
如何看待 Google Docs 将从 HTML 迁移到基于 Canvas 渲染?
共 5089字,需浏览 11分钟
·
2022-02-09 17:29
Google Docs 这么做是必然选择,而且是所有号称要做「云端Office」在线文档的终极形态。
相关问题回答如下
- Google Docs 会采用 canvas 是否标志着网页三剑客(HTML、CSS、JS)的没落?
- Google Docs 之前的技术选型有什么问题?
- Google Docs 会如何技术升级(瞎猜)?
1. Google Docs 会采用 canvas 是否标志着网页三剑客(HTML、CSS、JS)的没落?
肯定不是,采用 canvas 渲染取决于 Google Docs 的项目复杂度和特殊性,99.9999%的项目用网页三剑客无疑是更好的选择,文本处理器(Google Docs)有超高的一致性和性能要求,这些要求绝大多数应用根本不需要考虑,可惜,Google Docs 就是那 0.0001% 它是极其特殊的存在,而且我个人认为 Google Docs 并不会重新造一个类似于 flutter 的 UI 系统,而是重写「字体解析」「字体整形」「文本布局」「文字处理渲染引擎」等一系列相关的引擎,总之,Google Docs 用 canvas 干的事情,跟大家理解用 canvas 干的不是一回事。
2. Google Docs 之前的技术选型有什么问题?
Google Docs 2010 之前基于 contenteditable ,之后不基于 contenteditable 但仍基于DOM。
基于 contenteditable 的富文本编辑器会产生非常多的问题,已经是老生常谈了,下面这篇文章已经写得比较清楚了:
为什么 ContentEditable 很恐怖 - OSCHINA - 中文开源技术交流社区Google Docs 在 2010 年也解释了为什么抛弃 contenteditable:
https://drive.googleblog.com/2010/05/whats-different-about-new-google-docs.html简单而言就是为了一致性、高级功能(标尺、脚注、分页)、协同编辑。
其实关于 contenteditable 的技术选型问题无需我多言,以上两篇文章足以解答。
我们重点谈抛弃了 contenteditable 之后为什么依然有问题?
Google Docs 已经说明了是为了「一致性」和「性能」考虑。
首先,我们解释一下在线文档的一致性是什么?
如果你的在线文档基于浏览器,那么必然会用到浏览器实现的特性,而各大浏览器实现的方式不同,呈现的效果也不同,这就导致了不同浏览器编辑同一份文档会出现不一致,现在在线协同是这些软件的标榜功能之一,如果编辑的呈现效果不一致,那么何谈「协同编辑」?
实际上现代浏览器的一致性差异已经比较小了(相比于2010年 IE 还在大行其道的年代),所以大多数情况下一致性是可以接受的,但是依然有一些一致性问题困扰着开发者。
比如「语雀」基于浏览器实现了选取拖蓝,这就导致了不一致性,如果你在 Firefox 下双击选区会选择「一句文字」进行拖蓝:

如果你在 Chrome 下进行双击选取拖蓝,它会拖蓝「一个词组」:

归根到底是 Chrome 相比于 Firefox ,多进行了一步基于 CC-CEDICT 的分词操作,Chrome 会优先选择词组而不是句子:
当然你可以用各种方法把这些不一致性抹平,比如拖蓝选区的一致性问题也可以解决,那就是自己写一个相关的库替代浏览器自带的拖蓝选区功能,但是这就像一个无底洞,你不知道像浏览器这种庞然大物到底有多少不一致性,每一次更新都可能带来变化。
大家要记住,越多的依赖浏览器的能力,就越多的受到浏览器一致性问题的困扰
2010 年后 Google Docs 计算出文本的大小进行绝对定位排版,实现了自己全新的文本布局引擎,包括选区、光标、排版都进行了自研,似乎已经彻底摆脱了浏览器的控制,但是事实却不是这样。
现在的 Google Docs 的文本布局引擎是基于 「div+span+绝对定位」 的方式实现的,实际上并没有脱离 DOM,这就到了大量的操作依然依赖于浏览器的底层提供的能力。
双向文本(BIDI)
我们的现代汉字和实际上绝大多数文字的书写方式是自左向右的,但是也有不少例外,阿拉伯文、希伯来文的书写顺序是自右向左,而古代汉语、传统蒙语等是纵向排版的,这需要文本处理器可以识别不同的文字进行不同的处理。
https://zh.wikipedia.org/wiki/%E9%9B%99%E5%90%91%E6%96%87%E7%A8%BFUnicode 有相关的 BIDI 算法,而 Google Docs 选择了基于浏览器的能力,大家看看这段阿拉伯文, Google Docs 的处理方式,利用了 CSS 的属性,而并非自己实现。

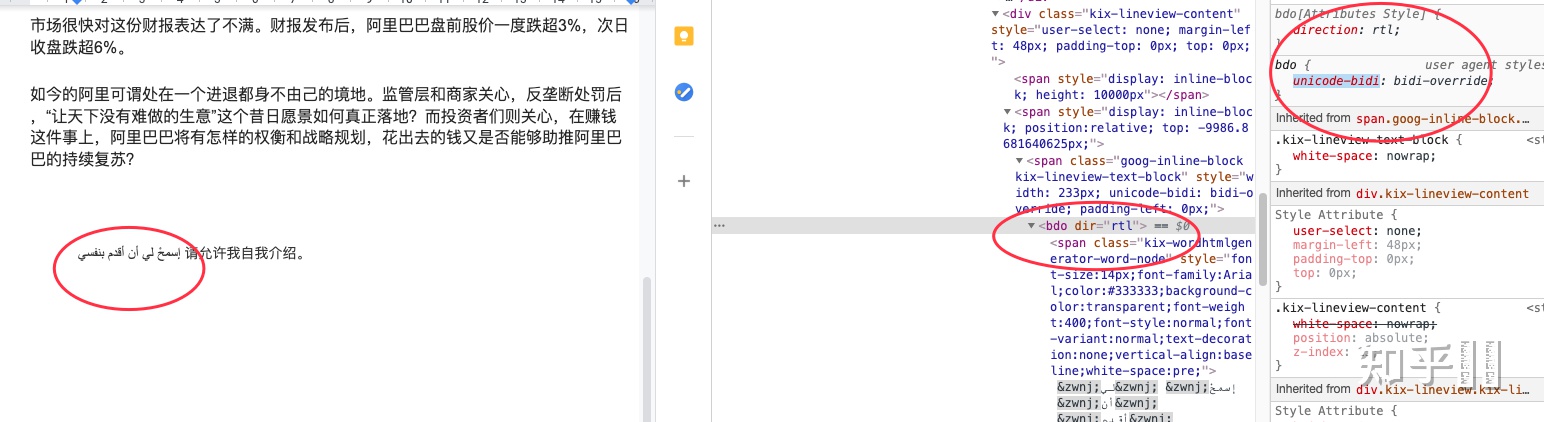
同样的, CSS 基于浏览器提供的底层算法,苹果系统需要 CoreText 提供支持,而 Linux 下则是 :
fribidi/fribidi幸好这个算法是有通用标准的,实现起来应该大差不差,如果没有通用解决方法,各个浏览器自己实现,那么不一致问题就会出现。
字体解析与渲染
我们提到了,Google Docs 的字体解析与渲染依然是基于浏览器的,看下图,直接 span + css 对文字进行了排版:

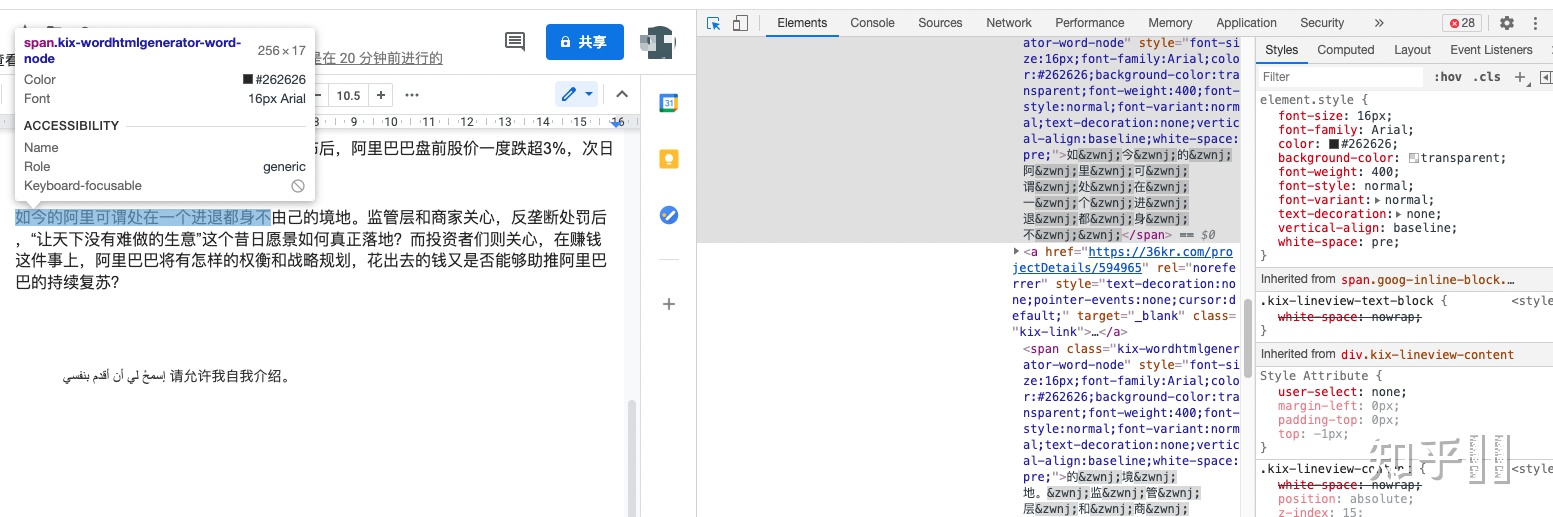
浏览器在不同平台依赖的底层库也不一致,比如 windows 下的 DirectWrite,Mac 下的 Core Text 等等。
我就存在一个可能由于解析+渲染导致的不一致问题。
比如在 Google Docs 下我一台 Mac Mini 的 Chrome 呈现是这样的(存在bug),注意那个笑脸表情,光标所在的位置直接显示在笑脸上面:


当我打开同一台电脑、同一个文档,唯一的不同就是用 Firefox 打开后,显示是正确的,不仅如此所有其他电脑任何浏览器都是正确的,唯独这一台 Mac mini 用 Chrome 打开是错误的:


这就是我这台 Mac Mini 特有的系统级 Bug 导致的问题,因为这台 Mac mini 是通过时间机器从旧 MBP 上迁移的,而这个问题同样出现在旧 MBP,而旧 MBP 重置系统后问题消失了,旧 MBP 重置系统后跟 Mac mini 系统版本号一致,Chrome版本号也一致,但是没问题。
这说明,由于 Google Docs 依赖的浏览器提供的底层能力(浏览器的能力部分来自于操作系统),导致了这种不可控的 Bug。
说完一致性问题,我们再看看「性能」问题,这个依然是由于依赖浏览器的 DOM 导致的,虽然 Google Docs 在我看来已经很快了,用一些低端笔记本打开也挺流畅的,可能 Google Docs 有更高的性能要求吧。
目前 Google Docs 依然是我们上面所说的依赖 DOM,那么 Google Docs 的文字处理区域的回流、重绘依然是依靠浏览器自带的能力,Google Docs 目前除了文本布局是由自己接管之外,还得依靠浏览器,虽然对于绝大多数人浏览器提供的能力已经很够用了(我就觉得挺够用的 ),但是如果自己彻底接管整个文字处理区域的布局、排版,那么优化的上限会很高(下限也会很低,取决于开发者水平)。
至于 Google Docs 会如何优化,我在下面有自己的猜测。
Google Docs 背后技术升级的猜想
说了 Google Docs 为什么要升级技术,我们可以大胆猜测下 Google Docs 会如何升级技术。
接管字体相关的一切工作
从字体解析一直到光栅化必须由 Google Docs 自己控制,而非浏览器控制。
字体解析:这需要一个字体解析器,兼容 TrueType 和 OpenType 标准 ,并实现标准中的一系列特性,类似于这种:


文本整形(text shaping engine):文本整形是将一串字符代码(例如Unicode代码点)转换为正确排列的字形序列的过程,这些字形序列可以呈现在屏幕上或最终输出形式以包含在文档中。
这篇文章说的很清楚,为什么这一步必不可少:
Why do I need a shaping engine?举个简单的例子,阿拉伯文的字母出现在上下文不同的位置有四种不同的变体。
如阿拉伯文的mīm,单独书写为:

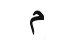
三个连写(mmm,显示为词头,词中,词尾形)就变为 :

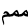
如果没有文本整形引擎,这一步无法实现。
比如如果没有文本整形引擎效果如下:


上图中我们文本框显示的是由浏览器渲染的是正确的的,下面的是字体解析器渲染的,如果没有文本整形,就是错误的。
如果字体解析器配合上文本整形引擎那么效果如下:


高级文本布局:目前 Google Docs 倒是实现了这一步,依靠绝对定位 + span 实现了对文本布局的控制,但是我猜想 Google Docs 用的方法是从 TextMetrics 倒推出文本前进宽度进行排版的(应该也没别的办法了),但是 TextMetrics 是个残废 API,很多属性都没有提供,而且短期内浏览器也不会提供,所以也只是能凑合用的程度。
TextMetrics 拿不到完整的 glyph list ,对于高级文本布局的排版只能凑合用大概,归根到底是浏览器不开放给开发者能力,那么如果字体相关的工作靠浏览器解析,他不给你你永远拿不到,这就是被浏览器厂商「卡脖子」,如果字体相关工作 Google Docs 自己「独立自主」,那么很多属性就可以拿到(比如unitsPerEm -字体内部坐标网格的大小,lineGap -行之间应包含的空间量,bbox-字体的边界框,等等等对高级文本布局排版非常有用的属性),可以进行精细化开发。


为了适应 Google Docs 的要求,必须实现包括但不限于:
- dibi 双向文本布局
- 文本断行
- 制表符
- 字间距、行间距、段间距等排版
- 页码、页眉、脚注等等
- 分页、分栏等
高性能渲染引擎:由于脱离了 DOM,虽然成功 「独立自主」,但是独立自主并非没有代价,那就是什么事情都得自己干。
浏览器提供了非常便捷的 DOM 直接供我们操作,但是用 canvas 你必须自己实现精灵、事件、动画,并自定义一系列控件,比如「列表」「表格」「按钮」「选区拖蓝」等等等,也就是 DOM 的一切现有的东西都无法复用,必须用 canvas 从头造一遍(至少Google Docs需要用到的东西)。
可以性能优化的点可能如下:
- 图形拾取优化:在 canvas 中文字、线条、表格、图片都是一视同仁的,都是 canvas 精灵,没了 DOM 都需要自己判断鼠标是否在某个精灵上,是否选中了某个精灵,才有可能触发鼠标或者键盘的各种事件,可以选择「离屏缓存 Canvas」或者「几何计算bbox」来进行判断,在大量文本、图片、表格等元素充斥的情况下保证性能很不容易。
- 局部渲染:很多时候我们修改的文本只涉及了某一段、某一行甚至某些文字,如果每次都全量渲染必然造成性能瓶颈,所以可以判断用户操作影响的范围,计算出局部刷新的影响的包围盒,只对影响范围内的元素进行刷新。
- 分片渲染:React Fiber 将一次大的渲染任务拆分为一系列小的渲染任务,每一个任务可以在浏览器的一帧(16ms)中执行完毕,并将任务分为高优先级(用户事件等)和 低优先级任务(普通渲染任务)分别处理。
我们也可以用同样的思路:
- 分拆渲染任务保证每个任务能在16毫秒内执行完
- 可以动态对任务进行调整,暂停、删除、终止任务
- 对不同类型的任务区分高低优先级,比如用户输入、拖蓝这种即时反馈的必须高优先级
还有什么预渲染、避免使用 shadow、避免使用浮点小数这种更常规的就不谈了。
除此之外还有光标处理、对象模型、复制粘贴、撤销等一系列问题应该都不是重点,总之,Google Docs 向传统桌面文字处理软件比如 WPS、Word 继续贴近了一大步,进入了 Web 文字处理软件的终极形态,从此之后应该不会有大的变化,只有小修小补了。
这种追求卓越的开发精神值得佩服,也不得不说,做这种事情需要大量人力、物力、时间的支撑,最后还是看出来,Google 真有钱!