
Android 逆向 | 不是加密的 Base64
不是加密的 Base64
Base64 就是一种基于 64 个可打印字符来表示二进制数据
Base64,就是说选出64个字符----小写字母a-z、大写字母A-Z、数字0-9、符号"+"、"/"(再加上作为垫字的"=",实际上是65个字符)作为一个基本字符集。然后,其他所有符号都转换成这个字符集中的字符
-- 选自《阮一峰老师的博客》
Base 系列还有 16/32/62/64/85/36/58/91/92 等,分别表示用不同个数的可打印字符表示二进制数据
那么为什么会用 Base 系列算法?
有的字符在一些环境中是不能显示或使用的,比如 &, = 等字符在 URL 被保留为特殊作用的字符;
比如描述一张图片,而图片中的二进制码如果转成对应的字符的话,会有很多不可见字符和控制符(如换行、回车之类),这时就需要对进行编码。
Base 系列的就是用来将字节编码为 ASCII 中的可见字符的。
这个在之前也有一篇文章用来描述关于请求中传递验证码使用的就是base64
他的本质其实就是把原本不好显示的字符切片分组后用好显示的ascii码来展示
今天就讲讲base64对字符做了啥?
第一种
待转换的字符串长度正好是 3 的整数倍
三个字符Man,转换示意图如下
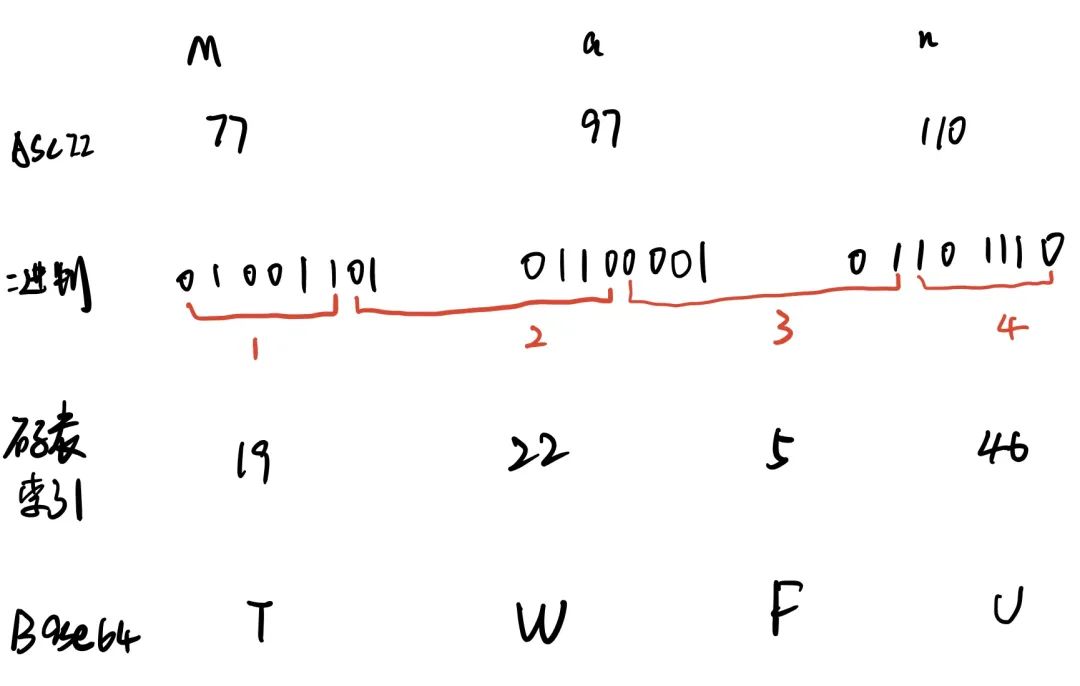
1、把待转换的字符串,分割成 3 个一组,并且转换为共 24 个的二进制位 2、将转换好的二进制位再按照每 6 个一组整成 4 组 3、将每组的数据补成 8位,前面加上两个 0 4、将补成的 8 位的二进制数据转化为 10 进制数 5、将转化为的 10 进制数对照 Base64 的码表注意转化为码表中的字符,得出 Base64的编码
如果一个编码后的 base64 编码是没有等号填充的,那么说明原字符的长度是 3 的整数倍
第二种
待转换的字符串长度正好比 3 的整数倍多 1 个字节或 2 个字节
像单个字符A,转换示意图如下
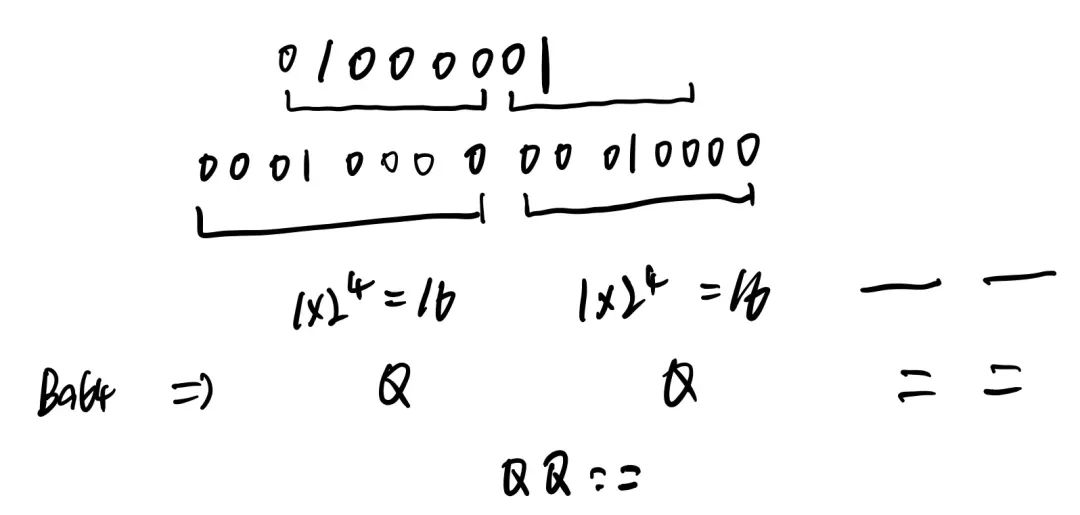
一个字节:一个字节共 8 个二进制位,依旧按照规则进行分组。此时共 8 个二进制位,每 6 个一组,则第二组缺少 4 位后面用 0 补齐得,得到两个 Base64 编码,而后面两组没有对应数据,都用 “ = ” 补上。
像两个字符AB,转换示意图如下
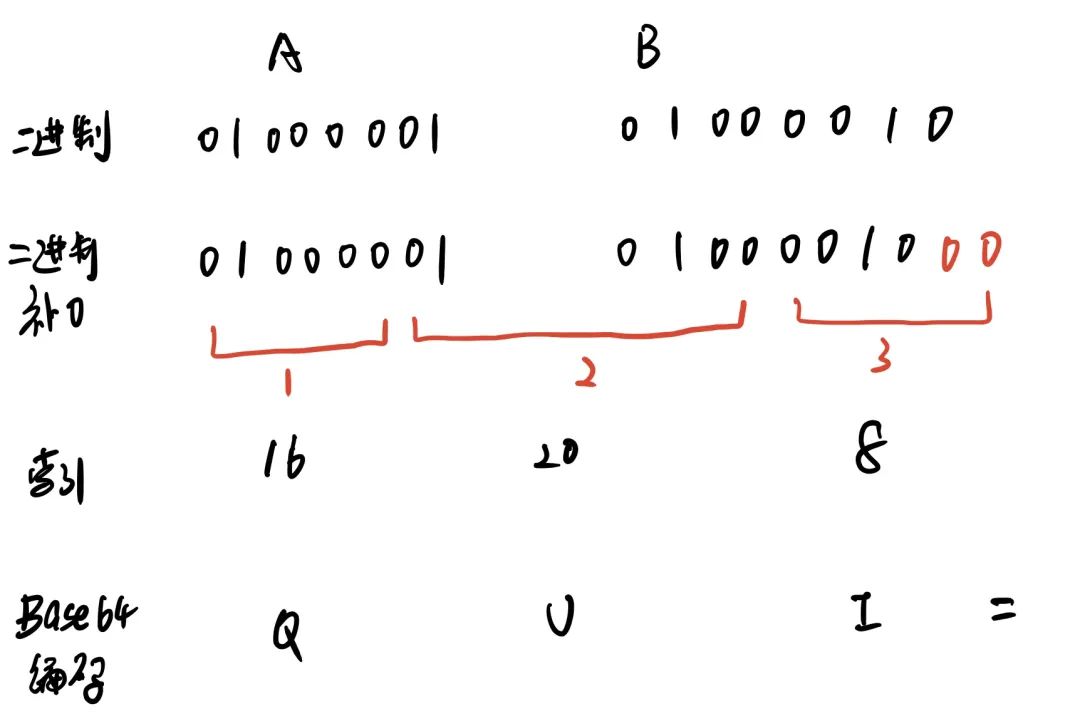
两个字节:两个字节共 16 个二进制位,依旧按照规则进行分组。此时总共 16 个二制位,每 6 个一组,则第三组缺少 2 位,用 0 补齐,得到三个 Base64 编码,第四组完全没有数据则用 “ = ” 补上。
按照上面的算法,我们可以得到以下规律
如果后面填充一个=那么原文长度是 3n + 2 的长度
如果后面填充的是两个=,那么原文长度是 3n + 1 长度
逆向反推快速识别
知道原理之后,快速用代码实现以下:
Python 无中文字符版:
import base64
str_encrypt="aaaa"
# 不要使用 base64.encodebytes(rq_time.encode()).decode()
base64_encrypt=base64.b64encode(str_encrypt.encode('utf-8')).decode()
print(base64_encrypt)
Python 含中文字符版:
"""
base64实现
"""
import base64
import string
# base 字符集
base64_charset = string.ascii_uppercase + string.ascii_lowercase + string.digits + '+/'
def encode(origin_bytes):
"""
将bytes类型编码为base64
:param origin_bytes:需要编码的bytes
:return:base64字符串
"""
# 将每一位bytes转换为二进制字符串
base64_bytes = ['{:0>8}'.format(str(bin(b)).replace('0b', '')) for b in origin_bytes]
resp = ''
nums = len(base64_bytes) // 3
remain = len(base64_bytes) % 3
integral_part = base64_bytes[0:3 * nums]
while integral_part:
# 取三个字节,以每6比特,转换为4个整数
tmp_unit = ''.join(integral_part[0:3])
tmp_unit = [int(tmp_unit[x: x + 6], 2) for x in [0, 6, 12, 18]]
# 取对应base64字符
resp += ''.join([base64_charset[i] for i in tmp_unit])
integral_part = integral_part[3:]
if remain:
# 补齐三个字节,每个字节补充 0000 0000
remain_part = ''.join(base64_bytes[3 * nums:]) + (3 - remain) * '0' * 8
# 取三个字节,以每6比特,转换为4个整数
# 剩余1字节可构造2个base64字符,补充==;剩余2字节可构造3个base64字符,补充=
tmp_unit = [int(remain_part[x: x + 6], 2) for x in [0, 6, 12, 18]][:remain + 1]
resp += ''.join([base64_charset[i] for i in tmp_unit]) + (3 - remain) * '='
return resp
def decode(base64_str):
"""
解码base64字符串
:param base64_str:base64字符串
:return:解码后的bytearray;若入参不是合法base64字符串,返回空bytearray
"""
if not valid_base64_str(base64_str):
return bytearray()
# 对每一个base64字符取下标索引,并转换为6为二进制字符串
base64_bytes = ['{:0>6}'.format(str(bin(base64_charset.index(s))).replace('0b', '')) for s in base64_str if
s != '=']
resp = bytearray()
nums = len(base64_bytes) // 4
remain = len(base64_bytes) % 4
integral_part = base64_bytes[0:4 * nums]
while integral_part:
# 取4个6位base64字符,作为3个字节
tmp_unit = ''.join(integral_part[0:4])
tmp_unit = [int(tmp_unit[x: x + 8], 2) for x in [0, 8, 16]]
for i in tmp_unit:
resp.append(i)
integral_part = integral_part[4:]
if remain:
remain_part = ''.join(base64_bytes[nums * 4:])
tmp_unit = [int(remain_part[i * 8:(i + 1) * 8], 2) for i in range(remain - 1)]
for i in tmp_unit:
resp.append(i)
return resp
def valid_base64_str(b_str):
"""
验证是否为合法base64字符串
:param b_str: 待验证的base64字符串
:return:是否合法
"""
if len(b_str) % 4:
return False
for m in b_str:
if m not in base64_charset:
return False
return True
if __name__ == '__main__':
s = '我的目标是星辰大海. One piece, all Blue'.encode()
local_base64 = encode(s)
print('使用本地base64加密:', local_base64)
b_base64 = base64.b64encode(s)
print('使用base64加密:', b_base64.decode())
print('使用本地base64解密:', decode(local_base64).decode())
print('使用base64解密:', base64.b64decode(b_base64).decode())
Java 版快速实现:
import sun.misc.BASE64Encoder;
public class Base64Utils {
public static void main(String[] args) {
String man = "Man";
String a = "A";
String bc = "BC";
BASE64Encoder encoder = new BASE64Encoder();
System.out.println("Man base64结果为:" + encoder.encode(man.getBytes()));
System.out.println("BC base64结果为:" + encoder.encode(bc.getBytes()));
System.out.println("A base64结果为:" + encoder.encode(a.getBytes()));
}
}
这里为什么强调有中文版和无中文版的 base64 算法呢?
因为按照上面的的示意图可以知道,我们第一步是将代码转化为ascii码之后再转化为二进制的,但是ascii码中并没有包含中文
所以其他的字符集就需要统一转化为二进制之后再分割,中文就是要同一编码方式,例如同一使用utf-8字符集转化为二进制之后分割
知道算法原理和规律有什么用?
知道算法原理和规律有助于我们快速识别这个编码方式是不是简单常用的算法,一定程度上减轻 app 逆向的工作量
我们主要需要快速识别下面几个要素,就能帮助我们在判断 APP 加密/编码方式的时候减少工作量:
输出字符串的长度 输入输出字符串的长度 逆向分析时明显的 编码表以及查表的过程
Love&Share
[ 完 ]
对了,看完记得一键四连,这个对我真的很重要。
