
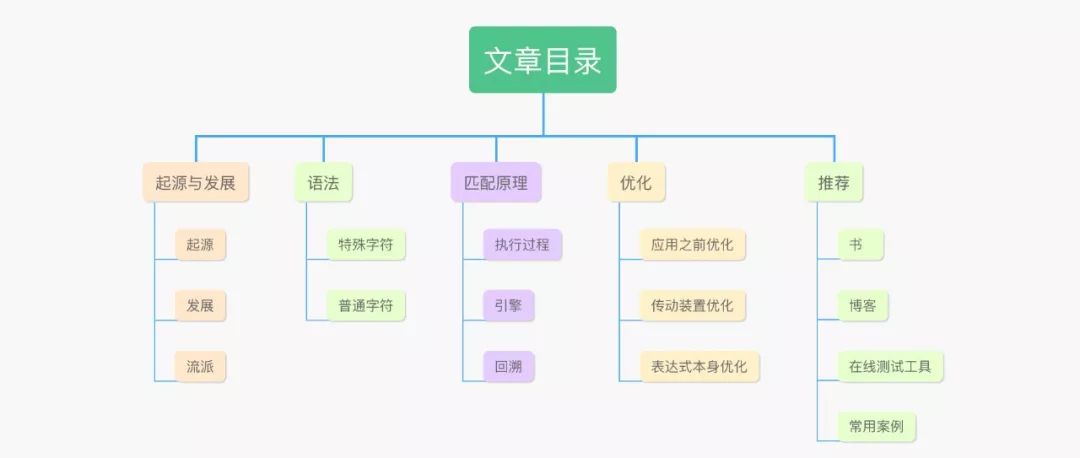
一篇值得收藏的正则表达式文章
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

使用正则表达式去匹配字符串Hello World 中的 Hello
伪代码:/Hello/, "Hello World"
输出:Hello
如何写好一篇关于 正则表达式 的文章,我思考了一周的时间,从未有一篇文章能让猪哥如此费神。
因为我觉得正则表达式 :难记忆、难描述、广而深且不受重视,有人说正则表达式既好写也难写!
好写:无非写一些常用、实用的案例,说实话你们每个人都能写出这种:在网上百度一下然后结合一点自己的实际经验,一篇文章就出来了。 难写:很多人都认为正则简单,不用记,要用就百度一下。但是绝大多数人了解的只是正则的一个小面,真正的精髓却很少关注!

* ^ $ \d 等等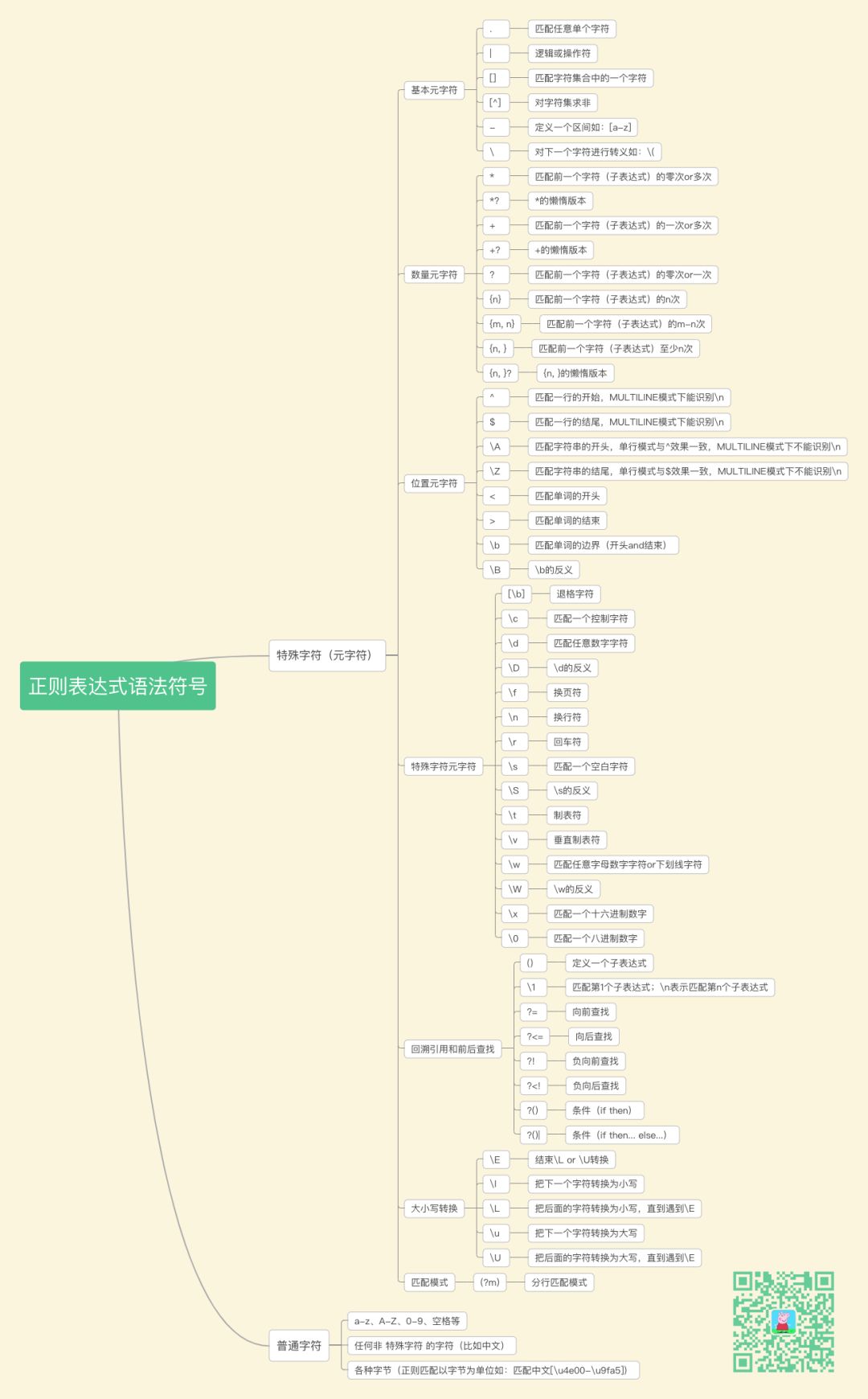
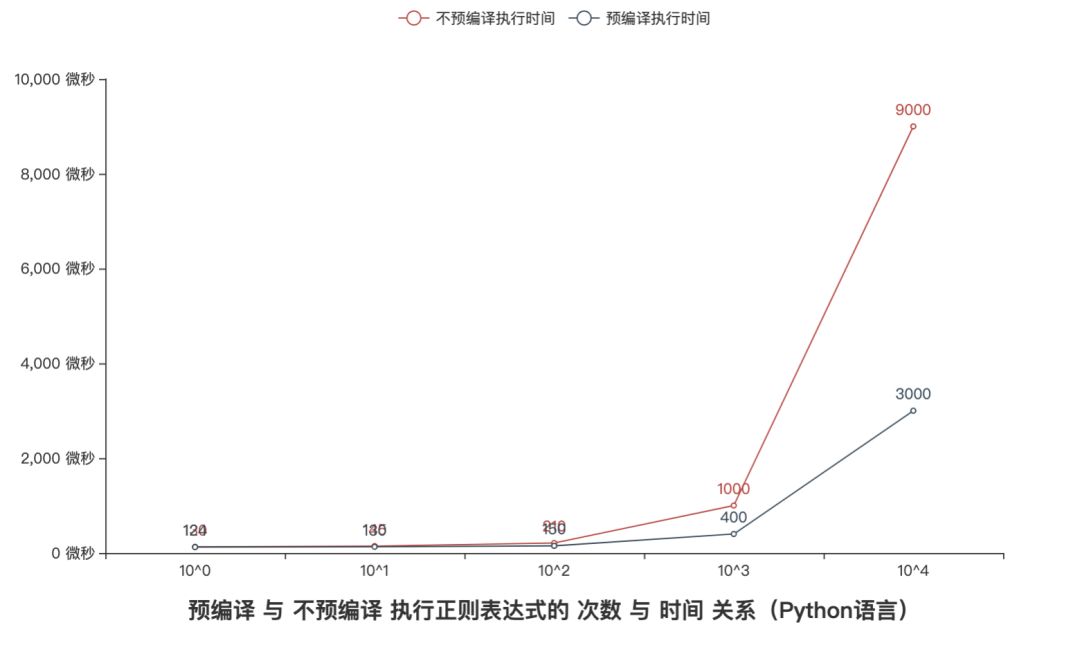
1.执行过程
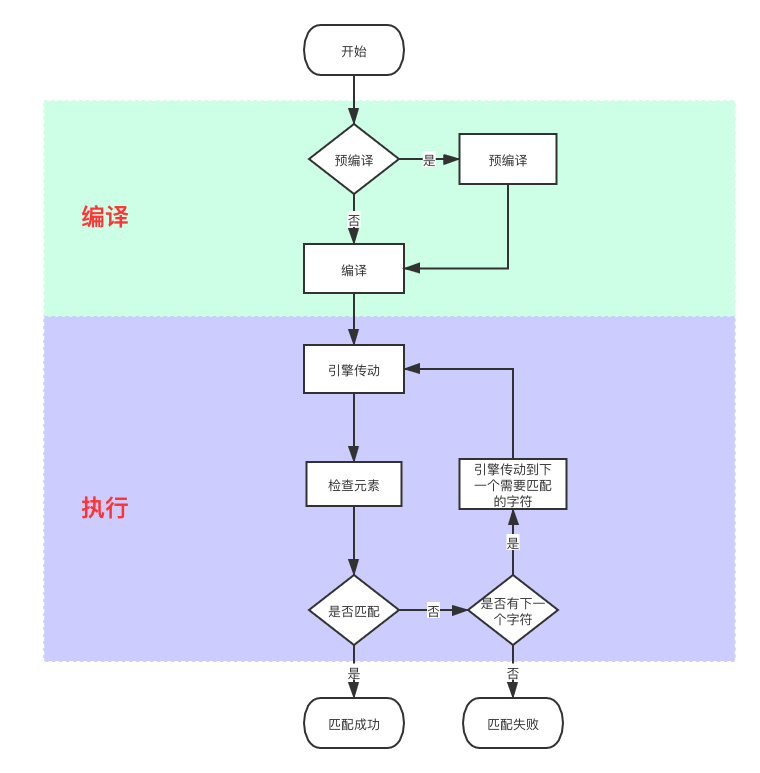
re模块举例:通过 re.compile(pattern)预编译返回Pattern对象,在后面代码中可以直接引用。通过 re.match(pattern, text)即用编译,虽然也会有缓存Pattern对象,但是每次使用都需要去缓存中取出,比预编译多一步取操作。
pattern = r'http:\/\/(?:.?\w+)+'text = 'xxx.com'
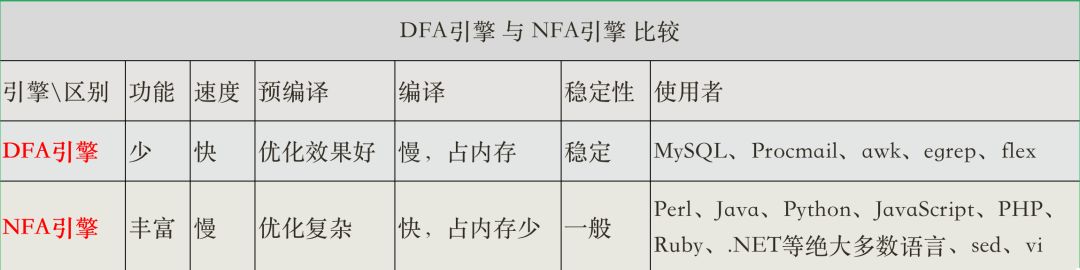
2.引擎(重点)
DFA (Deterministic finite automaton) 确定型有穷自动机 NFA (Non-deterministic finite automaton) 非确定型有穷自动机
确定型、有穷、自动机这几个名词:确定型与非确定型:假设有一个字符串(text=abc)需要匹配,在没有编写正则表达式的前提下,就直接可以确定字符匹配顺序的就是确定型,不能确定字符匹配顺序的则为非确定型。 有穷:有穷即表示有限的意思,这里表示有限次数内能得到结果。 自动机:自动机便是自动完成,在我们设置好匹配规则后由引擎自动完成,不需要人为干预!
为了大家能很清楚的理解DFA引擎执行原理,猪哥制作了一个简易的动态执行过程图给大家看看

根据上面的动图我们可以得出DFA引擎的一些特点:
文本主导:按照文本的顺序执行,这也就能说明为什么DFA引擎是确定型(deterministic)了,稳定! 记录当前有效的所有可能:我们看到当执行到 (d|b)时,同时比较表达式中的d和b,所以会需要更多的内存。每个字符只检查一次:这提高了执行效率,而且速度与正则表达式无关。 不能使用反向引用等功能:因为每个字符只检查一次,文本零宽度(位置)只记录当前比较值,所以不能使用反向引用、环视等一些功能!
猪哥同样画了一个简易的NFA引擎执行过程图方便大家理解

根据上面的动图我们可以得出NFA引擎的一些特点:
文表达式主导:按照表达式的一部分执行,如果不匹配换其他部分继续匹配,直到表达式匹配完成。 会记录某个位置:我们看到当执行到 (d|b)时,NFA引擎会记录字符的位置(零宽度),然后选择其中一个先匹配。单个字符可能检查多次:我们看到当执行到 (d|b)时,比较d后发现不匹配,于是NFA引擎换表达式的另一个分支b,同时文本位置回退,重新匹配字符'b'。这也是NFA引擎是非确定型的原因,同时带来另一个问题效率可能没有DFA引擎高。可实现反向引用等功能:因为具有回退这一步,所以可以很容易的实现反向引用、环视等一些功能!
DFA(电动机) 和NFA(汽油机) 都有很长的历史,不过,正如汽油机一样,NFA 的历史更长一些。也有些系统采用了混合引擎,它们会根据任务的不同选择合适的引擎(甚至对同一表达式中的不同部分采用不同的引擎,以求得功能与速度之间的最佳平衡)。 ——《精通正则表达式》
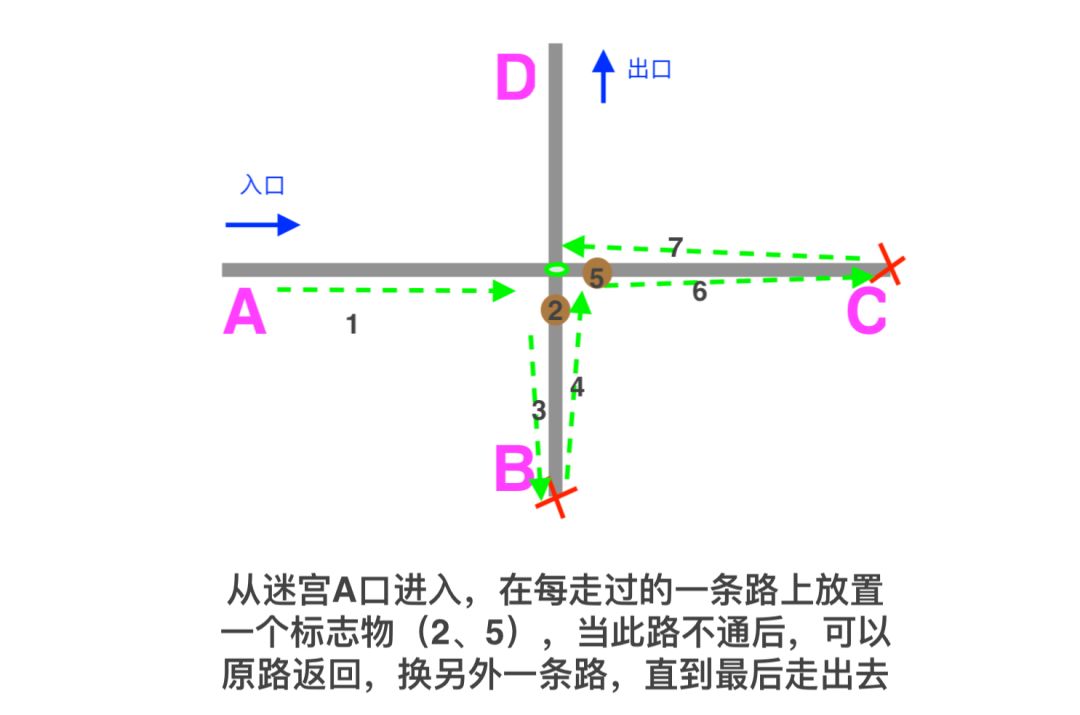
3.回溯(重点)
动图中,我们可以看到当某个正则分支匹配不成功之后,文本的位置需要回退,然后换另一个分支匹配,而回退这步专业术语就叫:回溯。
$1=b。(a*):匹配到了文本中的aaaaa 匹配正则中的b,但是失败,因为(a*)已经把text都吃了 这时候引擎会要求(a*)吐出最后一个字符(a),但是无法匹配b 第二次是吐出倒数第二个字符(还是a),依然无法匹配 就这样引擎会要求(a*)逐个将吃进去的字符都吐出来 但是到最后都无法匹配b
*匹配的东西一点一点吐回,我们假设如果文本长度为几万,那引擎就要回溯几万次,这对机器的CPU来说简直是灾难。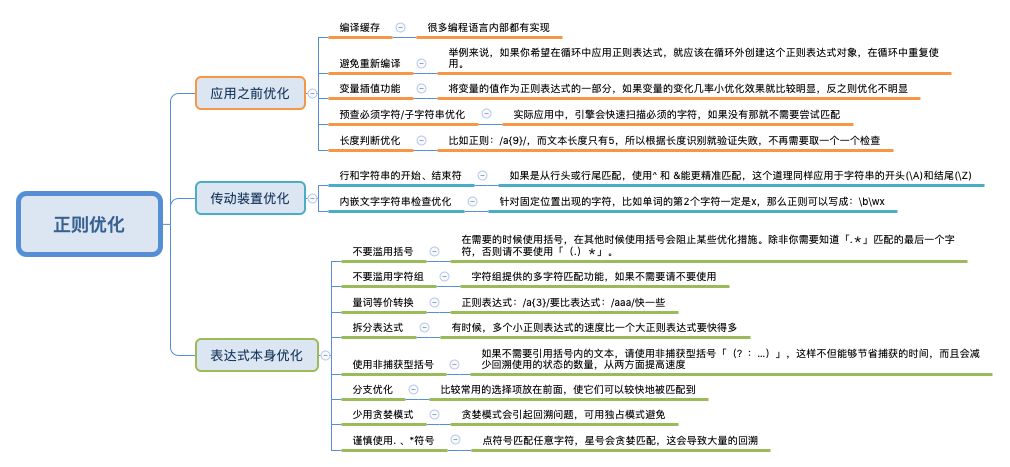
在面试过程中也许会被问到关于正则的优化,大家记住几点就可以。
1.书

2.博客
深入:某不知名大佬:https://blog.csdn.net/lxcnn
3.在线测试工具
4.常用案例

最后祝愿大家都能搞定正则表达式,处理文本可以得心应手!
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论