
「知识复盘」初中级前端值得收藏的正则表达式知识点扫盲


本文是思维导图学前端系列第二篇,主题是正则表达式。首先还是想说下我的出发点,之所以自己画一遍思维导图,是因为我整理的思维导图里加入了自己的理解,更容易记忆。之前也看过很多别人整理的思维导图,虽然有点拨之用,但是要想吸收个二三分营养却也是很难。
所以,建议本系列的读者在阅读文章之后,在时间允许的情况下,可以考虑自行整理知识点,便于更好地理解和吸收。
推荐下同系列文章:
「思维导图学前端」6k字一文搞懂Javascript对象,原型,继承[1]
很多前端新手在遇到正则表达式时都望而却步,我自己初学时,也基本上是直接跳过了正则表达式这一章,除了copy网上的一些常用的正则表达式做表单校验,其余时候几乎没有去了解过如何写一个正则表达式。
但是,当自己真正要去写一个适合特定业务的正则表达式时,我发现自己掌握的正则表达式知识真的是捉襟见肘。所以我这里也用思维导图整理了一些正则表达式必知必会的知识点。
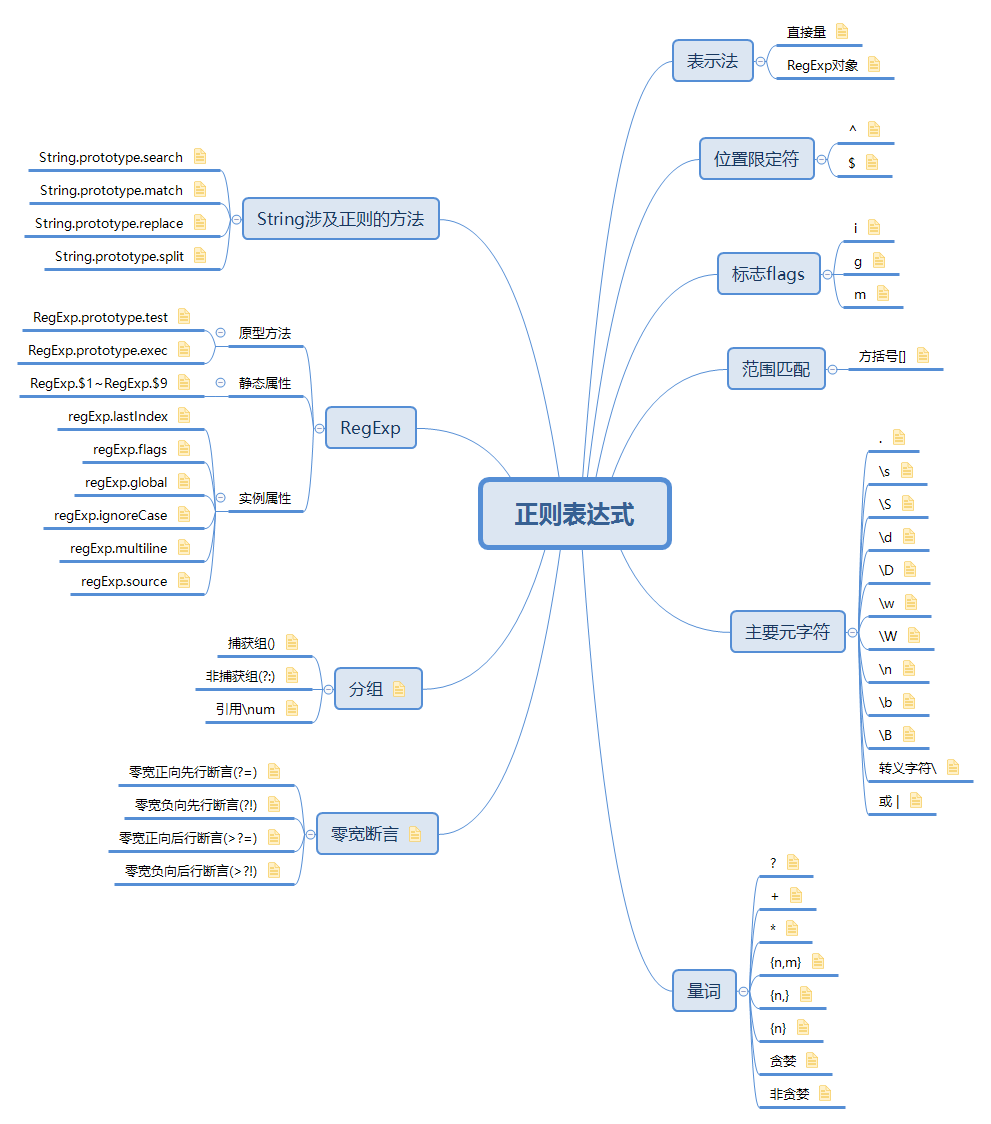
什么是正则表达式
正则表达式[2],又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
在软件开发过程中,我们或多或少会接触到正则表达式,对于前端而言,正则表达式不仅可以校验表单,文本查找和替换,还可以做语法解析器,用于AST,编辑器等领域。
正则表示法
直接量表示法
直接量也称为字面量,写法如下:
/^\d+$/g
直接量写法的正则表达式在执行时会转换为一个新的RegExp对象。我想应该是因为直接量是没有调用方法的能力的,只有转为了对象,才使得调用方法成为可能。所以才有了/^\d+$/.test()。
当在循环中用到正则对象lastIndex判断终止条件时,一定不要使用直接量正则表达式写法,否则每次循环lastIndex都会被重置为0,这是因为每次执行字面量正则表达式时,都会转换为一个新的RegExp对象,相应的lastIndex当然也会变成0。
RegExp对象表示法
var pattern = new RegExp(/^\d+$/, 'g')
第一个参数可以接受正则表达式直接量,也可以接受字符串,传递字符串作为第一个参数时,首尾不需要带斜杠,字符串中如果用到特殊字符\,需要在\前再加一个\,防止\在字符串中被转义。
"\s" === "s" // true
字符串"\\s"才能正确地表示\s
第二个参数代表标志flags,可接受的标志有i, g, m等。
标志flags
i
如果启用了标志i,正则表达式在执行时不区分大小写。
/abc/i.test('abc')等价于/abc/i.test('ABC')
g
如果启用了标志g,正则表达式会执行全局匹配,匹配到一个结果后不会立刻停止匹配,直到后续没有任何符合匹配规则的字符为止。
m
如果启用了标志m,正则表达式会执行多行匹配,^可以匹配每一行的开始或整个字符串的开始,而$可以匹配每一行的结束或整个字符串的结束。
示例如下:
/^\d+$/.test('123\n456') // false
/^\d+$/m.test('123\n456') // true
仍然可以匹配整个字符串
/^\d+\n\d+$/m.test('123\n45') // true
位置限定符
^
匹配字符的开始。比如必须以数字开始,可以这么写:
/^\d/
$
匹配字符的结束。比如必须以数字结束,可以这么写:
/\d$/
范围匹配
范围匹配是利用方括号[]实现的。
方括号[]用于范围匹配,也就是查找某个范围内的字符。比如[0-9]代表匹配数字,而[a-z]可以匹配小写字母a到z这26个字符中的任意一个。
如果要匹配不在方括号中的字符,可以在方括号中以^开头,比如[^0-9],用于匹配非数字,等价于\D。
主要元字符
.
匹配除换行符\n外的任意字符,如果要匹配任意字符,应该用/[.\n]*/。
\s
匹配任意空字符,包括空格,制表符\t,垂直制表符\v,换行符\n,回车符\r,换页符\f。\s等价于[ \t\v\n\r\f],注意方括号内第一个位置有空格。
这里也说下换行符和回车符的区别:
换行符 \n:光标下移一行,不回行首。回车符 \r:光标回到行首,不换行。
\S
\S是\s的反集
,利用\s和\S的这种互为反集的关系,我们就可以匹配任意字符,写法如下:
/[\s\S]/
\d
\d用于匹配数字,等价于[0-9]。
\D
\D是\d的反集,也就是匹配非数字,等价于[^0-9]。
\w
\w用于匹配单词字符,包含0-9,a-z,A-z以及下划线_,等价于[A-Za-z0-9_]。
\W
\W是\w的反集,用于匹配非单词字符,等价于[^A-Za-z0-9_]。
\n
\n是开发中经常遇到的换行符,而上面提到的\s是包含\n在内的。所以,能被\n匹配的字符,也一定能被\s匹配。
\b
\b用于匹配单词的边界,即单词的开始或结束。
一开始其实我不太能理解\b在正则表达式中的作用。
直到我自己试了一下这个案例
'I love you'.match(/love/)
'Iloveyou'.match(/love/)
这两个表达式都能匹配到结果"love"。
但是有时候我们并不希望这样的字符串'Iloveyou'被匹配,因为它没有单词间的空格。
所以\b有了它存在的意义。看下面的例子:
'I love you'.match(/\blove\b/)
'Iloveyou'.match(/\blove\b/) // null
第一个表达式仍然可以正常匹配到结果,而第二个就无法匹配到结果了,这符合我们的预期。
有的人可能会说,那我可以用空格匹配啊。
'I love you'.match(/ love /)
空格和\b在这种场景下还是有一点不一样的,这体现在match的结果上。
如果是用空格匹配,那么match的结果数组中的第一项就是" love ",是带了空格的,然而很多时候我们不希望在结果中得到空格,所以\b存在的意义也就比较明显了。
\B
与\b相反,代表非单词边界。也就是说,使用\B匹配时,目标字符前或后不能是空格。
假设\B在前,比如
/\Babc/.test('111 abc') // false
假设\B在后,比如
/abc\B/.test('abc 111') // false
转义字符\
由于正则表达式中很多字符有特殊含义,比如(, ), \, [, ], +,如果你真的要匹配它们,必须加上转义符\。
/\//.test('/'); // true
或 |
实现或的逻辑是比较简单的,正则表达式提供了|。
要注意的是,|隔断的是其左右的整个子表达式,而不是单个普通字符。
所以,
/^ab|cd|ef$/.test('ab') // true
/^ab|cd|ef$/.test('cd') // true
/^ab|cd|ef$/.test('ace') // false
还要注意的是,|具有从左到右的优先级,如果左侧的匹配上了,右侧的就被忽略了,即便右侧的匹配看起来更“完美”。
/a|ab/.exec('ab')得到的结果是
["a", index: 0, input: "ab", groups: undefined]
量词
?
匹配前面的子表达式零次或一次
+
匹配前面的子表达式一次或多次
*
匹配前面的子表达式零次或任意次
{n,m}
匹配前一个普通字符或者子表达式最少n次,最多m次
{n,}
匹配前一个普通字符或者子表达式最少n次
{n}
匹配前一个普通字符或者子表达式n次
贪婪
贪婪匹配是尽可能多地匹配,如果能满足匹配条件,就尽可能侵占后面的匹配规则。
贪婪匹配是默认的,比如/\d?/会尽可能地匹配1个数字,/\d+/和/\d*/会尽可能地匹配多个数字。
举个例子,
'123456789'.match(/^(\d+)(\d{2,})$/)
以上结果中捕获组的第一项是"1234567",第二项是"89"。
为什么会这样呢?因为\d+是贪婪匹配,尽可能地多匹配,如果没有后面的\d{2,},捕获组第一项会直接是"123456789"。但是由于\d{2,}的存在,\d+会给\d{2,}留个面子,满足它的最小条件,即匹配2个数字,而\d+自己匹配7个数字。
非贪婪
非贪婪匹配是尽可能少地匹配,一般是在量词?, +, *之后再加一个?,表示尽可能少地匹配,把机会留给后面的匹配规则。
还是拿贪婪模式中那个例子举例,稍微改一下,\d+换成非贪婪模式\d+?。
'123456789'.match(/^(\d+?)(\d{2,})$/)
捕获组的第一项是"1",第二项变成了"23456789"。
为什么会这样呢?因为在非贪婪模式下,会尽可能少匹配,把机会留给后面的匹配规则。
分组
分组在正则中是一个非常有用的神器,用圆括号()来包裹的内容就是一个分组,在正则中是这种表示形式:
/(\d*)([a-z]*)/
捕获组()
利用捕获组,我们能捕获到关键字符。
比如
var group = '123456789hahaha'.match(/(\d*)([a-z]*)/)
分组1用于匹配任意个数字,分组2用于匹配任意个小写字母。
那么我们在match方法的返回结果中就可以取到这两个分组匹配的结果,group[1]是"123456789",group[2]是"hahaha"。
我们还可以在RegExp的静态属性$1~$9取得前9个分组匹配的结果。RegExp.$1是"123456789",RegExp.$2是"hahaha"。但是RegExp.$1~$9是非标准的,虽然很多浏览器都实现了,尽量不要在生产环境中使用。
这种捕获组的应用在字符串的replace方法中也是类似,不过在调用replace方法时,我们需要通过$1, $2, $n这种形式去引用分组。
"123456789hahaha".replace(/(\d*)([a-z]*)/, "$1") // "123456789"
利用$1,我们就可以把源字符串替换为分组1匹配到的字符串,也就是"123456789"。
非捕获组(?:)
非捕获组是不生成引用的分组,它也由圆括号()包裹起来,不过圆括号中起头的是?:,也就是/(?:\d*)/这种形式。
还是改造下之前的例子来看下:
var group = '123456789hahaha'.match(/(?:\d*)([a-z]*)/)
由于非捕获组不生成引用,所以group[1]是"hahaha";同样地,RegExp.$1也是"hahaha"。
看到这里,我不禁也产生了疑问,既然我不需要引用非捕获组,那么非捕获组的意义何在?
思考了一阵后,我觉得非捕获组大概有这么一些优势和必要性:
与捕获组相比,非捕获组在内存上开销更小,因为它不需要生成引用
分组是为了方便加量词。我们虽然可以不生成引用,但是如果没有分组,就不太方便加给一组字符加量词。
'1a2b3c...'.match(/(?:\d[a-z]){2,3}(\.+)/)
引用\num
正则表达式中可以引用前面的具有引用的分组,通过\1,\2这种形式可以实现引用前面的子表达式。
比如,我要匹配一个字符串,要求符合这样的规则:
字符串由单引号或双引号开头和结束,中间内容可以是数字,单词。
那我要保证的是首尾要么是单引号,要么是双引号,所以我的pattern写法可以是:
var pattern = /^(["'])[a-z\d]*\1$/
pattern.test("'perfect123'") // true
pattern.test('"1perfect2"') // true
零宽断言
说实话,一开始看零宽断言的概念和解释时,我真的完全不懂在说什么。
零宽正向先行断言(?=) 零宽负向先行断言(?!) 零宽正向后行断言(?<=) 零宽负向后行断言(?<!)
后面把词汇拆开来看,加入自己的理解,就慢慢有点懂了。
零宽:zero width,断言作为必要条件进行匹配,但是不体现在匹配结果中。 正向:positive,断言中的字符必须被匹配。 负向:negative,断言中的字符不能被匹配。 先行:lookahead,必须满足前方的条件,条件在前方,前方等同于右侧。 后行:lookbehind,必须满足后方的条件,条件在后方,后方等同于左侧。
零宽正向先行断言(?=)
约束目标右侧必须存在指定的字符。
/123(?=a)/.test('123a') // true
上面的例子约束了123右侧必须有a。
零宽负向先行断言(?!)
约束目标右侧不能存在指定的字符。
/123(?!a)/.test('123a') // false
上面的例子约束了123右侧不能有a,否则结果为false。
零宽正向后行断言(?<=)
约束目标左侧必须存在指定的字符。
/(?<=a)123/.test('a123') // true
上面的例子约束了123左侧必须有a。
ES2018才支持零宽后行断言,具体见TC39 Proposals[3]
零宽负向后行断言(?<!)
约束目标左侧不能存在指定的字符。
/(?<!a)123/.test('a123') // false
上面的例子约束了123左侧不能有a,否则结果为false
注:ES2018才支持此特性。
RegExp
说到正则表达式,就不得不提到RegExp对象。下面我们从原型方法,静态属性,实例属性等几个方面来认识下RegExp对象。
原型方法
RegExp.prototype.test
test()是我们平时最常用的正则方法,test()方法执行一个检索,用来查看正则表达式与指定的字符串是否匹配,返回一个布尔值true或false。
如果正则表达式设置了全局标志g,执行test()会改变RegExp.lastIndex属性,用于记录上次匹配到的字符的起始索引。连续执行test()方法,后续的执行将会从lastIndex处开始匹配字符串。这种情况下,如果test()无法匹配到结果,lastIndex就会重置为0。
RegExp.prototype.exec
exec()相较于test()能得到更丰富的匹配信息,其结果是一个数组,数组的第0个元素是匹配到的字符串,第1~n个元素是圆括号()分组捕获的结果。
结果数组是数组,数组也是对象类型数据,所以结果数组还有两个属性分别是index和input
index代表匹配到的字符位于原始字符串的基于0的索引值input则代表原始字符串
与test()一致,如果正则表达式设置了g标志符,那么每次执行exec()都会更新lastIndex。
静态属性
静态属性不属于任何一个实例,必须通过类名访问,这一点在上一篇「思维导图学前端」6k字一文搞懂Javascript对象,原型,继承[1]已经提到过。
RegExp.$1-$9
用于获取分组的匹配结果,RegExp.$1获取的是第一个分组的匹配结果,RegExp.$9则是第九个分组的匹配结果。
具体见上文分组-捕获组一节。
实例属性
lastIndex
lastIndex,从语义上理解,就是上次匹配到的字符的起始索引。要注意的是,只有设置了g标志,lastIndex才有效。
当还未进行匹配时,lastIndex自然是0,代表从第0个字符串开始匹配。
lastIndex会随着exec()和test()的执行而更新
var reg = /\d/g
reg.lastIndex // 0
reg.test('123456')
reg.lastIndex // 1
reg.exec('123456')
reg.lastIndex // 2
lastIndex可以手动修改,也就是说,你可以自由控制匹配的细节。
flags
flags属性返回一个字符串,代表该正则表达式实例启用了哪些标志。
var reg = /\d/ig
reg.flags; // "gi"
global
global是布尔量,表明正则表达式是否使用了g标志。
ignoreCase
ignoreCase是布尔量,表明正则表达式是否使用了i标志。
multiline
multiline是布尔量,表明正则表达式是否使用了m标志。
source
source,意为源,是正则表达式的字符串表示,不会包含正则字面量两边的斜杠以及任何的标志字符。
String涉及正则的方法
String.prototype.search
search()方法用正则表达式对字符串对象进行一次匹配,结果返回一个index,代表正则表达式在字符串中首次匹配项的索引。如果无法匹配,则返回-1。
search()方法的参数必须是正则表达式,如果不是也会被new RegExp()默默转换为正则表达式对象。
"123abc".search(/[a-z]/); // 3
String.prototype.match
字符串的match方法用于检索字符串,和正则表达式的exec方法是相似的。match方法的参数也要求是正则表达式。match方法返回一个数组。
与exec()的不同点在于,如果match方法传入的正则表达式带了标识g,则将返回与完整正则表达式匹配的所有结果,但不会返回捕获组。
"123abc456".match(/([a-z])/g);
// 返回["a", "b", "c"]
var reg = /([a-z])/g;
reg.exec('123abc456');
// 返回数组["a", "a", index: 3, input: "123abc456", groups: undefined]
reg.exec('123abc456');
// 返回数组["b", "b", index: 4, input: "123abc456", groups: undefined]
reg.exec('123abc456');
// 返回数组["c", "c", index: 5, input: "123abc456", groups: undefined]
如果match()方法传入的正则表达式不带标志g,表现与exec()方法一致,只会返回第一个匹配结果和分组捕获到的结果。
如果此时表达式中有圆括号分组,在match()的结果数组中也是可以获取到这些分组匹配的结果的,这一点在捕获组中也有提到。
"123abc456".match(/([a-z])/);
// 返回["a", "a", index: 3, input: "123abc456", groups: undefined]
RegExp.$1; // "a"
String.prototype.replace
replace()是字符串替换方法,它不要求第一个参数必须是正则表达式。如果第一个参数是正则表达式,并且包含分组,那么在replace()的第二个参数中,可以通过"$1","$2"这种形式引用分组匹配结果。
"123456789hahaha".replace(/(\d*)([a-z]*)/, "$1") // "123456789"
String.prototype.split
split()方法是字符串分割方法,也算平时用得很多的一个方法,但是很多人不知道它可以接受正则表达式作为参数。
假设我们得到这样一个不太规律的字符串"1,2, 3 ,4, 5",然后需要分割这个字符串得到纯数字组成的数组,直接使用split(",")是不行的,而利用正则表达式作为分割条件就可以做到。
var str = "1,2, 3 ,4, 5";
str.split(/\s*,\s*/);
// 返回 ["1", "2", "3", "4", "5"]
最后
正则表达式是一个非常重要却容易被忽视的知识点,在面试中也是一个频繁的考点,所以必须给予它足够的重视。经过上面的知识点梳理,相信能在后续的实战中胸有成竹,不慌不忙。
参考
「思维导图学前端」6k字一文搞懂Javascript对象,原型,继承: https://juejin.im/post/5ee9ac91f265da02aa2e751e
[2]正则表达式: https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F/1700215?fr=aladdin
[3]TC39 Proposals: https://github.com/tc39/proposals/blob/master/finished-proposals.md
END


“分享、点赞、在看” 支持一波 