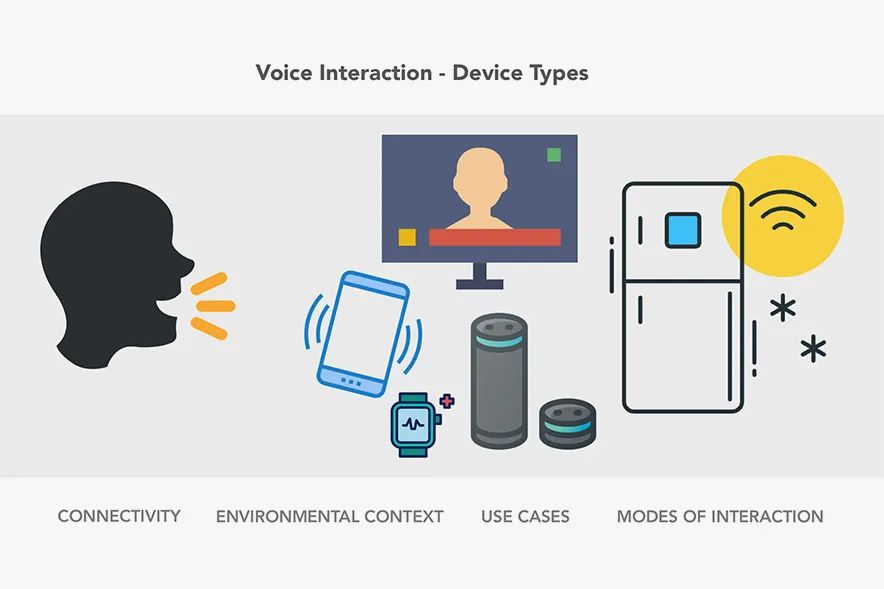
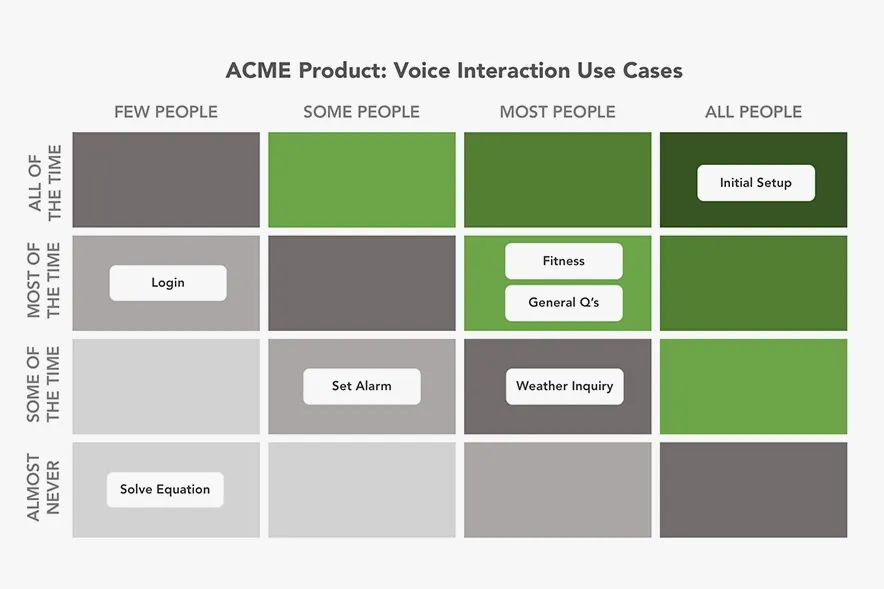
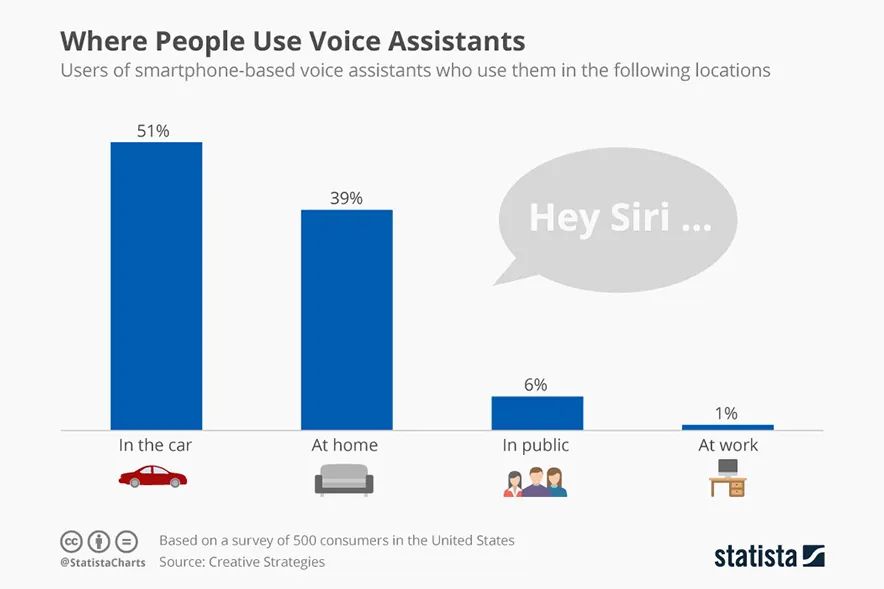
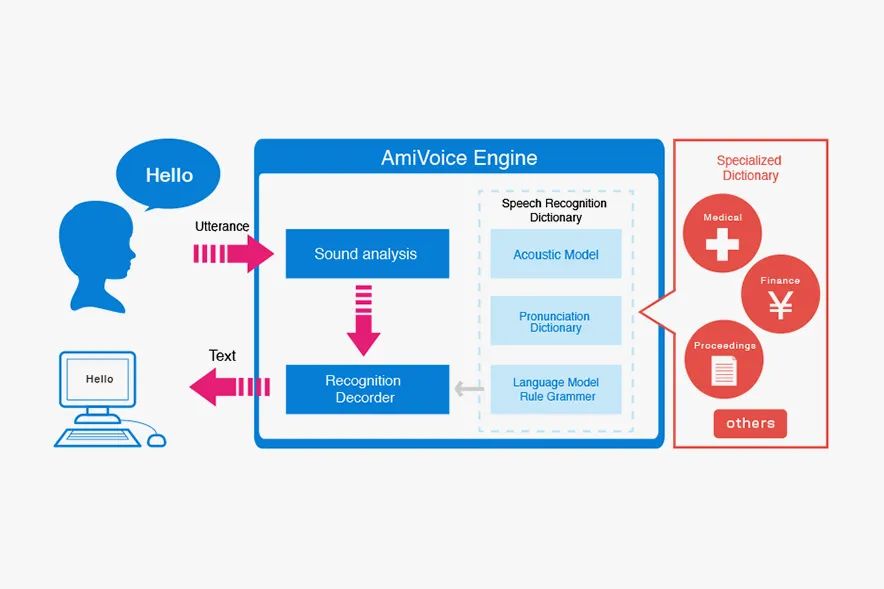
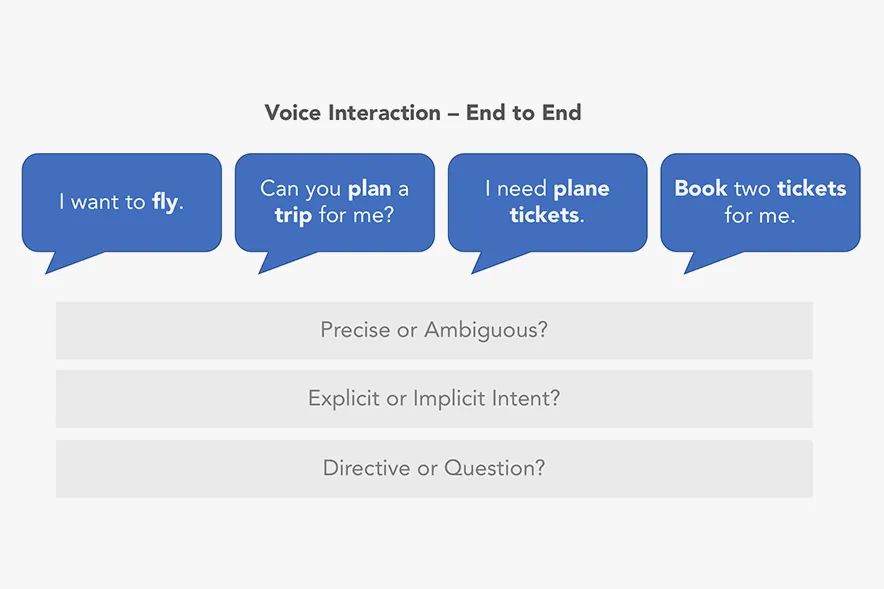
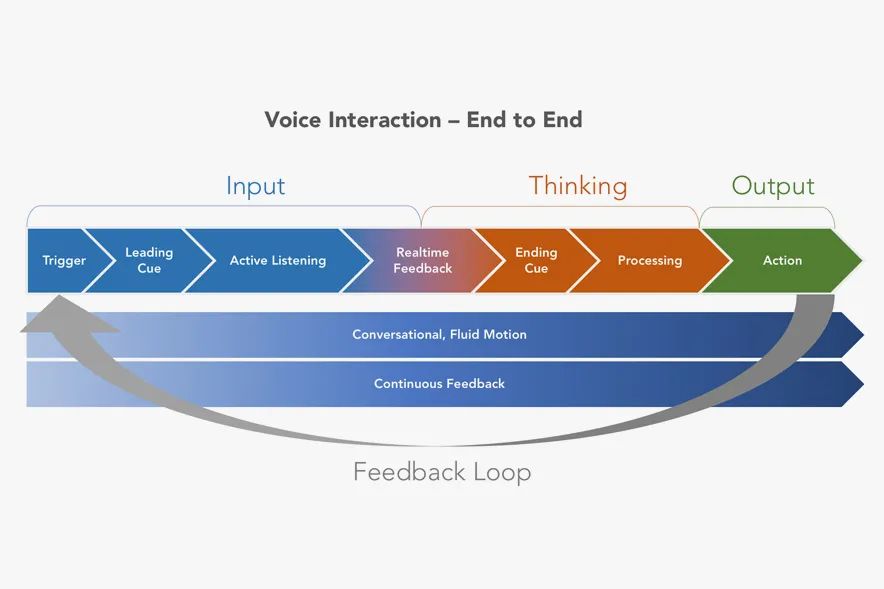
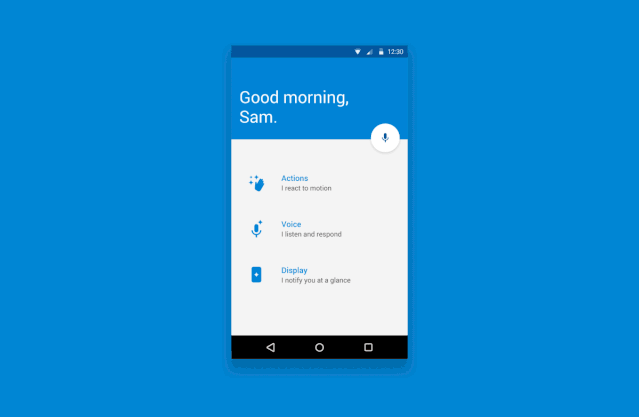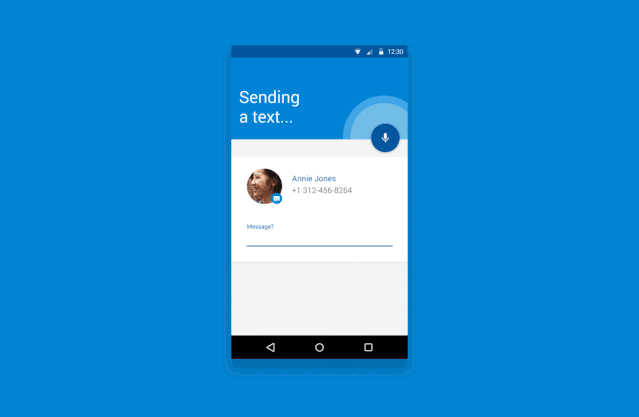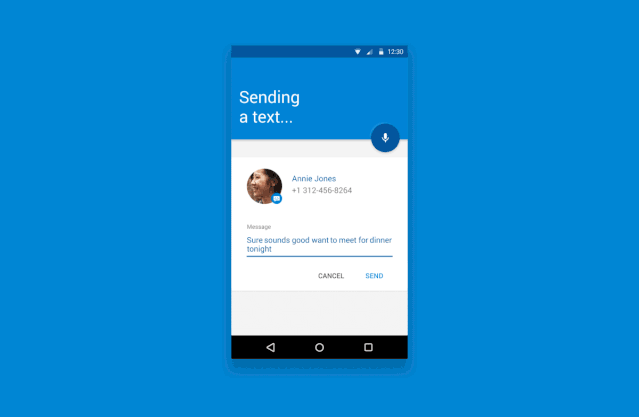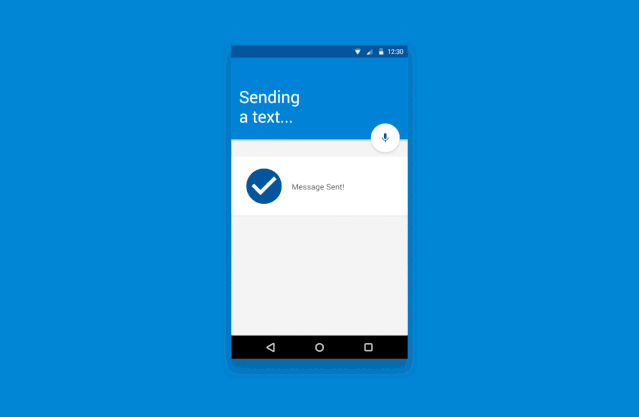
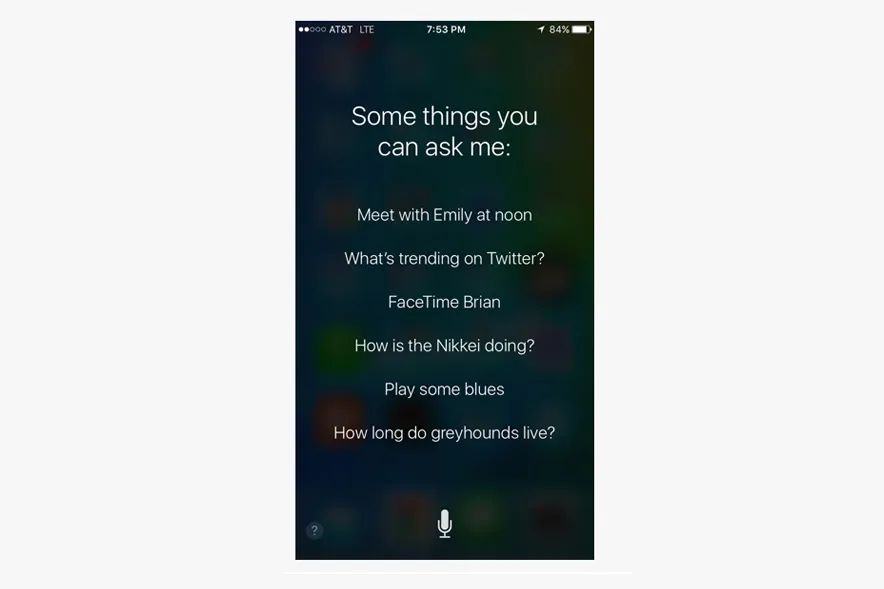
译客专栏|语音交互界面 —— 完全手册三分设关注共 6382字,需浏览 13分钟 ·2022-04-24 17:48 共 6222 字 22 图 预计阅读 16 分钟▲ Xfinity Remote by Juan C. Angustia“给我设置一个 7:15 的闹钟”“好的,正在打给马丁”“不,给我设置一个 7:15 的闹钟!”“对不起,我办不到”(叹气)手动去设置了闹钟我们的声音是各不相同的、复杂的、充满变化的。对于人类来说,语音指令有时都非常复杂且难以处理,更何况现在的处理方是机器。我们阐述想法的方式,我们所属的不同文化背景,我们对于不同俚语的使用,综上所有的因素都对我们理解语言会有影响。所以,设计师和工程师是如何应对这个挑战的呢?我们如何在 AI 与人之间建立信任呢?这时候我们就需要语音交互界面 Voice User Interface (VUI) 的帮助。VUI 可以是任何经由语音所触发的界面。当然 VUI 并不一定需要一个传统意义上有着屏幕的 “界面”。它可以完全以声控或者是触控的形态存在。虽然 VUI 的形态有很多,但他们都有一些用户体验上的共性。我们接下来将站在用户的角度,探索一些交互规则,来帮助身为设计师的你更好的打造基于 VUI 的产品体验。阶段一:“探索” —— 场景限制、依赖关系、用户案例我们与世界进行交互的方式极大地取决于科技上、环境上和社会关系上的限制。它们决定了我们能够处理信息的速度和准确度。在我们深入探讨交互设计规则之前,我们必须首先定义环境上的限制因素。1. 定义交互设备设备的形态决定了我们进行语音交互的模式。▲ 不同种类的交互设备手机• iPhone,Google Pixels,Samsung Galaxies• 网络连接方式:蜂窝数据,Wi-Fi,蓝牙配对• 环境因素对声音的交互影响非常大• 用户非常习惯于用语音进行交互• 允许视觉上、听觉上、触觉上的反馈• 交互模式在不同型号的设备上具有高度的统一性可穿戴式设备• 设备通常有非常强的场景针对性,例如手表、手环和智能鞋• 网络连接方式:蜂窝数据,Wi-Fi,蓝牙配对• 用户非常习惯于语音交互,但是不同设备的交互习惯很不一样• 仅有部分设备允许视觉上、听觉上、触觉上的反馈• 通常会有一个配对设备与用户进行交互同时进行数据处理固定式设备• 台式电脑、带有显示器的设备、温度控制仪、智能家居控制器、音响系统、电视机• 网络连接方式:蜂窝数据,Wi-Fi,蓝牙配对• 用户习惯于在固定位置,固定时间使用这些设备• 对于长得比较像的设备,交互方式通常会比较统一(例如 Google Home 与 Amazon Alexa长的差不多,并且都有相似的交互方式)非固定式设备• 笔记本电脑、平板、应答器、汽车媒体系统• 网络连接方式:蜂窝数据,有线连接(不常见)、Wi-Fi、蓝牙配对• 主要的交互方式通常不是声音• 环境因素对声音的交互影响非常大• 对于同种类的设备,交互方式通常比较统一2. 打造一个用户使用案例的分析表格用户的主要,次要,非次要使用案例是什么?设备是否只有一个主要使用案例(如健康手环),还是有多个主要使用案例(如手机)。用案例分析表格来了解用户是非常重要的。它能帮助你了解用户为什么要使用这个设备,了解用户的主要交互方式是什么,次要交互方式是什么。帮你分清楚什么功能是重点,什么仅仅是锦上添花的东西。▲ 语音控制的用户使用场景表格,对用户常用的功能进行分类。你可以针对每一个交互场景制作一个用例分析表格。它能帮助你了解你的用户现在是如何与这个设备交互的,了解用户期望如何与设备交互,以及用户在什么地点与设备交互。▲ 用户在使用语音管家的地点分布3. 针对交互的模式进行排序如果你正在通过用户调研来获取用户使用案例,那么通过排序来量化你的调研结果是非常重要的。如果某人告诉你:“如果我能够跟我的电视对话,让他说换台就换台,那这个电视就很赞了!”。这时你需要深究一下,他们是否真的会用这个功能?他们了解使用上的限制吗?他们是否真的有使用上的倾向呢?“作为一个设计师,你必须比你的用户还了解他们自己。你必须对他们在有替代功能下依然会坚持使用这个新功能的可能性保持怀疑态度。”举个例子。假如我们正在研究用户是否会偏好于用语音对电视进行控制。那么在这个前提下,我们需要明确的是,语音仅仅是众多交互方式中的 “一种” 而已。用户有非常多的选择,他有一个遥控器,一个已经跟电视配对好的手机,一个游戏手柄,一个无线的物联网设备等等。声音并不是用户默认的交互模式。所以,问题就变成了用户有多大的可能性依赖声音作为 “主要” 交互方式。如果不是主要方式,那么它是次要的吗?还是更次要的?针对交互模式进行排序能够帮助我们了解先觉假设是否成立,这样我们才能够拿捏到准确的交互场景。4. 对技术上的限制进行枚举把我们的语言转化为指令是一个非常复杂的技术难题。在时间、训练次数、网速不受限的条件下,一个被调教好的翻译引擎可以完美地把我们口述指令转化为可以执行的动作。但是不幸的是,我们生活在一个网速有限,时间有限的世界里。虽然我们希望语音交互能跟传统的触控、图形界面一样快,但这是难以达到的。下面流程图讲解了口头指令是如何被转译成机器指令的。如图所示,有非常多复杂的参数得根据我们的词汇、口音、音调被反复调整。▲ AMI 语音处理引擎每一个语音识别平台都有一些独特的技术瓶颈。你在为这些平台设计交互流程时,必须学会拥抱这些技术瓶颈。以下是我们在设计前需要了解的技术规格:• 网络连接速度:设备是否能一直连上网络?• 处理速度:口述指令需要能被实时翻译吗?• 处理精度:速度和精度之间怎么取舍,权衡轻重?• 如何处理缺陷:针对不能识别的指令,技术上有什么兜底策略。用户能使用一些别的交互方式吗?• 如何处理误指令:识别有误的指令是否会造成无法挽回的错误呢?我们的语音识别引擎是否足够的成熟可靠来避免这些严重的错误呢?• 环境测试:语音识别引擎是否在不同的环境下被测试过呢?例如,如果我们正在搭建一个车内互动系统,那么这个系统将会被暴露在比一个智能家居温控计更为嘈杂的噪音背景下。5. 非线性交互此外,我们同样需要考虑用户很多时候是采用非线性的方式与设备在进行交互。例如,如果我想要订一张机票。那么在网页上我必须要按照事先规定好的步骤一项一项来,先选目的地,再选时间等等。但是 VUI 会面对一个更加困难的交互场景。用户可以说 “我们一家想通过商务舱飞到旧金山去”。那么 VUI 需要从里面识别出所有相关的信息,并且这句话里面包含的信息的顺序关系对于订票系统来说可能是错乱的。如下图所示,用户每一句话的意思都可以理解成订机票,但是每一句话的阐述方式都是不一样的。这就是 VUI 所面临的处理难点。阶段二:输入阶段—— 如何通过声音进行交互在上文里,我们已经探索了技术上的限制,设备之间的依赖关系以及用户案例。我们可以更进一步的讨论在合适的场景下,设备如何与人进行交互。首先,我们需要解决设备在什么情况下要开始聆听用户发出的指令。下图介绍了一个基本的语音交互流程:▲ 一个典型涵盖了 “输入 - 处理 - 输出” 的语音交互流程它可以被具象化以下的例子:▲ 如上所示,用户通过语音完成了一次短信发送任务。整个交互流程里有以下几个关键的交互节点:1. 触发引信“触发引信” 是用户用来唤起设备的引子。• 声音引信:用户可以通过一句短语来让设备开始聆听用户指令。• 触控引信:用户通过一个按钮来唤起设备。• 动作引信:用户通过一个动作来唤起设备,例如在传感器前招一下手。• 设备自我唤醒:设备经由被设定好的指令被唤醒。作为一个设计师,你必须了解哪一些唤起引信是跟你的用户案例有关的。并且针对你的用户案例给不同的引信进行相关度上的排序。2. 唤醒反馈信号当一个设备被唤起并开始聆听用户指令时,设备通常需要给一个声音上、视觉上或者触觉上的反馈信号。▲ Alexa 的环形反馈信号则是一个环状灯▲ 谷歌语音助手的唤醒反馈信号则是一个简短的动效这些反馈信号需要遵循以下的原则:• 及时性:在收到有效的唤起指令后,反馈需要以最快的速度被传达给用户。即便它有可能打断用户当前正在执行的操作。• 简洁且快速:反馈信号需要有瞬时性,这点对于常用用户来说至关重要。举个例子,“叮叮”两声蜂鸣比一句“好的 Justin ,你想让我干什么” 要更加有效。反馈信号越长,用户的口述指令就越有可能与你的反馈信号在时间上相冲突。• 清晰的聆听开头:用户需要明确知道设备何时开始录制用户的声音。• 独特性:这个反馈信号需要有别于设备在其他场景下的反馈信号。• 多重信号反馈:可以同时通过多种渠道,例如声音、视觉等来告知反馈。• 初学引导:对于初次使用用户,如果用户似乎不知道从何开始,那么你可以显示一些初始教程来引导用户进行交互。▲ Siri 的新手引导界面3. 收听反馈信号收听反馈是声音交互界面中至关重要的一环。它能让用户及时且明确的知道自己的声音被设备记录下来且开始进行处理。收听反馈同样需要能让用户纠正或者进行二次确认的权力。▲ 微软 Cortana 通过将实时文字转译作为收听反馈信号以下是一些收听反馈信号的设计规则:• 给予及时性的视觉反馈:这是一种很常见的反馈形式(在手机上很常见,例如 Siri 在收听时的律动波纹)。根据录入声音的音色、音量大小,设备则会显示出相应的波纹和颜色。• 音频回放:通过一个简单的回放来确认被录入的声音内容。• 实时文字转译:在用户说话时显示实时的文字转译内容。• 文字化的指令转译:把用户说的自然语言转译成指令话的文字显示出来。• 显示屏以外的视觉反馈(信号灯):通过一些显示屏外的设备(LED灯)来告知反馈。4. 收听结束反馈信号这个反馈将告知用户,设备已经停止聆听用户说的话,并且系统将开始处理用户指令。许多我们之前提到的唤醒反馈的交互规则在这里同样适用(及时性、简洁性、独特性)。除此之外,还有一些别的交互规则:• 足够长的处理时间:保证用户已经被给予了足够长的语音输入时间。• 足够灵活的处理方式:针对不同的用户案例,需要设计灵活的反馈时间。例如当用户被询问到一个 “Yes / No” 的问题时,在用户回答 “Yes / No” 之前,我们需要预留给用户一个短暂的停顿思考的时间。• 合理的停顿时间:在用户说完最后一个字后,设备是否预留了一段合理的停顿缓冲时间呢?这个缓冲时间处理起来很麻烦,并且在不同的语义环境下的长短不一。阶段三:“对话阶段”—— 对话场景的交互简单的指令例如 “打开闹钟” 并不需要通过一场对话来进行传达。但是对于更加复杂的指令来说,对话的是必须的。与传统的人与人之间的交互不同的是,人与人工智能之间的交互可能需要多重确认,多次澄清。对于更加复杂的指令,我们通常需要多次对话才能获得足够高的精准性。并且很多情况下,用户甚至都不知道如何持续地与机器进行交流。那么 VUI 就需要对用户给予的信息进行解码,并且允许用户进行补充说明。以下是一些常用规则:• 给予用户明确肯定:当人工智能听懂人声之后,它需要给予明确的肯定反馈。例如,与其给用户回复 “好的”,人工智能最好能够回复 “好的,我会把灯关掉”。• 允许用户纠正:当人工智能无法理解用户意图时,它应该给予用户纠正的机会。让用户选择通过其他方式来进行交互或者从头发起一场对话。• 能与用户共情:当人工智能无法满足用户需求时,它需要为自己无法完成任务进行道歉,同时给予用户其他交互选项。共情能力可以培养人工智能与用户之间更加亲密私人的关系。1. 高阶场景:人格化的交互给予设备人格化的特征能够让用户与设备之间更好的互动。这种 “人格化” 的交互可以通过很多方式来表现:灯光模式、跳动的图案、抽象的圆形图案、电脑合成的声音等等。▲ Olly 通过光环来赋予设备人格▲ 有些设备甚至会有一个表情显示屏来搭建人格系统通过给予设备人格化的表现,用户和机器之间能建立更亲密的关系。市面上非常成熟的案例有 Google Assistant、Amazon Alexa 和 Apple Siri。设计人格化的表现时有下列可参考的交互规则:• 赋予虚拟人格:通过赋予机器虚拟的人格,用户能够与机器进行共情 (Empathy)。这也能缓解当机器在无法执行指令时用户所产生的负向情绪。• 保持积极态度:保持积极的态度能够鼓励用户进行互动。• 建立信心和信任:信任能够鼓励用户进行互动,并且鼓励用户进行复杂对话。2. 高阶场景:保持流畅的动态交互语音交互应该是流畅且充满动态的。当我们与人交流时,我们通常会使用非常多的表情、声调和肢体语言来表达自我。而 VUI 中的交互的难点就在于如何把这种流畅复杂的交互用数字化的方式表达出来。我们需要尽量让整个语音交互流程充满正向且动态的反馈。当然,对于 “关灯” 这种直白的指令不需要使其充满动态反馈。不过任何复杂的交互,例如通过智能助手进行做饭指导则需要一个动态且有深度的对话流程。通过以下三个原则,我们可以创造一个高效且动态的声音交互:• 保持无缝衔接:对于不同的交互状态,设备应该能无缝隙的在之间切换。用户不需要感觉自己在等待。• 保持活波:活泼有很多种表达方式,例如我们可以使用活泼的颜色来传达积极的感情,同时增加设备的未来感。它能够增加设备的科技感以及信任感,鼓励用户进行交互。• 保持高效反馈:针对用户输入的指令,设备需要明确地让用户知道电脑正在处理哪一部分信息。▲ 图示的车载交互系统会把指令中识别出来的关键信息进行高亮处理,来明确告知用户电脑收到的指令。总结与其他资料语音交互界面(VUI)是非常复杂,它并没有一个完整的定义,且通常会涉及到多种维度上的交互。我们要记住,当我们的世界被数码设备填充的越来越满时,我们在跟设备交互上花的时间实际上比跟人交流花的时间要更多。语音交互是否能成为今后设备的主流交互方式呢?让我们拭目以待吧!• How to Design Voice User Interfaces | Interaction Design Foundation• What Is a Voice User Interface (VUI)? An Introduction | Amazon Developers• Voice Actions | Google Developers• SiriKit | Apple Developers• Designing a VUI by Frederik Goossens• A Guide to Voice User Interfaces by Fjord— The end —原文标题:Voice User Interfaces (VUI) — The Ultimate Designer’s Guide文章来源:Medium作原创者:Kang Sung Seok Bruno翻译作者:CD文章编辑:小小虫文章转自:微信设计中心(We-Design)该译文并非完整原文,内容已做部分调整。如在阅读过程中发现错误与疏漏之处,欢迎不吝指出。如需转载,请注明来自 三分设。三分设·知识库📚 精选全球设计知识📚与更多优秀用户体验设计师一起成长▽🙋 我们一起聊设计 🙋♂️高质量设计行业交流微信群▽PS:欢迎大家关注三分设,每天早上9点,准时充电。分享优质设计、创意灵感、新知新识,定期大咖老师直播分享,零距离连麦,答疑解惑。 添加小小虫微信号【 Lil_Bug 】,备注【 三分设 】加入!(只面向星标了公众号三分设的粉丝) ↓↓↓点开【阅读原文】,欢迎你的加入 浏览 41点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 NGINX 完全手册全栈前端精选0Java完全自学手册……JavaEdge0Stagehand界面交互调试可视化Stagehand是由CameronDaigle开发的,是一款对开发者和设计者很有帮助的jQuery插件,用静态标记来描述,可视化和调试复杂的界面交互。在线演示CCFE文本交互界面开发包CCFE 是一个简单的工具用来快速开发基于文本的交互式界面开发包,如下图所示:CCFE文本交互界面开发包CCFE是一个简单的工具用来快速开发基于文本的交互式界面开发包,如下图所示:CORS 完全手册之 CORS 详解前端瓶子君0CORS 完全手册之 CORS 详解前端Q0中国空间站操作界面曝光,“天地交互”亮了前端达人0中国空间站操作界面曝光,“天地交互”亮了程序IT圈0如何用python做一个简单的输入输出交互界面?一行数据0点赞 评论 收藏 分享 手机扫一扫分享分享 举报








 下载APP
下载APP