点击“开发者技术前线”,选择“星标”
让一部分开发者看到未来
爱奇艺技术产品团队举办了第19期“i技术会沙龙”,本次i技术会的主题是“数据治理探索与应用”,来自快手、美团、快看的几位资深专家共同就相关技术议题进行了深入探讨。爱奇艺研究员彭涛老师分享了题为《爱奇艺数据质量监控的探索和实践》的内容,主要介绍数据治理平台中的规则引擎模块,包括当前规则引擎面临的问题、目标、异常检测的方法以及对后续规则引擎功能的探索。以下为《爱奇艺数据质量监控的探索和实践》干货分享,根据【i技术会】演讲整理成文。
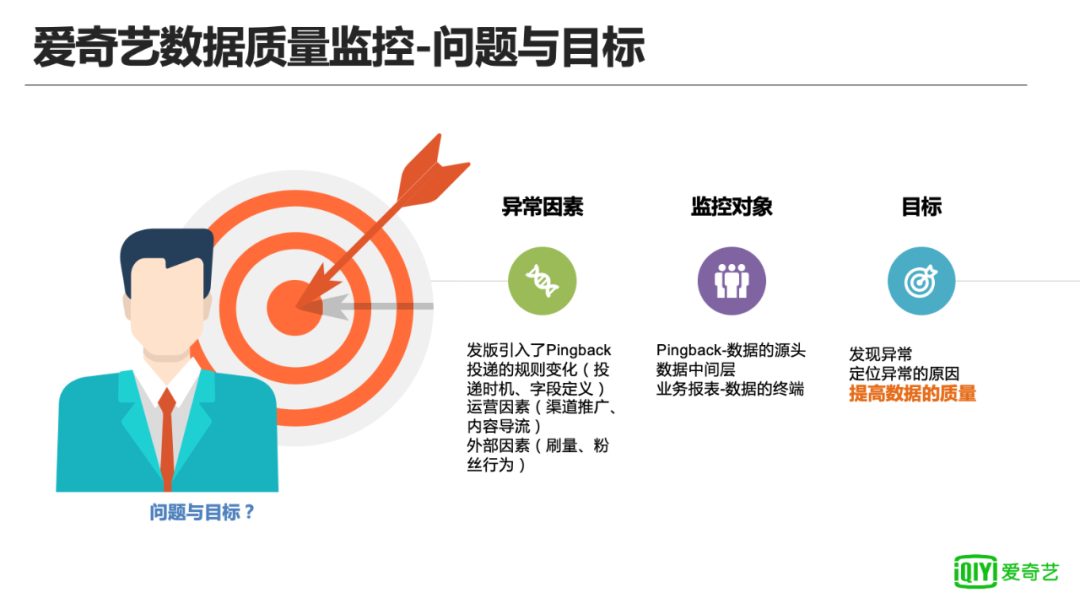
数据质量监控其实跟当前疫情的防控工作有些类似,核酸检测能尽早去发现病毒,溯源则会更了解病毒会在哪些场景,或者对哪些人有比较大的影响,方便进行跟踪,这和数据质量监控有异曲同工之处。 数据出现问题会有很多原因,我们把引起数据异常的原因分成以下3个因素:
产品因素:如APP发版,引起Pingback的投递策略发生了变化;
运营和外部因素:如渠道的运营、内容导流、刷量和粉丝行为、合作方因素;
技术问题:如数据的缺失、计算逻辑问题,这些也会对数据造成很大影响。
面对不同原因的数据异常,从监控角度我们怎么去管控呢?目前爱奇艺质量监控从3个层面进行,包括:
Pingback层:Pingback是各个报表的源头,从源头出发,对Pingback的投递质量进行改善;
数据中间层:通过在数据中间层增加必要的监控,避免异常数据传导到下游;
业务报表层:面对用户和运营,是非常重要的一块,也是非常直观的,这部分数据面向的人员众多,且每个人关注点会有差异,需要做到的是尽量覆盖重要业务的监控,尤其是核心数据监控。
针对这些问题,爱奇艺对数据质量监控提出了几个目标。
首先是发现异常,并及时处理;
其次是定位异常的原因,原因有的可能是合理的,比如运营的原因,合理因素只需要进行备注,错误的数据则需要进行开发处理,包括但不限于前端、后端、数据开发等;
最终目标是提高数据的质量,保证数据的流转和运营健康。
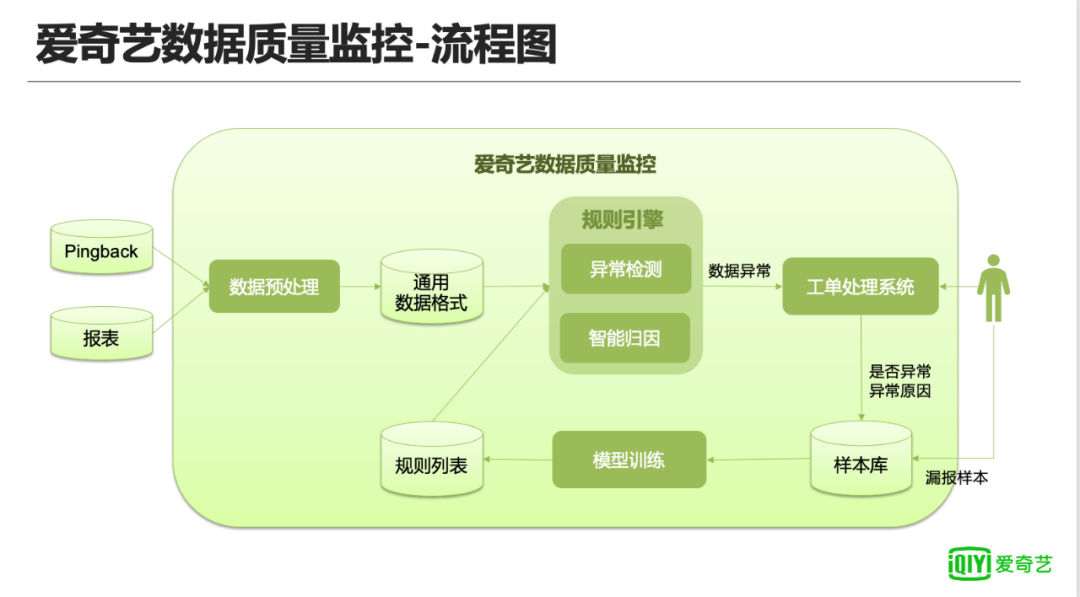
上图是目前爱奇艺数据质量监控的流程图,由于中间层和业务报表层在爱奇艺内部都以数据表形式存储,所以爱奇艺在做的数据质量的监控对这两部分内容进行了合并,最终把数据质量监控分成两块,Pingback和报表。数据预处理模块:负责对不同数据源进行统一的格式化处理;规则引擎分为异常检测和智能归因两部分,后面会详细阐述;工单处理系统:负责异常数据的后续处理,包括对异常原因进行备注,错误数据修复等线下管理工作,最终会把是否异常和异常原因写入样本库供后续监控的持续优化。

爱奇艺内部把Pingback的监控拆分成了以下三个维度:
- 业务维度:细分到具体的业务和端,如爱奇艺Android客户端、爱奇艺iPhone客户端等;
- 事件类型维度:针对用户的不同行为进行监控,如启动、播放、展现点击等;
- 时间维度:分成了三个等级:5分钟级、小时级、天级。
针对上述维度的Pingback监控,对指标进行了标准化处理,方便自动化的监控,包括日志的PV和UV、字段的空值率和有效率、数值类型的均值方法、枚举值的分布等等。对于Pingback维度的监控,这里举一个爱奇艺启动UV的例子,爱奇艺APP初期,仅投递了冷启动事件(用户手动打开APP),我们在数据分析中,发现播放UV每天都比启动UV高。我们后来发现,投递有很多漏投的情况,如Push拉起、用户切换程序再切回来、直接从历史任务中恢复等等。后来增加了其它投递类型的启动事件投递后,启动的PV和UV都有了很大的增长,保证我们的DAU计算更加真实合理。针对Pingback希望能够在投递层面尽早发现这些问题,所以Pingback异常监控,我们也会在灰度的时候介入并发现和修复问题,把影响范围降低到最小。
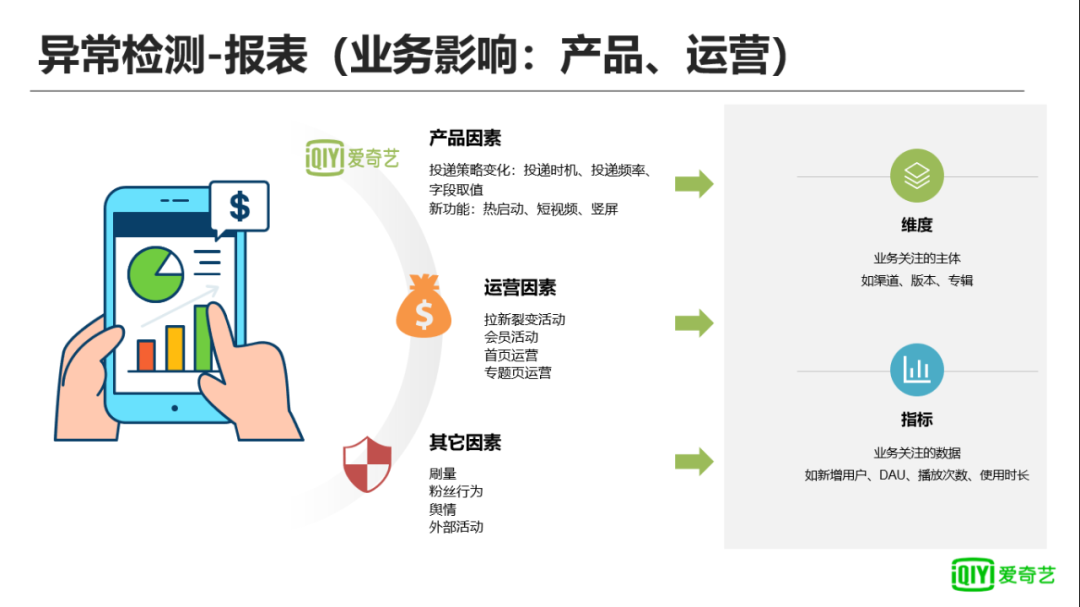
对报表影响的因素在“问题和目标”一节中已经进行过相应的介绍,这里不再赘述。针对这些问题,我们把监控区分为维度和指标:维度指业务关注的主体,如整体数据、分渠道的数据、分版本数据、分专辑数据等;指标指具体维度下计算的数值,以渠道数据为例,我们会有新增UV、次日留存、7日留存等指标。
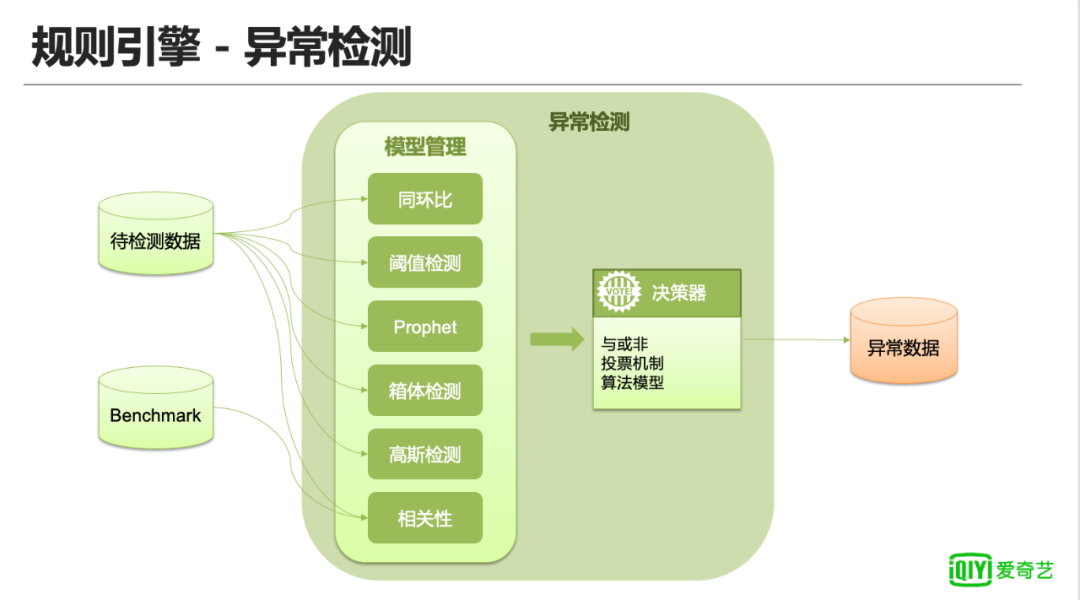
上图是爱奇艺数据质量监控异常检测模块涉及的检测方法,由前置的多个异常检测和后置的决策器一起作用。
每一种检测方法适用的场景也不同,需要根据数据情况进行匹配。下面会结合爱奇艺内部的一份真实数据对不同检测方法进行简单介绍,包括对方法的简单介绍、适用场景和优缺点。
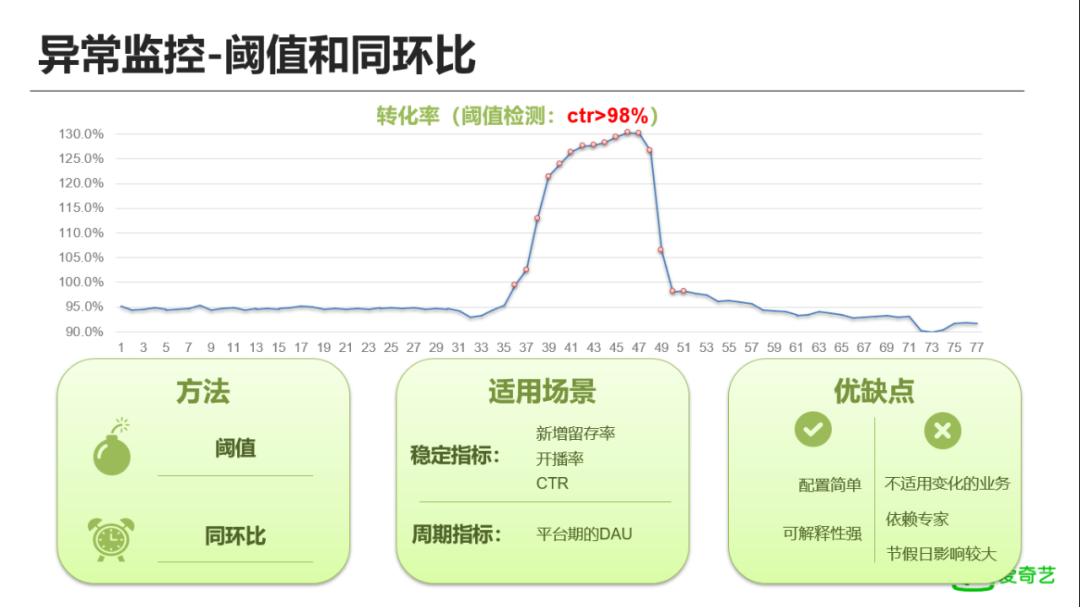
阈值和同环比:这是一个转化率指标,正常情况下都低于100%,某一天开始该数据突然上升到100%以上,高的时候都达到了130%。对于这个指标我们可以通过阈值法进行异常检测,以设定比如CTR大于阈值98%为例,可以很方便地把出现异常的日期标注出来(黄色的点即为异常点)。
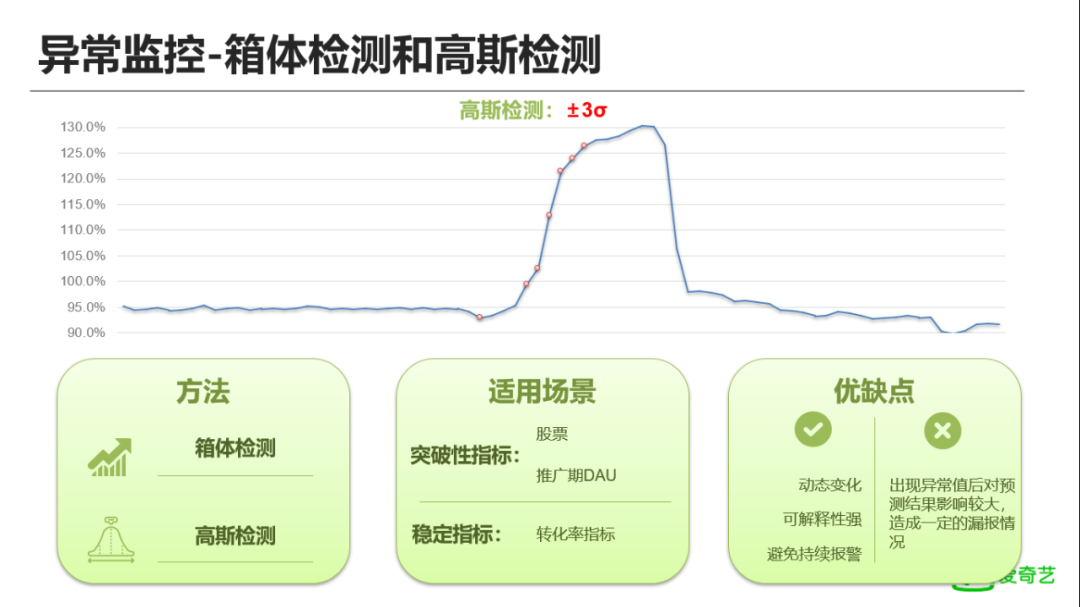
这是一种统计法的异常检测方案,根据历史趋势能够动态感知数据的趋势变化。同样以转化率这个指标使用高斯检测法为例,我们根据过去30天的统计指标,设置±3σ以外的数据为异常值,可以看出数据出现明显波动后可以有效检测出异常点,但稳定到高点附近以及回落的数据被判定为正常。由此可以看出上述统计法是一个动态调整的检测方法,非常适用于对业务推广期的检测。不过这里也有一个缺点,出现一个异常值之后,异常值加到序列里面,对后续预测的结果影响比较大,后面的都没有报警,这样会有些漏报的情况。
相关性检测
相关性的指标检测,是一个两种或者多种趋势相关性比较强的指标,所以适合相关性较强的指标间进行对比。同样以转化率为例,我们把转换率(转化率=B/A)拆分为A\B两个指标,通过计算其历史上的相关性,可以发现在正常情况下A、B指标具有很强的相关性,相关系数高达0.98,通过相关系数法,我们把低于0.8的都认为是异常。
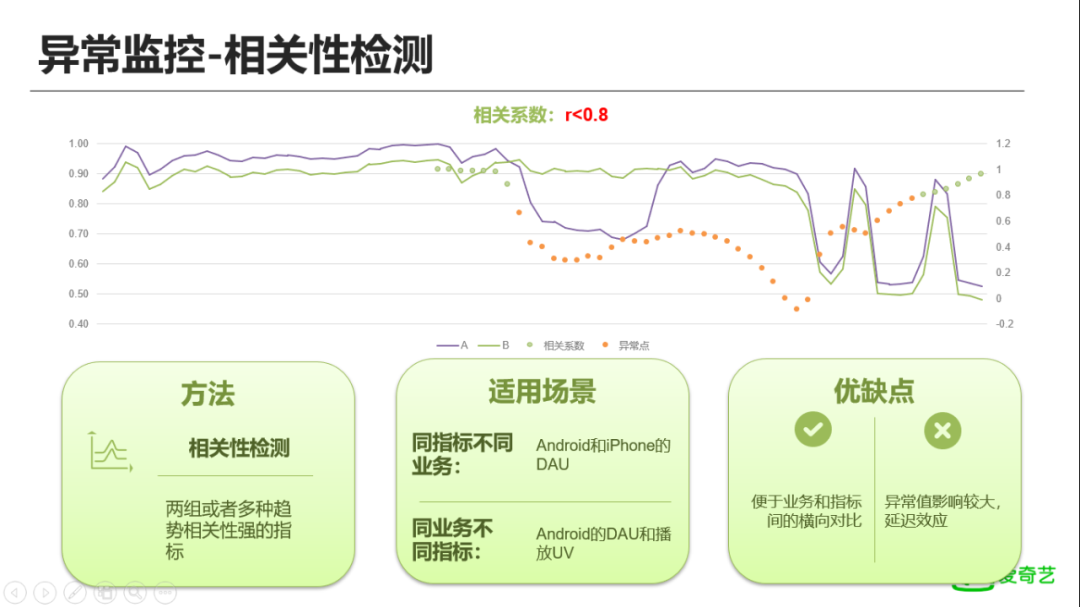
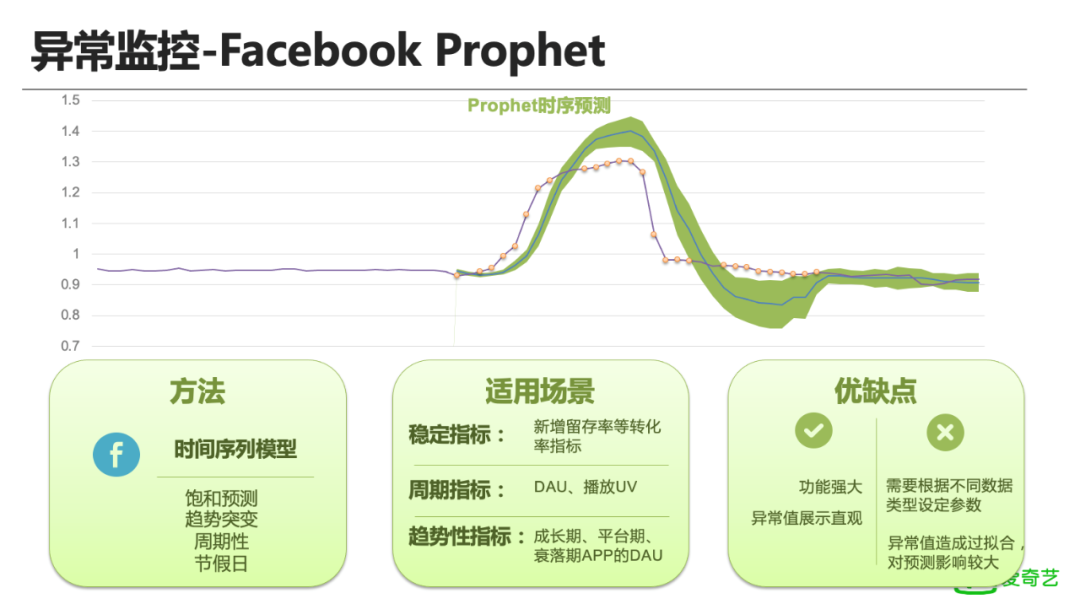
优点:是便于业务和指标间的横向对比。譬如DAU指标出现了明显下跌,可以通过参考其它业务进行横向对比,也可以参考同业务下其它指标进行纵向对比,分析是否异常。缺点:只能确定两个指标相关性异常,但是不能确定到底是A异常还是B异常,或者两者都有异常,需要结合其它检测方法一起使用;延迟效应特别严重,稳定指标出现异常时当天能比较快的发现,但后续会出现持续的报警,出现长时间的误报。 最后,我们引入了Facebook的 Prophet,这是一个时序预测模型,支持的类型比较多,包括:饱和预测,趋势的突变,周期性的指标,也引入了一些节假日的参数可以录入,因此该方法适用的场景也比前面更多。仍然以上述的转化率指标为例,看看Prophet是怎么做的,其会提供预测值、预测上限、预测下限3个指标。上图中,紫色的线是真实的转化率指标,绿色的区域是预测的上下限区间,中间蓝色的线则是预测曲线。通过设置绿色区间之外的值为异常值。可以发现该方法能够检测出绝大部分异常值,效果非常明显,但也有一个明显的问题,当把异常值引入样本后,预测值偏离了正常值曲线,且其预测的上下限区间也越来越大,造成过拟合。综合看,上述的相关性、高斯检测、Prophet等异常检测方法都对样本数据比较敏感,因此在实际生产中,需要对这些异常值进行处理。后续我们会结合样本库,把真实的异常值剔除进行策略制定,提升异常检测的整体效果。
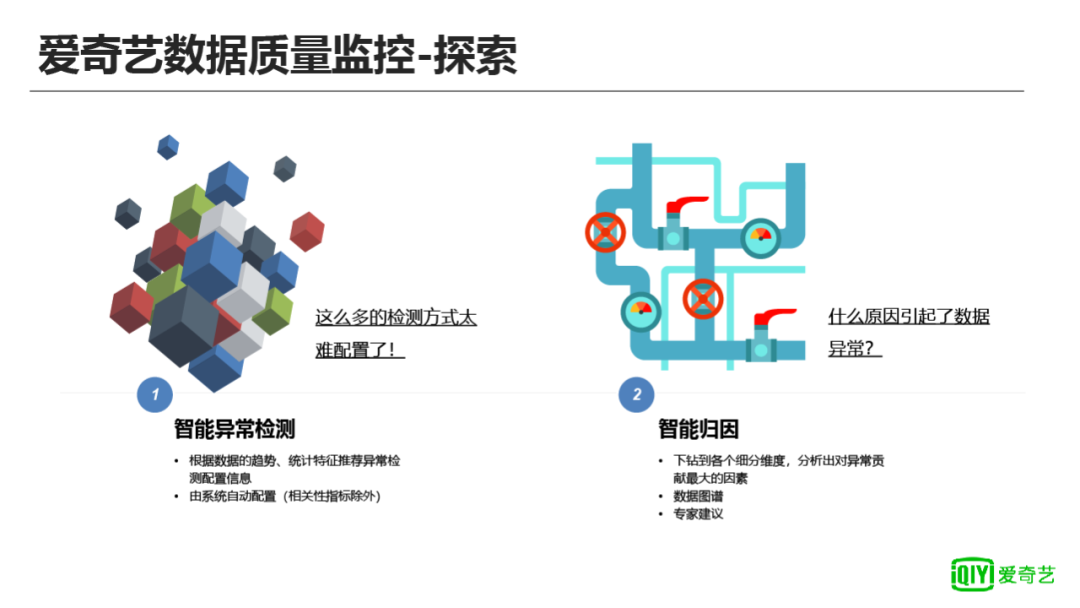
通过上面的介绍,可以看出异常检测方法非常多,具体到维度+指标的配置就会引入很大的工作量。因此上述方法前期只会应用到核心数据等指标。为了减少配置的工作量和提升异常数据的处理效率,我们计划做2件事:
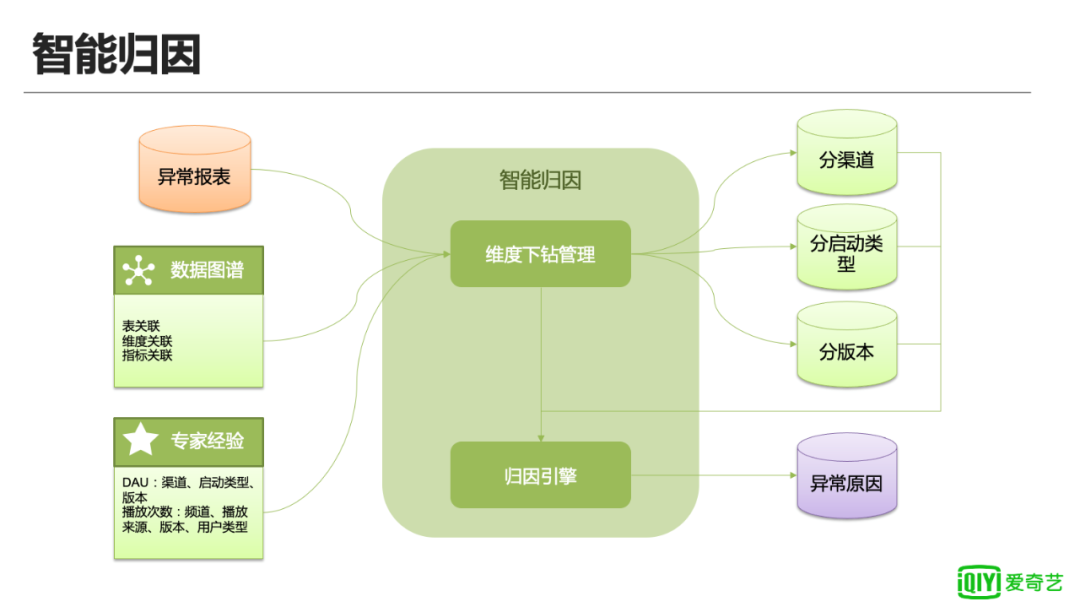
上图是智能归因模块的架构。
维度下钻管理:负责协调各个模块,制定下钻的逻辑;
数据图谱:爱奇艺数据中台的产品,管理表和字段的上下游关系,为智能归因提供血缘关系;
专家建议:沉淀异常原因历史经验,由于异常因素很多,通过历史经验,我们可以确定分析的核心方向,减少下钻的维度爆炸,提高计算效率;
归因引擎:负责具体的归因执行逻辑,包括发现下钻维度中异常因素最大的维度值;汇总不同维度的异常原因,输出可读的异常原因。
— 完 —
点这里👇关注我,记得标星呀~
前线推出学习交流一定要备注:研究/工作方向+地点+学校/公司+昵称(如JAVA+上海
扫码加小编微信,进群和大佬们零距离
后台回复“电子书” “资料” 领取一份干货,数百面试手册等