
来,把KeeWiDB的架构拆开给你们瞧瞧!
友好:完全兼容 Redis 协议,原先使用 Redis 的业务无需修改任何代码便可以迁移到 KeeWiDB 上; 高性能低延迟:通过创新性的分级存储架构设计,单节点读写能力超过 18 万 QPS,访问延迟达到毫秒级; 更低的成本:内核自动区分冷热数据,冷数据存储在相对低价的 SSD 上; 更大的容量:节点支持 TB 级别的数据存储,集群支持 PB 级别的数据存储; 保证了事务的 ACID (原子性 Atomicity、一致性 Consitency、隔离性 Isolation、持久性 Durability)四大特性;
整体架构
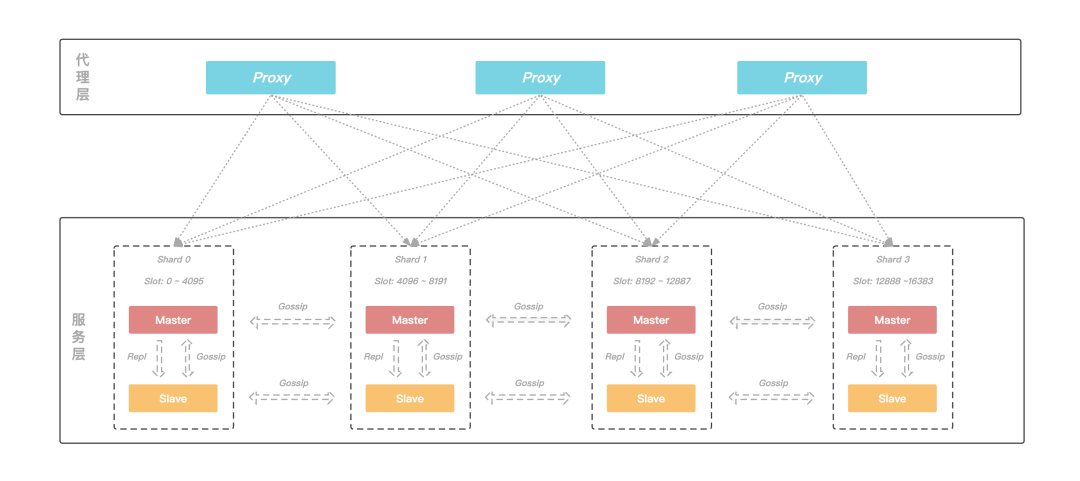 图:KeeWiDB整体架构图
图:KeeWiDB整体架构图
代理层
客户端直接和 Proxy 进行交互,后端集群在扩缩容场景不会影响客户端请求; Proxy 内部有自己的连接池和后端 KeeWiDB 进行交互,可大大减少 KeeWiDB 上的连接数量,同时有效避免业务短连接场景下反复建连断连对内核造成性能的影响; 支持读写分离,针对读多写少的场景,通过添加副本数量可以有效分摊 KeeWiDB 的访问压力; 支持命令拦截和审计功能,针对高危命令进行拦截和日志审计,大幅度提高系统的安全性; 由于 Proxy 是无状态的,负载较高场景下可以通过增加 Proxy 数量来缓解压力,此外我们的 Proxy 支持热升级功能,后续 Proxy 添加了新功能或者性能优化,存量 KeeWiDB 实例的 Proxy 都可以进行对客户端无感知的平滑升级;

服务层
Server内部模型
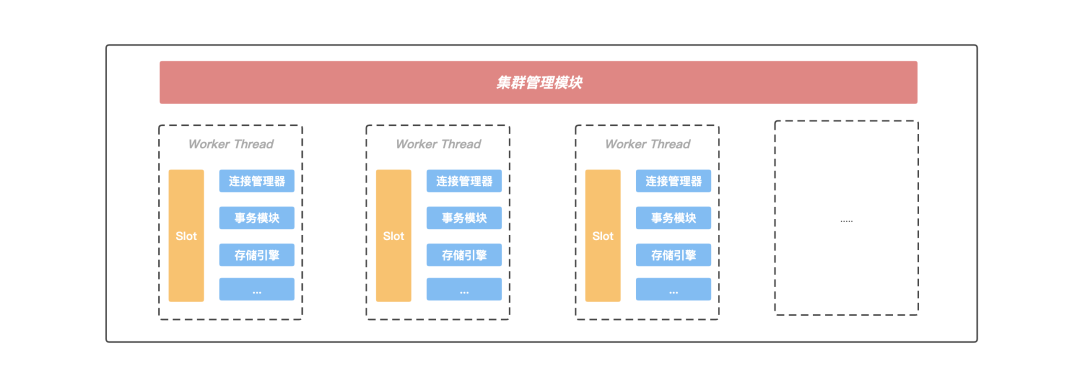 图:Server内部模块
图:Server内部模块
线程模型
 图:线程模型
图:线程模型
引入协程
开启过多的线程会耗费大量的系统资源, 包括内存; 线程的上下文切换涉及到用户空间和内核空间的切换, 大量线程的上下文切换同样会给 CPU 带来额外的开销;
A coroutine is a function that can suspend execution to be resumed later. Coroutines are stackless: they suspend execution by returning to the caller and the data that is required to resume execution is stored separately from the stack. This allows for sequential code that executes asynchronously (e.g. to handle non-blocking I/O without explicit callbacks).
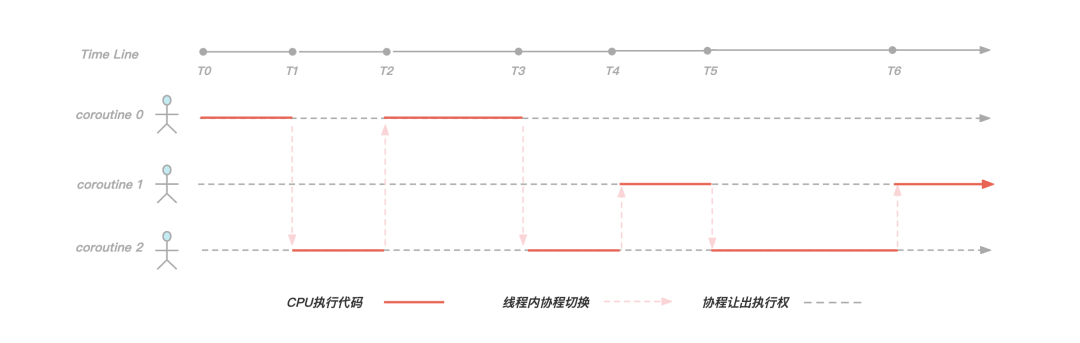 图:协程切换示意图
图:协程切换示意图
数据存储
 图:Dram和PMem以及SSD的性能比较
图:Dram和PMem以及SSD的性能比较
In computing, a page cache, sometimes also called disk cache, is a transparent cache for the pages originating from a secondary storage device such as a hard disk drive (HDD) or a solid-state drive (SSD). The operating system keeps a page cache in otherwise unused portions of the main memory (RAM), resulting in quicker access to the contents of cached pages and overall performance improvements. A page cache is implemented in kernels with the paging memory management, and is mostly transparent to applications.
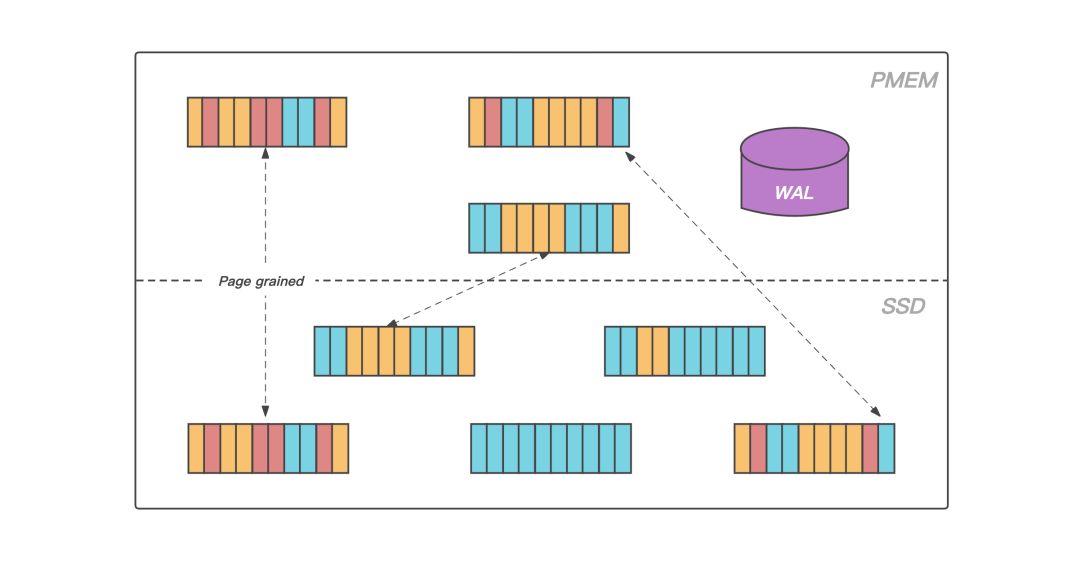 图:数据页的升温和落冷
图:数据页的升温和落冷主从同步
存储型数据库的请求执行过程中涉及到磁盘 IO,单个请求的执行耗时本身就比较长; 主节点同时服务多个客户端连接,不同连接的请求并发执行,发挥了协程异步 IO 的优势,节点整体 QPS 有保障; 主从同步只有一个连接,由于从库顺序回放请求,无法并发,回放的 QPS 远远跟不上主节点处理用户请求的 QPS;
在从节点增加 RelayLog 作为中继,将从节点的命令接收和回放两个过程拆开,避免回放过程拖慢命令的接收速度; 在主节点记录 Binlog 的时候增加逻辑时钟信息,回放的时候根据逻辑时钟确定依赖关系,将互相之间没有依赖的命令一起放进回放的协程池,并发完成这批命令的回放,提升从节点整体的回放 QPS;
 图:从库并发回放
图:从库并发回放
seqnum 是主节点事务 commit 的序列号,每次有新的事务 commit,当前 seqnum 赋给当前事务,全局 seqnum 自增1; parent 由主节点在每个事务开始执行前的 prepare 阶段获取,记录此时已经 commit 的最大 seqnum,记为 max,说明当前事务是在 max 对应事务 commit 之后才开始执行,二者在主节点端有逻辑上的先后关系;
总结
 ,即可进入官网申请公测),现已在内外部已经接下了不少业务,其中不乏有一些超大规模以及百万 QPS 级的业务,线上服务均稳定运行中。
,即可进入官网申请公测),现已在内外部已经接下了不少业务,其中不乏有一些超大规模以及百万 QPS 级的业务,线上服务均稳定运行中。﹀
﹀
﹀

给你一本武林秘籍,和KeeWiDB一起登顶高性能

Hi,我是KeeWiDB