
Node.js 进程、线程调试和诊断的设计和实现
大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
前言:本文介绍 Node.js 中,关于进程、线程调试和诊断的相关内容。进程和线程的方案类似,但是也有一些不一样的地方,本文将会分开介绍,另外本文介绍的是对业务代码无侵入的方案,通过命令行开启 Inspector 端口或者在代码里通过 Inspector 模块打开端口在很多场景下并不适用,我们需要的是一种动态控制的能力。
1. 背景
随着前端的快速发展,Node.js 在业务中的使用场景也越来越多,如何保证 Node.js 服务的稳定也逐渐成为一个非常重要事情,传统的服务器架构大多数基于多进程、多线程的,任务的执行是隔离的,一个任务出现问题通常不会影响其他任务,比如在一个请求中执行一个死循环,服务器还能处理其他的请求。
但是 Node.js 不一样,从整体来看,Node.js 是单线程的,单个任务出现问题有可能会影响其他任务,比如在一个请求中执行了死循环,那么整个服务就没法继续工作了。所以在 Node.js 中,我们更加需要方便的调试和诊断工具,以便遇到问题时可以快速找到问题,解决问题,另外,工具不仅可以帮我们排查问题,还可以找出我们服务中的性能瓶颈,方便我们进行性能优化。
2. 目标
我们基于 Node.js 本身提供的调试和诊断能力,提供一个调试和诊断平台,使用方只需要引入 SDK,然后通过调试和诊断平台就可以对服务的进程和线程进行调试和诊断。
3. 实现
目前支持了多进程和多线程的调试和诊断,下面按照进程和线程两个方面介绍一下原理和具体实现。
3.1. 单进程
3.1.1 调试和诊断基础
在 Node.js 中,可以通过以下方式收集进程的数据。
const inspector = require('inspector');
const session = new inspector.Session();
session.connect();
// 发送命令
session.post('Profiler.enable', () => {});
使用方式很简单,通过新建一个和 V8 Inspector 通信的 Session 就可以对进程进行数据的收集,比如抓取进程的堆快照和 Profile 数据。有了这个基础后,我们就可以封装这个能力。
const http = require('http');
const inspector = require('inspector');
const fs = require('fs');
// 打开一个和 V8 Inspector 的会话
const session = new inspector.Session();
session.connect();
function getCpuprofile(req, res) {
// 向V8 Inspector 提交命令,开启 CPU Profile 并收集数据
session.post('Profiler.enable', () = >{
session.post('Profiler.start', () = >{
// 收集一段时间后提交停止收集命令
setTimeout(() = >{
session.post('Profiler.stop', (err, { profile }) = >{
// 把数据写入文件
if (!err && profile) {
fs.writeFileSync('./profile.cpuprofile', JSON.stringify(profile));
}
// 回复客户端
res.end('ok');
});
},
3000);
})
});
}
http.createServer((req, res) = >{
if (req.url == '/debug/getCpuprofile') {
getCpuprofile(req, res);
} else {
res.end('ok');
}
}).listen(80);
但是这种方式不能调试进程,调试进程需要使用另外的 API,可以通过以下方式启动调试进程的服务。
const inspector = require('inspector');
inspector.open();
console.log(inspector.url());
这时候 Node.js 进程中就会启动一个 WebSocket Server,我们可以通过 Chrome Dev Tools 连上这个 Server 进行调试,我们看看如何封装。
const inspector = require('inspector');
const http = require('http');
let isOpend = false;
function getHTML() {
return `<html>
<meta charset="utf-8" />
<body>
复制到新 Tab 打开该 URL 开始调试 devtools://devtools/bundled/js_app.html?experiments=true&v8only=true&ws=${inspector.url().replace("ws://", '')}
</body>
</html>`;
}
http.createServer((req, res) = >{
if (req.url == '/debug/open') {
// 还没开启则开启
if (!isOpend) {
isOpend = true;
// 打开调试器
inspector.open();
}
// 返回给前端的内容
const html = getHTML();
res.end(html);
} else if (req.url == '/debug/close') {
// 如果开启了则关闭
if (isOpend) {
inspector.close();
isOpend = false;
}
res.end('ok');
} else {
res.end('ok');
}
}).listen(80);
我们以 API 的方式对外提供动态控制进程调试和诊断的能力,具体的实现可以根据场景去修改,比如给前端返回一个不带 Inspector 端口的 URL,前端再通过 URL 访问服务,服务代理请求 Websocket 请求到 Inspector 对应的 WebSocket 服务。比如把收集的数据上传到云上,给前端返回一个 URL。
3.1.2 具体实现
我们通过 API 的方式提供功能,设计上采用插件化的思想,主框架负责接收请求和路由处理,具体的逻辑交给具体的插件去做,结构如下所示。
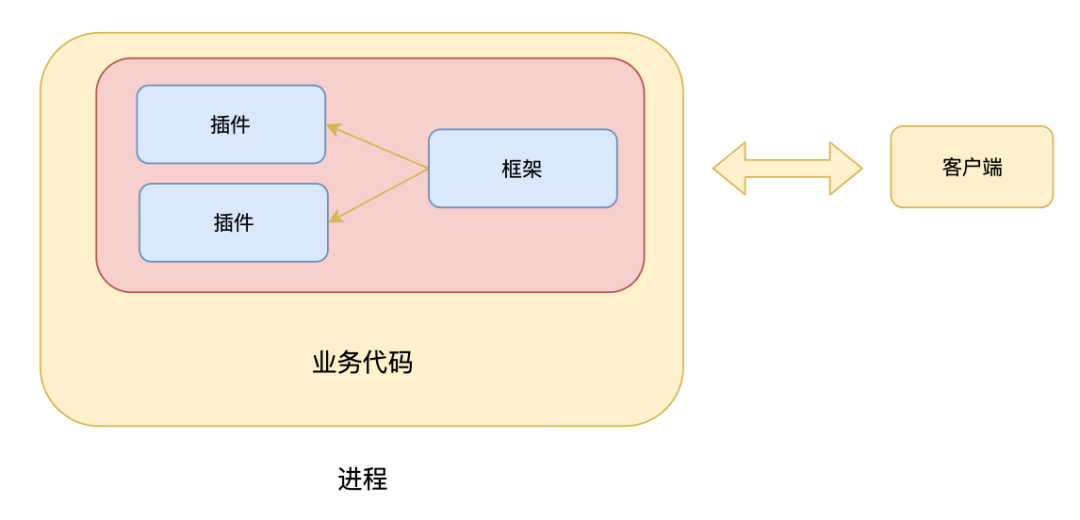
数据收集的实现和上面的例子中类似,收到请求路由到对应的插件,插件通过 Session 和 V8 Inspector 通信完成数据的收集。调试的实现就稍微复杂些,主要的原因是我们不能把端口返回给前端,让前端直接连接该端口。这个不是因为安全问题,因为调试的 URL 是一个带有一个复杂随机值的字符串,就算端口暴露了,攻击者也很难猜对随机值,相比来说,通过提供 API 的方式更加不安全,因为只要知道服务的地址,就可以通过 API 去调试进程了,所以严格来说,这里还需要加一些校验机制。言归正传,不暴露端口的原因是通常前端无法直接连接到这个端口,原因可能有很多,比如我们的服务运行在容器中,容器只对外暴露有限的端口,我们不能期待在进程中随便起一个端口,在前端就可以直接访问,但是有一个可以肯定的是,服务至少会对外提供一个端口,那就意味着我们可以通过某个对外的端口把非业务相关的请求传递到进程内,基于上面的情况,当我们打开 Inspector 端口时,我们只会告诉前端打开成功或者失败,当前端通过调试 API 访问服务器时,我们会判断端口是否已经打开,是的话代理请求到 WebSocket Server。结构设计如下:
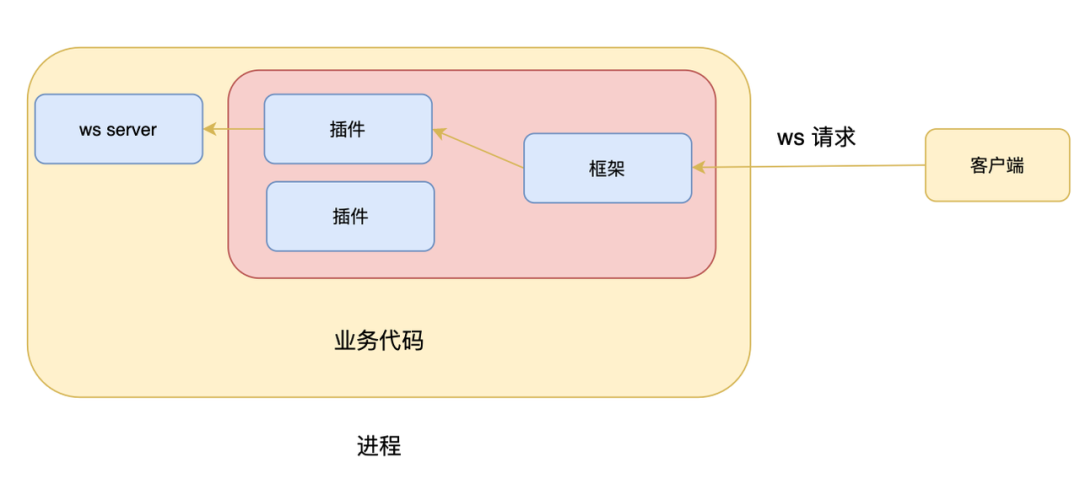
大致实现如下:
const client = connect(WebSocket Server地址);
client.on('connect', () = >{
// 转发协议升级的 HTTP 请求给 WebSocket Server
client.write(`GET ${req.path} HTTP/1.1\r\n` + buildHeaders(req.headers) + '\r\n');
// 透传
socket.pipe(client);
client.pipe(socket);
});
收到客户的的请求后,首先连接到 WebSocket Server,然后透传客户端的请求,接着通过管道让 WebSocket Server 和客户端通信就行。
3.2 多进程
为了利用多核,Node.js 服务通常会启动多个进程,所以支持多进程的调试和诊断也是非常必要的。但是单进程的调试诊断方案无法通过横行拓展来支持多进程的场景。
3.2.1 单进程方案的限制
前面提到的方式看起来工作得不错,但是如果服务是单实例上多进程部署,就会存在一些限制。我们来看看这时候的结构:

假如我们只有一个对外端口:
基于 Node.js Cluster 模块的多进程管理机制,多个进程监听同一个端口是没问题的,但是请求的分发上会存在问题,比如请求 1 被分发到进程 1,打开了进程 1 的 Inspector 端口,接着请求 2 想关闭这个端口,但是请求被分发到了进程 2,但是进程 2 并没有打开 Inspector 端口。
基于 child_process 的 fork 创建多进程,则在重复监听端口时会报错,导致只有一个进程可以使用提供的功能。
3.2.1 Agent 进程
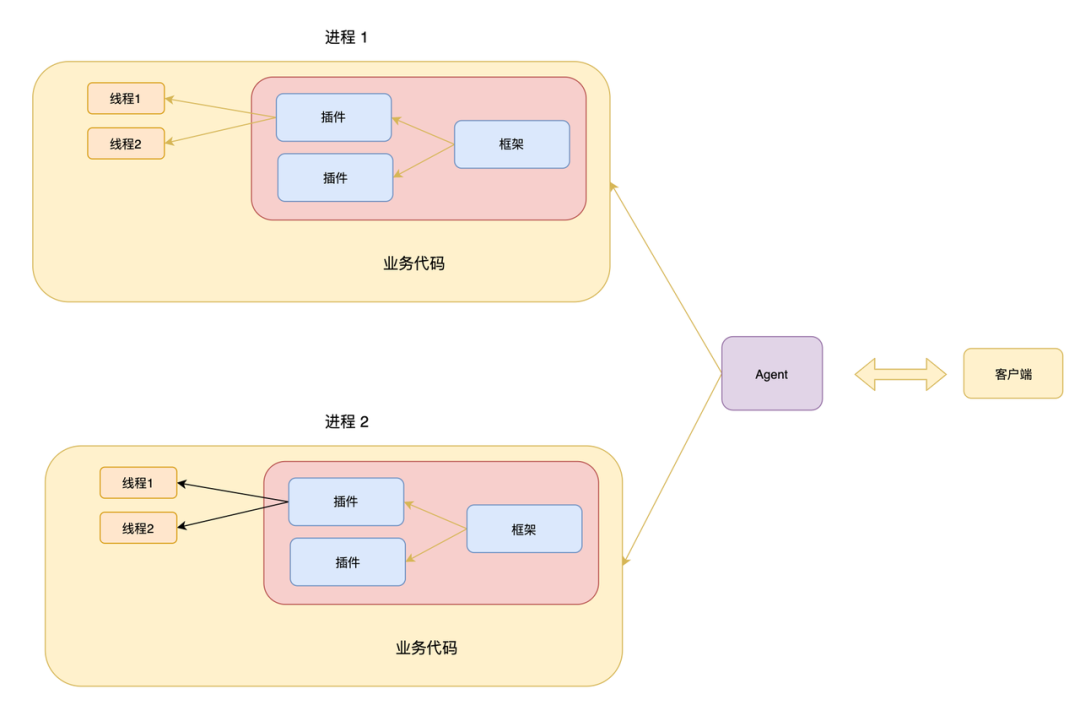
一种解决方案是每个进程监听不同的端口,这样又回到了前面讨论到问题,但是这种方案也不是完全不可行,只需要基于这个方案做一下改进,那就是引入 Agent 进程,这时候结构如下:

Agent 进程负责收集和管理工作进程的信息(如 pid、监听地址),并接管所有调试和诊断相关的请求,收到请求后根据参数进行请求分发。具体流程如下:
Agent 启动一个服务器。
子进程启动后,把自己的 pid 和监听的随机服务地址注册到 Agent。
客户端通过 Agent 获取进程的 pid 列表,并选择需要操作的进程。
Agent 收到客户的请求,根据入参中的 pid 把请求发送给对应的子进程。
子进程处理完毕后返回给 Agent,Agent返回给客户端。
3.2.2 如何创建 Agent 进程
确定了 Agent 进程的方案后,如何创建 Agent 进程成为一个需要解决的问题。在 Node.js 里启动多个服务器的方式是通过 Cluster 或者直接通过 child_process 模块 fork 出多个子进程,Node.js 框架/工具通常都会封装这些逻辑,但是框架不一定会提供创建 Agent 进程的方式。为了通用,我们不能假设运行在某种框架/工具中,所以我们只能寻找一种独立于框架/工具的方案。我们在每个 Worker 进程里都创建一个 Agent 进程,然后多个 Agent 进程竞争监听一个端口,监听成功的进程继续运行,监听失败的退出,最终剩下一个 Agent 进程。
3.3 多线程
线程和进程的调试、诊断类似,下面主要讲一下不一样的地方。
3.3.1 调试和诊断基础
可以通过以下方式收集线程的数据。
const { Worker, workerData } = require('worker_threads');
const { Session } = require('inspector');
const session = new Session();
session.connect();
let id = 1;
// 给子线程发送消息
function post(sessionId, method, params, callback) {
session.post('NodeWorker.sendMessageToWorker', {
sessionId,
message: JSON.stringify({
id: id++,
method,
params
})
},
callback);
}
// 子线程连接上 V8 Inspector 后触发
session.on('NodeWorker.attachedToWorker', (data) = >{
post(data.params.sessionId, 'Profiler.enable');
post(data.params.sessionId, 'Profiler.start');
// 收集一段时间后提交停止收集命令
setTimeout(() = >{
post(data.params.sessionId, 'Profiler.stop');
},
10000)
});
// 收到子线程消息时触发
session.on('NodeWorker.receivedMessageFromWorker', ({ params: { message } }) = >{});
const worker = new Worker('./httpServer.js', { workerData: { port: 80 } });
worker.on('online', () = >{
session.post("NodeWorker.enable", { waitForDebuggerOnStart: false }, (err) = >{
console.log(err, "NodeWorker.enable");
});
});
setInterval(() = >{},100000);
类似通过 Agent 进程管理多个 Worker 进程一样,因为一个进程中可能存在多个线程,所以需要对多个线程进行管理。首先通过 NodeWorker.enable 命令开启子线程的 Inspector 能力,然后通过 NodeWorker.attachedToWorker 事件拿到线程对应的 sessionId,后续通过 sessionId 和线程进行通信。接着看一下调试的实现:
const { Worker, workerData } = require('worker_threads');
const { Session } = require('inspector');
const session = new Session();
session.connect();
let workerSessionId;
let id = 1;
function post(method, params) {
session.post('NodeWorker.sendMessageToWorker', {
sessionId: workerSessionId,
message: JSON.stringify({
id: id++,
method,
params
})
});
}
session.on('NodeWorker.receivedMessageFromWorker', ({ params: { message } }) = >{
const data = JSON.parse(message);
console.log(data);
});
session.on('NodeWorker.attachedToWorker', (data) = >{
workerSessionId = data.params.sessionId;
post("Runtime.evaluate", {
includeCommandLineAPI: true,
expression: `const inspector = process.binding('inspector');
inspector.open();
inspector.url();
`
});
});
const worker = new Worker('./httpServer.js', { workerData: { port: 80 } });
worker.on('online', () = >{
session.post("NodeWorker.enable", { waitForDebuggerOnStart: false }, (err) = >{
err && console.log("NodeWorker.enable", err);
});
});
setInterval(() = >{}, 100000);
线程的调试主要利用 Runtime.evaluate 在子线程里动态执行代码来打开子线程的 Inspector 端口。了解了基础使用后,我们看一下具体实现。
3.3.2 具体实现
首先我们提供一个 API 获取线程列表,这样我们后续就可以选择操作某个线程,后续的每个请求都需要带上 线程对应的 id,这里以获取 Profile 为例讲一下处理过程。
const {
sessionId,
interval = INTERVAL,
duration = DURATION
} = req.query;
// 向V8 Inspector 提交命令,开启 CPU Profile 并收集数据
this.post(sessionId, { method: 'Profiler.enable' }, (err) = >{
this.post(sessionId, {
method: 'Profiler.setSamplingInterval',
params: { interval }
});
this.post(sessionId, { method: 'Profiler.start' }, (err) = >{
// 收集一段时间后提交停止收集命令
setTimeout(() = >{
this.post(sessionId, { method: 'Profiler.stop' }, (err, { profile }) => {});
}, duration);
});
})
我们看到每一个操作都需要 sessionId。通过 sessionId,我们把请求转发到对应的线程。但是和进程不一样,进程发送一个请求时传入一个回调,请求成功后就会执行对应的回调,我们不需要保存请求上下文,Node.js 会帮我们处理,但是线程不一样,存在一个嵌套的过程,因为 Inspector 命令的执行模式是一个请求命令对应一个回调,但是和线程通信时,是首选通过 NodeWorker.sendMessageToWorker 命令和主线程通信,主线程会解析出 NodeWorker.sendMessageToWorker 的参数,参数里包含了给子线程发送的命令,接着主线程通过 sessionId 把请求转发到子线程,然后这时候 NodeWorker.sendMessageToWorker 就会返回并执行对应的回调,这时候意味着 NodeWorker.sendMessageToWorker 执行结束了,但是我们请求子线程的命令还没有完成,也就是说我们需要自己维护请求子线程对应的回调。我们看看 post 的具体实现:
post(sessionId, message, callback ? ) {
// 请求对应的 id
const requestId = ++this.id;
this.session.post('NodeWorker.sendMessageToWorker', {
sessionId,
message: JSON.stringify({ ...message, id: requestId })
},
(err) = >{
/*
回调说明 NodeWorker.sendMessageToWorker 请求完成
err非空说明请求失败,直接执行回调
err为空说明请求成功,记录 post 调用方的请求回调,通过 id 关联
*/
if (typeof callback === 'function') {
// 发送失败则直接执行回调,成功则记录回调
if (err) {
callback(err);
} else {
this.sessionMap[sessionId]['requests'][requestId] = callback;
}
}
});
}
我们看到在 NodeWorker.sendMessageToWorker 回调里保存了请求子线程的回调。接下来我们看一下线程执行完命令后的回调。
this.session.on('NodeWorker.receivedMessageFromWorker', ({
params: {
sessionId,
message
}
}) = >{
const ctx = this.sessionMap[sessionId];
try {
const data = JSON.parse(message);
/**
* data 的内容格式如下:
* {
* method: string,
* params: Object
* }
* 或者
* {
* id: number,
* result: { result: Object }
* }
*/
const {
id,
method,
result
} = data;
// 有 id 说明是请求对应的响应,没有 id 说明是 Inspector 异步触发的事件
if (id) {
if (typeof ctx.requests[id] === 'function') {
const fn = ctx.requests[id];
delete ctx.requests[id];
fn(null, result);
}
} else {
ctx.emit(method, data);
}
} catch(e) {
console.warn(e);
}
});
通过 NodeWorker.receivedMessageFromWorker 事件可以接收到线程返回的请求结果,从响应的数据中我们可以知道这个响应来自的线程和请求 id,根据这些信息我们就可以从维护的上下文中找到对应的回调(某些请求在收到响应前会触发一些事件,这种情况下响应里是没有请求 id 的)。
接着看一下如何调试子线程,调试端口默认是 9229,因为存在多线程,如果我们要同时调试多个线程的话,则会失败,所以我们要允许前端来控制打开的端口,接着给子线程发送一个命令。
this.post(query.sessionId, {
method: "Runtime.evaluate",
params: {
includeCommandLineAPI: true,
expression: `let inspector;
try {
inspector = require('inspector');
inspector.open(${port}, ${host});
} catch(e) {
inspector = process.binding('inspector');
inspector.open(${port}, ${host});
}
inspector.url();`
}
},
(err, result) = >{
});
我们通过在子线程里动态执行代码来打开 Inspector 端口,这里需要处理一下不同 Node.js 版本的兼容问题,高版本(比如 16)中增加了一个判断逻辑,如果存在 session 就无法动态打开 Inspector 端口了,比如以下代码在 16 中会报错(换一下 connect 和 open 的位置就可以执行)。
const inspector = require('inspector');
const session = new inspector.Session();
session.connect();
inspector.open()
这里需要绕过 JS 层的判断,通过 C++ 模块提供的接口直接打开 Inspector 端口,这样就可以保证任何时候我们都可以动态打开 Inspector 端口。最后通过 inspector.url() 让子线程返回调试的 URL 并保存到上下文中,和进程一样,前端也是通过 API 的方式连接子线程的 WebSocket Server。最后形成的结构如下。
4. 使用方式
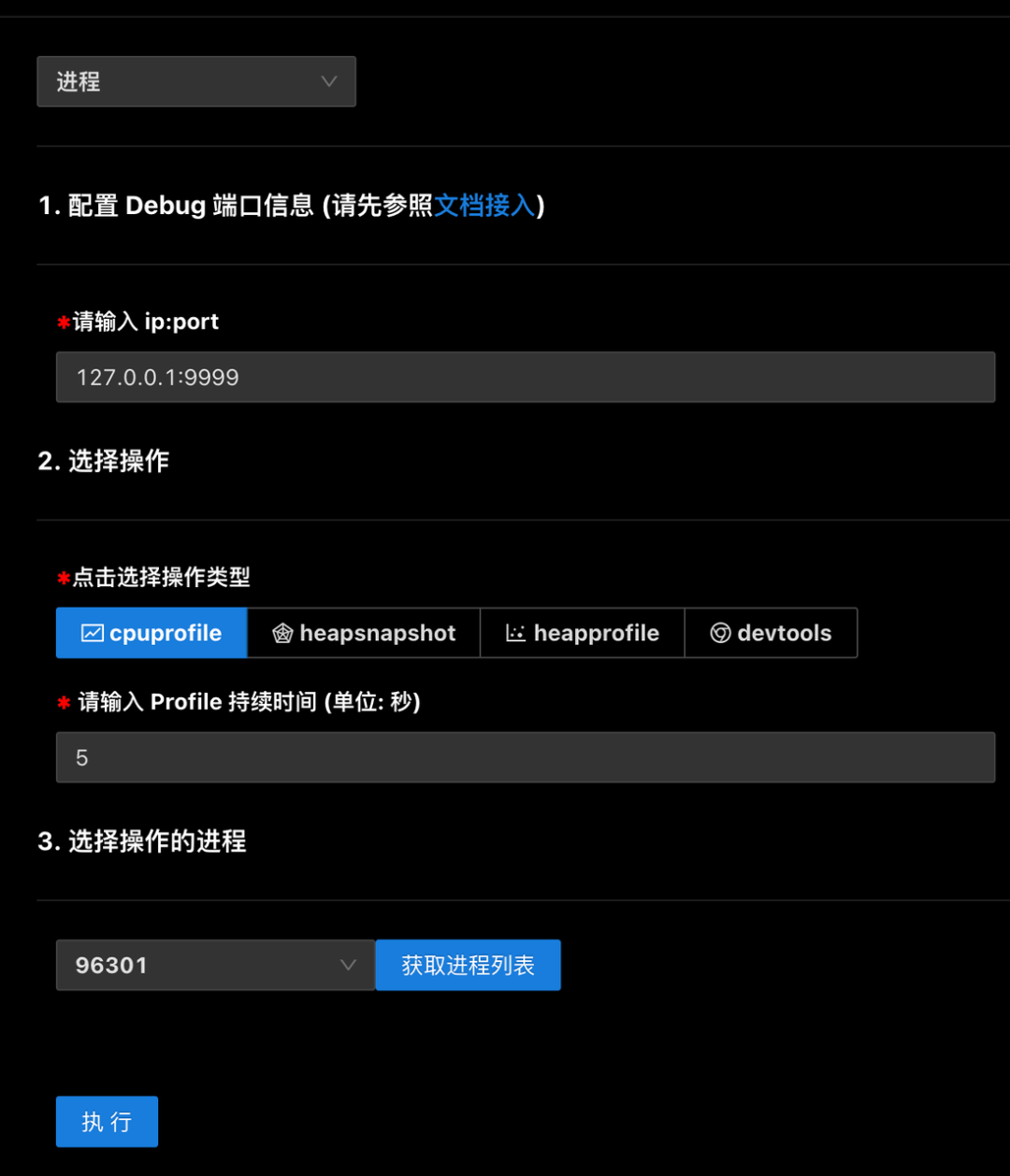
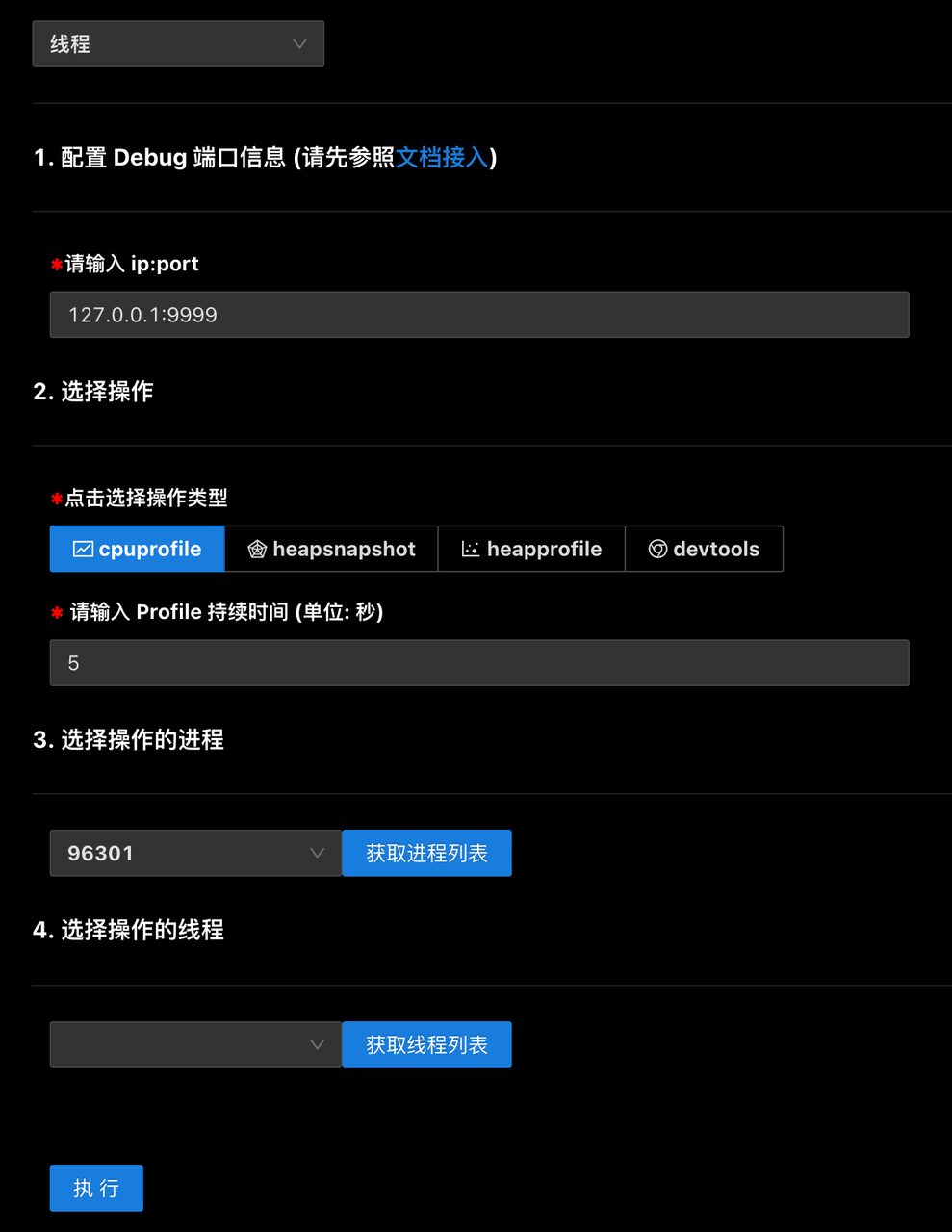
目前支持了多个子进程和多个线程的调试、获取 CPU Profile、获取 Heap Profile、获取 Heap Snapshot、获取内存信息(RSS、堆外内存、ArrayBuffer等信息)能力。使用方首先在业务代码里加载 SDK,部署服务后,进入调试诊断平台页面,按照以下步骤操作:
选择调试进程还是线程
输入服务地址(Agent 进程监听的地址)和选择对应的操作类型,如果是收集数据则还需要输入收集的持续时间。
获取进程列表,并从中选择你想操作的进程,每个选项 hover 时会提示进程对应的信息,比如文件路径。
如果操作线程的话,在选择进程后,还需要获取该进程下的线程列表,并选择你想操作的线程。
点击执行就可以获得你想收集的数据或者在线调试的 URL。
进程:
线程:
5. 总结
进程、线程的调试和诊断在 Node.js 中的实现非常复杂,了解了 Node.js 的实现和使用方式后,具体应用到业务里也不容易,主要是要考虑到不同的业务场景,需要设计出通用的方案,另外调试是一个比较有用但是也比较危险的操作,在安全方面也需要多多考虑。调试、诊断和安全一样,平时用不上,但是有问题的时候,能帮助我们更好地解决问题。
更多内容参考:
深入理解 Node.js 的 Inspector:https://mp.weixin.qq.com/s/GLIlhURSrCYQ-8Bqg7i1kA
Node.js子线程调试和诊断指南:https://zhuanlan.zhihu.com/p/402855448
Node 社群
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
“分享、点赞、在看” 支持一波👍