
手把手教你实现web文本划线的功能

来源 | https://www.cnblogs.com/wanglinmantan/p/15106871.html
开篇
InfoQ写作平台:

等等,这个功能看似简单,实际上难点还是很多的,比如如何高性能的对各种复杂的文本结构划线、如何尽可能少的存储数据、如何精准的回显划线、如何处理重复划线、如何应对文本后续编辑的情况等等。
作为一个前端搬砖工,每当看到一个有意思的小功能时我都想自己去把它做出来,但是看了仅有的几篇相关文章之后,发现,不会😓,这些文章介绍的都只是一个大概思路,看完让人感觉好像会了,但是细想就会发现很多问题,只能去看源码,看源码总是费时的,还不一定能看懂。
想要实现一个生产可用的难度还是很大的,所以本文退而求其次,单纯的写一个demo开心开心。
demo效果请点击:http://lxqnsys.com/#/demo/textUnderline。
总体思路
总体思路很简单,遍历选区内的所有文本,切割成单个字符,给每个字符都包裹上划线元素,重复划线的话就在最深层继续包裹,事件处理的话从最深的元素开始。
存储的方式是记录该划线文本外层第一个非划线元素的标签名和索引,以及字符在其内所有字符里总的偏移量。
回显的方式是获取到上述存储数据对应的元素,然后遍历该元素的字符添加划线元素。
实现
HTML结构
<div class="article" ref="article"></div>
文本内容就放在上述的div里,我从掘金小册里随便挑选了一篇文章,把它的html结构原封不动的复制粘贴进去:

显示tooltip
首先要做的是在选区上显示一个划线按钮,这个很简单,我们监听一下mouseup事件,然后获取一下选区对象,调用它的getBoundingClientRect方法获取位置信息,然后设置到我们的tooltip元素上:
document.addEventListener('mouseup', this.onMouseup)onMouseup () {// 获取Selection对象,里面可能包含多个`ranges`(区域)let selObj = window.getSelection()// 一般就只有一个Range对象let range = selObj.getRangeAt(0)// 如果选区起始位置和结束位置相同,那代表没有选到任何东西if (range.collapsed) {return}this.range = range.cloneRange()this.tipText = '划线'this.setTip(range)}setTip (range) {let { left, top, width } = range.getBoundingClientRect()this.tipLeft = left + (width - 80) / 2this.tipTop = top - 40this.showTip = true}

划线
给tooltip绑定一下点击事件,点击后需要获取到选区内的所有文本节点,先看一下Range对象的结构:

简单介绍一下:
collapsed属性表示开始和结束的位置是否相同;
commonAncestorContainer属性返回包含startContainer和endContainer的公共父节点;
endContainer属性返回包含range终点的节点,通常是文本节点;
endOffset返回range终点在endContainer内的位置的数字;
startContainer属性返回包含range起点的节点,通常是文本节点;
startContainer返回range起点在startContainer内的位置的数字;
所以目标是要遍历startContainer和endContainer两个节点之间的所有节点来收集文本节点,受限于笔者匮乏的算法和数据结构知识,只能选择一个投机取巧的方法,遍历commonAncestorContainer节点。
然后使用range对象的isPointInRange()方法来检测当前遍历的节点是否在选区范围内,这个方法需要注意的两个点地方,一个是isPointInRange()方法目前不支持IE,二是首尾节点需要单独处理,因为首尾节点可能部分在选区内,这样这个方法是返回false的。
mark ()this.textNodes = []let { commonAncestorContainer, startContainer, endContainer } = this.rangethis.walk(commonAncestorContainer, (node) => {if (node === startContainer ||node === endContainer ||this.range.isPointInRange(node, 0)) {// 起始和结束节点,或者在范围内的节点,如果是文本节点则收集起来if (node.nodeType === 3) {this.textNodes.push(node)}}})this.handleTextNodes()this.showTip = falsethis.tipText = ''}
walk是一个深度优先遍历的函数:
walk (node, callback = () => {}) {callback(node)if (node && node.childNodes) {for (let i = 0; i < node.childNodes.length; i++) {this.walk(node.childNodes[i], callback)}}}
获取到选区范围内的所有文本节点后就可以切割字符进行元素替换:
handleTextNodes () {// 生成本次的唯一idlet id = ++this.idx// 遍历文本节点this.textNodes.forEach((node) => {// 范围的首尾元素需要判断一下偏移量,用来截取字符let startOffset = 0let endOffset = node.nodeValue.lengthif (node === this.range.startContainer &&this.range.startOffset !== 0) {startOffset = this.range.startOffset}if (node === this.range.endContainer && this.range.endOffset !== 0) {endOffset = this.range.endOffset}// 替换该文本节点this.replaceTextNode(node, id, startOffset, endOffset)})// 序列化进行存储,获取刚刚生成的所有该id的划线元素this.serialize(this.$refs.article.querySelectorAll('.mark_id_' + id))}
如果是首节点,且startOffset不为0,那么startOffset之前的字符不需要添加划线包裹元素,如果是尾节点,且endOffset不为0,那么endOffset之后的字符不需要划线,中间的其他所有文本都需要进行切割及划线:
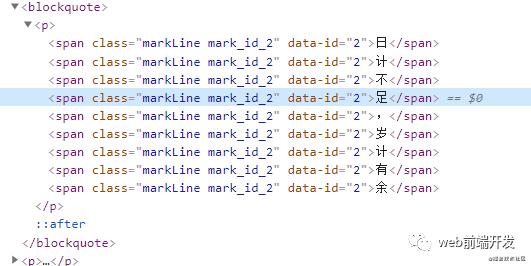
replaceTextNode (node, id, startOffset, endOffset) {// 创建一个文档片段用来替换文本节点let fragment = document.createDocumentFragment()let startNode = nulllet endNode = null// 截取前一段不需要划线的文本if (startOffset !== 0) {startNode = document.createTextNode(node.nodeValue.slice(0, startOffset))}// 截取后一段不需要划线的文本if (endOffset !== 0) {endNode = document.createTextNode(node.nodeValue.slice(endOffset))}startNode && fragment.appendChild(startNode)// 切割中间的所有文本node.nodeValue.slice(startOffset, endOffset).split('').forEach((text) => {// 创建一个span标签用来作为划线包裹元素let textNode = document.createElement('span')textNode.className = 'markLine mark_id_' + idtextNode.setAttribute('data-id', id)textNode.textContent = textfragment.appendChild(textNode)})endNode && fragment.appendChild(endNode)// 替换文本节点node.parentNode.replaceChild(fragment, node)}
效果如下:

此时html结构:
序列化存储
一次性的划线是没啥用的,那还不如在文章上面盖一个canvas元素,给用户一个自由画布,所以还需要进行保存,下次打开还能重新显示之前画的线。
存储的关键是要能让下次还能定位回去,参考其他文章介绍的方法,本文选择的是存储划线元素外层的第一个非划线元素的标签名,以及在指定节点范围内的同类型元素里的索引,以及该字符在该非划线元素里的总的字符偏移量。
描述起来可能有点绕,看代码:
serialize (markNodes) {// 选择article元素作为根元素,这样的好处是页面的其他结构如果改变了不影响划线元素的定位let root = this.$refs.article// 遍历刚刚生成的本次划线的所有span节点markNodes.forEach((markNode) => {// 计算该字符离外层第一个非划线元素的总的文本偏移量let offset = this.getTextOffset(markNode)// 找到外层第一个非划线元素let { tagName, index } = this.getWrapNode(markNode, root)// 保存相关数据this.serializeData.push({tagName,index,offset,id: markNode.getAttribute('data-id')})})}
计算字符离外层第一个非划线元素的总的文本偏移量的思路是先算获取同级下之前的兄弟元素的总字符数,再依次向上遍历父元素及其之前的兄弟节点的总字符数,直到外层元素:
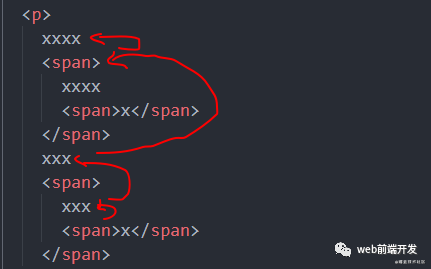
getTextOffset (node) {let offset = 0let parNode = node// 遍历直到外层第一个非划线元素while (parNode && parNode.classList.contains('markLine')) {// 获取前面的兄弟元素的总字符数offset += this.getPrevSiblingOffset(parNode)parNode = parNode.parentNode}return offset}
获取前面的兄弟元素的总字符数:
getPrevSiblingOffset (node) {let offset = 0let prevNode = node.previousSiblingwhile (prevNode) {offset +=prevNode.nodeType === 3? prevNode.nodeValue.length: prevNode.textContent.lengthprevNode = prevNode.previousSibling}return offset}
获取外层第一个非划线元素在上面获取字符数的方法里其实已经有了:
getWrapNode (node, root) {// 找到外层第一个非划线元素let wrapNode = node.parentNodewhile (wrapNode.classList.contains('markLine')) {wrapNode = wrapNode.parentNode}let wrapNodeTagName = wrapNode.tagName// 计算索引let wrapNodeIndex = -1// 使用标签选择器获取所有该标签元素let els = root.getElementsByTagName(wrapNodeTagName)els = [...els].filter((item) => {// 过滤掉划线元素return !item.classList.contains('markLine');}).forEach((item, index) => {// 计算当前元素在其中的索引if (wrapNode === item) {wrapNodeIndex = index}})return {tagName: wrapNodeTagName,index: wrapNodeIndex}}
最后存储的数据示例如下:

反序列化显示
显示就是根据上面存储的数据把线画上,遍历上面的数据,先根据tagName和index获取到指定元素,然后遍历该元素下的所有文本节点,根据offset找到需要划线的字符:
deserialization () {let root = this.$refs.article// 遍历序列化的数据markData.forEach((item) => {// 获取到指定元素let els = root.getElementsByTagName(item.tagName)els = [...els].filter((item) => {// 过滤掉划线元素return !item.classList.contains('markLine');})let wrapNode = els[item.index]let len = 0let end = false// 遍历该元素所有节点this.walk(wrapNode, (node) => {if (end) {return}// 如果是文本节点if (node.nodeType === 3) {// 如果当前文本节点的字符数+之前的总数大于offset,说明要找的字符就在该文本内if (len + node.nodeValue.length > item.offset) {// 计算在该文本里的偏移量let startOffset = item.offset - len// 因为我们是切割到单个字符,所以总长度也就是1let endOffset = startOffset + 1this.replaceTextNode(node, item.id, startOffset, endOffset)end = true}// 累加字符数len += node.nodeValue.length}})})}
结果如下:

删除划线
删除划线很简单,我们监听一下点击事件,如果目标元素是划线元素,那么获取一下所有该id的划线元素,创建一个range,显示一下tooltip,然后点击后把该划线元素删除即可。
// 显示取消划线的tooltipshowCancelTip (e) {let tar = e.targetif (tar.classList.contains('markLine')) {e.stopPropagation()e.preventDefault()// 获取划线idthis.clickId = tar.getAttribute('data-id')// 获取该id的所有划线元素let markNodes = document.querySelectorAll('.mark_id_' + this.clickId)// 选择第一个和最后一个文本节点来作为range边界let startContainer = markNodes[0].firstChildlet endContainer = markNodes[markNodes.length - 1].lastChildthis.range = document.createRange()this.range.setStart(startContainer, 0)this.range.setEnd(endContainer,endContainer.nodeValue.length)this.tipText = '取消划线'this.setTip(this.range)}}
点击了取消按钮后遍历该id的所有划线节点,进行元素替换:
cancelMark () {this.showTip = falsethis.tipText = ''let markNodes = document.querySelectorAll('.mark_id_' + this.clickId)// 遍历所有划线街道for (let i = 0; i < markNodes.length; i++) {let item = markNodes[i]// 如果还有子节点,也就是其他id的划线元素if (item.children[0]) {let node = item.children[0].cloneNode(true)// 子节点替换当前节点item.parentNode.replaceChild(node, item)} else {// 否则只有文本的话直接创建一个文本节点来替换let textNode = document.createTextNode(item.textContent)item.parentNode.replaceChild(textNode, item)}}// 从序列化数据里删除该id的数据this.serializeData = this.serializeData.filter((item) => {return item.id !== this.clickId})}

缺点
到这里这个极简划线就结束了,现在来看一下这个极简的方法有什么缺点.
首先毋庸置疑的就是如果划线字符很多,重复划线很多次,那么会生成非常多的span标签及嵌套层次,节点数量是影响页面性能的一个大问题。
第二个问题是需要存储的数据也会很大,增加存储成本和网络传输时间:
这可以通过把字段名字压缩一下,改成一个字母,另外可以把连续的字符合并一下来稍微优化一下,但是然并卵。
第三个问题是如其名,文本划线,真的是只能给文本进行划线,其他的图片上面的就不行了:
第四个问题是无法应对如果划线后文章被修改了,html结构变化了的问题。
这几个问题个个扎心,导致它只能是个demo。
稍微优化一下
很容易想到的一个优化方法是不要把字符单个切割,整块包裹不就好了吗,道理是这个道理:
replaceTextNode (node, id, startOffset, endOffset) {// ...startNode && fragment.appendChild(startNode)// 改成直接包裹整块文本let textNode = document.createElement('span')textNode.className = 'markLine mark_id_' + idtextNode.setAttribute('data-id', id)textNode.textContent = node.nodeValue.slice(startOffset, endOffset)fragment.appendChild(textNode)endNode && fragment.appendChild(endNode)// ...}
这样序列化时需要增加一个长度的字段:
let textLength = markNode.textContent.lengthif (textLength > 0) {// 过滤掉长度为0的空字符,否则会有不可预知的问题this.serializeData.push({tagName,index,offset,length: textLength,// ++id: markNode.getAttribute('data-id')})}
这样序列化后的数据量会大大减少:

接下来反序列化也需要修改,字符长度不定的话就可能跨文本节点了:
deserialization () {let root = this.$refs.articlemarkData.forEach((item) => {let wrapNode = root.getElementsByTagName(item.tagName)[item.index]let len = 0let end = falselet first = truelet _length = item.lengththis.walk(wrapNode, (node) => {if (end) {return}if (node.nodeType === 3) {let nodeTextLength = node.nodeValue.lengthif (len + nodeTextLength > _offset) {// startOffset之前的文本不需要划线let startOffset = (first ? item.offset - len : 0)first = false// 如果该文本节点剩余的字符数量小于划线文本的字符长度的话代表该文本节点还只是划线文本的一部分,还需要到下一个文本节点里去处理let endOffset = startOffset + (nodeTextLength - startOffset >= _length ? _length : nodeTextLength - startOffset)this.replaceTextNode(node, item.id, startOffset, endOffset)// 长度需要减去之前节点已经处理掉的长度_length = _length - (nodeTextLength - startOffset)// 如果剩余要处理的划线文本的字符数量为0代表已经处理完了,可以结束了if (_length <= 0) {end = true}}len += nodeTextLength}})})}
最后取消划线也需要修改,因为子节点可能就不是只有单纯的一个划线节点或文本节点了,需要遍历全部子节点:
cancelMark () {this.showTip = falsethis.tipText = ''let markNodes = document.querySelectorAll('.mark_id_' + this.clickId)for (let i = 0; i < markNodes.length; i++) {let item = markNodes[i]let fregment = document.createDocumentFragment()for (let j = 0; j < item.childNodes.length; j++) {fregment.appendChild(item.childNodes[j].cloneNode(true))}item.parentNode.replaceChild(fregment, item)}this.serializeData = this.serializeData.filter((item) => {return item.id !== this.clickId})}
现在再来看一下效果:
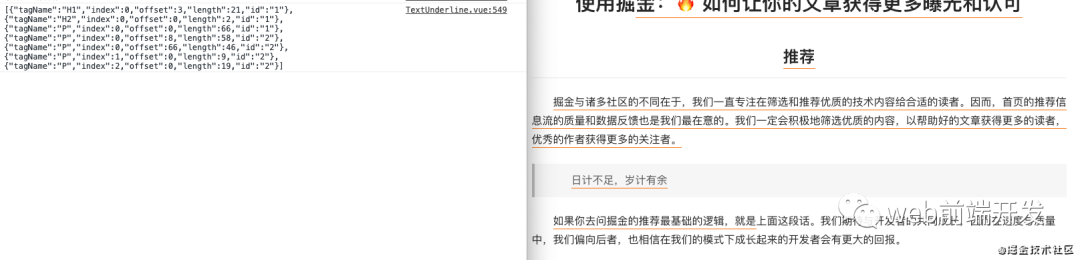
html结构:

可以看到无论是序列化的数据还是DOM结构都已经简洁了很多。
但是,如果文档结构很复杂或者多次重复划线最终产生的节点和数据还是比较大的。
总结
本文介绍了一个实现web文本划线功能的极简实现,最初的想法是通过切割成单个字符来进行包裹,这样的优点是十分简单,缺点也很明显,产生的序列号数据很大、修改的DOM结构很复杂,在文章及demo的写作过程中经过实践,发现直接包裹整块文字也并不会带来太多问题,但是却能减少和优化很多要存储的数据和DOM结构,所以很多时候,想当然是不对的,最后想说,数据结构和算法真的很重要😭。
示例代码在:https://github.com/wanglin2/textUnderline。
学习更多技能
请点击下方公众号
![]()
