系要解决的是什么场景下的问题。不仅要知道场景,还需要知道具体的目标。比如广告投放是一个场景,这个场景里面可能会有多种不同的目标,可以是在固定投入的情况下,触达到更多的人,或者是在固定触达人数的情况下,尽可能减少预算;如果要选媒体,那么在不同的目标之下的情况可能也是大不相同的。
第二步:明确场景中的流程和角色。比如广告投放的场景,角色可能会有哪些?比如要选媒体,选媒体点位,选完点位之后,需要确定投放的素材,确定完素材之后,还需要确定时间。考虑时间的时候,还要考虑每个媒体提供的不同的时间的人流量表现是不一样的。这个过程中就包含很多的角色,这些角色在不同的环节中完成不同的工作,他们的关注点也是不一样的,我们需要了解每一个角色在这个过程中需要去解决的问题是什么。
第三步:明确场景中需要被标签化的对象,也就是要去给谁打标签,比如刚刚提到的场景中,我们做广告投放的时候,如果说目标是要去触达到更多的用户,那么用户可能就是打标签的对象。
第四步:明确我们不同对象在场景中需要的标签类型,例如,是基本属性标签,还是消费偏好表现,是动态标签,还是静态标签,是预测标签,还是行为标签,等等。
最后:确定了类型之后,需要列举出标签的值,比如人口属性标签中的年龄段标签,需要进一步确定出“0-15岁”,“16-18岁”,“18岁以上”等具体的值。




推荐阅读
欢迎长按扫码关注「数据管道」