
终于有人把Spring Cloud+Nginx架构的主要组件给讲明白了
Spring Cloud+Nginx架构的主要组件
以crazy-springcloud开发脚手架为例,一个Spring Cloud+Nginx应用的架构如图1-1所示。
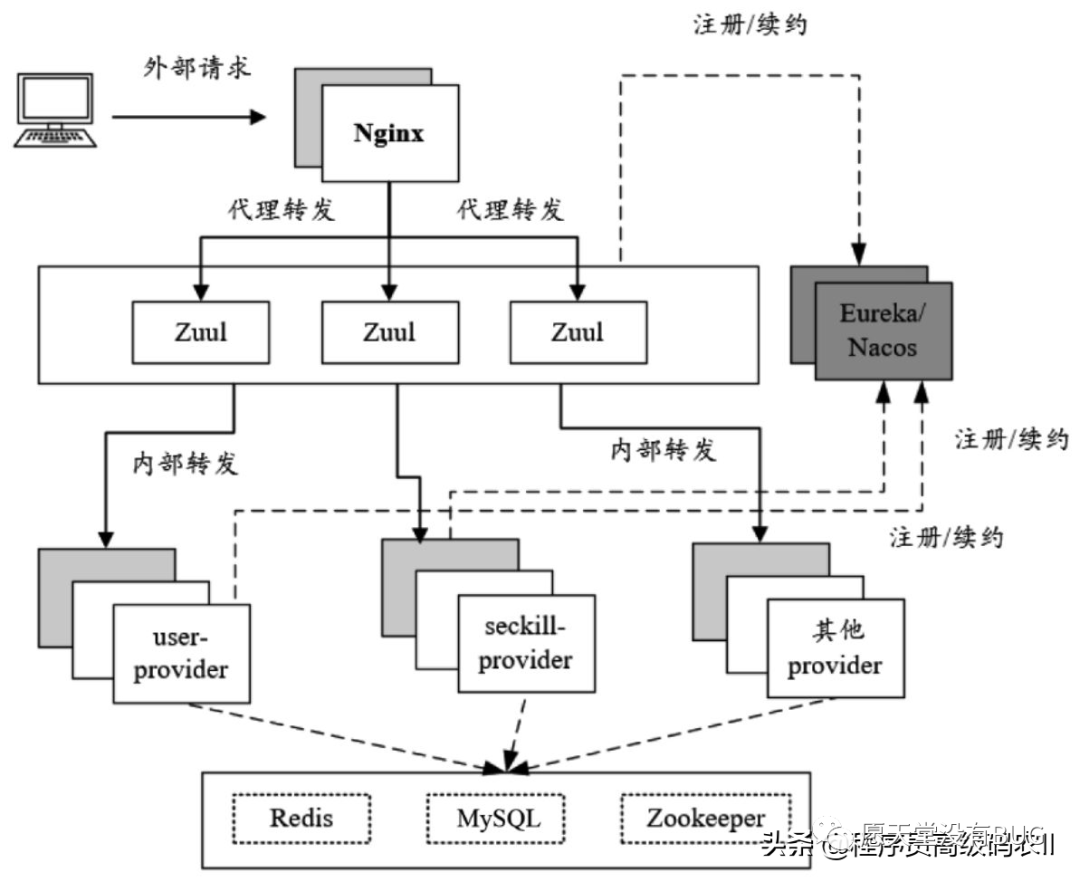
图1-1 基于Spring Cloud+Nginx的应用架构
Nginx作为反向代理服务器,代理内部Zuul网关服务,通过Nginx自带的负载均衡算法实现客户端请求的代理转发、负载均衡等功能。
Zuul网关主要实现了微服务集群内部的请求路由、负载均衡、统一校验等功能。虽然在路由服务和负载均衡方面,Zuul和Nginx的功能比较类似,但是Zuul是自身注册到Eureka/Nacos,通过微服务的serviceID实现微服务提供者之间的路由和转发。
Eureka、Nacos都是Spring Cloud技术体系中提供服务注册与发现的中间件。Eureka是Netflix开源的一款产品,提供了完整的服务注册和发现,是Spring Cloud“全家桶”中的核心组件之一。
Nacos是阿里巴巴推出来的一个开源项目,也是一个服务注册与发现中间件,它用于完成服务的动态注册、动态发现、服务管理,还兼具了配置管理的功能。Nacos提供了一组简单易用的特性集,用于实现动态服务发现、服务配置、服务元数据及流量管理。
由于新版本的Eureka已经闭源,而阿里巴巴的Nacos除了具备Eureka注册中心功能外,还具备Spring Cloud Config配置中心的功能,因此大大地降低了使用和维护的成本。另外,Nacos还具有分组隔离功能,一套Nacos集群可以支撑多项目、多环境。综合上述多个原因,在实际的开发场景中,推荐大家使用Nacos。但是,本文出于学习目的,注册中心和配置中心的内容还是介绍Eureka+Config组合,其实在原理上,Nacos和Eureka+Config组合是差不多的。
除了一系列基础设施中间件技术组件之外,微服务架构中大部分独立业务模型都是以服务提供者的角色出现的。一般来说,系统可以按照各类业务模块进行细粒度的微服务拆分,例如秒杀系统中的用户、商品等,每个业务模块拆分成一个微服务提供者Provider组件,作为独立应用程序进行启动和执行。
在Spring Cloud生态中,微服务提供者Provider之间的远程调用是通过Feign+Ribbon+Hystrix组合来完成的:Feign用于完成RPC远程调用的代理封装;Ribbon用于在客户端完成各远程目标服务实例之间的负载均衡;Hystrix用于完成自动熔断降级等多个维度的RPC保护。在Nginx+Spring Cloud架构中还存在一系列辅助中间件,包括日志记录、链路跟踪、应用监控、JVM性能指标、物理资源监控等等。本文并没有对上述辅助中间件做专门的介绍。
Spring Cloud和Spring Boot的版本选择
Spring Cloud是基于Spring Boot构建的,它们之间的版本有配套的对应关系。在构建项目时,要注意版本之间的这种对应关系,版本若对应不上则会出现问题。
Spring Cloud和Spring Boot的版本配套关系如表1-1所示。
表1-1 Spring Cloud与Spring Boot的版本配套关系
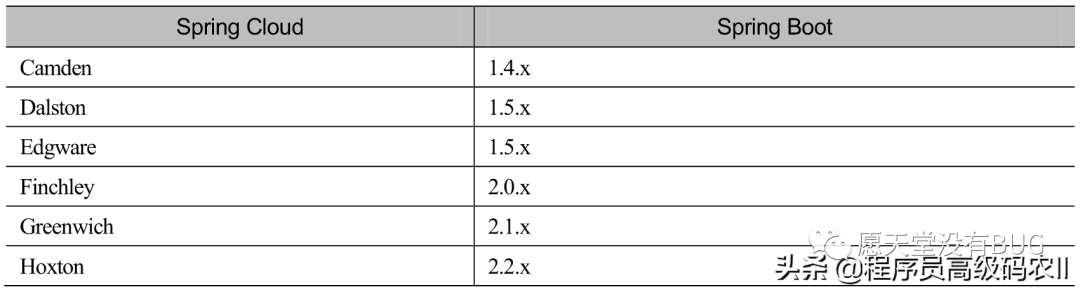
表1-1 Spring Cloud与Spring Boot的版本配套关系
Spring Cloud包含一系列子组件,如Spring Cloud Config、Spring Cloud Netflix、Spring Cloud Openfeign等,为了防止与这些子组件的版本号混淆,Spring Cloud的版本号全部使用英文单词形式命名。具体来说,Spring Cloud的版本号使用了英国伦敦地铁站的名称来命名,并按字母A~Z的次序发布版本,它的第一个版本叫作Angel,第二个版本叫作Brixton,以此类推。另外,每个大版本在解决了一个严重的Bug后,Spring Cloud会发布一个Service Release版本(小版本),简称SRX版本,其中X是顺序的编号,比如Finchley.SR4是Finchley大版本的第4个小版本。
大家做技术选型时非常喜欢用最高版本,但是对于Spring全家桶的选择来说,高版本不一定是最佳选择。比如,目前最高的Spring CloudHoxton版本是基于Spring Boot 2.2构建的,Spring Boot 2.2又是基于Spring Framework 5.2构建的,也就是说,这是一次整体的、全方位的大版本升级。大家在项目上会用到非常多的第三方组件,总会有一些组件没有来得及进行配套升级而不能兼容Spring Boot 2.2或SpringFramework 5.2,如果贸然地进行基础框架的整体升级,就会给项目开发带来各种各样的疑难杂症,甚至带来潜在的线上Bug。
除此之外,Spring Cloud高版本推荐了不少自家的新组件,但是这些新组件没有经过大规模实践应用的考验,其功能尚待丰富和完善。以负载均衡组件为例,Spring Cloud Hoxton推荐的自家组件springcloud-loadbalancer在功能上与Ribbon的负载均衡功能相比就弱很多。
Spring Cloud Finchley到Greenwich版本的升级其实很小,可以说微乎其微,主要是提升了对Java 11的兼容性。然而,在当前的生产场景中Java 8才是各大项目的主流选择,另外Java 11(2019年4月之后的升级补丁)已经不完全免费了。当然,和Java 11一样,Java 8在2019年4月之后的补丁版本也面临收费的问题。使用Java 8的理由是,自2014年3月18日发布起至目前,Java 8被广泛使用,且被维护了这么多年,已经非常成熟和稳定了。
综上所述,本文选用了Spring Cloud Finchley作为学习、研究和使用的版本,推荐使用的子版本为Finchley.SR4。具体的Maven依赖坐标如下:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-dependenciesartifactId>
<version>Finchley.SR4version>
<type>pomtype>
<scope>importscope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-dependenciesartifactId>
<version>2.0.8.RELEASEversion>
<scope>importscope>
<type>pomtype>
dependency>
dependencies>
dependencyManagement>Spring Cloud微服务开发所涉及的中间件
在基于crazy-springcloud脚手架(其他的脚手架类似)的微服务开发和自验证过程中,所涉及的基础中间件大致如下:
1.ZooKeeper
ZooKeeper是一个开放源码的分布式协调应用程序,是大数据框架Hadoop和HBase的重要组件。在分布式应用中,它能够高可用地提供保
障数据一致性的很多基础功能:分布式锁、选主、分布式命名服务等。
在crazy-springcloud脚手架中,高性能分布式ID生成器用到了ZooKeeper。
2.Redis
Redis是一个高性能的缓存数据库。在高并发的场景下,Redis可以对关系数据库起到很好的缓冲作用;在提高系统的并发能力和响应速度方面,Redis至关重要。crazy-springcloud脚手架的分布式Session用到了Redis。
3.Eureka
Eureka是Netflix开发的服务注册和发现框架,它本身是一个REST服务提供者,主要用于定位运行在AWS(Amazon云)上的中间层服务,以达到负载均衡和中间层服务故障转移的目的。Spring Cloud将Eureka集成在子项目spring-cloud-netflix中,以实现Spring Cloud的服务注册和发现功能。
4.Spring Cloud Config
Spring Cloud Config是Spring Cloud全家桶中最早的配置中心,虽然在生产场景中很多企业已经使用Nacos或者Consul整合型的配置中心替代了独立的配置中心,但是Config依然适用于Spring Cloud项目,通过简单地配置即可使用。
5.Zuul
Zuul是Netflix开源网关,可以和Eureka、Ribbon、Hystrix等组件配合使用,Spring Cloud对Zuul进行了整合与增强,使用它作为微服务集群的内部网关,负责给集群内部的各个Provider(服务提供者)提供RPC路由和对请求进行过滤。
6.Nginx/OpenResty
Nginx是一个高性能HTTP和反向代理服务器,是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点开发的Web服务器。Nginx源代码以类BSD许可证的形式对外发布,它的第一个公开版本0.1.0在2004年10月4日发布,1.0.4版本在2011年6月1日发布。Nginx因高稳定性、丰富的功能集、内存消耗少、并发能力强而闻名全球,并被广泛使用,百度、京东、新浪、网易、腾讯、淘宝等都是它的用户。OpenResty是一个基于Nginx与Lua的高性能Web平台,它的内部集成了大量精良的Lua库、第三方模块以及大多数的依赖项,用于快速搭建能够处理超高并发的扩展性极高的动态Web应用、Web服务和动态网关。
以上中间件的端口配置以及部分安装与使用的演示视频如表1-2所示。
表1-2 本文案例涉及的主要中间件的端口配置以及部分安装与使用的演示视频
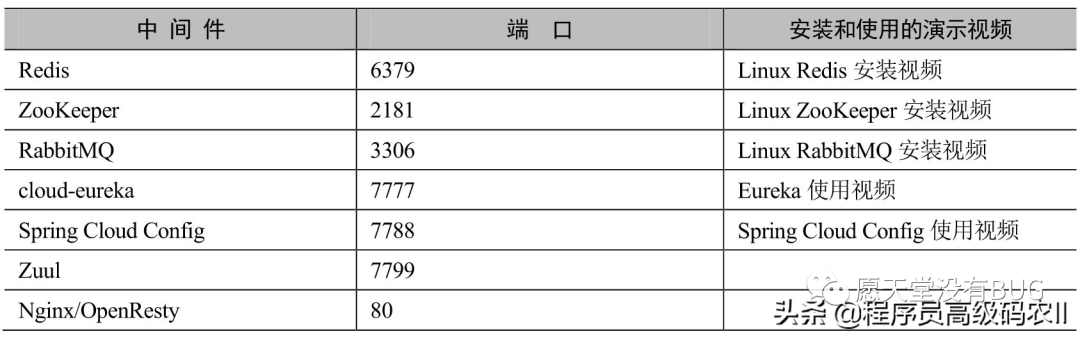
Spring Cloud微服务开发和自验证环境
在开始学习Spring Cloud核心编程之前,先来介绍一下开发和自验证环境的准备、中间件的安装以及抓包工具的准备。
开发和自验证环境的系统选项和环境变量配置
首先介绍开发和自验证系统的选型。大部分开发人员学习开发都用过Windows环境,在这种情况下,强烈建议使用虚拟机装载CentOS作为自验证环境。为什么要推荐CentOS呢?
1.提前暴露生产环境中的问题
在生产环境上,90%以上的Java应用都是使用Linux环境(如CentOS)来部署的。因此,使用CentOS作为自验证环境可以提前暴露生产环境中的潜在问题,避免在开发时没有发现有问题的程序,一旦部署到生产环境中就出现问题(笔者亲历)。
2.学习Shell命令和脚本
在生产环境中定位、分析、解决线上Bug时,需要用到基础的Shell命令和脚本,因此平时要多使用、多练习。另外,Shell命令和脚本是Java程序员必知必会的面试题。使用CentOS作为自验证环境能方便大家学习Shell命令和脚本。
当然,可以借助一些文件同步或共享工具提高开发效率。比如,可以通过VMware Tools共享Windows和CentOS之间的文件夹,这样在后续的Lua脚本的开发和调试过程中能避免来回地复制文件。
这里给大家介绍一下crazy-springcloud脚手架开发和自验证环境的准备,主要涉及两个方面:
(1)中间件(含Eureka、Redis、MySQL等)相关信息的环境变量的配置。
(2)主机名称的配置。
对于中间件相关信息(如IP地址、端口、用户账号等),很多项目都是直接以明文编码的方式存放在配置文件中,这样存在安全隐患甚至会引发泄密的风险。对于这些信息,建议通过操作系统环境变量进行配置,然后在配置文件中使用环境变量而不是明文编码。
例如,可以对Eureka的IP提前配置好环境变量EUREKA_ZONE_HOST,然后在应用的配置文件bootstrap.yml中按照如下方式来使用:
eureka:
client:
serviceUrl:
defaultZone: ${SCAFFOLD_EUREKA_ZONE_HOSTS:http://localhost:7777/eureka/}在上面的配置中,通过${
SCAFFOLD_EUREKA_ZONE_HOSTS}表达式从环境变量中获取Eureka的service-url地址。环境变量SCAFFOLD_EUREKA_ZONE_HOSTS后面跟着一个冒号和一个默认值,表示如果环境变量值为空,就会使用默认值
http://localhost:7777/eureka/作为配置项的值。
通过环境变量配置中间件的信息有什么好处呢?
一是使配置信息的切换多了一层灵活性,如果切换IP,那么只需修改环境变量即可;二是可以不用在配置文件中以明文编码方式存放密码之类的敏感信息,多了一层安全性。
crazy-springcloud微服务开发脚手架用到的环境变量较多,以自验证环境CentOS中的配置文件/etc/profile为例,部分内容大致如下:
export SCAFFOLD_DB_HOST=192.168.233.128
export SCAFFOLD_DB_USER=root
export SCAFFOLD_DB_PSW=root
export SCAFFOLD_REDIS_HOST=192.168.233.128
export SCAFFOLD_REDIS_PSW=123456
export SCAFFOLD_EUREKA_ZONE_HOSTS=http://192.168.233.128:7777/eureka/
export RABBITMQ_HOST=192.168.233.128
export SCAFFOLD_ZOOKEEPER_HOSTS=192.168.233.128:2181以上环境变量中的192.168.233.128是笔者自验证环境CentOS虚拟机的IP地址,Redis、ZooKeeper、Eureka、MySQL、Nginx等中间件都运行在这台虚拟机上,大家在运行crazy-springcloud微服务开发脚手架之前需要进行相应的更改。
最后介绍一下有关主机名称的配置。如果在调试过程中直接通过IP访问REST接口,那么在Fiddler工具抓包中查看报文就不方便。为了方便抓包,将IP地址都映射成主机名称。在笔者使用的Windows开发环境中,hosts文件内配置的主机名称如下:
127.0.0.1 crazydemo.com
127.0.0.1 file.crazydemo.com
127.0.0.1 admin.crazydemo.com
127.0.0.1 xxx.crazydemo.com
192.168.233.128 eureka.server
192.168.233.128 zuul.server
192.168.233.128 nginx.server
192.168.233.128 admin.nginx.server注意,本书后文的演示用例用到的URL会使用以上主机名称取代IP地址。
使用Fiddler工具抓包和查看报文
在微服务程序开发和验证的过程中,一般来说对HTTP接口发起请求有多种方式:
(1)直接发起请求。
(2)通过内部网关代理(如Zuul)发起请求。
(3)通过外部网关反向代理(如Nginx)发起请求。
以crazy-springcloud脚手架中的uaa-provider服务的HTTP接口/api/user/detail/v1为例,通过以上3种方式发起请求的HTTP链路示意图如图1-2所示。
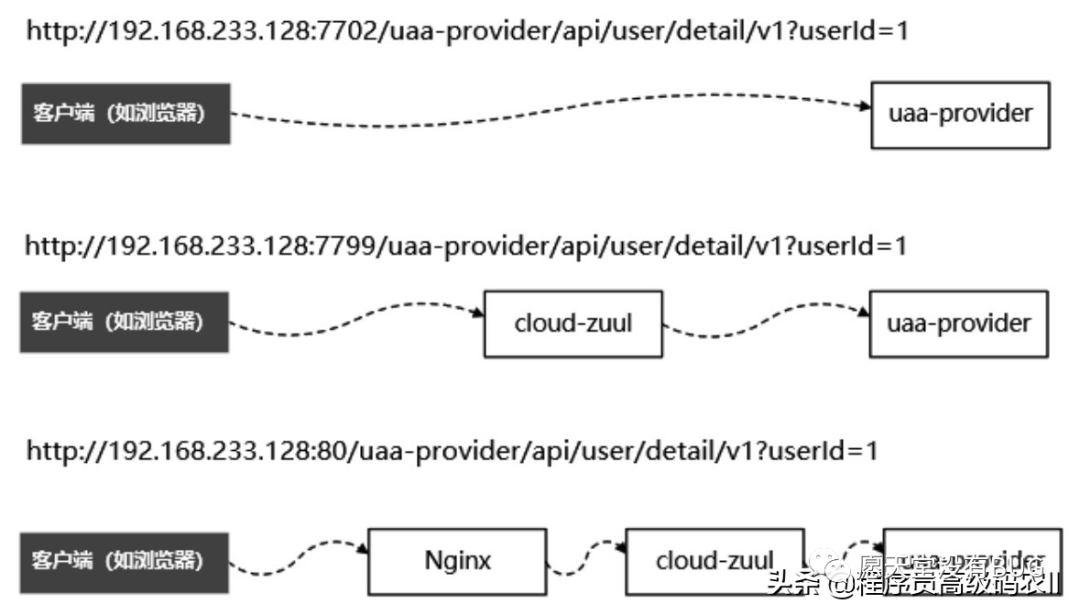
图1-2 3种方式请求uaa-provider的HTTP链路示意图
在生产环境下,为了满足内外网之间的转发、多服务器之间的负载均衡要求,外部反向代理(Nginx)往往不止一层。因此,请求的HTTP链路往往更加复杂。
无论是在开发环境、自验证环境、测试环境还是在生产环境中,查看HTTP接口的访问链路和报文内容对于定位、分析、解决问题来说都非常重要,这就需要使用抓包工具。抓包工具的类型比较多,笔者目前使用较多的为Fiddler。
比如,在调试本书crazy-springcloud脚手架中的uaa-provider功能时,使用Fiddler能全面地查看发往服务端的HTTP报文的请求头和响应头,如图1-3所示。
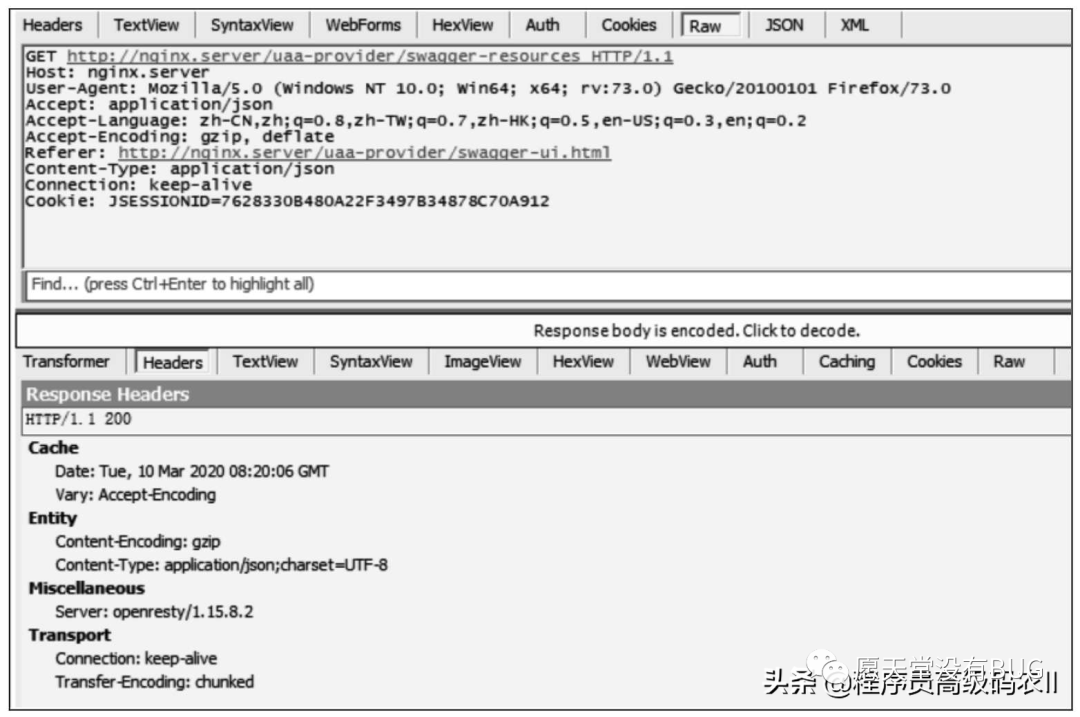
图1-3 使用Fiddler查看请求头和响应头
在开发过程中,Fiddler这类抓包工具的使用对于分析和定位问题非常有用。笔者经常使用Fiddler完成下面的工作:
(1)查看REST接口的处理时间,在解决性能问题时帮助查看接口的整体时间。
(2)查看REST接口的请求头、响应头、响应内容,主要用于查看请求URL、请求头、响应头是否正确,并且在必要的时候可以将所有请求头一次性地复制到Postman等请求发起工具,帮助新请求快速地构造同样的HTTP头部。
(3)请求重发,除了可以使用独立的请求工具(如SwaggerUI/Postman等)重发请求之外,还可以在Fiddler中直接进行请求重发,重发的请求有相同的头部和参数,调试时非常方便。
crazy-springcloud微服务开发脚手架
无论是单体应用还是分布式应用,如果从零开始开发,那么都会涉及很多基础性的、重复性的工作,比如用户认证、Session管理等。
有了开发脚手架,这些基础工作就可以省去,直接利用脚手架提供的基础模块,然后按照脚手架的规范进行业务模块的开发即可。
笔者在开源平台看到过不少开源的脚手架,但是发现这些脚手架很少可以直接拿来进行业务模块的开发,要么封装过于重量级而不好解耦,要么业务模块分包不清晰而不方便开发,所以本着简洁和清晰的原则,笔者发起的疯狂创客圈社群推出了自己的微服务开发脚手架crazy-springcloud,它的模块和功能如下:
crazymaker-server -- 根项目
│ ├─cloud-center -- 微服务的基础设施中心
│ │ ├─cloud-eureka -- 注册中心
│ │ ├─cloud-config -- 配置中心
│ │ ├─cloud-zuul -- 网关服务
│ │ ├─cloud-zipkin -- 监控中心
│ ├─crazymaker-base -- 公共基础依赖模块
│ │ ├─base-common -- 普通的公共依赖,如utils类的公共方法
│ │ ├─base-redis -- 公共的Redis操作模块
│ │ ├─base-zookeeper -- 公共的ZooKeeper操作模块
│ │ ├─base-session -- 分布式Session模块
│ │ ├─base-auth -- 基于JWT + SpringSecurity的用户凭证与认证模块
│ │ ├─base-runtime -- 各Provider的运行时公共依赖,装配了一些通用Spring
IOC Bean实例
│ ├─crazymaker-uaa -- 业务模块: 用户认证与授权
│ │ ├─uaa-api -- 用户DTO、Constants等
│ │ ├─uaa-client -- 用户服务的Feign远程客户端
│ │ ├─uaa-provider -- 用户认证与权限的实现,包含controller层、service层、dao层的代码实现
│ ├─crazymaker-seckill -- 业务模块:秒杀练习
│ │ ├─seckill-api -- 秒杀DTO、Constants等
│ │ ├─seckill-client -- 秒杀服务的Feign远程调用模块
│ │ ├─seckill-provider -- 秒杀服务核心实现,包含controller层、service层、 dao层的代码实现
│ ├─crazymaker-demo -- 业务模块:练习演示
│ │ ├─demo-api -- 演示模块的DTO、Constants等
│ │ ├─demo-client -- 演示模块的Feign远程调用模块
│ │ ├─demo-provider -- 演示模块的核心实现,包含controller层、service层、 dao层的代码实现在业务模块如何分包的问题上,大部分企业都有自己的统一规范。crazy-springcloud脚手架从职责清晰、方便维护、能快速导航代码的角度出发,将每一个业务模块细分成以下3个子模块。
(1){module}-api:该子模块定义了一些公共的Constants业务常量和DTO传输对象,既被业务模块内部依赖,又可能被依赖该业务模块的外部模块所依赖。
(2){module}-client:该子模块定义了一些被外部模块所依赖的Feign远程调用客户类,是专供给外部模块的依赖,不能被内部的其他子模块所依赖。
(3){module}-provider:该子模块是整个业务模块的核心,也是一个能够独立启动、运行的服务提供者(Application)。该模块包含涉及业务逻辑的controller层、service层、dao层的完整代码实现。
crazy-springcloud微服务开发脚手架在以下两方面进行了弱化:
(1)在部署方面对容器的介绍进行了弱化,没有使用Docker容器而是使用Shell脚本。这有多方面的原因:一是本脚手架的目的是学习,使用Shell脚本而不是Docker去部署,方便大家学习Shell命令和脚本;二是Java和Docker其实整合得很好,学习起来非常容易,稍加配置就能做到一键发布,找点资料学习一下就可以轻松掌握;三是部署和运维是一项专门的工作,生产环境的部署,甚至是整个自动化构建和部署的工作实际上是属于运维的专项工作,由专门的运维人员去完成,而部署的核心仍然是Shell脚本,所以对于开发人员来说掌握Shell脚本才是重中之重。
(2)对监控软件的介绍进行了弱化。本书没有专门介绍链路监控、JVM性能指标、熔断器监控软件的使用,这也有多方面的原因:一是监控软件太多,如果介绍得太全,篇幅就不够,介绍得太少,大家又不一定会用到;二是监控软件的使用大多是一些软件的操作步骤和说明,原理性的内容比较少,传播这类知识使用视频的形式比文字的形式效果更好。疯狂创客圈后续可能会推出一些微服务监控方面的教学视频供大家参考,请大家关注社群博客。无论如何,只要掌握了Spring Cloud的核心原理,那么掌握监控组件的使用对大家来说基本上就是小菜一碟。
以秒杀作为Spring Cloud+Nginx的实战案例
本文的综合性实战案例是实现一个高性能的秒杀系统。为何要以秒杀作为本书的综合性实战案例呢?先回顾一下在单体架构还是主流的年代,大家学习J2EE技术时的综合性实战案例。一般来说,都是从0开始编写代码,一行一行地编写一个购物车应用。通过编写购物车应用能对J2EE有一个全方位的练习,包括前端的HTML网页、JavaScript脚本,后端的MVC框架、数据库、事务、多线程等各种技术。
时代在变,技术的复杂度在变,前端和后端的分工也变了。现在的J2EE开发已经进入分布式微服务架构的时代,前端和后端框架都变得非常复杂,前端和后端工程师已经有比较明确的分工。后端程序员专门做Java开发,前端程序员专门做前端的开发。后端程序员可以不需要懂前端的技术,如Vue、TypeScript等,当然,很多前端程序员也不一定需要懂后端技术。
相比单体服务时代,现在的分布式开发时代学习Java后端技术的难度大多了。首先面临一大堆分布式、高性能中间件的学习,比如Netty、ZooKeeper、RabbitMQ、Spring Cloud、Redis等都是当今后端程序员必知必会的。然后像JMeter这类压力测试工具和Fiddler这类抓包工具,已经成为每个后端程序员必须掌握的知识。因为在分布式环境下需要定位、发现并解决数据一致性、高可靠性等问题,通过压力测试,本来很正常的代码也会在运行时出现很多性能相关的问题。
另外,随着移动互联网、物联网的发展,当前面临的高并发场景已经不局限于电商,在其他的应用中也越来越多。所以,现在高并发开发技术由少数工程师需要掌握的高精尖技术变成了大多数人都需要掌握的基础技能。一般来说,高并发开发的三大利器为缓存、降级和限流。缓存的目的是提高系统访问速度,它是对抗高并发的银弹;而降级是当服务出问题或者服务影响到核心流程时,可以将服务暂时屏蔽掉,待高峰或者问题解决后再打开;而有些场景并不能用缓存和降级来解决,比如稀缺资源(秒杀、抢购)、写数据(如评论、下单)等,这种情况下可以使用限流措施来对接口进行保护。
有了缓存、降级和限流这三大利器,遇到像京东618、阿里双11这样的高并发应用场景,才不用担心瞬间流量导致系统雪崩,哪怕是最终只能做到有损的服务,也不会出现某些小电商平台在活动期间服务器宕机数小时的事故。
秒杀程序的业务足够简单,涉及的技术又足够全面,可以说是分布式应用场景非常好的实战案例。另外,现在IT行业人才流动性比较大,大家都会为面试做准备。在面试中,秒杀业务所覆盖的缓存、降级、高并发限流、分布式锁、分布式ID、数据一致性等问题一般是重点、热门问题。
本文给大家讲解的内容是Spring Cloud+Nginx架构的主要组件
下篇文章给大家讲解的是Spring Cloud入门实战;
觉得文章不错的朋友可以转发此文关注小编;
感谢大家的支持!
本文就是愿天堂没有BUG给大家分享的内容,大家有收获的话可以分享下,想学习更多的话可以到微信公众号里找我,我等你哦。