
不会一致性hash算法,劝你简历别写搞过负载均衡
作者:小富
来源:SegmentFault 思否社区
大家好,我是小富~
这两天看到技术群里,有小伙伴在讨论一致性hash算法的问题,正愁没啥写的题目就来了,那就简单介绍下它的原理。下边我们以分布式缓存中经典场景举例,面试中也是经常提及的一些话题,看看什么是一致性hash算法以及它有那些过人之处。
构建场景
假如我们有三台缓存服务器编号node0、node1、node2,现在有3000万个key,希望可以将这些个key均匀的缓存到三台机器上,你会想到什么方案呢?
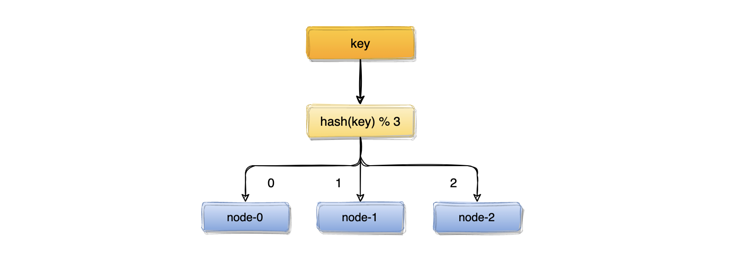
我们可能首先想到的方案,是取模算法hash(key)% N,对key进行hash运算后取模,N是机器的数量。key进行hash后的结果对3取模,得到的结果一定是0、1或者2,正好对应服务器node0、node1、node2,存取数据直接找对应的服务器即可,简单粗暴,完全可以解决上述的问题。
hash的问题
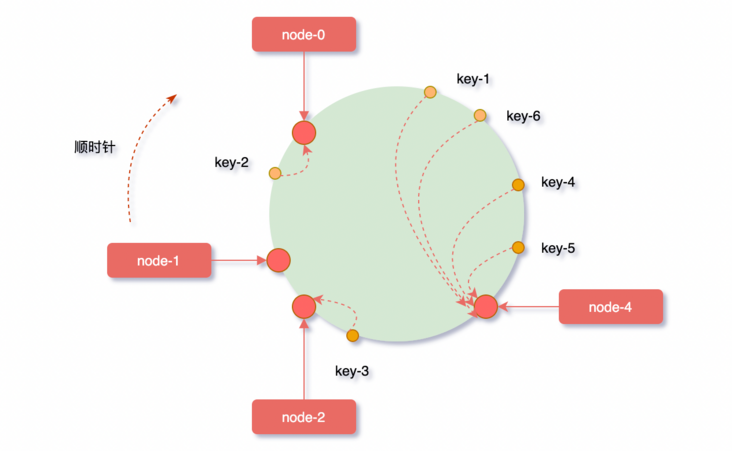
取模算法虽然使用简单,但对机器数量取模,在集群扩容和收缩时却有一定的局限性,因为在生产环境中根据业务量的大小,调整服务器数量是常有的事;而服务器数量N发生变化后hash(key)% N计算的结果也会随之变化。
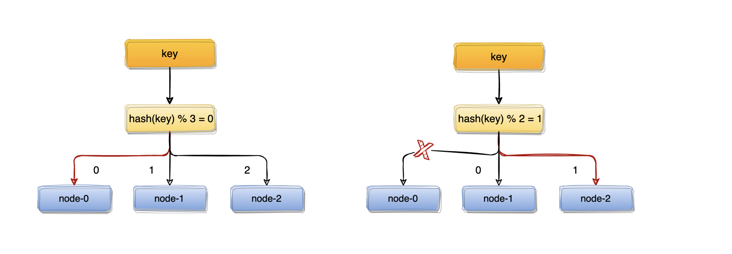
比如:一个服务器节点挂了,计算公式从hash(key)% 3变成了hash(key)% 2,结果会发生变化,此时想要访问一个key,这个key的缓存位置大概率会发生改变,那么之前缓存key的数据也会失去作用与意义。
大量缓存在同一时间失效,造成缓存的雪崩,进而导致整个缓存系统的不可用,这基本上是不能接受的,为了解决优化上述情况,一致性hash算法应运而生~
那么,一致性哈希算法又是如何解决上述问题的?
一致性hash
一致性hash算法本质上也是一种取模算法,不过,不同于上边按服务器数量取模,一致性hash是对固定值2^32取模。
IPv4的地址是4组8位2进制数组成,所以用2^32可以保证每个IP地址会有唯一的映射
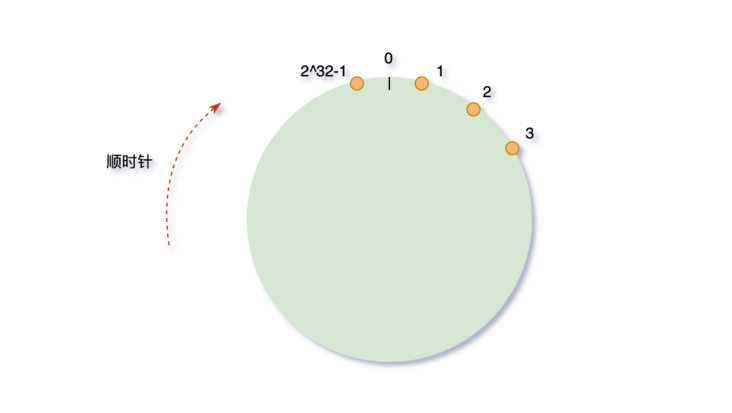
hash环
我们可以将这2^32个值抽象成一个圆环(不得意圆的,自己想个形状,好理解就行),圆环的正上方的点代表0,顺时针排列,以此类推,1、2、3、4、5、6……直到2^32-1,而这个由2的32次方个点组成的圆环统称为hash环。
那么这个hash环和一致性hash算法又有什么关系嘞?我们还是以上边的场景为例,三台缓存服务器编号node0、node1、node2,3000万个key。
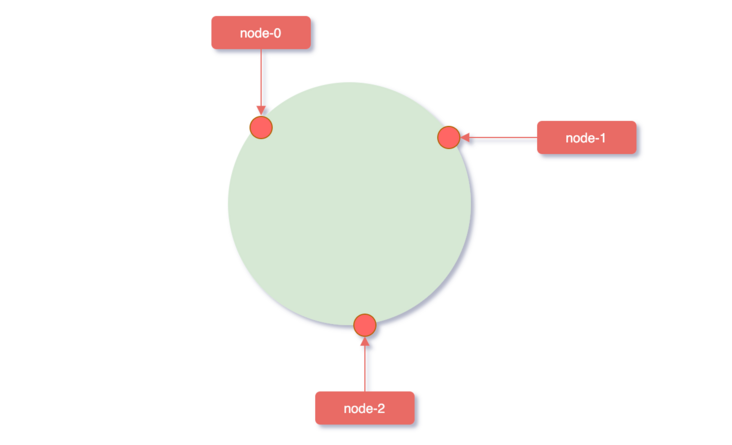
服务器映射到hash环
这个时候计算公式就从hash(key)% N 变成了hash(服务器ip)% 2^32,使用服务器IP地址进行hash计算,用哈希后的结果对2^32取模,结果一定是一个0到2^32-1之间的整数,而这个整数映射在hash环上的位置代表了一个服务器,依次将node0、node1、node2三个缓存服务器映射到hash环上。
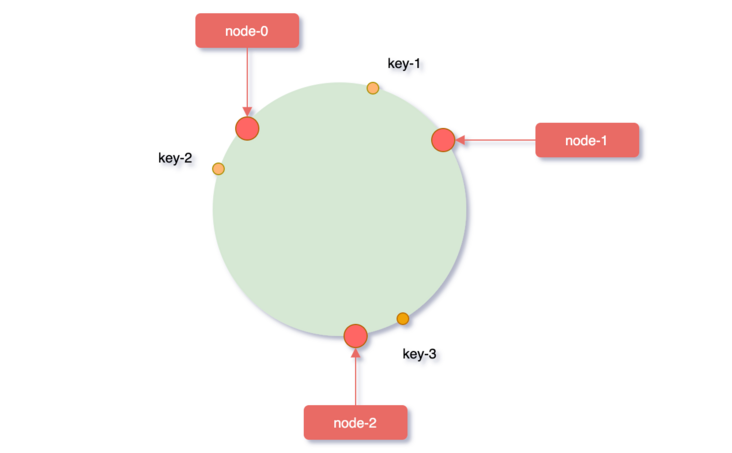
对象key映射到hash环
接着在将需要缓存的key对象也映射到hash环上,hash(key)% 2^32,服务器节点和要缓存的key对象都映射到了hash环,那对象key具体应该缓存到哪个服务器上呢?
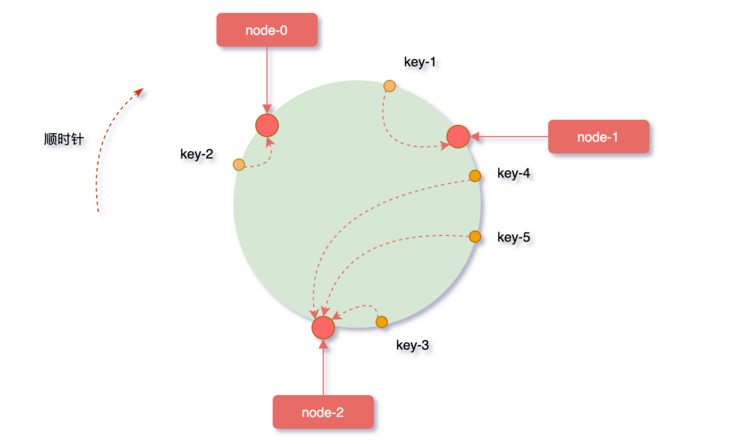
对象key映射到服务器
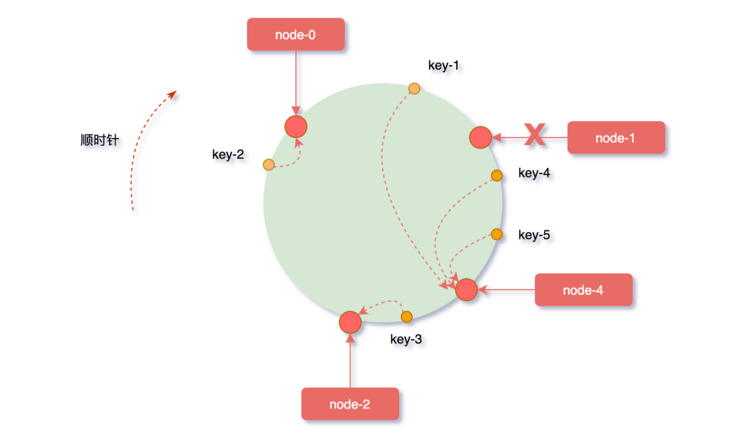
从缓存对象key的位置开始,沿顺时针方向遇到的第一个服务器,便是当前对象将要缓存到的服务器。
因为被缓存对象与服务器hash后的值是固定的,所以,在服务器不变的条件下,对象key必定会被缓存到固定的服务器上。根据上边的规则,下图中的映射关系:
key-1 -> node-1 key-3 -> node-2 key-4 -> node-2 key-5 -> node-2 key-2 -> node-0
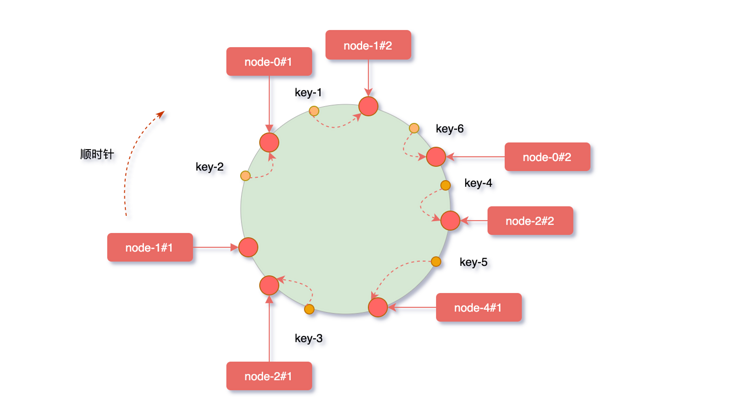
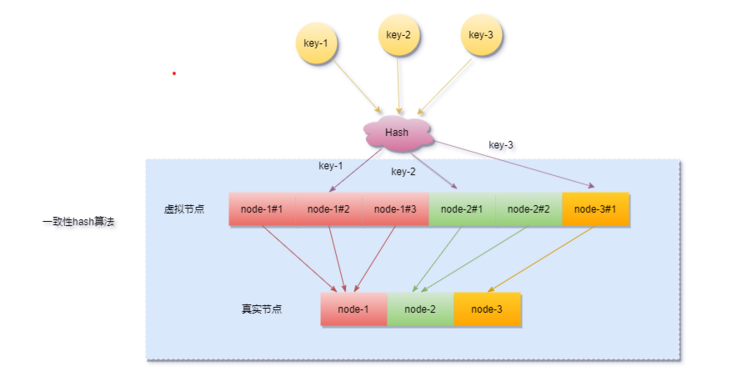
一致性hash的优势
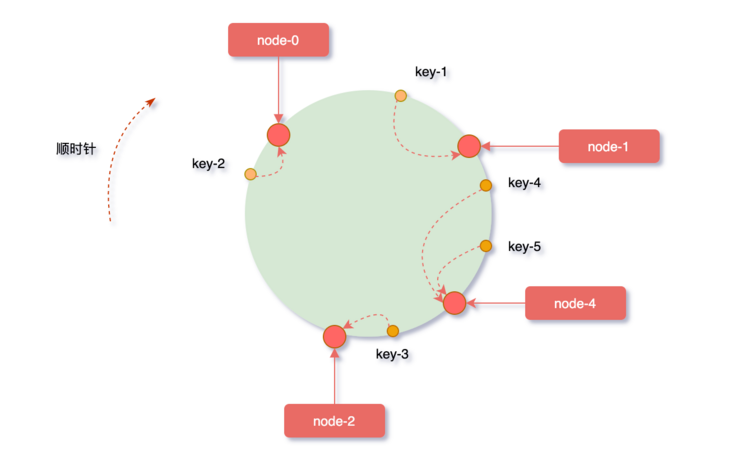

hash(10.24.23.227#1)% 2^32
hash(10.24.23.227#1)% 2^32 hash(10.24.23.227#2)% 2^32 hash(10.24.23.227#3)% 2^32
一致性hash的应用场景
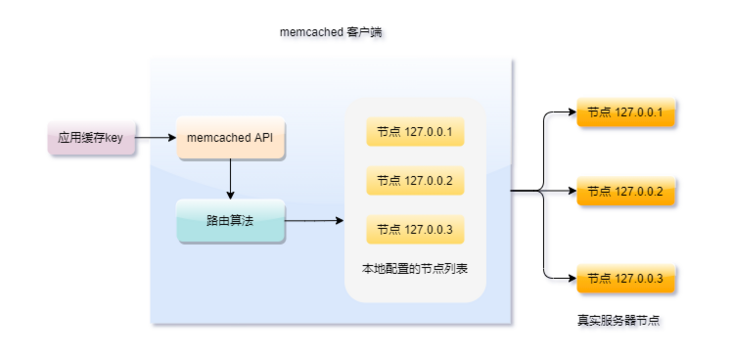
RPC框架Dubbo用来选择服务提供者 分布式关系数据库分库分表:数据与节点的映射关系 LVS负载均衡调度器 .....................
总结
