搞定,爬取公众号文章转换成PDF,自动邮件发送给自己!
↑↑↑关注后"星标"简说Python
人人都可以简单入门Python、爬虫、数据分析 简说Python发布 来源:简说Python 作者:老表
大家好,我是老表!
今天给大家分享如何每天定时爬取公众号文章链接和标题,并将内容转换成PDF,以附件的形式通过邮件发送给自己的小技巧(脚本)。
一、写在前面
这也是一个读者的需求,之前也有读者提到过,趁五一还在假期中(调休几天),给大家一并解决了,拿到需求,先简单分析下,然后百度下,基本解决方法就有了,哈哈哈哈!
最后呈现效果:
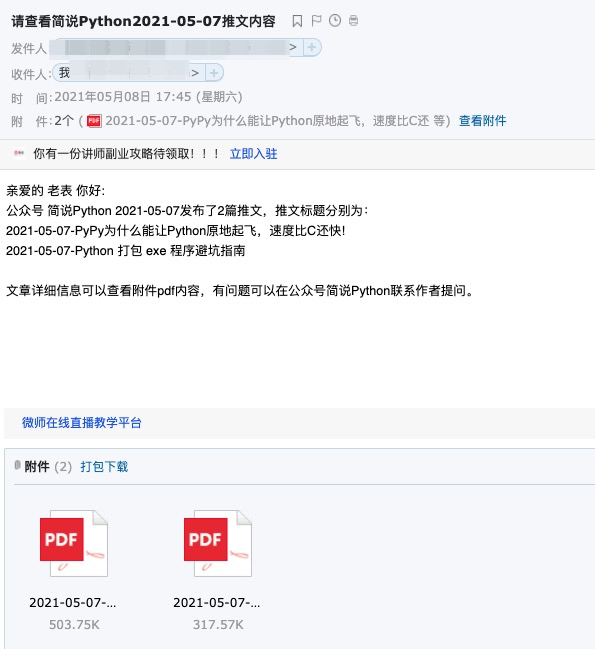
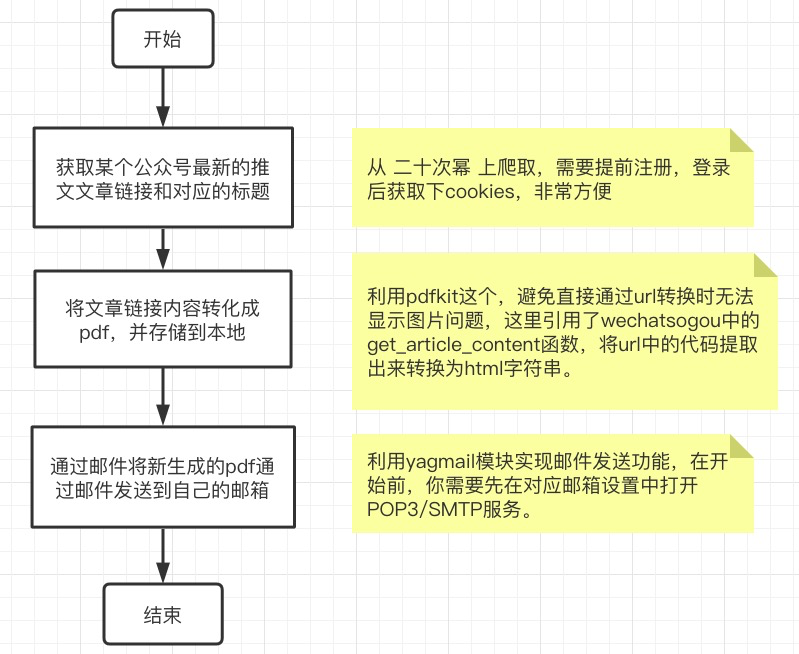
本需求主要分为三个部分:
爬取到公众号发布文章的链接和标题
这块,目前网络上有的一些方法有:从搜狗微信上爬取(有个现成的框架wechatsogou[1],不过好像已经好久没人维护了,链接获取功能测试失败)、从微信公众号后台爬取(需要大家注册微信公众号,麻烦),这里我用的方法是直接从第三方数据平台爬取(简单)。
我选择了志军大佬开发的二十次幂平台[2],这里也给大家安利下这个网站,除了一些公众号主可以用,读者朋友也可以在上面查看全网热文以及喜欢的公众号的历史文章等。
将公众号链接内容转换为pdf
这里利用pdfkit这个库,避免直接通过url转换成pdf时出现的无法显示图片问题,我们本次引用了wechatsogou[1]中的get_article_content函数,将url中的代码提取出来转换为html字符串,具体源码我简单看了下,有兴趣的也可以私聊我一起研究下(空闲的时候)。
通过邮件将pdf以附件形式发送
这一步蛮简单的,利用yagmail模块实现邮件发送功能,在开始前,我们需要先在对应邮箱的设置中打开POP3/SMTP服务,这样才能使用,不然会提示没有权限。
二、基本知识概要
爬虫,利用requests发送get请求
requests.get(url,headers=headers)json将json格式字符串转为Python字典格式
json.loads(json_string)基本反爬和反反爬策略 pdfkit将文本内容或者url链接内容转换成pdf wechatsogou搜狗微信爬虫框架 正则表达式re.sub函数和字符串处理函数replace yagmail.SMTP自动发送邮件 markdown语法写邮件内容(格式) 字符串传多个参数format函数 os模块基本操作,获取当前文件目录、创建文件夹等 datetime模块获取当前日期并前推一天 sys模块exit()结束当前程序
等。。。
三、开始动手动脑
3.1 本次项目需要导入的库
import requests # 发送get/post请求,获取网站内容
import wechatsogou # 微信公众号文章爬虫框架
import json # json数据处理模块
import datetime # 日期数据处理模块
import pdfkit # 可以将文本字符串/链接/文本文件转换成为pdf
import os # 系统文件管理
import re # 正则匹配模块
import yagmail # 邮件发送模块
import sys # 项目进程管理
3.2 爬取到公众号发布文章的链接和标题
'''
1、从二十次幂获取公众号最新的推文链接和标题
'''
def get_data(publish_date):
# 添加Cookie 记录登录状态
header = {
'Cookie': "获取方法见下文"
}
# 可以自定义设置获取文章的发布时间区间,日期越多,获取到的文章越多,本项目默认获取前一天的数据
start_at = publish_date
end_at = publish_date # 每次只爬去前一天的数据
url1 = 'https://www.ershicimi.com/api/stats/articles?'
# bid=EOdxnBO4 表示公众号 简说Python,每个公众号都有对应的bid,可以直接搜索查看
url2 = 'page=1&page_size=50&bid=EOdxnBO4&start_at={0}&end_at={1}&position=all'.format(start_at,end_at)
url3 = url1+url2
r = requests.get(url3, headers=header)
json_data = json.loads(r.text)
html_data = json_data['data']['articles']
# print(html_data)
return html_data
如何获取你自己登录二十次幂后的Cookie:首先我们需要知道为什么需要这个玩意。我们如果直接访问我上面提供的链接会发现print(html_data)出来的是登录页面的源码,这也是一个比较基本的反爬手段--需要登录后才可以访问网站内的数据。
针对这个反爬手段,最简单的反反爬虫手段就是手动登录后获取Cookie,这里会记录我们的登录信息,让我们再访问这类页面的时候让系统以为我们是已经登录过了的人,不过Cookie是有时效的,所以这种方法还蛮麻烦的。
还有种简单方法,直接通过代码传参,然后登录二十次幂,保持Session,然后再去访问我们想访问的数据页面就可以了,这个我简单的利用requests.session()试了下,没成功,有兴趣的同学可以试试,这样就不用每天运行代码前还需要手动到页面登录获取Cookie,欢迎试成功的同学在评论区或者微信和我分享下,我也会第一时间和大家分享。
手动获取Cookie方法:1)注册好二十次幂后(网站地址见文末参考链接注释),在登录页面填写账号相关信息,点击登录按钮登录。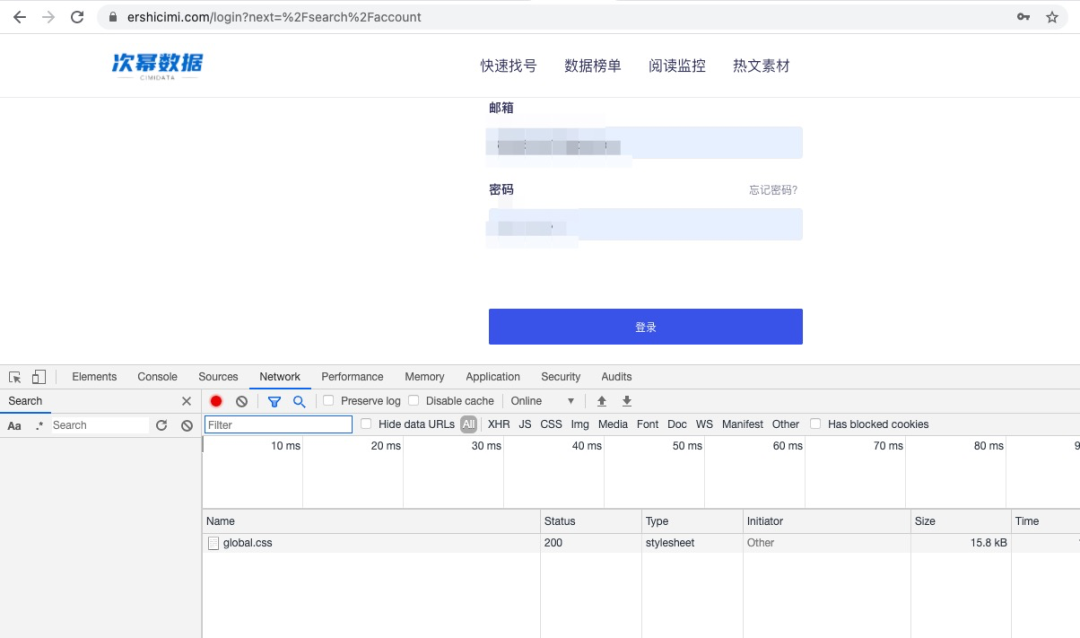 2)按住F12调出浏览器的开发者工具,选择Network,然后刷新页面,在Network会出现网页加载过程中的一些内容,找到下图中打红框的
2)按住F12调出浏览器的开发者工具,选择Network,然后刷新页面,在Network会出现网页加载过程中的一些内容,找到下图中打红框的login?next=%2Fsearch%2Faccount,点击一下,右侧就会出现请求相关信息,找到Request Headers中的Cookie后对应的一长串字符串就是我们需要的Cookie值。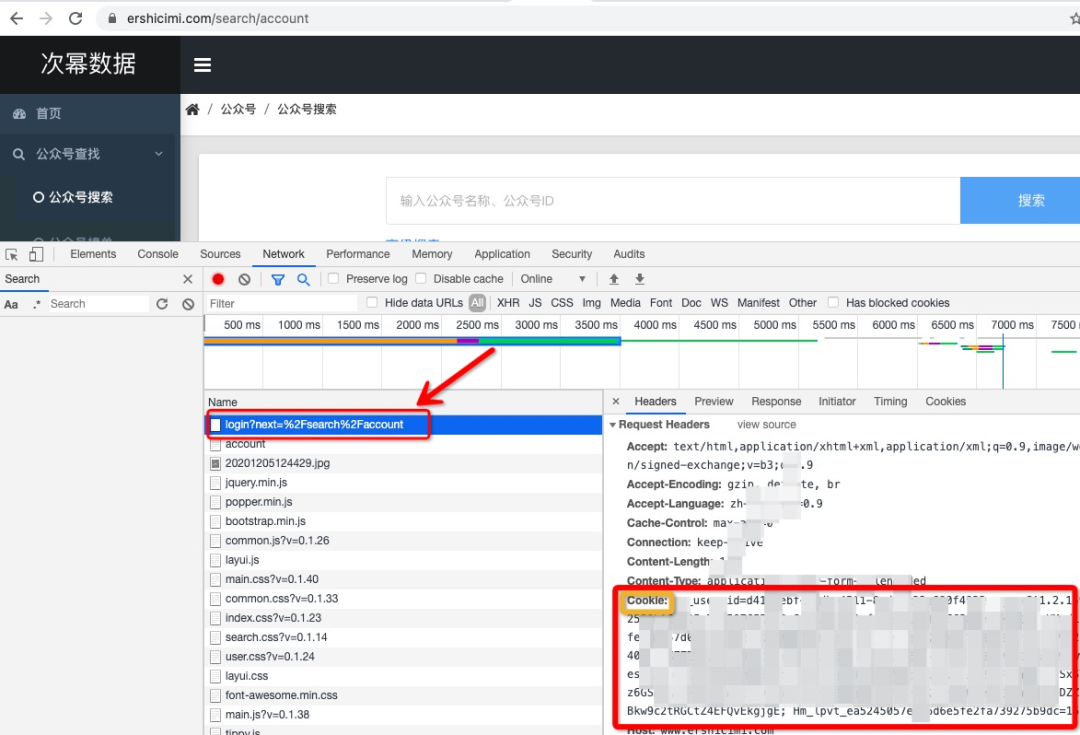
3.3 将公众号链接内容转换为pdf
'''
2、for循环遍历,将每篇文章转化为pdf
'''
# 转化url为pdf时,调用wechatsogou中的get_article_content函数,将url中的代码提取出来转换为html字符串
# 这里先初始化一个WechatSogouAPI对象
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
def url_to_pdf(url, title, targetPath, publish_date):
'''
使用pdfkit生成pdf文件
:param url: 文章url
:param title: 文章标题
:param targetPath: 存储pdf文件的路径
:param publish_date: 文章发布日期,作为pdf文件名开头(标识)
'''
try:
content_info = ws_api.get_article_content(url)
except:
return False
# 处理后的html
html = f'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{title}</title>
</head>
<body>
<h2 style="text-align: center;font-weight: 400;">{title}</h2>
{content_info['content_html']}
</body>
</html>
'''
# html字符串转换为pdf
filename = publish_date + '-' + title
# 部分文章标题含特殊字符,不能作为文件名
# 去除标题中的特殊字符 win / \ : * " < > | ?mac :
# 先用正则去除基本的特殊字符,python中反斜线很烦,最后用replace函数去除
filename = re.sub('[/:*"<>|?]','',filename).replace('\\','')
pdfkit.from_string(html, targetPath + os.path.sep + filename + '.pdf')
return filename # 返回存储路径,后面邮件发送附件需要
这里为了解决pdfkit直接转换url成为pdf会出现图片无法显示问题,参考了博客园xuzifan[3]提供的思路,利用wechatsogou中的get_article_content函数,将url中的代码提取出来转换为html字符串,然后将html字符串转换为pdf,完美解决。
这里需要注意的是:使用pdfkit需要提前访问wkhtmltopdf下载地址[4]下载并安装好wkhtmltopdf。如果是mac蛮简单的,直接下载安装即可,如果是windows需要下载安装后将安装路径添加到系统环境变量中或者修改转换pdf代码(如下)。
config=pdfkit.configuration(wkhtmltopdf='你的wkhtmltopdf安装路径'))
pdfkit.from_string(html, targetPath + os.path.sep + filename + '.pdf', configuration=config)
3.4 通过邮件将pdf以附件形式发送
'''
3、通过邮件将新生成的文件发送到自己的邮箱
'''
def send_email(user_name, email, gzh_data):
yag = yagmail.SMTP(user='你的邮箱',password='你的POP3/SMTP服务密钥',host='smtp.163.com')
contents = ['亲爱的 '+user_name+' 你好:<br>',
'公众号 {0} {1}发布了{2}篇推文,推文标题分别为:<br>'.format(gzh_data['gzh_name'], gzh_data['publish_date'], len(gzh_data['save_path'])),
'<br>'.join(gzh_data['save_path']),
'<br>文章详细信息可以查看附件pdf内容,有问题可以在公众号%s联系作者提问。<br>'%gzh_data['gzh_name'],
'<br><br><p align="right">公众号-%s</p>'%gzh_data['gzh_name']
]
# 在邮件内容后,添加上附件路径(蛮简单实现动态添加附件,直接拼接两个列表即可哈哈哈哈)
contents = contents + [targetPath + os.path.sep + i + '.pdf' for i in gzh_data['save_path']]
yag.send(email, '请查看'+gzh_name+publish_date+'推文内容', contents)
yagmail可以实现简单的自动发送邮件功能,我也拿来做过批量发送,蛮好用的,还支持markdown语法对邮件内容进行排版,蛮好的。
yag = yagmail.SMTP(user='你的邮箱',password='你的POP3/SMTP服务密钥',host='smtp.163.com')
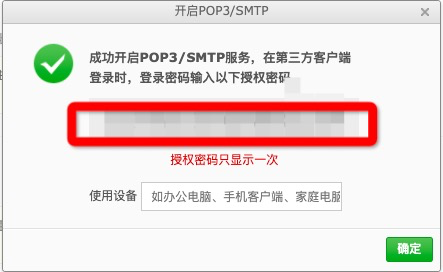
这里需要注意的是,代码里的user就是你的邮箱地址,比如1234567@163.com,password不是你的邮箱密码,而是你在邮箱页面开启POP3/SMTP服务后,系统给到的一个码,下面以163邮箱为例子给大家介绍如何获取这个password。
1)在网站登录对应的邮箱;
2)点击设置按钮,然后选择POP3/SMTP/IMAP,进入到相关设置页面。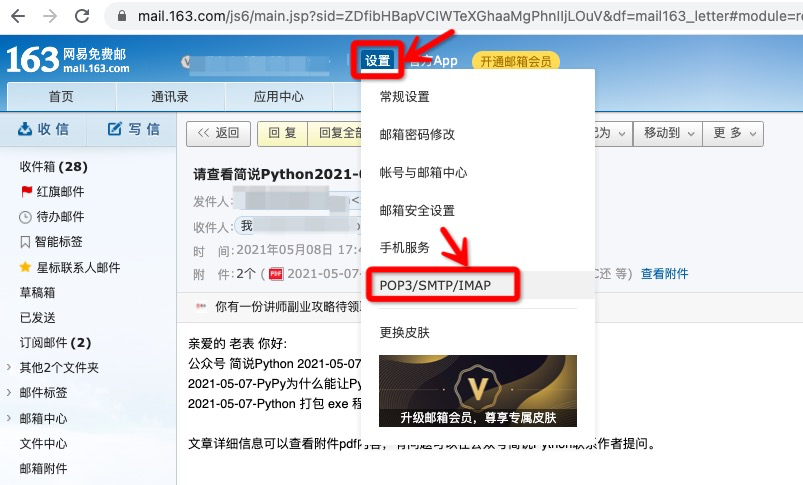
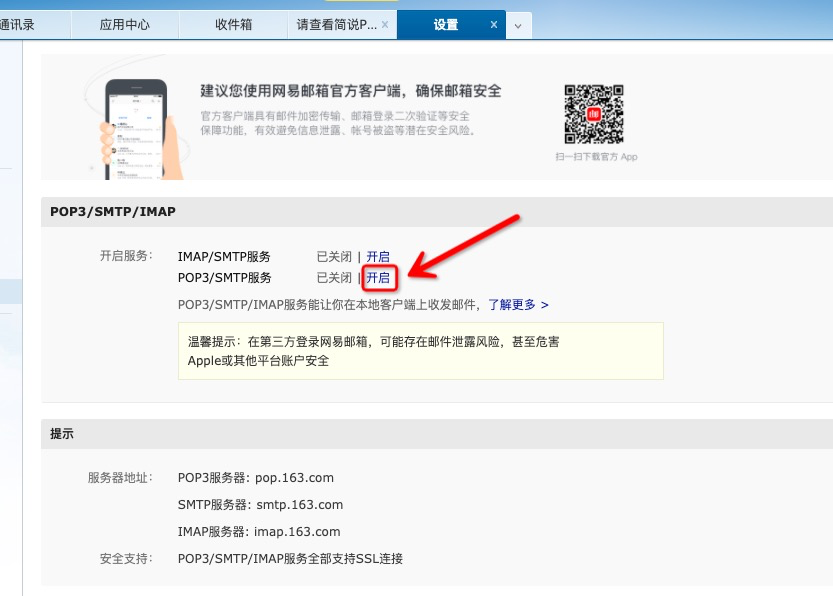
3)点击POP3/SMTP服务后的 开启 按钮,然后验证下即可,完成后会有弹框提示,授权密码就是我们要的password。
3.5 定时每天自动执行程序
今天回杭州,路上写了一天,颠颠倒倒,这个功能就开放留给大家啦,大家写出后可以留言区将自己的方案写上,第一个给出方案的读者朋友可以获得Python自动化测试相关图书一本。
全部代码:
import requests # 发送get/post请求,获取网站内容
import wechatsogou # 微信公众号文章爬虫框架
import json # json数据处理模块
import datetime # 日期数据处理模块
import pdfkit # 可以将文本字符串/链接/文本文件转换成为pdf
import os # 系统文件管理
import re # 正则匹配模块
import yagmail # 邮件发送模块
import sys # 项目进程管理
'''
1、从二十次幂获取公众号最新的推文链接和标题
'''
def get_data(publish_date):
# 添加Cookie 记录登录状态
header = {
'Cookie': "获取方法见上文介绍"
}
# 可以自定义设置获取文章的发布时间区间,日期越多,获取到的文章越多,本项目默认获取前一天的数据
start_at = publish_date
end_at = publish_date # 每次只爬去前一天的数据
url1 = 'https://www.ershicimi.com/api/stats/articles?'
# bid=EOdxnBO4 表示公众号 简说Python,每个公众号都有对应的bid,可以直接搜索查看
url2 = 'page=1&page_size=50&bid=EOdxnBO4&start_at={0}&end_at={1}&position=all'.format(start_at,end_at)
url3 = url1+url2
r = requests.get(url3, headers=header)
json_data = json.loads(r.text)
html_data = json_data['data']['articles']
# print(html_data)
return html_data
'''
2、for循环遍历,将每篇文章转化为pdf
'''
# 转化url为pdf时,调用wechatsogou中的get_article_content函数,将url中的代码提取出来转换为html字符串
# 这里先初始化一个WechatSogouAPI对象
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
def url_to_pdf(url, title, targetPath, publish_date):
'''
使用pdfkit生成pdf文件
:param url: 文章url
:param title: 文章标题
:param targetPath: 存储pdf文件的路径
:param publish_date: 文章发布日期,作为pdf文件名开头(标识)
'''
try:
content_info = ws_api.get_article_content(url)
except:
return False
# 处理后的html
html = f'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{title}</title>
</head>
<body>
<h2 style="text-align: center;font-weight: 400;">{title}</h2>
{content_info['content_html']}
</body>
</html>
'''
# html字符串转换为pdf
filename = publish_date + '-' + title
# 部分文章标题含特殊字符,不能作为文件名
# 去除标题中的特殊字符 win / \ : * " < > | ?mac :
# 先用正则去除基本的特殊字符,python中反斜线很烦,最后用replace函数去除
filename = re.sub('[/:*"<>|?]','',filename).replace('\\','')
pdfkit.from_string(html, targetPath + os.path.sep + filename + '.pdf')
return filename # 返回存储路径,后面邮件发送附件需要
'''
3、通过邮件将新生成的文件发送到自己的邮箱
'''
def send_email(user_name, email, gzh_data):
yag = yagmail.SMTP(user='你的发邮件的邮箱,可以和收件的是一个',password='你的POP3/SMTP服务密钥',host='smtp.163.com')
contents = ['亲爱的 '+user_name+' 你好:<br>',
'公众号 {0} {1}发布了{2}篇推文,推文标题分别为:<br>'.format(gzh_data['gzh_name'], gzh_data['publish_date'], len(gzh_data['save_path'])),
'<br>'.join(gzh_data['save_path']),
'<br>文章详细信息可以查看附件pdf内容,有问题可以在公众号%s联系作者提问。<br>'%gzh_data['gzh_name'],
'<br><br><p align="right">公众号-%s</p>'%gzh_data['gzh_name']
]
# 在邮件内容后,添加上附件路径(蛮简单实现动态添加附件,直接拼接两个列表即可哈哈哈哈)
contents = contents + [targetPath + os.path.sep + i + '.pdf' for i in gzh_data['save_path']]
yag.send(email, '请查看'+gzh_name+publish_date+'推文内容', contents)
# 程序开始
# 0、为爬取内容创建一个单独的存放目录
gzh_name = '简说Python' # 爬取公众号名称
targetPath = os.getcwd() + os.path.sep + gzh_name
# 如果不存在目标文件夹就进行创建
if not os.path.exists(targetPath):
os.makedirs(targetPath)
print('------pdf存储目录创建成功!')
# 1、从二十次幂获取微信公众号最新文章数据
year = str(datetime.datetime.now().year)
month = str(datetime.datetime.now().month)
day = str(datetime.datetime.now().day-1)
publish_date = datetime.datetime.strptime(year+month+day,'%Y%m%d').strftime('%Y-%m-%d') # 文章发布日期
html_data = get_data(publish_date)
if html_data:
print('------成功获取到公众号{0}{1}推文链接!'.format(gzh_name, publish_date))
else:
print('------公众号{0}{1}没有发布推文,请前往微信确认'.format(gzh_name, publish_date))
sys.exit() # 结束进程
# 2、for循环遍历,将每篇文章转化为pdf
save_path = []
for article in html_data:
url = article['content_url']
title = article['title']
# 将文章链接内容转化为pdf,并记录存储路径,用于后面邮件发送附件
save_path.append(url_to_pdf(url, title, targetPath, publish_date))
print('------pdf转换保存成功!')
# 3、通过邮件将新生成的文件发送到自己的邮箱
user_name = '收件人名称' # 可以写自己的名字
email = '收件邮箱地址'
gzh_data = {
'gzh_name':gzh_name,
'publish_date':publish_date,
'save_path':save_path
}
send_email(user_name, email, gzh_data)
print('------邮件发送成功啦!')
随便说说
我的五一也结束啦,祝大家明天周末愉快。
最重要的是明天是母亲节,在这里祝我的妈妈节日快乐,身体健康,其他的话单独和妈妈说(嘿嘿),也祝天下所有母亲节日快乐。
另外大家如果有什么类似需求,或者想要本文所有相代码的ipynb文件,可以扫下方二维码添加我的微信,查看朋友圈获取。
欢迎大家进行学习交流。
参考链接
wechatsogou:https://github.com/Chyroc/WechatSogou 二十次幂平台:https://www.ershicimi.com/ 博客园xuzifan:https://www.cnblogs.com/xuzifan/p/11121878.html wkhtmltopdf下载地址:https://wkhtmltopdf.org/downloads.html
扫码即可加我微信
观看朋友圈,获取最新学习资源
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
“点赞”传统美德不能丢