
超110篇!CVPR 2021最全GAN论文汇总梳理!

下述论文已分类打包好!超110篇,事实上仍有一些GAN论文未被包含入内……可见GAN在CVPR 2021仍十分火热。
后台回复 2021GAN (长按红字、选中复制)获取分类、按文件夹汇总好的论文集,gan起来吧!!!
等你着陆!【GAN生成对抗网络】知识星球!一、年龄迁移
1,Continuous Face Aging via Self-estimated Residual Age Embedding

人脸合成,尤其是年龄迁移,一直是生成对抗网络 (GAN) 的重要应用之一。大多数现有的人脸年龄迁移方法会将数据集分为几个年龄组并利用基于组的训练策略,这在本质上缺乏提供精细控制的连续年龄合成的能力。
这项工作提出统一的网络结构,将线性年龄估计器嵌入到基于 GAN 的模型中,年龄估计器与编码器和解码器联合训练以估计人脸图像的年龄并提供个性化的目标年龄特征嵌入。
 二、发型迁移
二、发型迁移2,LOHO: Latent Optimization of Hairstyles via Orthogonalization

由于源发型和目标发型的结构差异,发型迁移具有挑战性。提出通过正交化(LOHO)对发型进行潜在空间的优化,用GAN逆映射方法,在发型迁移期间填充潜在空间中缺失的头发结构细节。
方法将头发分解为三个属性:结构、外观和风格,并定制损失来独立建模这些属性。提出两阶段优化和梯度正交化,以实现头发属性的潜在空间解纠缠优化。使用LOHO进行潜在空间操作,用户可通过操作头发属性,从参考发型中迁移所需的属性来合成新图像。

- 与当前最先进的发型迁移技术相比,LOHO实现FID表现更好。根据PSNR和SSIM,LOHO较好保留了主体身份。代码https://github.com/dukebw/LOHO
3,Spatially-invariant Style-codes Controlled Makeup Transfer

从未对齐的参考图像中迁移妆容具有挑战性。以前的方法通过计算两个图像之间的像素对应来克服这个障碍,这不准确且计算成本高。本文从不同的角度将妆容迁移问题分解为两步“提取-分配”过程。
为此提出一种基于风格的可控 GAN 模型,由三个组件组成,每个组件分别对应于目标风格码编码、人脸身份特征提取和妆容融合。
特定于局部区域风格的编码器将参考图像的局部妆容编码为中间潜在空间 W 中的风格码。风格码忽略空间信息,对于空间错位具有不变性。而且,风格码嵌入了局部信息,支持从多个参考进行灵活的编辑。此风格码与源身份特征一起集成到AdaIN层融合,在解码器生成最终结果。方法支持卸妆、阴影可控的、特定部的位妆容迁移。
代码可在 https://github.com/makeuptransfer/SCGAN
4,Lipstick ain’t enough: Beyond Color Matching for In-the-Wild Makeup Transfer

妆容迁移将参考图像中的化妆风格应用到源脸上。现实生活中的妆容是多样的,包括变色、图案贴纸、腮红甚至珠宝等。然而,现有方法忽视了后者的组成部分,并将妆容迁移到色彩处理上,只关注淡妆风格。
这项工作提出一个整体的妆容迁移框架,由改进的颜色迁移分支和图案迁移分支组成,用于学习所有化妆属性,包括颜色、形状、纹理和位置。为训练和评估,还为真实和合成的极端化妆引入新的化妆数据集。
实验结果表明,方法在淡妆、浓妆都达到了最先进的性能。代码https://github.com/VinAIResearch/CPM
5,Disentangled Cycle Consistency for Highly-realistic Virtual Try-On

- 图像虚拟试穿指的是,用参考衣服图像替换人物图像上的衣服,这并不简单,因为人和衣服没有配对数据集。现有方法将虚拟试穿制定为修复或循环一致性。这两个公式都鼓励生成网络以自监督的方式重建输入图像。然而并没有区分服装和非服装区域。由于严重耦合的图像内容,简单的生成阻碍了虚拟试穿质量。

- 本文提出Disentangled Cycleconsistency Try-On Network (DCTON),能够通过解耦虚拟试穿的重要组成部分(包括衣服变形、皮肤合成和图像合成)来生成高度逼真的试穿图像。此外,在循环一致性学习之后,DCTON 可以以自监督的方式自然地进行训练。
6,VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization

虚拟试穿任务旨在将目标服装迁移到人的相应区域,通常通过将衣服拟合到身体部位,并与人体融合来解决。虽然已经进行了越来越多的研究,但合成图像的分辨率仍然低(例如,256×192)。限制源于几个挑战:随着分辨率的增加,扭曲的衣服和所需的衣服区域之间未对齐区域中的伪影在最终结果中变得明显;方法在生成高质量的身体和保持衣服的纹理清晰度方面性能较低。
提出VITON-HD,成功合成1024×768的虚拟试穿图像。首先准备分割图来指导虚拟试穿合成,然后将目标服装大致适合给定人的身体。接下来,提出ALIgnmentAware Segment (ALIAS) 归一化和 ALIAS 生成器来处理未对齐的区域,并保留 1024×768 输入的细节。通过与现有方法比较,证明VITON-HD在合成图像质量方面在质量和数量上有显著改进。
 五、姿势迁移、人像合成
五、姿势迁移、人像合成7,HumanGAN: A Generative Model of Human Images

- 生成对抗网络在各领域图像合成取得了出色的表现,然而通常用潜在向量来对采样输出进行全局编码。这不能方便地控制图像中语义相关的各个部分,也不能绘制仅在部分方面不同的样本,例如服装风格。

- 本文尝试解决这些限制,可以控制姿势、局部身体部位的外观和服装风格。
8,MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generation

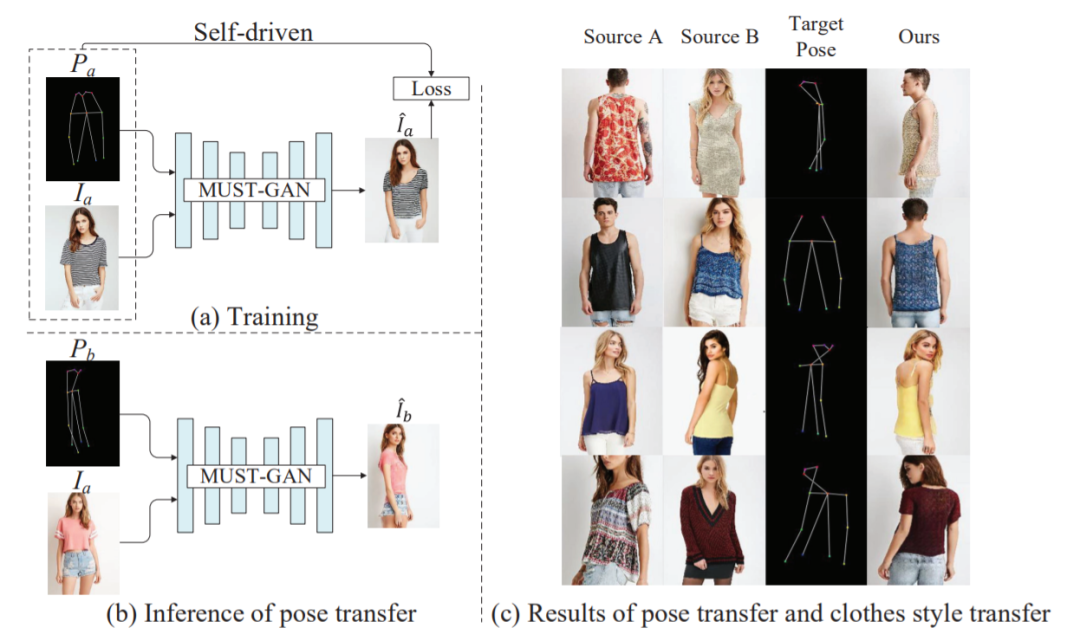
9,PISE: Person Image Synthesis and Editing with Decoupled GAN

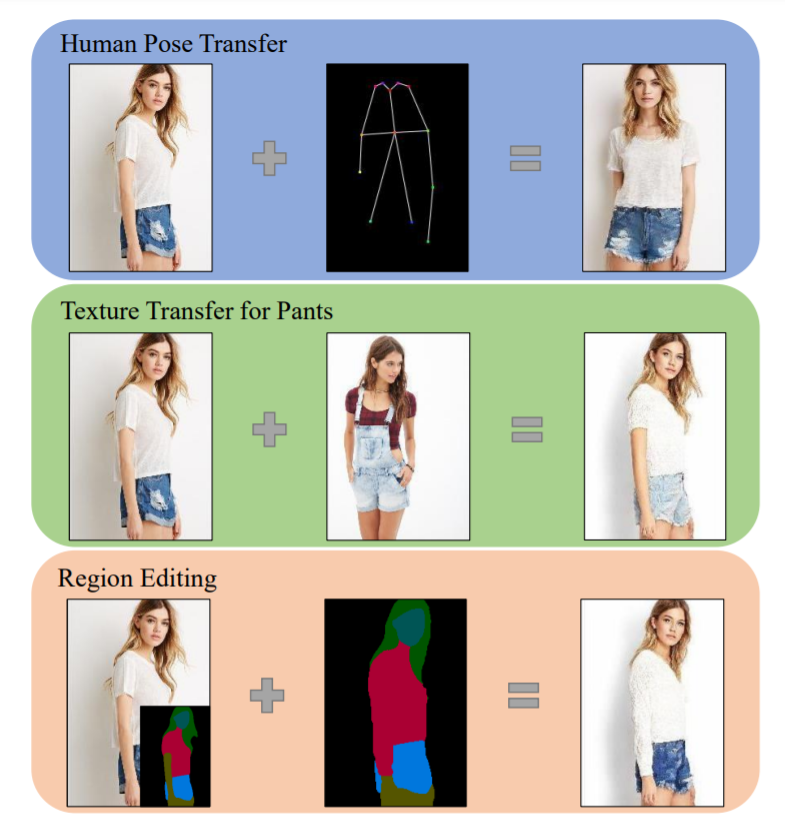
由于大的变化和遮挡,人物图像合成,例如姿势迁移,是一个具有挑战性的问题。现有方法难以预测合理的不可见区域,并且无法解耦服装的形状和风格,这限制了它们在人物图像编辑中的应用。
本文提出PISE,一种用于人物图像合成和编辑的新型两阶段生成模型,能生成具有所需姿势、纹理或语义布局的逼真人物图像。
对于人体姿势迁移,首先合成一个与目标姿势对齐的人体解析分割图,通过解析生成器来表示服装的形状,然后通过图像生成器生成最终图像。为解耦服装的形状和风格,提出联合全局和局部每个区域的编码和归一化来预测不可见区域的合理服装风格。还提出了空间感知归一化以保留源图像中的空间上下文关系。
10,HistoGAN: Controlling Colors of GAN-Generated and Real Images via Color Histograms

虽然生成对抗网络 (GAN) 可以成功生成高质量的图像,但生成内容难以控制。简化基于 GAN 的图像生成对于它们在平面设计和艺术作品中的采用至关重要。这一目标引起了人们对可以直观地控制 GAN 生成的图像外观的方法的极大兴趣。本文提出HistoGAN,一种基于颜色直方图的方法,用于控制 GAN 生成图像的颜色。
专注于颜色直方图,是因为它提供一种直观的方式来描述图像颜色。具体来说,对StyleGAN 架构修改,由目标颜色直方图特征指定的颜色GAN生成图像。实验表明,这种基于直方图的方法提供了一种更好的方法来控制 GAN 生成图像的颜色。https://github.com/mahmoudnafifi/HistoGAN HistoGAN

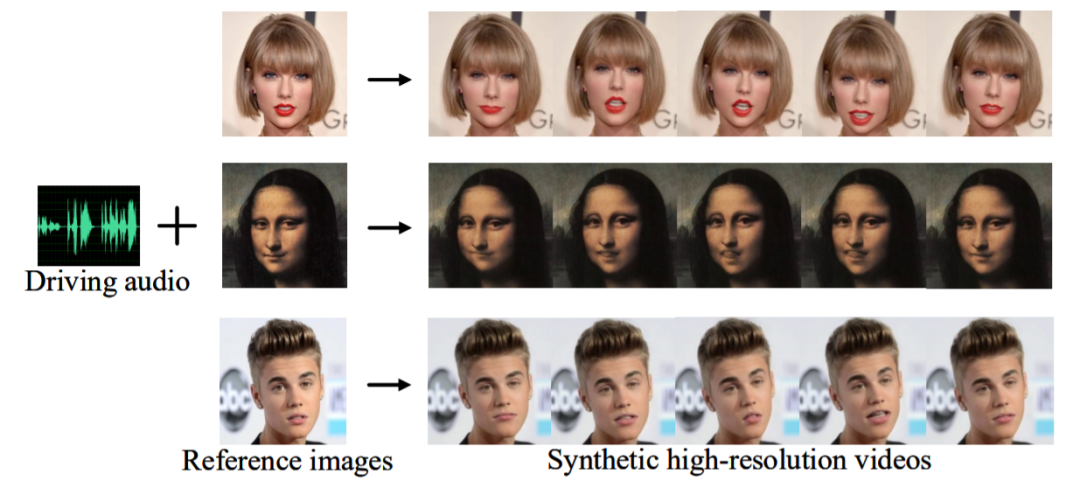
11,Audio-Driven Emotional Video Portraits

- 尽管此前一些方法在基于音频驱动的说话人脸生成方面已取得不错的进展,但大多数研究集中在语音内容与嘴形之间的相关性上。人脸的情感表现是很重要的特征,但此前的方法总忽视这一点。

- 这项工作提出“表情视频肖像” (Emotional Video Portraits,EVP),一种由音频驱动、具有动态情感的肖像视频合成系统。具体来说,提出交叉重构式的表情解耦技术,将语音分解为两个解耦空间,即与时长无关的情感空间和与时长相关的内容空间。解开的特征可推断出动态2D表情人脸。
12,Everything’s Talkin’: Pareidolia Face Reenactment

提出Pareidolia Face Reenactment 的新应用方向,指的是动画化静态虚幻的脸,让其与参照视频中的人脸一起变动。
分解为三个串联过程:形状建模、运动迁移和纹理合成。通过分解,引入了三个关键组件,即参数形状建模、动作迁移和无监督纹理合成器。

13,Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation

- 针对任意人的、以其音频驱动的说话人脸生成研究方向,已实现了较准确的唇形同步,但头部姿势的对齐问题依旧不理想。

- 此前的方法依赖于预先估计的结构信息,例如关键点和3D参数。但极端条件下这种估计信息不准确则效果不佳。本文主要针对的是,如何生成姿势可控的说话人脸。
14,One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing

- 提出一种说话人脸的视频合成模型,并展示在视频会议中的应用。

- 使用包含目标人物的源图像,以及驱动视频来合成源人物说话视频。运动信息基于一种关键点表示进行编码,其中特定于身份和运动相关的信息被无监督地解耦。
15,Flow-guided One-shot Talking Face Generation with a High-resolution Audio-visual Dataset

一次性说话人脸生成应合成具有合理表情和头部姿势动画的高视觉质量人脸视频,并仅以任意驾驶音频和任意单人脸图像为源。由于缺乏合适的高分辨率视听数据集,以及稀疏面部标志在提供不良表情细节方面的限制,当前的工作无法生成超过 256×256 分辨率的逼真视频。
为此构建一个大型的高分辨率视听数据集,并提出一种流式引导的说话人脸生成方法。新数据集从youtube 收集,由大约 16 小时的 720P 或 1080P 视频组成。利用人脸3D可变形模型 (3DMM) 将框架拆分为两个级联模块,而不是学习从音频到视频的直接映射。第一个模块里,设计生成器来同时生成嘴巴、眉毛和头部姿势的运动;第二个模块,将动画转化为密集流以提供更多的表达细节,并设计流引导的视频生成器来合成视频。方法能制作高清视频,并在客观和主观比较中优于当前最好算法。
 八、人脸图像编辑
八、人脸图像编辑16,Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing

生成对抗网络 (GAN) 从随机潜在向量Z合成逼真的图像。虽然通过潜在向量能一定程度上控制合成,但存在以下问题:i) 将真实图像投影到潜在向量的优化耗时,ii) 通过编码器的特征嵌入难精确。提出StyleMapGAN:中间潜在空间具有空间维度,且替代AdaIN,更准确控制。
https://github.com/naver-ai/StyleMapGAN

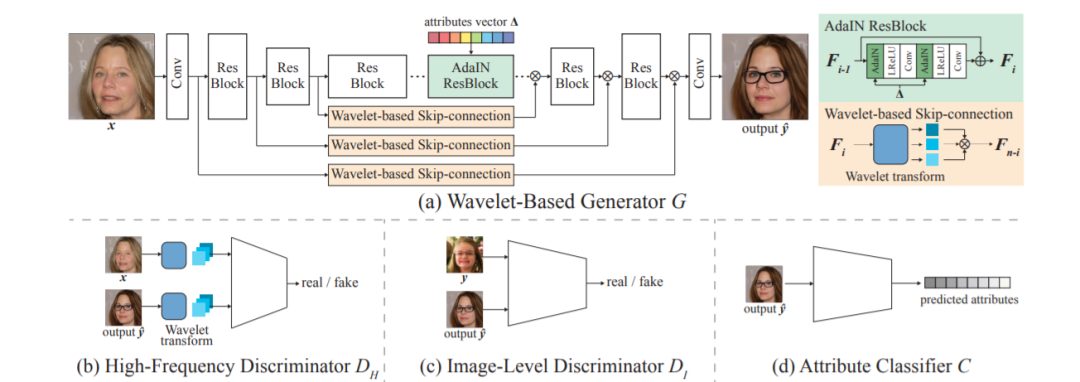
17,High-Fidelity and Arbitrary Face Editing

- 循环一致性广泛用于人脸编辑。然而,生成器倾向于为满足循环一致性的约束,无法保持丰富细节。这项工作提出HifaFace,从两个角度解决上述问题。首先,通过将输入图像的高频信息直接馈送到生成器的末端来减轻生成器合成丰富细节的压力。其次,采用额外的判别器来鼓励生成器合成丰富的细节。具体来说,应用小波变换将图像变换到多频域,其中高频部分可用于恢复丰富的细节。注意到,对属性进行细粒度和更广泛的控制对于人脸编辑非常重要。为了实现这一目标,提出了一种新的属性回归损失。
18,Hijack-GAN: Unintended-Use of Pretrained, Black-Box GANs


- GAN模型具有高度非线性的潜在空间,本文通过迭代方案实现对图像生成过程的控制。代码可在 https://github.com/a514514772/hijackgan
19,Linear Semantics in Generative Adversarial Networks

生成对抗网络 (GAN) 能够生成高质量的图像,但仍难明确指定合成图像的语义。这项工作旨在更好地理解 GAN 的语义表示,从而实现语义控制。
本文发现训练好的GAN以一种非常简单的方式在其内部特征图中编码图像语义:特征图的线性变换足以提取生成的图像语义。为了验证这种简单性,对各种 GAN 和数据集进行了大量实验;并且由于这种简单性,能从少量(例如 8 个)标记图像中为经过训练的 GAN 学习语义分割模型。最后利用这种发现,提出少样本图像编辑方法。代码https://github.com/AtlantixJJ/LinearGAN
20,DeFLOCNet: Deep Image Editing via Flexible Low-level Controls

在图像编辑场景中,往往会有一些用户交互,比如期望的内容草图、颜色等提示线索。现有方法将输入图像和用户交互线索用于CNN 输入,但相应的特征表示不足以传达用户意图细节,从而导致生成内容不佳。
本文提出DeFLOCNet,依赖于深度编码器-解码器保留输入信息在深度特征表示。在每个跳跃连接层中,设计结构生成块,并将这些用户提示直接注入每个结构生成块中。同时,DeFLOCNet还有另一个用于纹理生成和细节增强的解码器分支。
代码可在 https://github.com/KumapowerLIU/DeFLOCNet

21,L2M-GAN: Learning to Manipulate Latent Space Semantics for Facial Attribute Editing


一般来说,深度人脸属性编辑模型力求满足两个要求:(1)属性正确性——目标属性应该正确出现在编辑后的人脸图像上;(2) 不相关保存——任何不相关的信息(如身份)在编辑后不应更改。。
本文提出一种潜在空间分解模型,称为L2M-GAN,它是端到端学习的,可有效编辑局部和全局属性。(1)GAN 的潜在空间向量被分解为属性相关和不相关的码,并施加正交性约束以确保解开。(2) 学习一个属性相关的转换器来操作属性值;
22,One Shot Face Swapping on Megapixels

换脸既有娱乐、人机交互等正面的应用,也有DeepFake对政治、经济等的威胁等负面应用。本文提出第一个用于单样本、百万像素级人脸交换方法(或称MegaFS)。
MegaFS提出“层次表征人脸编码器” (HieRFE) 来表征人脸,保持更多细节,而不是以前的人脸交换方法中的压缩表示。还提出一种精心设计的人脸迁移模块(FTM)将身份从源图像迁移到目标。最后,可以利用StyleGAN2的训练稳定性和强大的生成能力来合成交换的人脸。
MegaFS的每个部分都可以单独训练,因此可以满足百万像素人脸交换的 GPU 内存模型的相应要求。总之,完整的人脸表征、稳定的训练和有限的内存使用是方法的三个亮点。大量实验了证明MegaFS的优越性,本文也发布了第一个百万像素级别的人脸交换数据库,用于研究DeepFake检测和人脸图像编辑。
 九、人脸识别
九、人脸识别23、A 3D GAN for Improved Large-pose Facial Recognition

基于端到端的深度卷积神经网络进行人脸识别,依赖于大型人脸数据集。这需要大量类别(不同人或者身份)的人脸图像,且对每个人都需要各种各样的图像,如此网络才能适应类内差异,增加鲁棒性。
然而现实中很难获得这样的数据集,特别是那些包含不同姿势变化的数据集。生成对抗网络(GAN)由于具有生成逼真的合成图像的能力,因此提供了解决此问题的潜在方法。

- 但最近的研究表明,将姿势与个人身份特征分离的方法效果并不好。本文尝试将3D可变形模型合并到GAN的生成器中,生成人脸,并在不影响个人身份辨识度的情况下操纵姿势、照明和表情。所生成的数据用在CFP和CPLFW数据集上,可增强人脸识别模型的性能。
24、When Age-Invariant Face Recognition Meets Face Age Synthesis: A Multi-Task Learning Framework

为了最大程度地减少年龄变化对人脸识别的影响,先前的工作有两种方案:一是通过最小化身份特征和年龄特征之间的相关性来提取与身份相关的辨识性特征(称为年龄不变的人脸识别age-invariant face recognition,AIFR);二是通过转换不同年龄组的人脸到同一年龄组,称为人脸年龄生成(face age synthesis,FAS);但是,前者缺乏用于模型解释的视觉结果,而后者则的生成效果可能有影响下游识别的伪影。
本文提出一个统一的多任务框架MTLFace来共同处理人脸识别和生成任务,它可以学习与年龄不变的身份表征,同时完成人脸合成。具体来说,通过注意力机制将混合的人脸特征分解为两个不相关的部分(身份和年龄相关的特征),然后使用多任务训练和连续域自适应将这两个部分的相关性进行解耦。
其中,与实现组级FAS的常规one-hot编码相反,提出了一种新颖的以身份作为条件的模块来实现身份级别的FAS,并采用权重共享策略来改善合成人脸的年龄平滑度。
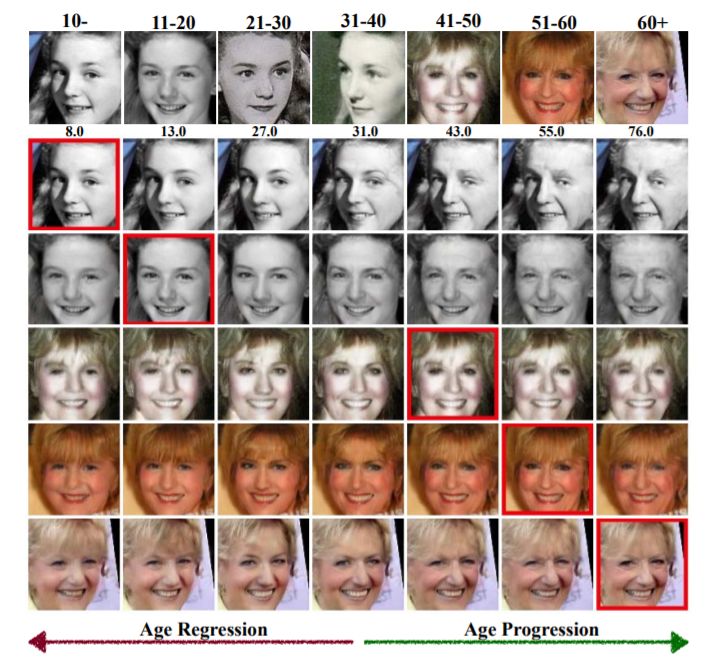
- 此外,收集并发布带有年龄和性别标注的大型跨年龄人脸数据集,以推进AIFR和FAS的发展。在五个基准跨年龄数据集上进行的广泛实验表明,MTLFace性能优于现有的AIFR和FAS方法。https://github.com/Hzzone/MTLFace
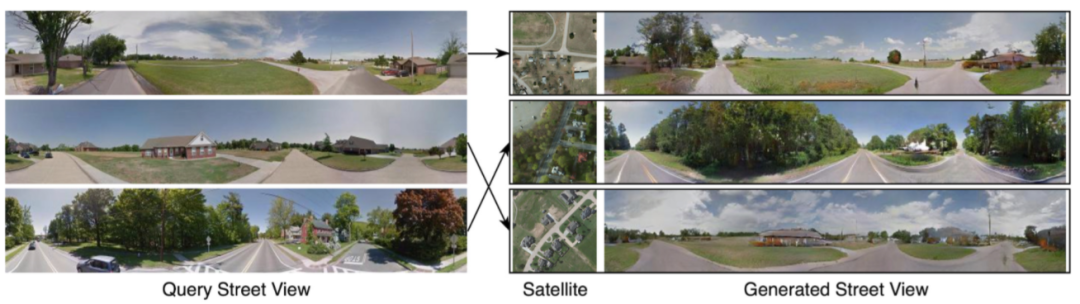
25、Coming Down to Earth: Satellite-to-Street View Synthesis for Geo-Localization

- 本文方法以卫星输入,跨视图地去合成街景图像。通过将查询街道图像与数据库中最近的卫星图像进行匹配来同时确定查询街道图像的地理位置。
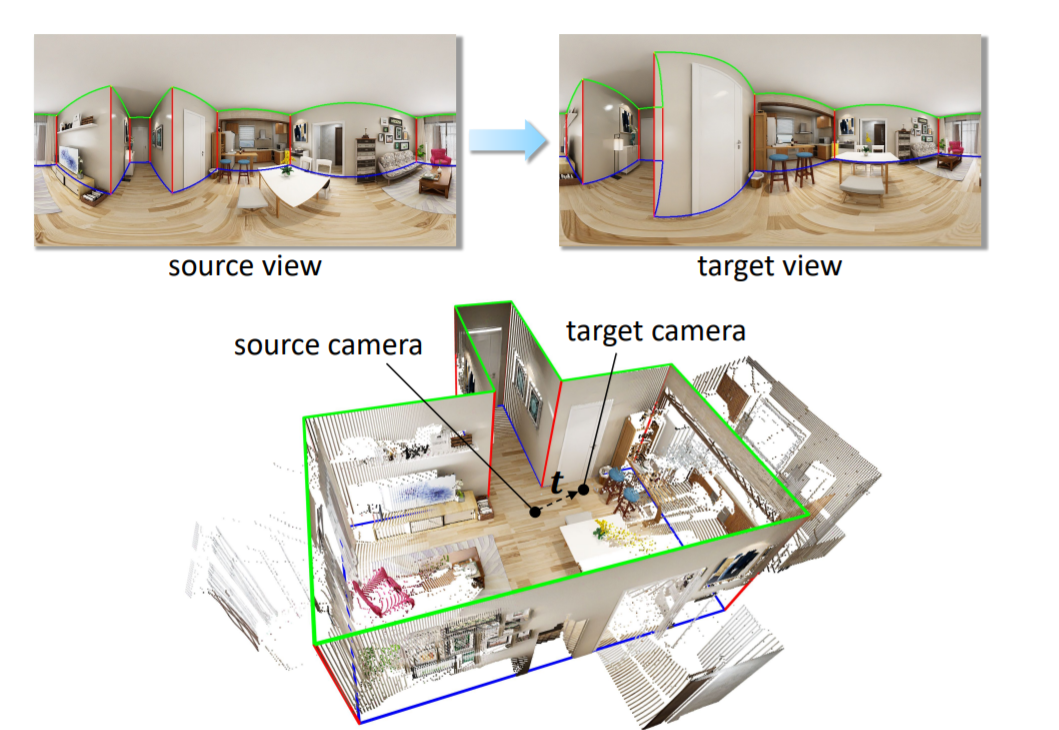
26、Layout-Guided Novel View Synthesis from a Single Indoor Panorama

本文尝试从单个室内全景图生成新的视图,并考虑到大型相机平移效果。首先使用卷积神经网络 (CNN) 从源视图图像中提取深度特征并估计深度图。然后,利用室内场景的强结构约束先验房间布局来指导目标视图的生成。
https://github.com/bluestyle97/PNVS
27、ID-Unet: Iterative Soft and Hard Deformation for View Synthesis

视图合成通常由自动编码器完成,其中编码器将源视图图像映射为潜在内容码,解码器根据条件将其转换为目标视图图像。但在此设置中,源内容往往没有得到很好的保存,这会导致视图转换过程中发生不必要的更改。虽然添加如Unet的结构,可缓解问题,但经常导致视图一致性不佳。
本文以迭代方式执行源到目标的转变合成,不是简单地结合来自多个编码器层的特征,而是设计软和硬变形模块,将编码器特征扭曲到不同分辨率的目标视图,并将结果提供给解码器以补充细节。
https://github.com/MingyuY/ Iterative-view-synthesis

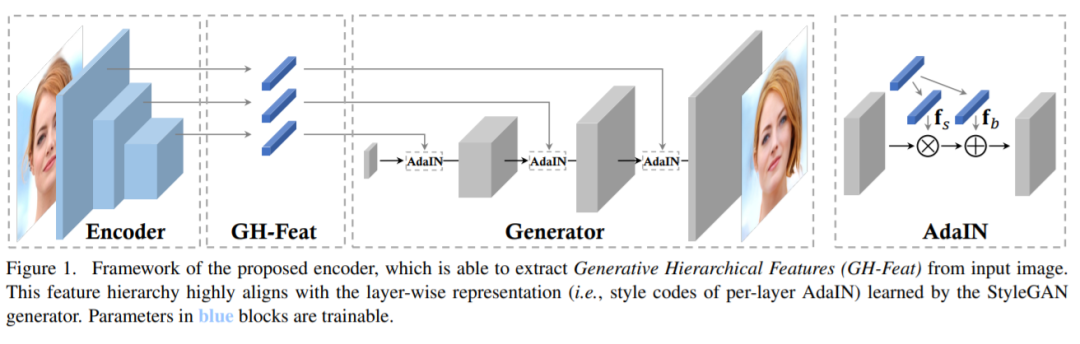
28、Generative Hierarchical Features from Synthesizing Images

生成对抗网络 (GAN) 通过学习数据的潜在分布来进行图像合成,但从中学到的特征如何适用于其他视觉任务仍然很少被探索。
这项工作表明通过学习合成图像,可以带来显著意义的层次视觉特征,这些特征可在各应用中使用。具体来说,将预训练的 StyleGAN 生成器视为学习的损失函数,并利用其逐层的表征来训练新的层次编码器,而编码器产生的视觉特征称为“生成式层次特征 (GH-Feat)”,对生成和判别任务具有很强的可迁移性,包括图像编辑、图像协调、图像分类、人脸验证、地标检测和布局预测。大量的定性和定量实验结果证明了GH-Feat的潜力。
https://genforce.github.io/ghfeat/
 十二、解耦学习
十二、解耦学习29,Smoothing the Disentangled Latent Style Space for Unsupervised Image-to-Image Translation

对图像到图像 (I2I) 多域转换模型,通常也使用其语义插值结果的质量进行评估。然而,最先进的模型经常在插值过程中显示图像外观的突然变化,并且在跨域插值时通常表现不佳。
本文提出基于三个特定损失的新训练方法,有助于学习平滑且解耦开的潜在风格空间,其中:1)域内和域间插值对应于生成图像的逐渐变化2)在转换过程中更好地保留源图像的内容。
提出一种评估指标来正确衡量 I2I 转换模型的潜在风格空间的平滑度。方法可以插入现有的转换方法中,在不同数据集上大量实验表明,可以显著提高生成图像的质量和插值的自然渐变。

30,Surrogate Gradient Field for Latent Space Manipulation

生成对抗网络 (GAN) 可以从采样的潜码中生成高质量的图像。最近的工作试图通过操纵其潜码来编辑图像,但很少超出属性调整的基本任务。
提出一种可以使用多维条件(例如关键点)进行操作的方法,基于辅助映射网络诱导的Surrogate Gradient Field(SGF)来搜索满足目标条件的新潜码。为定量比较,提出一个度量来评估操作方法的解耦度。

- 对人脸属性调整任务的分析表明,方法在解耦方面优于最先进方法。方法应用于各种条件模态的任务,也能改变复杂的图像属性,例如关键点等。
31,StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation

本文探索分析在多个数据集上预训练的模型StyleGAN2的潜在风格空间。
首先表明,在通道级别的风格参数空间在解耦度上更好;接下来,介绍一种挖掘大量风格通道的方法,它们以一种高度分离的方式控制不同的视觉属性。
最后还提出一种用预训练分类器或少量示例图像来识别控制特定属性的风格通道的简单方法。

32,Unsupervised Disentanglement of Linear-Encoded Facial Semantics

提出一种无需外部监督即可从 StyleGAN 中解开线性编码面部语义的方法。该方法源自线性回归和稀疏表示学习概念,使解耦的潜在表示也易于解释。
首先将 StyleGAN 与3D可变形人脸重建方法相结合,以将单视图生成分解为多个语义。然后提取潜在表示以捕获可解释的面部语义。
这项工作可以摆脱标签以解开有意义的人脸语义,沿着解耦的表示引导外推可以帮助数据增强,这有助于处理不平衡的数据。
 十三、主动学习
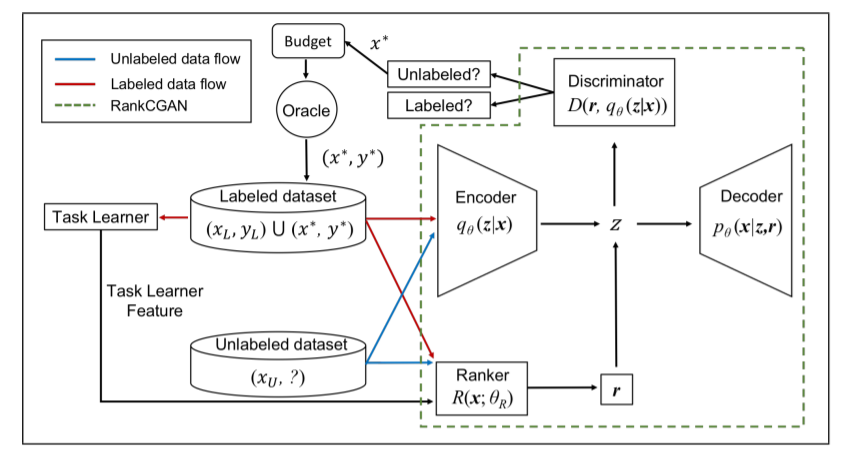
十三、主动学习33、Task-Aware Variational Adversarial Active Learning

- 标记大量数据成本高、甚至不可能。主动学习 (AL) 通过在未标记的池中查询信息量最大的样本来解决无标签数据的问题。
- 本文提出任务感知变分对抗主动学习(TA-VAAL),在平衡/不平衡标签的分类以及语义分割的各种基准数据集上的表现优于最先进的技术。
 十四、终身学习
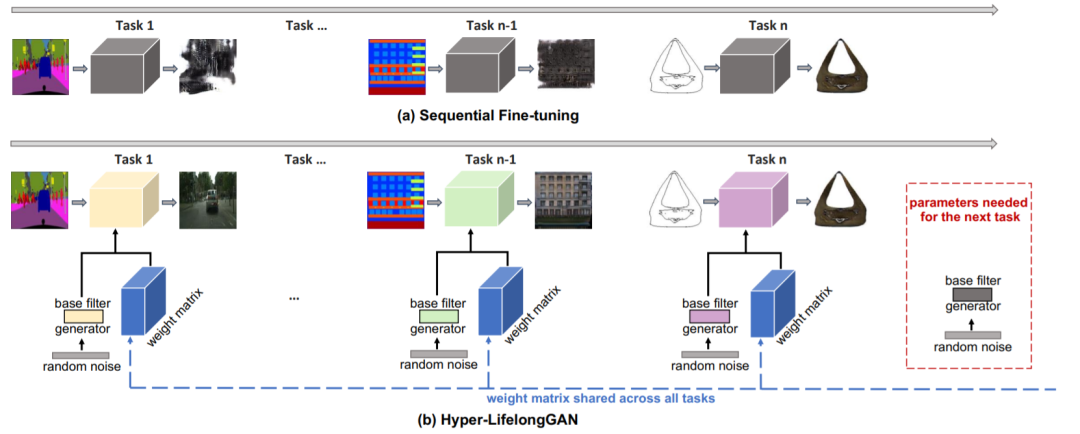
十四、终身学习34、Hyper-LifelongGAN: Scalable Lifelong Learning for Image Conditioned Generation

深度神经网络容易出现灾难性遗忘:当遇到新任务时,它们只能记住新任务,而无法保持其完成先前学习任务的能力。
本文研究生成模型的终身学习问题,提出一种通用的持续学习框架Hyper-LifelongGAN,所提出的方法可以以较低的参数成本保持甚至提高生成质量。在各种图像条件生成任务上验证方法可有效地解决灾难性遗忘问题。
 十五、迁移学习
十五、迁移学习35、Visualizing Adapted Knowledge in Domain Transfer

在源数据上训练的源模型,通过无监督域适应 (UDA) 学习的目标模型,它们通常编码了不同的知识。为理解不同域的适应过程,本文用图像转换来描绘它们的知识差异。
具体来说,将转换后的图像及其原始版本分别提供给两个模型,形成两个分支。通过更新转换后的图像,强制两个分支的输出相似。当满足这些要求时,两个图像之间的差异可以补偿并代表模型间的知识差异。
代码https://github.com/houyz/DA_visualization

36、Efficient Conditional GAN Transfer with Knowledge Propagation across Classes

生成对抗网络 (GAN) 在无条件和有条件的图像生成中都显示出令人印象深刻的结果。近来一些研究表明,可以迁移不同数据集上的预训练 GAN,以改进小目标数据的图像生成效果。
本文引入了一种新的 GAN 迁移方法来显式地将知识从旧类传播到新类。关键思想是强制条件批量归一化 (BN)从旧类信息学习新类信息,并进行知识共享。代码:https://github.com/mshahbazi72/cGANTransfer
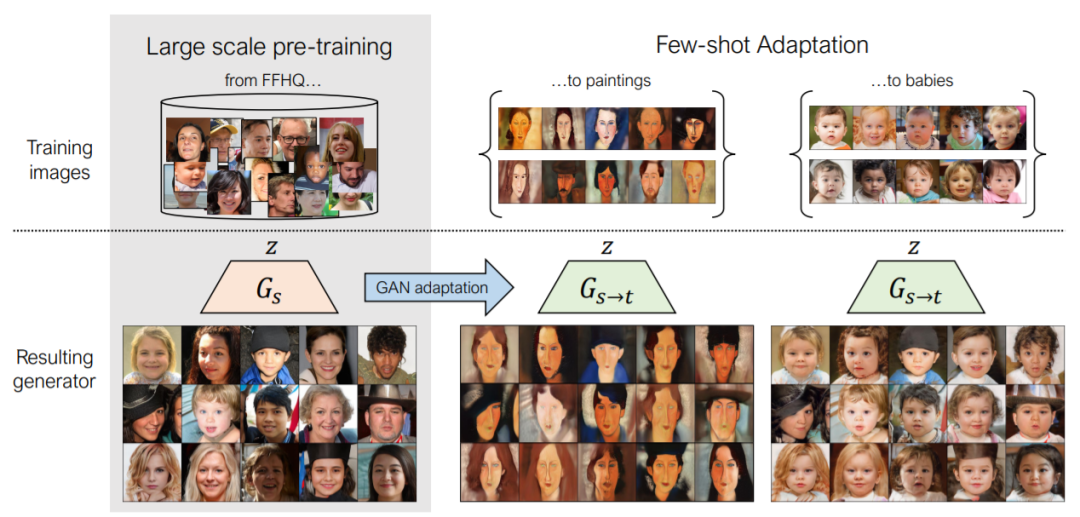
37,Few-shot Image Generation via Cross-domain Correspondence

- 样本有限(例如10个)训练生成模型时,容易导致过拟合。这项工作寻求利用大型源域进行预训练并将多样性信息从源转移到目标。
- 提出一种新的跨域距离一致性损失来保留源中实例之间的相对相似性和差异性。为进一步减少过拟合,提出一种基于锚的策略,以鼓励潜在空间中不同区域的不同程度的真实感。定性和定量地证明该小样本模型可以自动发现源域和目标域之间的对应关系,并生成比以前的方法更多样化和更逼真的图像。
 十七、半监督学习
十七、半监督学习38、Mask-Embedded Discriminator with Region-based Semantic Regularization for Semi-Supervised Class-Conditional Image Synthesis

当没有足够的标记数据可用时,半监督生成学习 (SSGL) 使用未标记的数据来实现数据和性能之间的权衡。学习精确的类语义对于有限监督数据的类条件图像合成至关重要。为此,提出一个带有掩码嵌入判别器的半监督生成对抗网络MED-GAN。
通过引入掩码嵌入模块,判别器特征与空间信息相关联,判别器在区分真实图像和合成图像时,可以将焦点限制在指定区域内。如此,强制生成器合成包含更精确类语义的实例。同样受益于掩码嵌入,在判别器特征空间上强加了基于区域的语义正则化,可增加真假类之间以及对象类别之间的分离程度。实验中MED-GAN 的优越性能证明了掩码嵌入和相关正则化在促进 SSGL 方面的有效性。
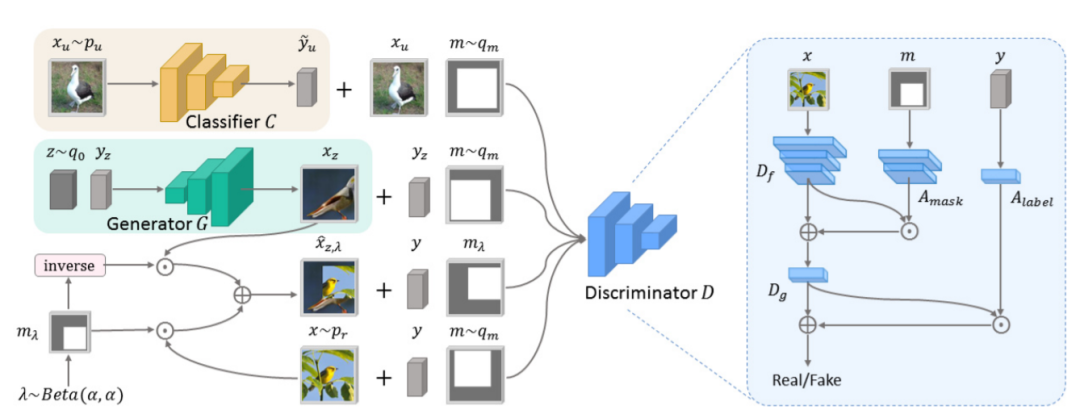
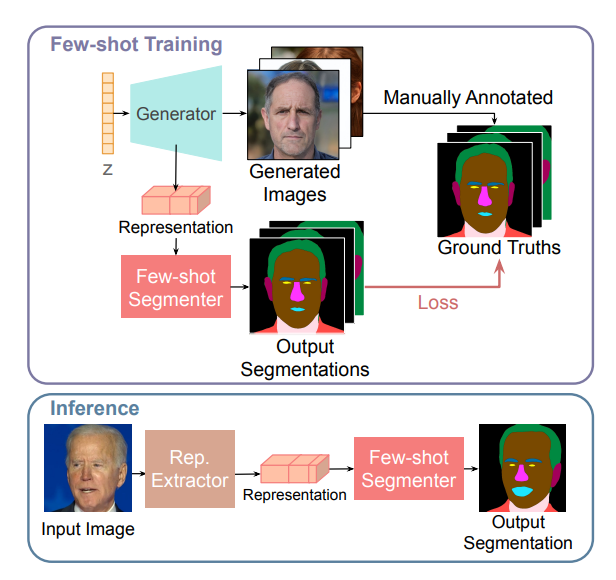
39、DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort

提出DatasetGAN用于生成高质量语义分割图像的大量数据集。当前的深度网络得益于大规模数据集的训练,而这些数据集标注起来非常耗时。
方法基于GAN生成逼真图像,展示了如何解码 GAN 潜码以生成图像语义分割图。训练解码器只需要几个带标签的例子就可以推广到其余的潜在空间,从而产生无限的带标签的数据集生成器!
 十八、单样本训练
十八、单样本训练40,Learning to Generate Novel Scene Compositions from Single Images and Videos

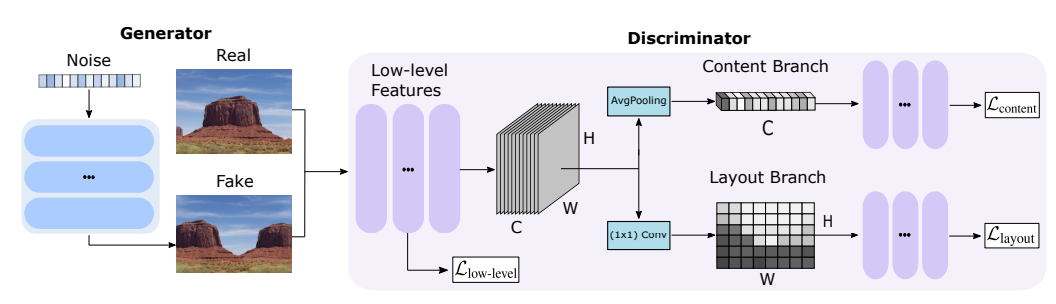
在少量训练数据情况下,训练 GAN 仍是一个挑战,通常会有过拟合问题。
这项工作引入One-Shot GAN,它可以学习从一张图像或一个视频的训练集中生成样本。提出了一个两分支鉴别器,其内容和布局分支旨在分别从场景布局真实感中判断内部内容。这就可以合成具有不同内容和布局的视觉上合理的、新颖的场景组合,同时保留原始样本的上下文。与之前的单图像 GAN 模型相比,One-Shot GAN 实现了更好的多样性和合成质量。它也适用单个视频的学习。
41,IMAGINE: Image Synthesis by Image-Guided Model Inversion

引入了一种基于逆映射的方法,用IMAge-Guided INvVersion (IMAGINE)表示,可以仅从单个训练样本生成高质量和多样化的图像。
利用来自预训练分类器的图像语义知识,通过匹配分类器中多级特征表示来实现合理的生成,并与外部鉴别器的对抗训练相关联。IMAGINE使合成过程能够同时 1) 在合成过程中强制执行语义特异性约束,2) 无需生成器训练即可生成逼真的图像,3) 为用户提供对生成过程的直观控制。
 十九、多样化生成
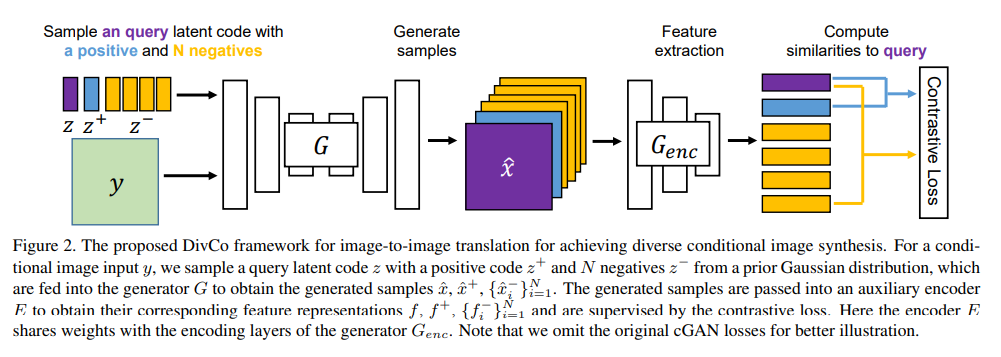
十九、多样化生成42,DivCo: Diverse Conditional Image Synthesis via Contrastive Generative Adversarial Network

条件生成对抗网络 (cGAN) 可以在给定输入条件和潜码的情况下,合成不同的、多样化的图像。但常常会遇到模式坍塌的问题。为了解决这个问题,以前的工作主要集中在潜码与其生成的图像的关系上,而忽略了各种潜码所生成图像之间的关系。
与MSGAN只考虑图像对之间的“负”关系不同,本文所提出的DivCo框架,可以恰当地约束潜在空间中指定的生成图像之间的“正”、“负”关系;这是第一次将对比学习用于多样性条件图像生成的尝试。
本文引入一种潜在增强对比损失,它鼓励从相邻潜码生成的图像相似、而不同潜码生成的图像则不同。所提出的潜在增强对比损失可以很好地与各种 cGAN 架构兼容。大量实验表明,在多个非成对和成对的图像生成任务中,DivCo可以生成更多样化的图像,且不牺牲视觉质量。训练代码和预训练模型:https://github.com/ruiliu-ai/DivCo
43,Diverse Semantic Image Synthesis via Probability Distribution Modeling

- 语义图像合成(Semantic image synthesis),将语义布局转换为照片般逼真的图像,是一个一对多的映射问题。

尽管已有不错的进展,但有效地产生多样化效果仍是一个挑战。本文从语义类分布的角度提出一种多样化语义图像合成框架,支持语义甚至实例级别的多样化生成。
提出通过将类级条件调制参数建模为连续概率分布而不是离散值来实现,对多个数据集的大量实验表明,与最先进方法相比,可以实现更好的多样性和视觉质量。代码:https://github.com/tzt101/INADE.git
44,Navigating the GAN Parameter Space for Semantic Image Editing

- 生成对抗网络 (GAN) 目前是视觉编辑不可或缺的工具,是图像转换和图像复原的常用方法。此外,可以通过探索GAN的潜在空间中所包含的可解释方向,可以进行可控生成、语义编辑等操作。本文扩展使用最先进模型(如 StyleGAN2),在生成器参数空间中探索可解释的方向。

45,Context-Aware Layout to Image Generation with Enhanced Object Appearance

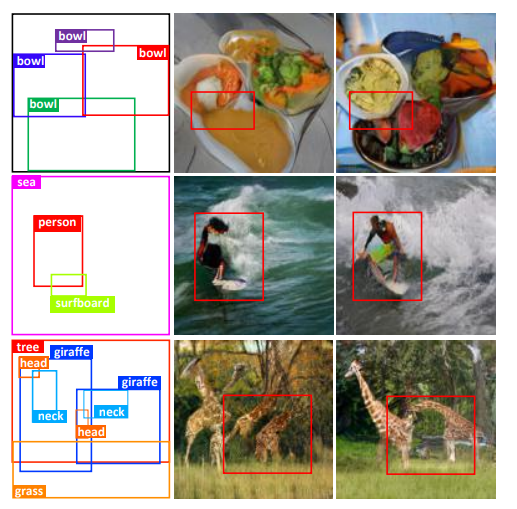
布局到图像 (layout to image,L2I) 任务的生成模型:以给定布局为条件输入,生成符合语义的图像。现有方法有两个局限:(1)图像中对象之间的关系不完整;(2)对象的外观扭曲,语义辨识度。
本文认为这是由于生成器中缺少上下文特征感知的能力,或者判别器缺少位置敏感的外观表示造成。为此这项工作提出两个新模块:在生成器引入上下文感知特征转换模块,以确保生成的对象的特征编码了解场景中其他共存的对象;其次,使用从生成的对象图像的特征图计算的 Gram 矩阵来保留位置敏感信息,以改善对象的外观。代码:https://github.com/wtliao/layout2img
46,House-GAN++: Generative Adversarial Layout Refinement Network towards Intelligent Computational Agent for Professional Architects

本文提出一种用于自动平面图生成的GAN网络,方法由图约束的关系GAN和条件GAN集成。前一步生成的布局作为下一个输入,实现迭代细化。
代码、模型和数据可在 https://ennauata.github.io/houseganpp/page.html
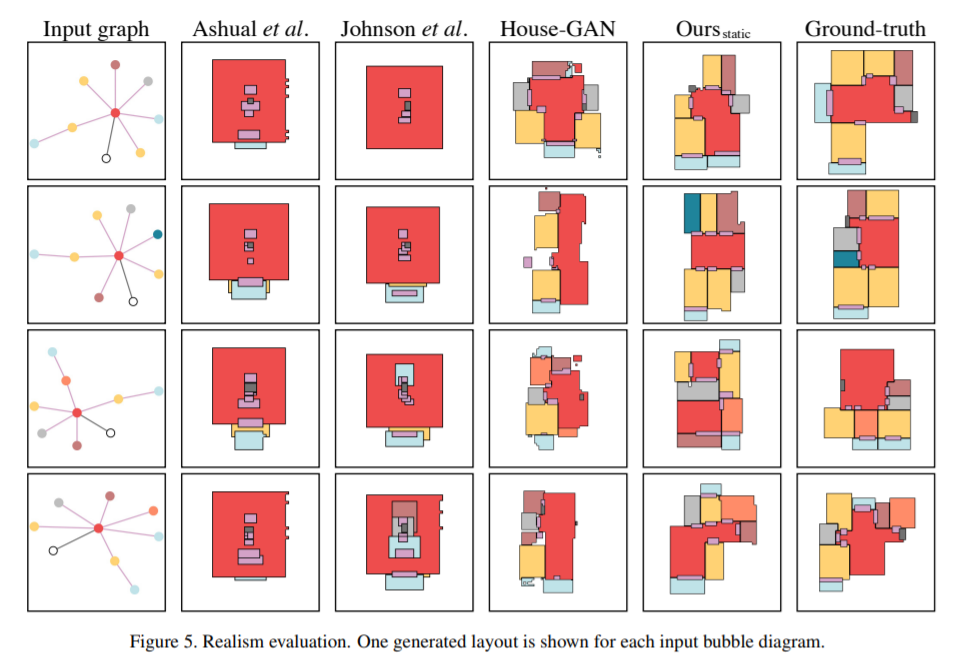
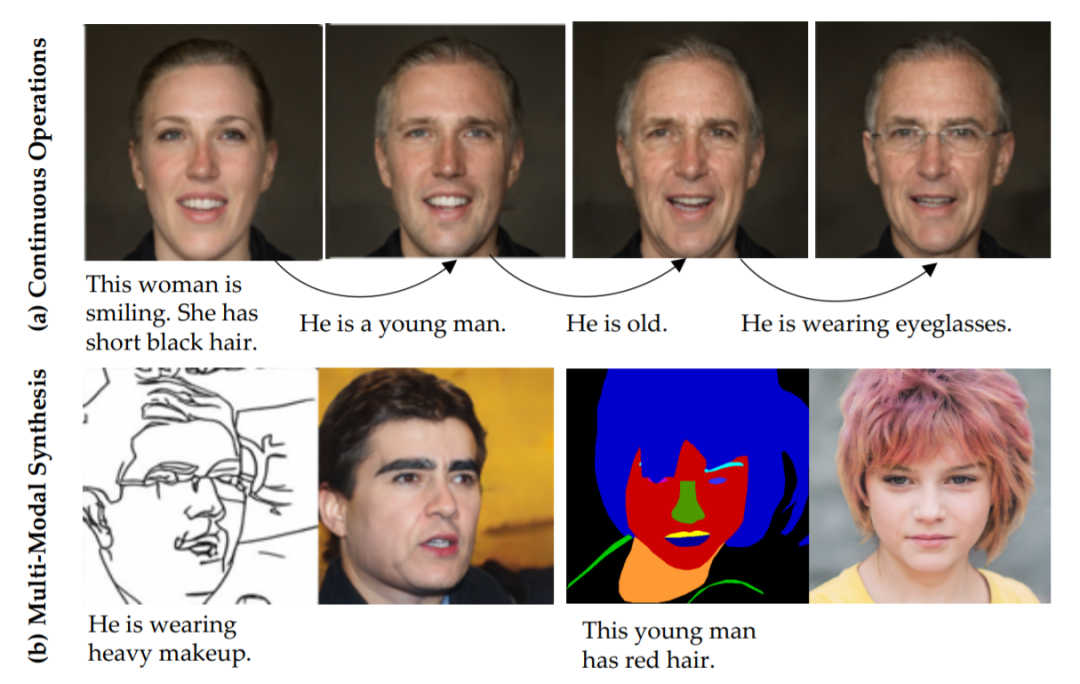
47,TediGAN: Text-Guided Diverse Image Generation and Manipulation

提出TediGAN,一种用于多模态图像生成和处理文本描述的方法。由三个部分组成:StyleGAN逆映射模块、视觉语言相似性学习和实例级优化。
逆映射模块是训练图像编码器将真实图像映射到StyleGAN潜在空间;视觉-语言相似性通过将图像和文本映射到公共嵌入空间来学习文本-图像匹配;实例级优化用于操作中的ID身份信息保存。
为了促进文本引导的多模态合成,提出MULTIMODAL CELEBA-HQ,一个由真实人脸图像和相应的语义分割图、草图和文本描述组成的大规模数据集。
在引入数据集上的大量实验证明了方法的优越性能。代码和数据https://github.com/weihaox/TediGAN
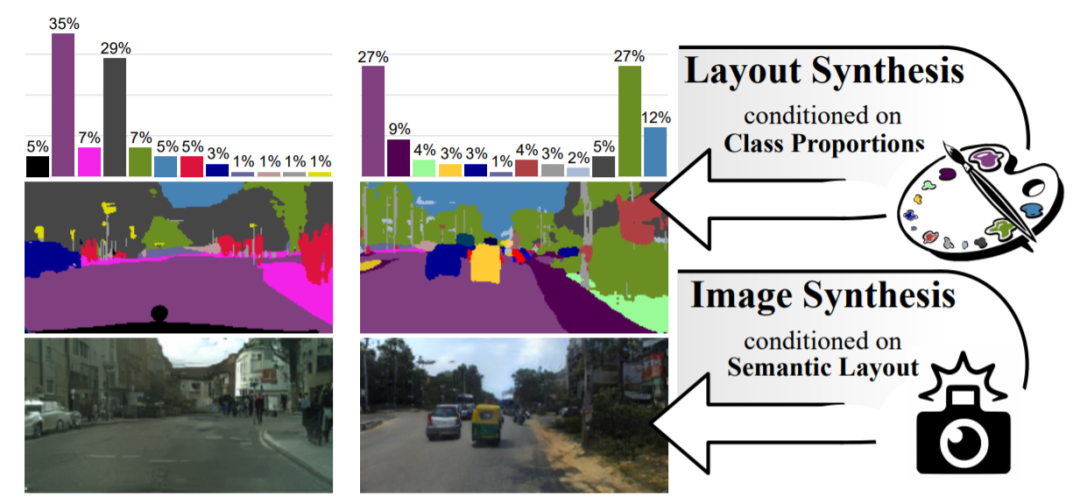
48、Semantic Palette: Guiding Scene Generation with Class Proportions

尽管最近生成对抗网络 (GAN) 在合成逼真图像方面取得了进展,但生成复杂的城市场景仍然是一个具有挑战性的问题。
这项工作探索的是,更高的语义控制下的条件布局生成:给定一个类比例向量,生成对应的布局。
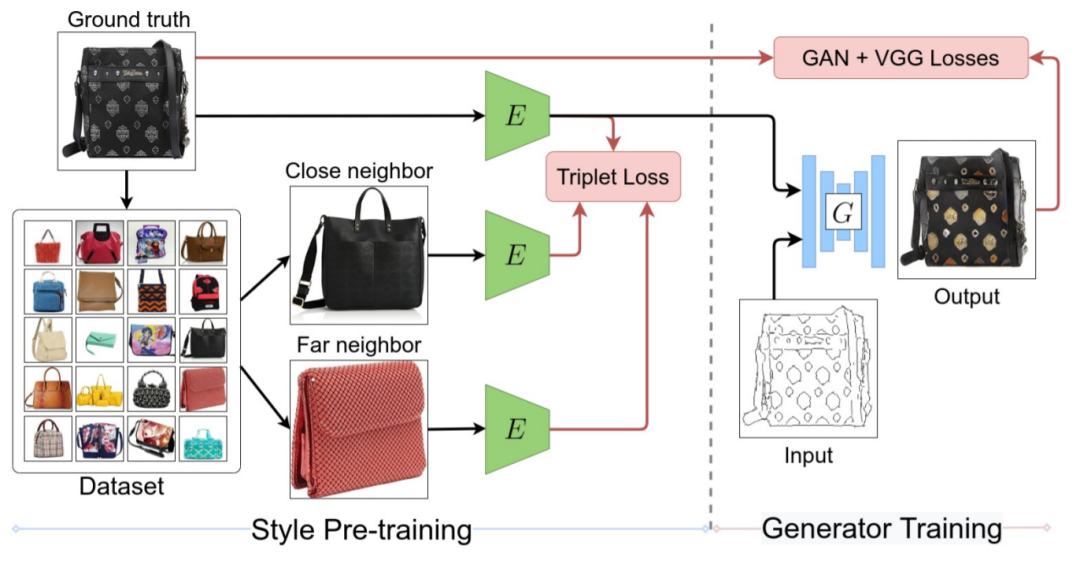
49、StEP: Style-based Encoder Pre-training for Multi-modal Image Synthesis

提出一种多模态图像转换的新方法,解决输入域和输出域之间的一对多关系。本文预训练通用风格编码器,学习从任意域到低维风格潜在空间的图像特征嵌入。与以前的多模 I2I 转换传统方法相比,学习到的潜在空间优点是:首先,它不依赖于目标数据集,并且可以很好地跨多个域泛化;其次,它学习了一个更强大和更具表现力的潜在空间,提高了风格捕捉和迁移的保真度;预训练还简化了训练目标并加快训练速度。
此外,本文详细研究了不同损失项对多模态 I2I 转换任务的贡献,并提出一种简单的VAE替代方案,以实现从不受约束的潜在空间采样。最后,在六个基准测试中取得了当前最好的结果。其训练目标简单,仅包括 GAN 损失和重建损失。
 二十一、行人重识别
二十一、行人重识别50、 Joint Generative and Contrastive Learning for Unsupervised Person Re-identification

- 最近的自监督对比学习通过从输入的不同视图(转换版本)中学习不变性,为无监督行人重识别 (ReID) 提供了一种有效的方法。本文将生成对抗网络 (GAN) 和对比学习模块合并到一个联合训练框架中,GAN 为对比学习提供在线数据增强,对比模块学习视图不变特征以进行生成。在这种情况下,提出一个基于网格的视图生成器和一种视图不变损失,以促进原始视图和生成视图之间的对比学习。实验结果表明,方法在几个大规模 ReID 数据集上的无监督和无监督域自适应设置下均优于最先进的方法。源代码和模型:https://github.com/chenhao2345/GCL
51、 Single-Shot Freestyle Dance Reenactment


- 源舞者和目标人之间的运动迁移任务是姿势迁移问题的一个特例,其中目标人根据舞者的动作改变他们的姿势。这项工作提出一种新方法,可通过任意视频序列重新激活单个图像。该方法结合了三个网络:分割映射网络、帧渲染网络、人脸细化网络。通过将此任务分为三个阶段,能获得逼真帧序列,捕捉自然运动和外观。
52、 Scene-aware Generative Network for Human Motion Synthesis

- 人体运动合成通常在两个方面受到限制:1) 专注于姿势,而将位置运动抛在脑后,2) 忽略环境对人体运动的影响。本文考虑场景和人体运动之间的相互作用。考虑到人体运动的不确定性,将此任务制定为生成任务,其目标是生成以场景和人体初始位置为条件的合理人体运动。
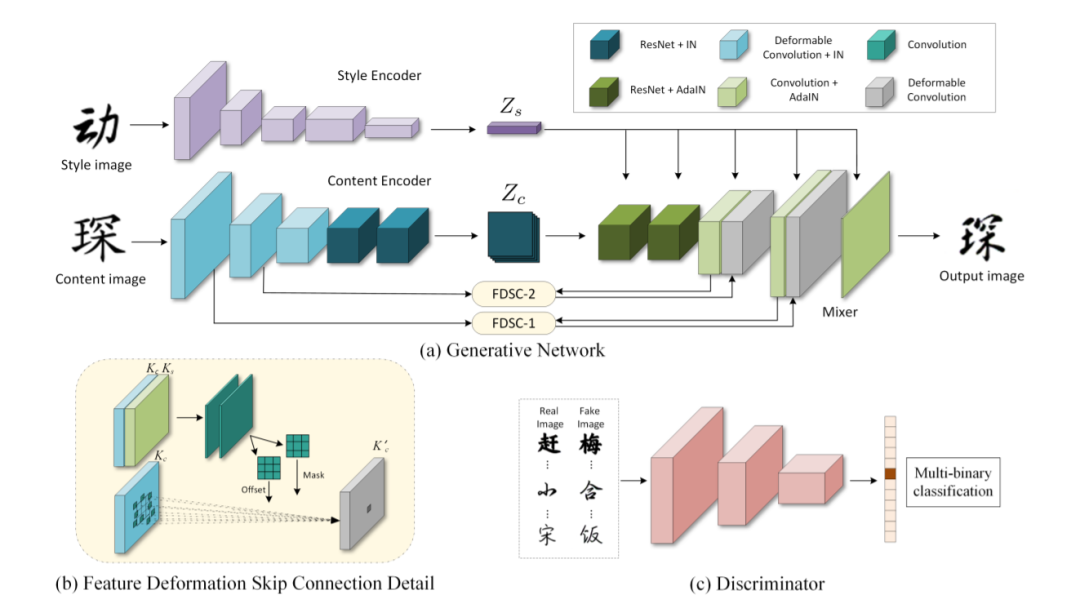
53、DG-Font: Deformable Generative Networks for Unsupervised Font Generation

字体生成是一个具有挑战性的问题,然而现有的字体生成方法通常是在监督学习中。它们需要大量成对的数据,这是劳动密集型的,收集起来很昂贵。此外,常见的图像到图像转换模型通常将风格定义为纹理和颜色的集合,不能直接应用于字体生成。
本文提出用于无监督字体生成(DGFont)的新型可变形生成网络。源代码:https://github.com/ecnuycxie/DG-Font
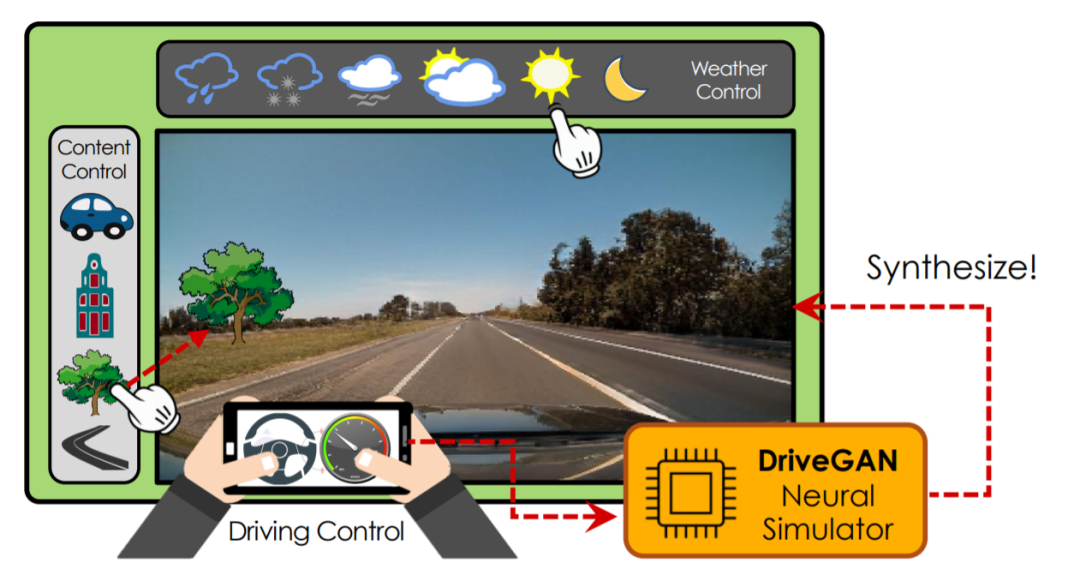
 二十四、仿真
二十四、仿真54、DriveGAN: Towards a Controllable High-Quality Neural Simulation

- 仿真对训练和验证机器人系统至关重要。这项工作目标是通过观察无标签的帧序列及其相关动作,学习直接在像素空间中模拟动态环境。
 二十五、医学图像
二十五、医学图像55、GAN-Based Data Augmentation and Anonymization for Skin-Lesion Analysis: A Critical Review

- 缺乏训练样本仍是皮肤病变分析的主要挑战之一。通过合成与真实图像无法区分的样本,生成对抗网络 (GAN) 似乎是缓解该问题的诱人替代方案。但本文作者更偏向于一种质疑批判的态度,认为由于与 GAN 使用相关的成本和风险,这些结果表明在将其用于医疗应用时要谨慎。
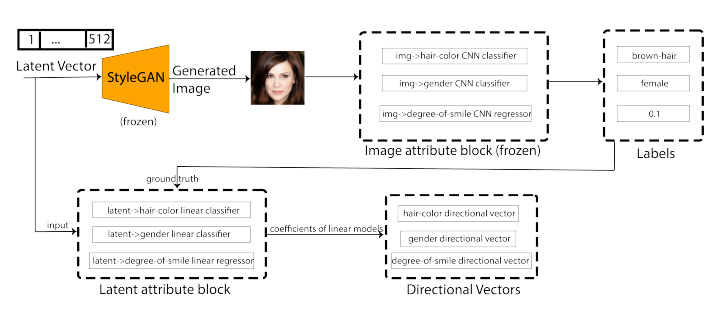
56,Directional GAN: A Novel Conditioning Strategy for Generative Networks

图像是营销活动、网站和横幅的主要形式之一。这可能需要设计师花费大量时间来生成此类专业的内容。提出一种简单而新颖的调节策略,针对无条件图像生成任务训练的生成器生成给定语义属性的图像。
方法基于修改潜在向量,使用潜在空间中相关语义属性的方向向量,处理离散(二类、多类)的和连续的图像属性。
57,Image Generators with Conditionally-Independent Pixel Synthesis

现有的生成器网络一般都依赖空间卷积、或者自注意力模块,然后以由粗到细的方式逐渐合成图像。
本文提出一种新的生成器架构,其中每个像素的颜色值是根据随机潜在向量的值和该像素的坐标独立计算的,在合成过程中不涉及跨像素传播信息的空间卷积或类似操作。
58,Efficient Feature Transformations for Discriminative and Generative Continual Learning

随神经网络越来越多地应用于实际中,解决数据分布差异、偏移和序列任务学习等问题、不会“遗忘”至关重要。通过增加模型容量来学习新任务,同时避免灾难性遗忘,但可能很耗算力。
基于连续学习提出一种特征图转换策略,为学习新任务提供了更好的灵活性,而这只需在基础架构中添加最少的参数即可实现。
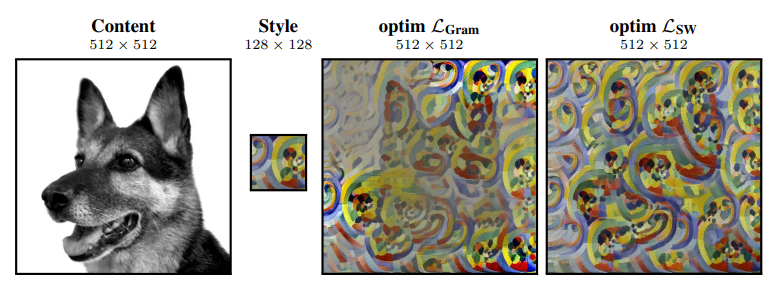
59,A Sliced Wasserstein Loss for Neural Texture Synthesis
在风格迁移或者GAN里,经常通过以目标分类识别任务而优化好的网络(例如 VGG-19),利用其提取特征激活,从而获取统计数据来计算纹理损失;其本质数学问题是测量特征空间中两个分布之间的距离。Gram-matrix loss 是这个问题的普遍近似,但它有一些缺点。
本文推广Sliced Wasserstein Distance,实现简单,效果更好。
60,Regularizing Generative Adversarial Networks under Limited Data

- GAN模型依赖大量的训练数据,这项工作提出一种在有限数据上训练鲁棒 GAN 模型的正则化方法。在理论上展示了正则化损失和称为 LeCam-divergence 的 f-divergence 之间的联系,它在有限的训练数据下更加稳健。https://github.com/google/lecam-gan
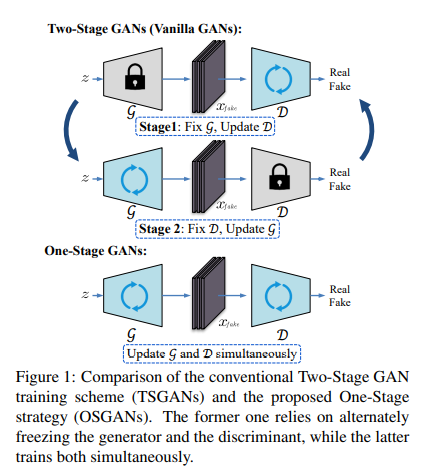
61,Training Generative Adversarial Networks in One Stage
生成对抗网络 (GAN) 有着繁琐的训练过程,生成器和判别器交替更新。本文研究仅在一个阶段就可以有效地训练 GAN。
基于生成器和判别器的对抗性损失,将 GAN 分为两类,对称 GAN 和非对称 GAN,并引入了一种新的梯度分解方法来统一这两者,能够在一个阶段训练这两个类,减轻训练难度。
62,Posterior Promoted GAN with Distribution Discriminator for Unsupervised Image Synthesis

- 本文研究者认为生成器中需要有足够的关于真实数据分布的信息,这是GAN生成能力的关键点。但目前GAN及其变体缺乏这一点,导致训练过程脆弱。
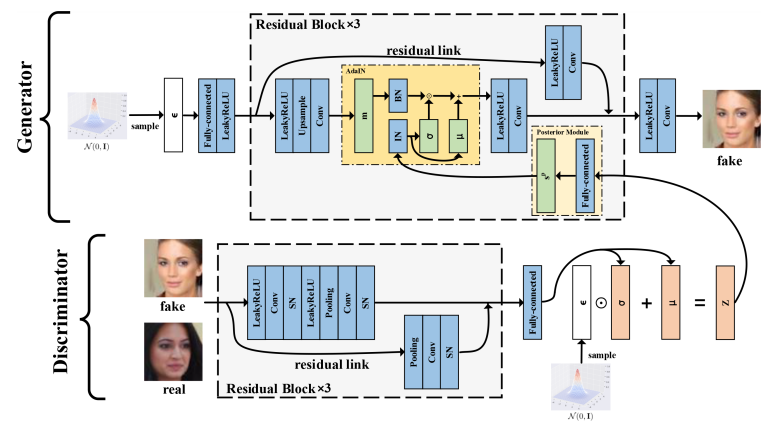
- 本文提出了一种新的 GAN 变体,即Posterior Promoted GAN(P2GAN),它使用判别器产生的后验分布中的真实信息来提升生成器。与 GAN 的其他变体不同,判别器将图像映射到多元高斯分布并提取真实信息;生成器使用 AdaIN 后的真实信息和潜码。实验结果表明,P2GAN 在无监督图像合成方面取得了与GAN最先进的变体相当的结果。
63、Adversarial Generation of Continuous Images

在大多数现有的学习系统中,图像通常被视为二维像素阵列。然而,在另一种越来越流行的范式中,2D 图像被表示为隐式神经表示 ( implicit neural representation,INR):一种根据其 (x, y) 坐标预测 RGB 像素值的MLP。本文提出两种基于INR的图像解码器技术:分解乘法调制和多尺度INR,并用它们构建最先进的连续图像GAN。
提出的INR-GAN架构将连续图像生成器的性能提高了数倍,大大缩小了连续图像 GAN 与基于像素的 GAN 之间的差距。除此之外,探索了基于INR的解码器的几个令人兴奋特性,如开箱即用的超分辨率、有意义的图像空间插值、低分辨率图像的加速推理、图像边界外推能力等
https://universome.github.io/inr-gan
64,Partition-Guided GANs

尽管生成对抗网络 (GAN) 取得了成功,但它们的训练仍存在几个众所周知的问题,包括模式坍塌等困难。
本文将学习复杂高维分布的任务分解为更简单的子任务,支持更多样化的样本生成。方案设计了一个分区器,将生成空间分成更小的区域,每个区域都有更简单的分布,并为每个分区训练不同的生成器。这是以无监督的方式完成的,不需要任何标签。
为此,为空间分区器制定了两个所需的损失标准,以帮助训练混合生成器:1) 生成连接的分区;2) 提供分区和数据样本之间距离的代理,以及减少该距离的方向。这也是为了避免从不存在数据密度的地方生成样本,并且还通过为生成器提供额外的方向来促进训练。
65,Positional Encoding as Spatial Inductive Bias in GANs

尽管有效的感受野有限,但SinGAN在学习内部结构分布方面表现出令人印象深刻的能力。这项工作以 SinGAN 和 StyleGAN2 为例,表明这种生成能力在很大程度上是由在生成器中使用零填充(zero padding)时隐式位置编码带来的。这种位置编码对于生成高保真图像是必不可少的。在其他生成式架构(例如 DCGAN 和 PGGAN)中也观察到了相同的现象。
本文进一步表明,零填充会导致不平衡的空间偏差、位置间关系模糊。为提供更好的空间归纳偏差,研究了替代位置编码并分析了它们影响。
 二十七、结合VAE
二十七、结合VAE66,Dual Contradistinctive Generative Autoencoder

提出一种具有双重对比损失的生成自动编码器,本文将模型命名为“双对比生成自编码器 (DC-VAE)”,融合了实例级判别性损失(为重建/合成维持实例级保真度)与集合级对抗性损失。
DC-VAE在不同分辨率(包括 32×32、64×64、128×128 和 512×512)上的广泛实验结果表明,显著提高基线 VAE 的定性和定量性能。DC-VAE 是一种通用的 VAE 模型,适用于视觉和机器学习中各种下游任务。
67,Soft-IntroVAE: Analyzing and Improving the Introspective Variational Autoencoder

- 最近推出的变分自动编码器IntroVAE展示了出色的图像生成能力,IntroVAE 的主要思想是对抗性地训练 VAE,使用 VAE 编码器来区分生成的数据样本和真实的数据样本。这项工作提出SoftIntroVAE,一种改进的 IntroVAE,它在生成的样本上用平滑的指数损失替换了铰链损失项。这一变化显著提高了训练的稳定性,也使得对完整算法的理论分析成为可能。
- 代码:https://taldatech.github.io/soft-introvae-web

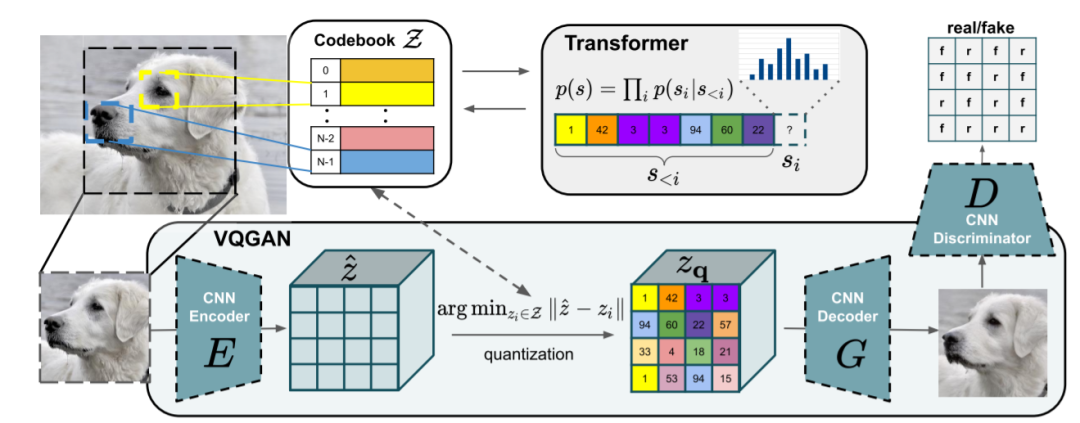
68,Taming Transformers for High-Resolution Image Synthesis

transformers在学习序列数据上的远程交互是有优越性的,在各种任务上显示出最先进的效果。与 CNN 相比,它们可能不会优先考虑局部交互的归纳偏差。本文展示了如何将 CNN 的归纳偏置有效性与 Transformer 的表达能力相结合,建模高分辨率图像。
https://git.io/JLlvY
 二十九、模型压缩
二十九、模型压缩69,Anycost GANs for Interactive Image Synthesis and Editing

- 大型生成器(例如 StyleGAN2)的计算成本很高,在边缘设备上运行一次常需几秒钟时间,阻碍交互式体验。本文提出Anycost GAN 用于交互式自然图像编辑。Anycost GAN支持弹性分辨率和通道以多种速度更快地生成图像。
- https://github.com/mit-han-lab/anycost-gan
70,Content-Aware GAN Compression

- 直接应用通用常见的压缩方法在 GAN 上,结果往往不佳。本文提出无条件 GAN 压缩的新方法,首先介绍专门用于无条件 GAN 的有效通道修剪和知识蒸馏方案。然后,提出内容感知方法来指导修剪和蒸馏的过程。与全尺寸模型StyleGAN2相比,FLOP减少了11倍,图像质量损失在视觉上可以忽略不计。
 三十、散焦模糊检测
三十、散焦模糊检测71,Self-generated Defocus Blur Detection via Dual Adversarial Discriminators

- 全监督离焦模糊检测 (defocus blur detection,DBD) 模型显著提高了性能,但训练这种深度模型需大量的像素级手动标注,非常耗时、易错。针对这个问题,本文致力于在不使用任何像素级标注的情况下训练深度 DBD 模型。

在不影响全模糊图像/全清晰图像的判断的情况下,可以任意粘贴散焦模糊区域/对焦清晰区域到给定的真实全模糊图像/全清晰图像。具体来说,以对抗双重判别器 Dc 和 Db 的对抗方式训练生成器 G。G 学习生成 DBD 掩码,通过将聚焦区域和未聚焦区域从相应的源图像复制到另一个完整清晰图像和完整模糊图像,从而生成复合清晰图像和复合模糊图像。
https://github.com/shangcai1/SG
72,GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution

- 预训练的生成对抗网络 (GAN),例如StyleGAN,可以用作潜码库来提高图像超分辨率 (SR) 的恢复质量。虽然大多数现有的 SR 方法都试图通过对抗性损失的学习来生成逼真的纹理,但本文方法Generative LatEnt bANk (GLEAN) 通过直接利用封装在预训练 GAN 中的丰富多样的先验超越了现有方法。与流行的 GAN 逆映射方法需要在运行时进行昂贵的图像特定优化不同,方法只需一次前向即可生成放大图像。
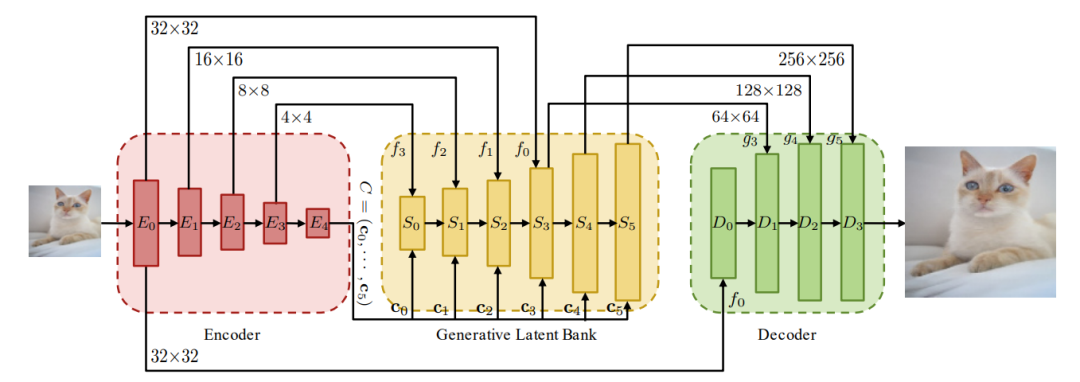
73,GAN Prior Embedded Network for Blind Face Restoration in the Wild

严重退化的人脸图像中恢复清晰(Blind face restoration ,BFR)极具挑战。现有的基于生成对抗网络 (GAN) 的方法往往会过度平滑。
这项工作首先学习用于生成高质量人脸图像的GAN,并将其嵌入到U形DNN 作为先验解码器,然后用一组合成的低质量人脸图像微调。所提出的GAN先验嵌入网络 (GPEN) 易于实现,并且可以生成视觉上逼真的结果。源代码和模型https://github.com/yangxy/GPEN

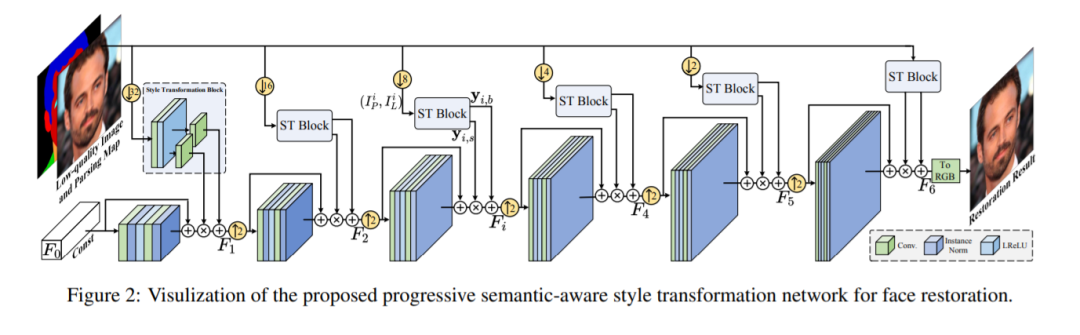
74,Progressive Semantic-Aware Style Transformation for Blind Face Restoration

人脸恢复在人脸图像处理中很重要,通常很难将低质量 (LQ) 人脸图像转换生成高质量 (HQ) 结果。本文提出一种渐进式语义感知风格转换框架PSFR-GAN,用于人脸恢复。
与以前的方法使用编码器解码器不同,本文基于一种多尺度渐进、语义感知的风格转换过程。给定一对LQ人脸图像及其对应的解析图,首先生成输入的多尺度金字塔,然后从粗到细逐步调制不同尺度的特征。与之前的网络相比,PSFR-GAN 充分利用了来自不同尺度输入对的语义(解析图)和像素(LQ 图像)空间信息。
 三十二、图像去雨
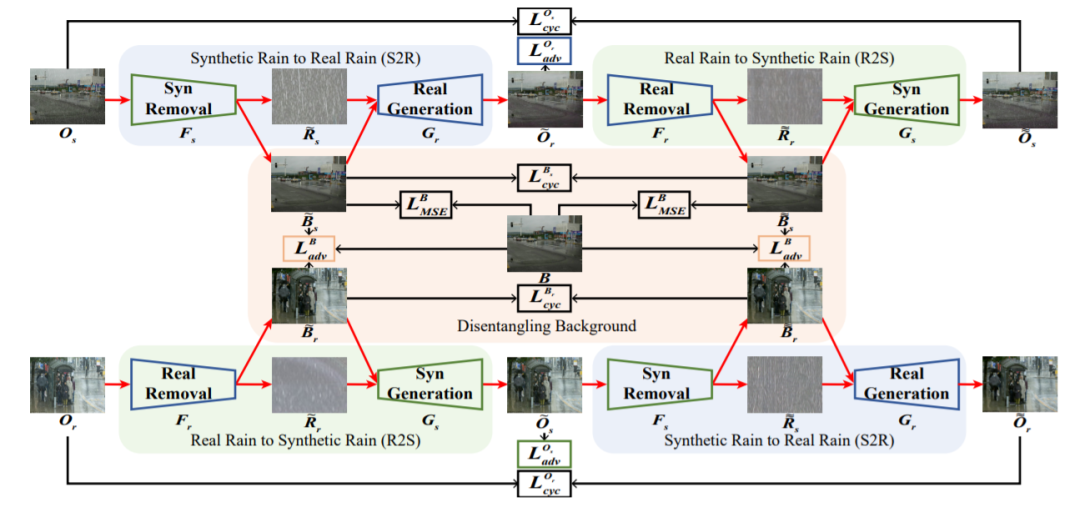
三十二、图像去雨75,Closing the Loop: Joint Rain Generation and Removal via Disentangled Image Translation

基于深度学习的图像去雨方法通常依赖于成对的清晰图像和模拟的雨天图像。然而,由于简化合成雨与复杂真实雨之间的巨大差距,这些方法在面对真实雨时会出现性能下降。
这项工作认为雨水的产生和去除是同一枚硬币的两个方面,应该紧密耦合。提出在统一的、解耦的图像转换框架内共同学习真实的雨生成和去除过程。具体来说,提出一个双向解耦转换网络,其中每个单向网络包含两个循环,分别用于真实和合成雨图像的生成和去除。
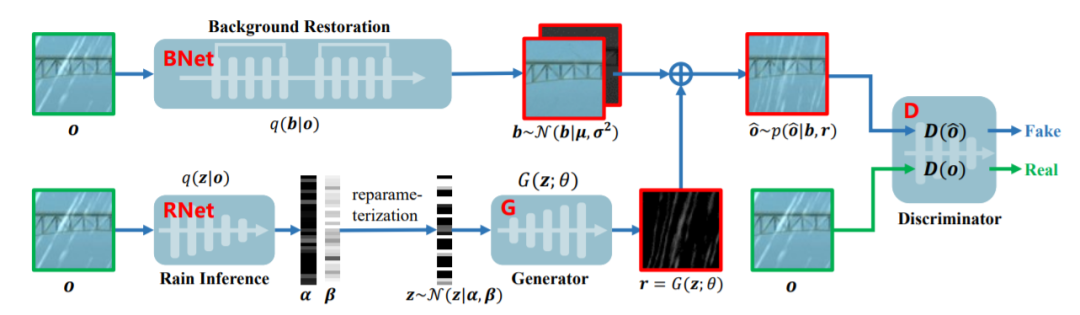
76,From Rain Generation to Rain Removal

对于单图像去雨 (single image rain removal,SIRR) 任务,基于深度学习 (DL) 的方法的性能受去雨模型和训练数据集的影响。本文探索一种有效的合成雨天图像的方法,从训练数据集的角度处理 SIRR 任务。
具体来说,为雨天图像构建了一个完整的贝叶斯生成模型,采用变分推理以数据驱动的方式近似预测雨天图像的统计分布。通过学习生成器,自动充分生成多样化的训练对,有效丰富现有基准数据集。用户研究定性和定量评估生成的雨天图像真实性。综合实验证明,所提出模型可提取复杂的降雨分布,有助于提高当前单幅图像去雨性能,且在很大程度上放宽SIRR任务对大训练样本预收集的要求。代码https://github.com/hongwang01/VRGNet
 三十三、图像修复
三十三、图像修复77,Generating Diverse Structure for Image Inpainting With Hierarchical VQ-VAE

给定没有额外约束、不完整的图像,图像修复可能有多种修复方案。但这些方法难以确保质量,例如可能有扭曲的结构或模糊的纹理。
提出一个两阶段模型,第一阶段生成多个粗略结果,每个结果具有不同的结构;第二阶段通过增加纹理分别细化每个粗略结果。所提出的模型受变分自动编码器 (VQ-VAE) 启发,其分层架构将结构和纹理信息分开。
代码:https://github.com/USTC- JialunPeng/ Diverse-Structure-Inpainting

78,Image Inpainting with External-internal Learning and Monochromic Bottleneck

提出了一种所谓的两阶段、外部-内部修复方案。外部学习,重建单色空间中缺失的结构和细节;内部学习,针对单图像内部的颜色恢复,采用渐进式学习策略。
源代码 https://github.com/Tengfei-Wang/external-internal-inpainting

79,Image Inpainting Guided by Coherence Priors of Semantics and Textures

- 本文引入语义和纹理一致性先验,采用多尺度联合优化对相关性先验进行建模,然后以粗到细的方式交错优化图像修复和语义分割。设计了语义注意力传播 (Semantic-Wise Attention Propagation,SWAP) 模块,探索非局部语义连贯性来优化跨尺度的图像纹理,有效减轻纹理混淆。还提出了两个损失来限制语义和修复图像在整体结构和详细纹理方面的一致性。

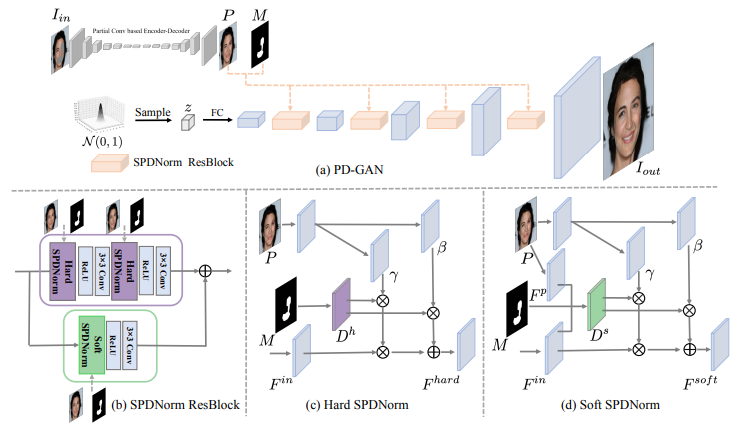
80,PD-GAN: Probabilistic Diverse GAN for Image Inpainting

提出PD-GAN,一种用于图像多样化修复的GAN。给定有任意空洞区域的输入图像,PD-GAN会产生具有多样化、视觉逼真的多个修复结果。
PD-GAN基于随机噪声生成图像的GAN,在生成过程中,从粗到细调制输入到深层的特征。在修复时,缺失边界附近的像素相较于缺失区域中间,更具确定性。而对于缺失较内部区域,有更多自由发挥空间。提出空间概率多样性归一化(SPDNorm),以模拟生成以上下文信息为条件的像素的概率。
代码可在 https://github.com/KumapowerLIU/PD-GAN
 三十四、图像拼接融合
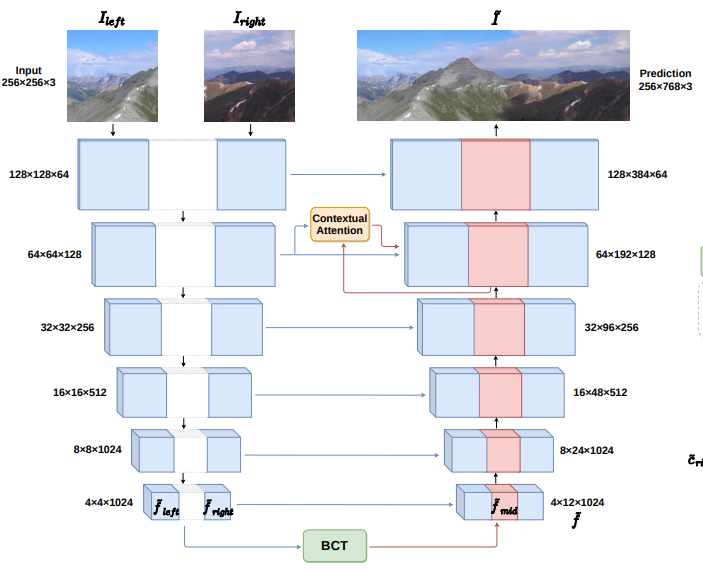
三十四、图像拼接融合81,Bridging the Visual Gap: Wide-Range Image Blending

本文提出图像处理中的一个新应用,即“宽度上的图像融合”(wide-range image blending),旨在通过为它们之间的中间区域生成新的图像内容,将两张不同的输入照片平滑地合并成一张全景图。
尽管此类问题与图像修复、图像修复和图像混合等主题密切相关,但类似的方法无法解决。为此,提出了一种双向内容传输模块,通过循环神经网络对中间区域的特征表示进行条件预测。除了在混合过程中确保空间和语义的一致性外,还在提出的方法中采用了上下文注意机制以及对抗性学习方案来提高合成全景的视觉质量。
 三十五、图像阴影
三十五、图像阴影82,Towards High Fidelity Face Relighting with Realistic Shadows

现有的人脸补光(Face Relighting)方法面临两个难点:保持被摄对象的局部面部细节和准确去除和合成重打光图像中的阴影。
本文方法学习预测具有所需照明的源图像和目标图像之间的比率图像,在保持局部面部细节的同时重新进行补光。训练期间,模型还通过用估计的阴影蒙版来强调高对比度阴影边界来准确修改阴影。

83,From Shadow Generation to Shadow Removal

- 阴影去除旨在恢复阴影区域中的图像内容。本文提出G2RShadowNet,通过仅用一组阴影图像及其相应的阴影掩模进行训练,利用阴影生成进行弱监督阴影去除。

84,Intrinsic Image Harmonization

不同的图像进行合成时,不可避免地会遇到“不协调自然”的问题,这主要是由于来自具有不同表面和光线的两个不同图像的前景和背景不兼容引起的。
本文寻求通过反射和照明的可分离协调来解决图像协调任务,即内在图像协调。方法基于自动编码器,将合成图像分解为反射和照明,以进一步单独协调。
代码和数据集 https://github.com/zhenglab/IntrinsicHarmony

85,Region-aware Adaptive Instance Normalization for Image Harmonization

图像组合在照片编辑中扮演着常见、重要的角色。要获得逼真的组合图像,必须调整前景的外观和视觉风格以与背景兼容。现有的用于协调合成图像的深度学习方法直接学习从合成到真实图像的图像映射网络,而没有明确探索背景和前景图像之间的视觉风格一致性。
为了确保前景和背景之间的视觉风格一致性,本文将图像协调视为风格迁移问题。提出一个简单有效的区域感知自适应实例归一化 (RAIN) 模块,从背景中明确地制定视觉风格,并自适应地将它们应用于前景。
代码可在 https://github.com/junleen/RainNe 获得

86,Repurposing GANs for One-shot Semantic Part Segmentation

提出一种基于 GAN 的简单有效的语义分割方法,只需要一个标签示例和一个未标记的数据集。关键思想是利用经过训练的 GAN 从输入图像中提取像素级表示,并将其用作分割网络的特征向量。实验表明,这种 GAN 衍生的表征具有极佳的区分度,可以产生令人惊讶的效果,与使用更多标签训练的监督方法相媲美。
https://RepurposeGANs.github.io/
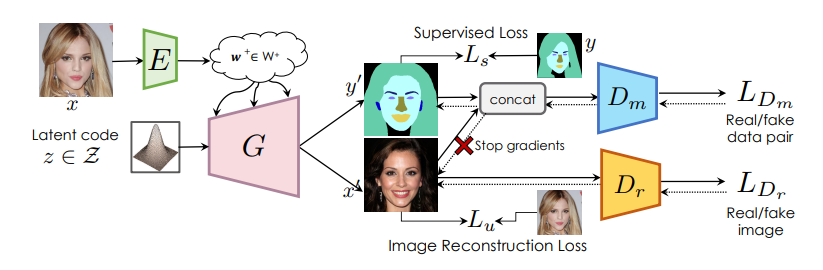
87,Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization

用有限的标记数据训练深度网络,同时实现强大的泛化能力,是半监督学习的目标。针对像素标签预测的分割任务,本文学习一个生成对抗网络捕获联合图像标签分布,它使用大量未标记图像进行有效训练,而仅辅以少量标记图像。
在StyleGAN2上增加一个标签合成分支,测试时,图像通过编码器和优化,将目标图像嵌入到潜在空间中表示,然后推断生成标签。在医学图像分割和人脸分割任务中表现良好,例如医学成像中CT到MRI,真实人脸照片转换到绘画,雕塑甚至卡通和动物的脸。
https://nvtlabs.github.io/semanticGAN/
 三十八、图像分类
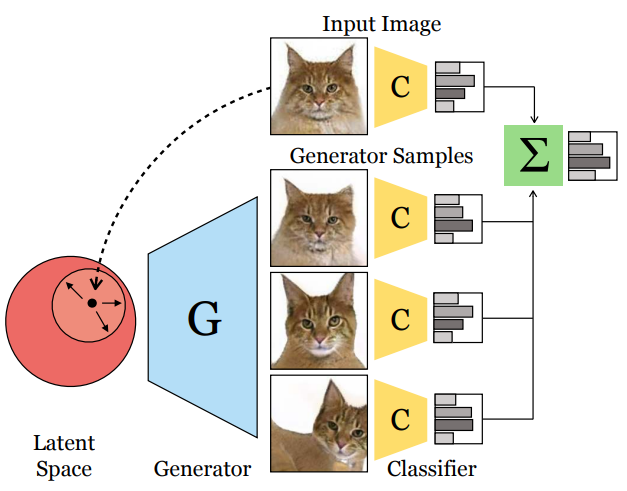
三十八、图像分类88,Ensembling with Deep Generative Views

最近的生成模型可以合成真实图像,本文调查这些合成图像是否可以应用于真实图像以有益于下游分析任务,例如图像分类。
使用预训练的生成器,首先找到与给定的真实输入图像对应的潜码,并对其做一定扰动,产生图像的自然变化,然后在测试时将它们组合在一起。实验使用的是StyleGAN2作为生成增强的来源,并在涉及人脸属性、猫脸和汽车的分类任务上研究这种设置。
本文发现几个设计决策决定了这个过程的作用;扰动、增强和原始图像之间的加权以及在合成图像上训练分类器都会影响结果。虽然使用基于 GAN 的增强在测试时集成可以提供一些小的改进,但瓶颈是 GAN 重建效率和准确性,以及分类器对 GAN 生成图像中的伪影的敏感性。
 三十九、图像转换
三十九、图像转换89,Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation

提出一个通用的图像转换框架pixel2style2pixel(pSp)。pSp框架基于编码器网络,直接生成一系列风格向量,然后将它们输入到预训练的StyleGAN生成器中,从而扩展成“W+潜在空间”。
编码器可以直接将真实图像嵌入到W+,而无需其它优化。利用编码器直接解决图像转换任务,如此一来图像转换任务可定义为:从某些输入域到潜在域的编码问题。
此前的方法中,StyleGAN编码器一般是“先反转(图像到潜码),后编辑”。而pSp不要求输入图像在StyleGAN域中进行特征表示,也可以处理各种任务。由于不需要对抗,极大地简化了训练过程,在没有“图像对(源图像,目标图像)”的严格标签数据下提供更好的支持,并且通过风格的重采样可以支持多模式合成。
实验表明,pSp在各种图像转换任务中也表现出不俗的潜力。即使与专为某种任务而设计的最新解决方案相比,例如人脸转换任务,pSp也表现极佳。
代码:https://github.com/eladrich/pixel2style2pixel

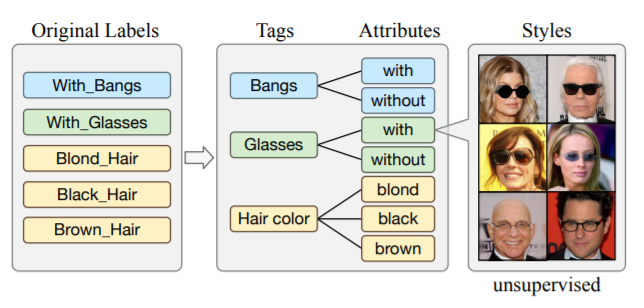
90,Image-to-image Translation via Hierarchical Style Disentanglement

近来,图像转换任务在多标签(不同标签为条件)和多风格的生成任务上都取得了不错进展。
但由于标签不具备独立性、排他性,图像转换结果b并不能完全精准可控。本文提出分层风格分离(HiSD)来解决此问题。具体来说,将标签组织成分层的树状结构,其中独立的标签,排他的属性和解耦的风格从上到下进行分配。相应地,设计一种新的转换过程以适应上述结构,确定可控转换的风格。在CelebA-HQ数据集上的定性和定量实验都证明HiSD的能力。
代码:https://github.com/imlixinyang/HiSD
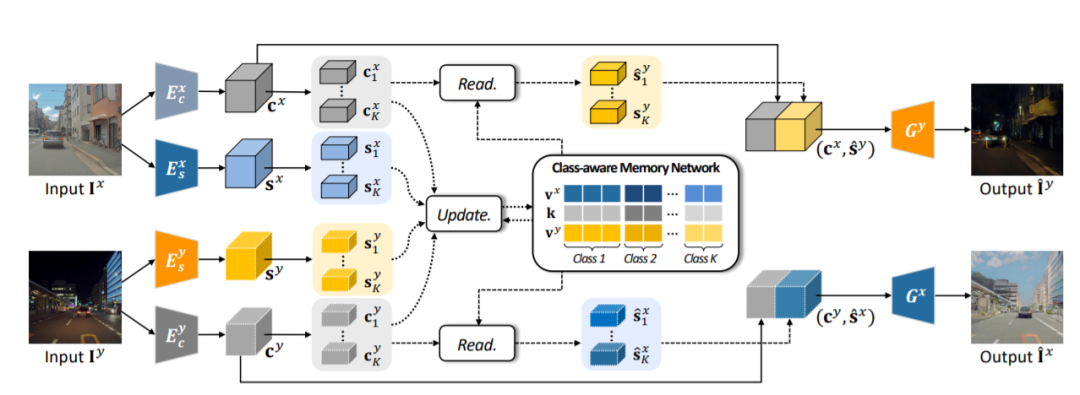
91,Memory-guided Unsupervised Image-to-image Translation

为实例级别的图像转换问题提供了一种新的无监督框架。尽管近期一些方法通过融进额外的物体标签可以取得进一步的效果,但通常无法处理多个不同对象的的情形。主要原因是,在推理过程中,这些算法将全局整体的风格应用于整幅图像,而没有考虑实例个体与背景之间或个体内部间的风格差异。
为此,提出一个类别感知的内存网络,可以显示地明确说明局部风格变化。引入一组具有读/更新操作的键值存储结构,以记录类别的风格变化,且在测试阶段无需目标检测器就可以访问它们。
“键”存储的是与域无关的内容表征,用于分配内存,而“值”则编码了域特定的风格表征。还提出一种特征对比损失,以增强内存的判别能力。实验表明,通过合并内存,可以跨域迁移类别感知的、准确的风格表征。
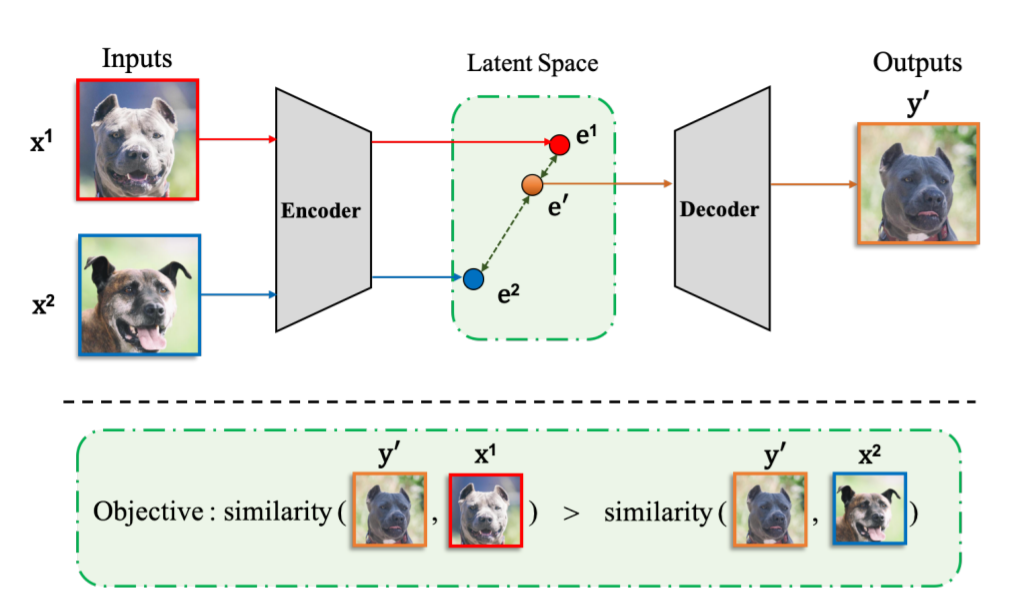
92,ReMix: Towards Image-to-Image Translation with Limited Data

当可用的训练数据是有限的时候,基于生成对抗网络(GAN)的图像到图像(I2I)转换方法通常有过拟合的现象发生。
这项工作提出一种数据增强方法(ReMix)来解决此问题:在特征级别上对训练样本进行插值,并根据样本之间的感知关系提出一种新的内容损失。生成器学习转换中间样本,而不是记住训练集,从而迫使判别器有更好的泛化能力。
只需稍作修改,即可轻松将ReMix方法合并到现有GAN模型中。在众多任务上的实验结果表明,配备ReMix方法的GAN模型效果更佳。
93,Spatially-Adaptive Pixelwise Networks for Fast Image Translation

介绍了一种新的生成器网络结构,通过将其设计为全分辨率图像的极轻量级网络,以实现快速高效的高分辨率图像转换。
通过简单的仿射变换和非线性组合的操作,将每个像素都独立于其它像素去进行处理。主要采取三个关键步骤,使这种方法看似简单但极具表现力。
首先,逐像素网络的参数在空间上是变化的,因此与简单的1×1卷积相比,它们可以表示更广泛的函数类。其次,这些参数是由快速卷积网络预测的,该网络处理输入的低分辨率表示。第三,通过拼接空间坐标的正弦编码来增强输入图像,为生成高质量的图像内容提供了有效的归纳偏置(inductive bias)。
实验表明模型比此前的方法快达18倍,同时在不同的图像分辨率和转换中也有着极具竞争力的视觉质量。
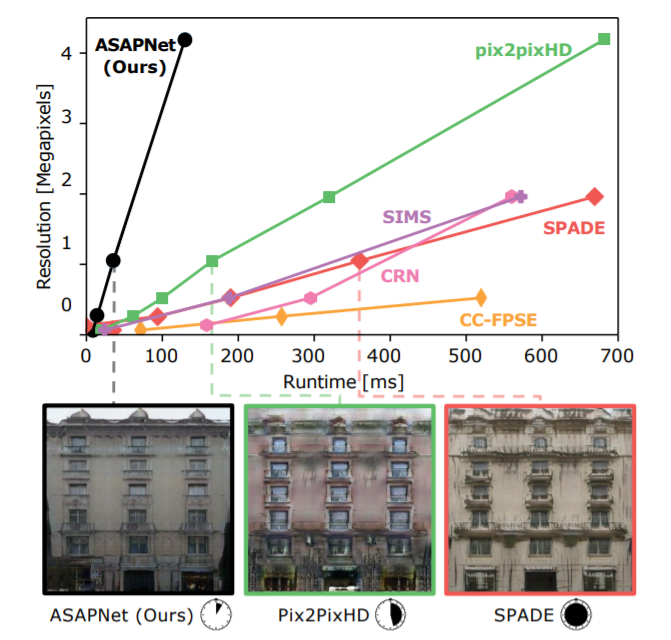
94,The Spatially-Correlative Loss for Various Image Translation Tasks

提出一种空间相关损失,简单有效,保持场景结构的一致性,同时在未配对的图像到图像 (I2I) 转换任务中较好支持大幅的外观变化。此前方法通过像素级循环一致性或特征级匹配损失,但缺陷是无法完成跨度大的域间转换。
代码https://github.com/lyndonzheng/F-LSeSim

95,CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation

- 提出跨域图像的全分辨率学习应用于图像转换任务。采用分层策略,使用粗级的对应关系来指导细级。在每个层次结构中,可通过PatchMatch有效地计算对应关系,在每次迭代中,ConvGRU模块用于细化当前,考虑更大的上下文和历史估计。它是可微且高效的,当与图像转换联合训练时,以无监督的方式建立全分辨率语义对应关系,促进转换质量。

96,BalaGAN: Cross-Modal Image Translation Between Imbalanced Domains

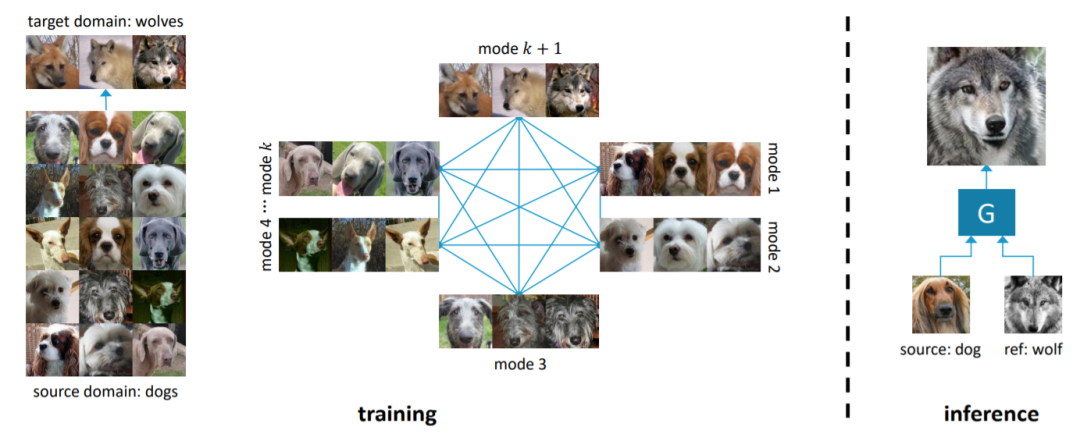
- 图像转换方法往往会面临数据域不平衡问题,例如其中一个域缺乏丰富性和多样性。本文提出新的无监督BalaGAN,专门用于解决域不平衡问题。针对两个不平衡域的图像转换问题,利用相对更丰富数据域的潜在模态转化为多类域的转换问题。在没有任何监督的情况下分析源域并学习将其分解为一组潜在模式或类。
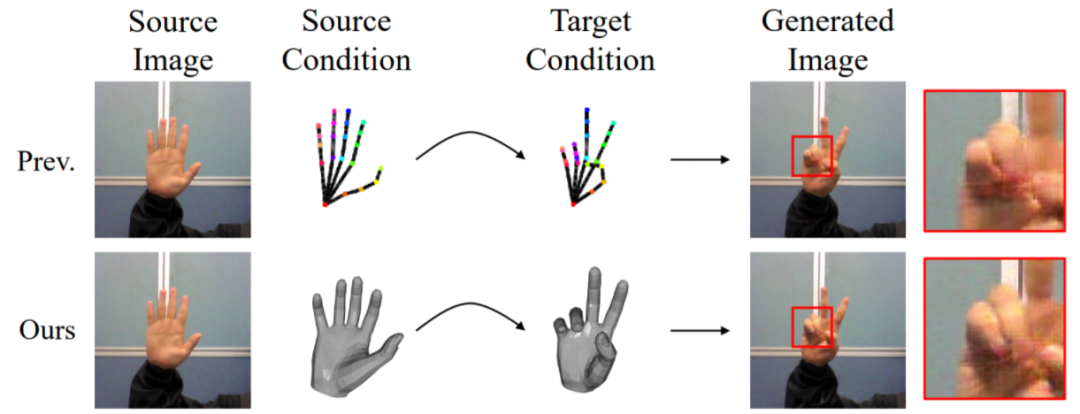
97,Model-Aware Gesture-to-Gesture Translation

- 手势到手势的转换是一个重要、有趣的问题,在许多应用中发挥着关键作用,例如手语制作。此任务涉及对源和目标手势之间映射的细粒度结构理解。本文提出一种新的模型感知手势转换方法。
98,Saliency-Guided Image Translation

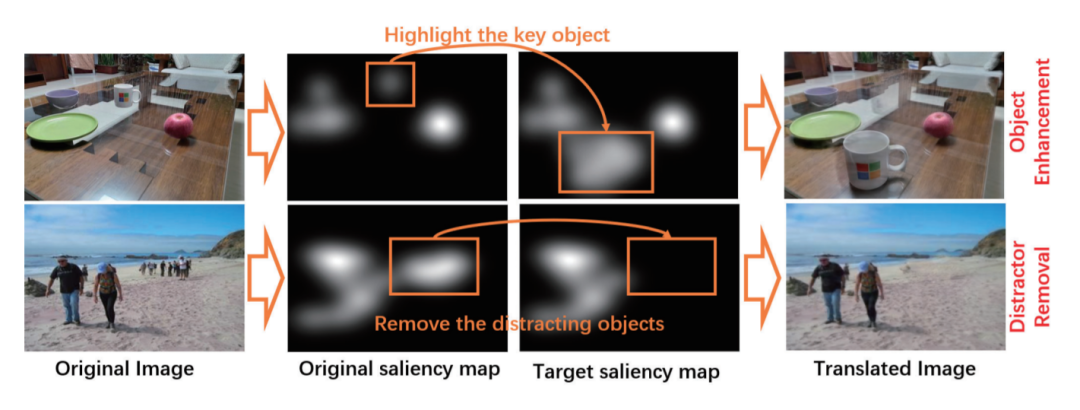
- 本文提出一种新的显著性引导的图像转换任务,其目标是基于用户指定的显著性图进行图像到图像的转换。为此,给定原始图像和目标显著性图,提出SalG-GAN,一种解耦的表示框架。
- 引入了基于显著性图的注意力模块作为一种特殊的注意力机制。此外,构建了一个合成数据集和一个带有标记视觉注意力的真实数据集,用于训练和评估SalG-GAN。
99,Teachers Do More Than Teach: Compressing Image-to-Image Models

生成对抗网络 (GAN) 在生成高保真图像方面取得巨大成功,但需要巨大的计算成本和内存使用。这项工作引入一个教师网络,提供一个搜索空间,除知识蒸馏外,还可以在其中找到有效的网络架构。压缩网络实现了与原始模型相似甚至更好的图像保真度(FID,mIoU),且大大降低计算成本
https://github.com/snap-research/CAT
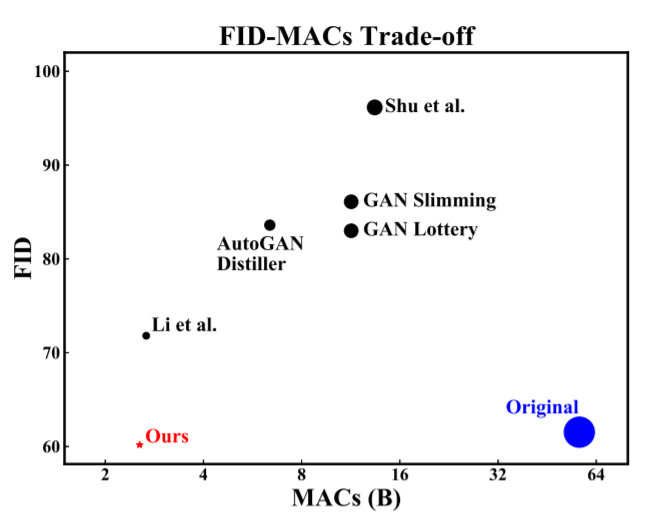
100,Not just Compete, but Collaborate: Local Image-to-Image Translation via Cooperative Mask Prediction

- 人脸属性编辑任务方面,生成对抗网络以及编码器-解码器架构已被广泛使用。然而因缺少标注图像,现有未配对数据集方法仍不能正确保留与属性无关的细节。
- 这项工作提出一种新颖直观的CAM一致性损失,提高了图像转换中的一致性。相比循环一致性损失,本文方法通过使用从判别器计算的Grad-CAM输出,使模型进一步保留与属性无关的区域。

101,Smoothing the Disentangled Latent Style Space for Unsupervised Image-to-Image Translation
对图像到图像 (I2I) 多域转换模型,通常也使用其语义插值结果的质量进行评估。然而,最先进的模型经常在插值过程中显示图像外观的突然变化,并且在跨域插值时通常表现不佳。
本文提出基于三个特定损失的新训练方法,有助于学习平滑且解耦开的潜在风格空间,其中:1)域内和域间插值对应于生成图像的逐渐变化2)在转换过程中更好地保留源图像的内容。
提出一种评估指标来正确衡量 I2I 转换模型的潜在风格空间的平滑度。方法可以插入现有的转换方法中,在不同数据集上大量实验表明,可以显著提高生成图像的质量和插值的自然渐变。
102,CoMoGAN: continuous model-guided image-to-image translation

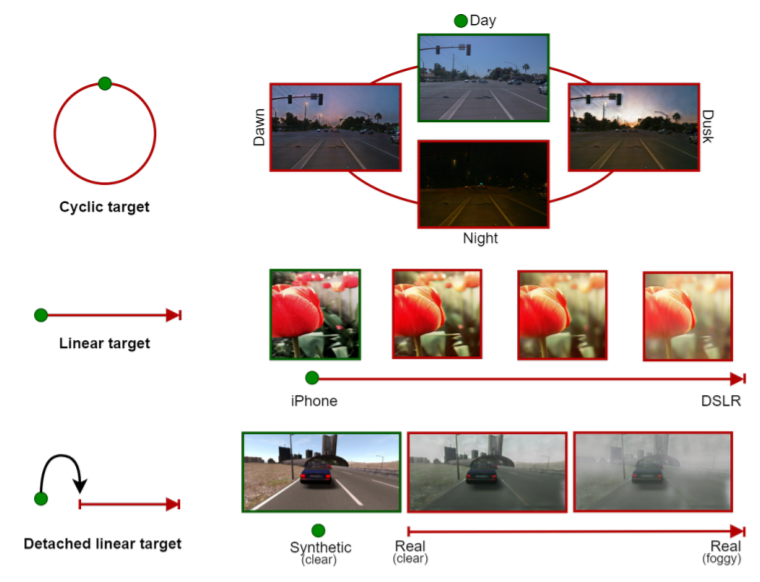
- 提出CoMoGAN,一个使用无监督目标数据学习非线性连续转换的图像转换算法,CoMoGAN 可以与任何 GAN backbone一起使用,代码 https://github.com/cv-rits/CoMoGAN
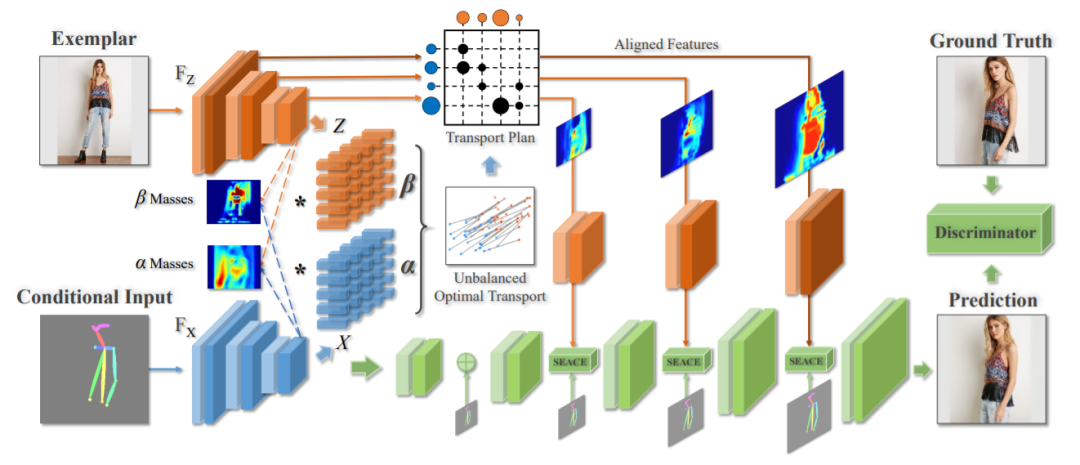
103,Unbalanced Feature Transport for Exemplar-based Image Translation

尽管 GAN 在具有不同条件输入(例如语义分割和边缘图)的图像转换方面取得巨大成功,但生成具有参考风格的高保真图像方面,仍是巨大挑战。
本文提出一个通用的图像转换框架,结合条件输入和风格示例之间特征对齐的最优传输,显著减轻了多对一特征匹配的约束,同时在条件输入和样本间建立准确的语义对应关系。
104,Unpaired Image-to-Image Translation via Latent Energy Transport

图像到图像的转换任务,旨在保留源内容,同时在两个视觉域之间转换到目标风格。大多数方法应用对抗学习,在计算上可能很昂贵且训练具有挑战性。本文提出,在预训练自动编码器的潜在空间中部署基于能量的模型 (EBM)。预训练自动编码器既可作为潜码提取器,也可图像重建,是第一个适用于1024×1024分辨率未配对图像转换的方法。
代码https://github.com/YangNaruto/latentenergy-transport
105,DECOR-GAN: 3D Shape Detailization by Conditional Refinement

- 介绍用于 3D 形状细节化的生成网络,风格化几何细节:条件3D细节化生成对抗网络DECOR-GAN。代码https://github.com/czq142857/DECOR-GAN

106,Inverting Generative Adversarial Renderer for Face Reconstruction

- 给定单目人脸图像作为输入,3D 人脸几何重建旨在恢复相应的 3D 人脸mesh。这项工作提出一种新的生成对抗渲染器 (GAR)。

107,Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement

- 引入GAN框架,用于从一张无约束的照片中数字化一个人3D 头像。

108,A 3D GAN for Improved Large-pose Facial Recognition
基于端到端的深度卷积神经网络进行人脸识别,依赖于大型人脸数据集。这需要大量类别(不同人或者身份)的人脸图像,且对每个人都需要各种各样的图像,如此网络才能适应类内差异,增加鲁棒性。
然而现实中很难获得这样的数据集,特别是那些包含不同姿势变化的数据集。生成对抗网络(GAN)由于具有生成逼真的合成图像的能力,因此提供了解决此问题的潜在方法。

- 但最近的研究表明,将姿势与个人身份特征分离的方法效果并不好。本文尝试将3D可变形模型合并到GAN的生成器中,生成人脸,并在不影响个人身份辨识度的情况下操纵姿势、照明和表情。所生成的数据用在CFP和CPLFW数据集上,可增强人脸识别模型的性能。
109,pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis

- 提出一种新生成模型,称为周期隐式生成对抗网络(π-GAN 或 pi-GAN),用于高质量的 3D 感知图像合成。

110,StylePeople: A Generative Model of Fullbody Human Avatars

- 提出一种新的全身人体数字化方法,从一张或几张图像中创建穿着打扮的数字人。项目代码 saic-violet.github.io/style-people
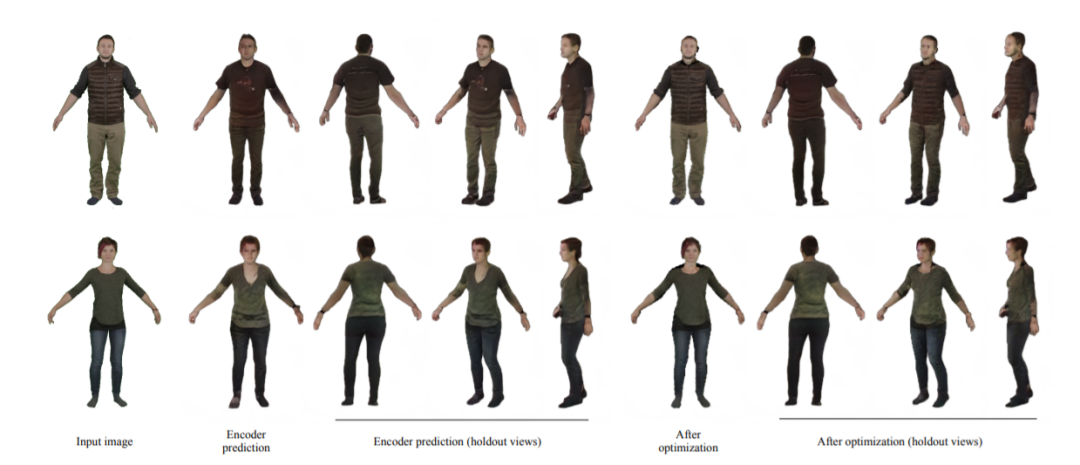
111,Unsupervised 3D Shape Completion through GAN Inversion

- 大多数 3D 形状补全方法严重依赖全监督方式。本文提出ShapeInversion,首次引入生成对抗网络 (GAN) 的逆映射来形状补全。

猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!