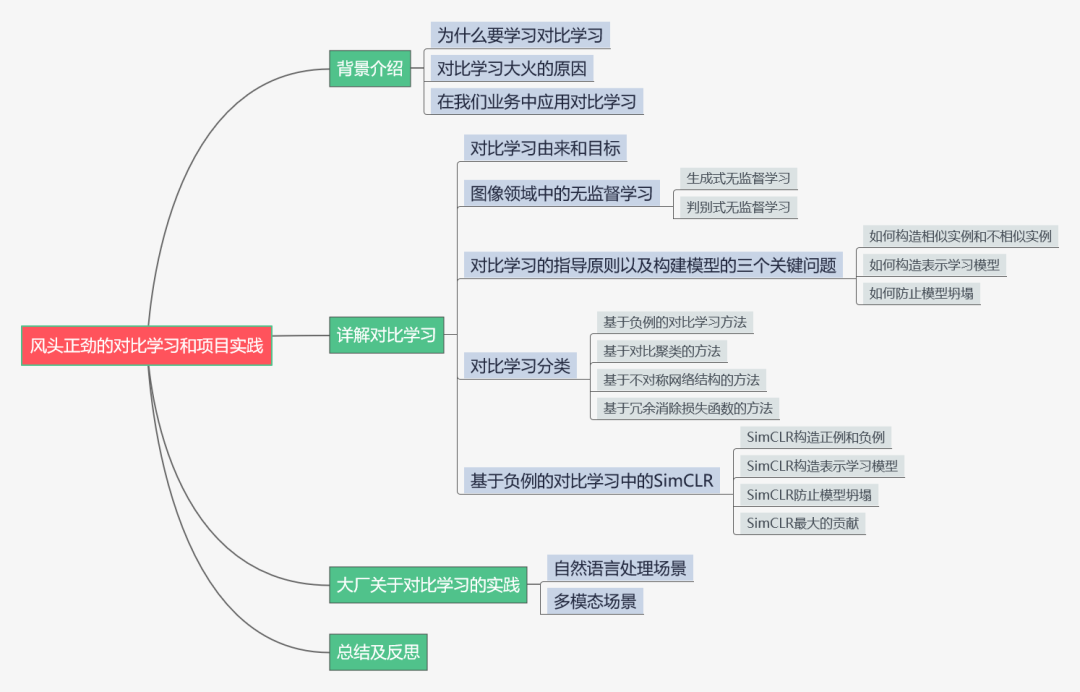
目前在进行敏捷管理项目实施的时候,对比了一下市面上主流的项目协作管理的软件&开源工具。
对比对象包括Teambition, OrangeScrum, Tuleap Open ALM, Taiga.io, 飞书,企业微信, Slack, Trello, Asana, Mattermost, Wrike, Teamwork, Proofhub.
功能对比结果图
在其中挑选出六个功能比较完备的软件和开源软件进行优劣势以及价格的对比:
分别为:Teambition, Taiga, OrangeScrum, Tuleap, 飞书, 企业微信。
其中飞书目前不支持燃尽图,任务管理也比较粗糙,但是目前中小企业申请可以三年免费,而且支持聊

 下载APP
下载APP