
搞定ReentrantReadWriteLock 几道小小数学题就够了
你有一个思想,我有一个思想,我们交换后,一个人就有两个思想
If you can NOT explain it simply, you do NOT understand it well enough
前言
文章 万字超强图文讲解AQS以及ReentrantLock应用(建议收藏) 介绍了AQS独占式获取同步状态的实现,并以 ReentrantLock 为例说明其是如何自定义同步器实现互斥锁的 文章 精美图文讲解Java AQS 共享式获取同步状态以及Semaphore的应用 介绍 AQS 共享式获取同步状态的实现,并说明了 Semaphore 是如何自定义同步器实现简单限流作用的
有了以上两篇文章的铺垫,来理解本文要介绍的既有独占式,又有共享式获取同步状态的 ReadWriteLock,就非常轻松了
ReadWriteLock
ReadWriteLock 直译过来为【读写锁】。现实中,读多写少的业务场景是非常普遍的,比如应用缓存
一个线程将数据写入缓存,其他线程可以直接读取缓存中的数据,提高数据查询效率
之前提到的互斥锁都是排他锁,也就是说同一时刻只允许一个线程进行访问,当面对可共享读的业务场景,互斥锁显然是比较低效的一种处理方式。为了提高效率,读写锁模型就诞生了
效率提升是一方面,但并发编程更重要的是在保证准确性的前提下提高效率
一个写线程改变了缓存中的值,其他读线程一定是可以 “感知” 到的,否则可能导致查询到的值不准确
所以关于读写锁模型就了下面这 3 条规定:
允许多个线程同时读共享变量 只允许一个线程写共享变量 如果写线程正在执行写操作,此时则禁止其他读线程读共享变量
ReadWriteLock 是一个接口,其内部只有两个方法:
public interface ReadWriteLock {
// 返回用于读的锁
Lock readLock();
// 返回用于写的锁
Lock writeLock();
}
所以要了解整个读/写锁的整个应用过程,需要从它的实现类 ReentrantReadWriteLock 说起
ReentrantReadWriteLock 类结构
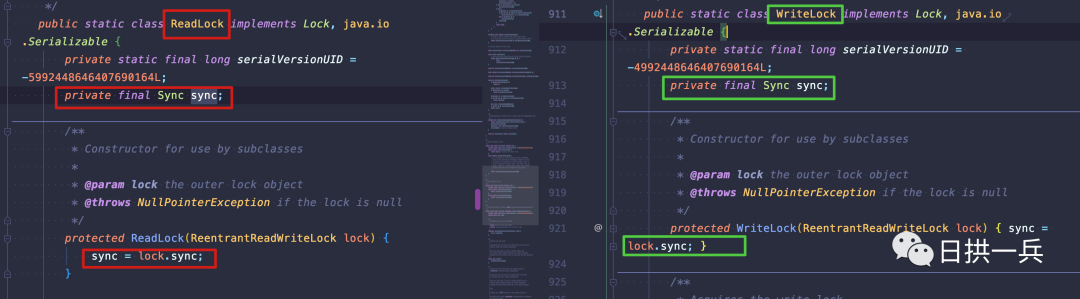
直接对比ReentrantReadWriteLock 与 ReentrantLock的类结构
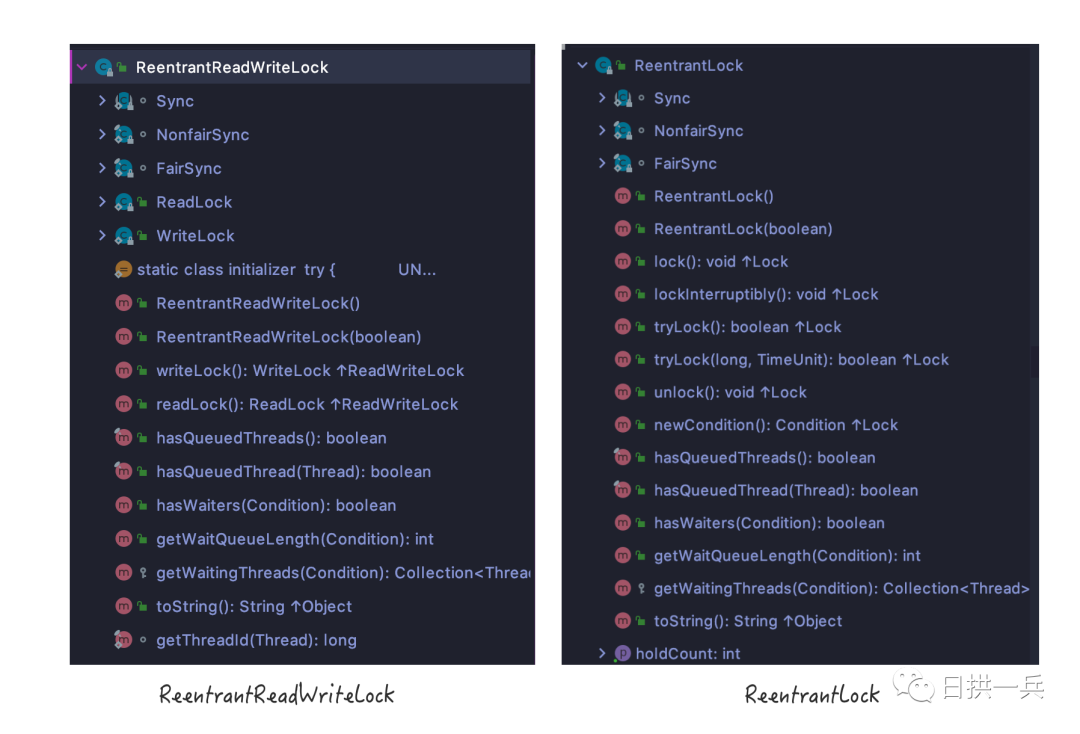
他们又很相似吧,根据类名称以及类结构,按照咱们前序文章的分析,你也就能看出 ReentrantReadWriteLock 的基本特性:
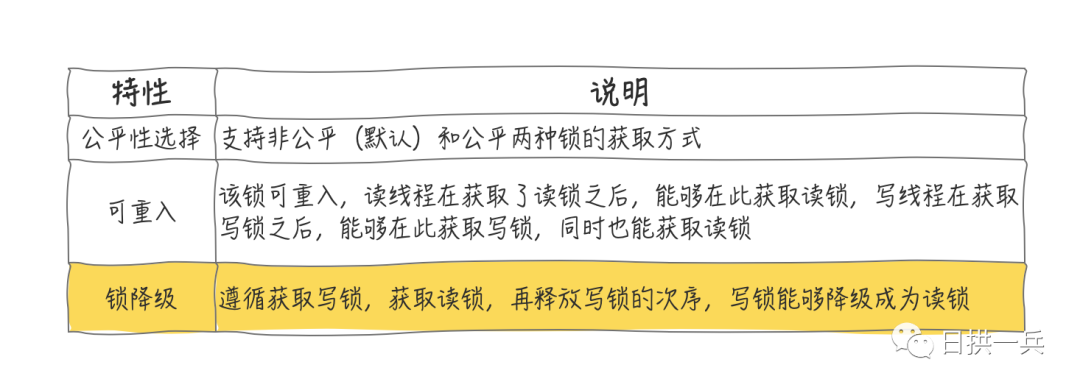
其中黄颜色标记的的 锁降级 是看不出来的, 这里先有个印象,下面会单独说明
另外,不知道你是否还记得,Java AQS队列同步器以及ReentrantLock的应用 说过,Lock 和 AQS 同步器是一种组合形式的存在,既然这里是读/写两种锁,他们的组合模式也就分成了两种:
读锁与自定义同步器的聚合 写锁与自定义同步器的聚合
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
这里只是提醒大家,模式没有变,不要被读/写两种锁迷惑
基本示例
说了这么多,如果你忘了前序知识,整体理解感觉应该是有断档的,所以先来看个示例(模拟使用缓存)让大家对 ReentrantReadWriteLock 有个直观的使用印象
public class ReentrantReadWriteLockCache {
// 定义一个非线程安全的 HashMap 用于缓存对象
static Map map = new HashMap();
// 创建读写锁对象
static ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
// 构建读锁
static Lock rl = readWriteLock.readLock();
// 构建写锁
static Lock wl = readWriteLock.writeLock();
public static final Object get(String key) {
rl.lock();
try{
return map.get(key);
}finally {
rl.unlock();
}
}
public static final Object put(String key, Object value){
wl.lock();
try{
return map.put(key, value);
}finally {
wl.unlock();
}
}
}
你瞧,使用就是这么简单。但是你知道的,AQS 的核心是锁的实现,即控制同步状态 state 的值,ReentrantReadWriteLock 也是应用AQS的 state 来控制同步状态的,那么问题来了:
一个 int 类型的 state 怎么既控制读的同步状态,又可以控制写的同步状态呢?
显然需要一点设计了
读写状态设计
如果要在一个 int 类型变量上维护多个状态,那肯定就需要拆分了。我们知道 int 类型数据占32位,所以我们就有机会按位切割使用state了。我们将其切割成两部分:
高16位表示读 低16位表示写
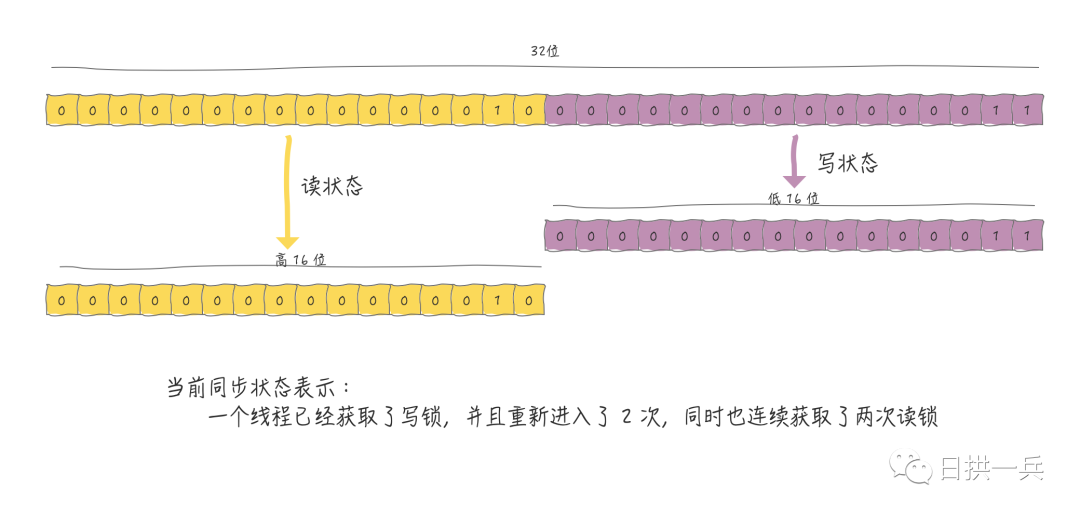
所以,要想准确的计算读/写各自的状态值,肯定就要应用位运算了,下面代码是 JDK1.8,ReentrantReadWriteLock 自定义同步器 Sync 的位操作
abstract static class Sync extends AbstractQueuedSynchronizer {
static final int SHARED_SHIFT = 16;
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
static int sharedCount(int c) {
return c >>> SHARED_SHIFT;
}
static int exclusiveCount(int c) {
return c & EXCLUSIVE_MASK;
}
}
乍一看真是有些复杂的可怕,别慌,咱们通过几道小小数学题就可以搞定整个位运算过程

整个 ReentrantReadWriteLock 中 读/写状态的计算就是反复应用这几道数学题,所以,在阅读下面内容之前,希望你搞懂这简单的运算
基础铺垫足够了,我们进入源码分析吧
源码分析
写锁分析
由于写锁是排他的,所以肯定是要重写 AQS 中 tryAcquire 方法
protected final boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread();
// 获取 state 整体的值
int c = getState();
// 获取写状态的值
int w = exclusiveCount(c);
if (c != 0) {
// w=0: 根据推理二,整体状态不等于零,写状态等于零,所以,读状态大于0,即存在读锁
// 或者当前线程不是已获取写锁的线程
// 二者之一条件成真,则获取写状态失败
if (w == 0 || current != getExclusiveOwnerThread())
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// 根据推理一第 1 条,更新写状态值
setState(c + acquires);
return true;
}
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))
return false;
setExclusiveOwnerThread(current);
return true;
}
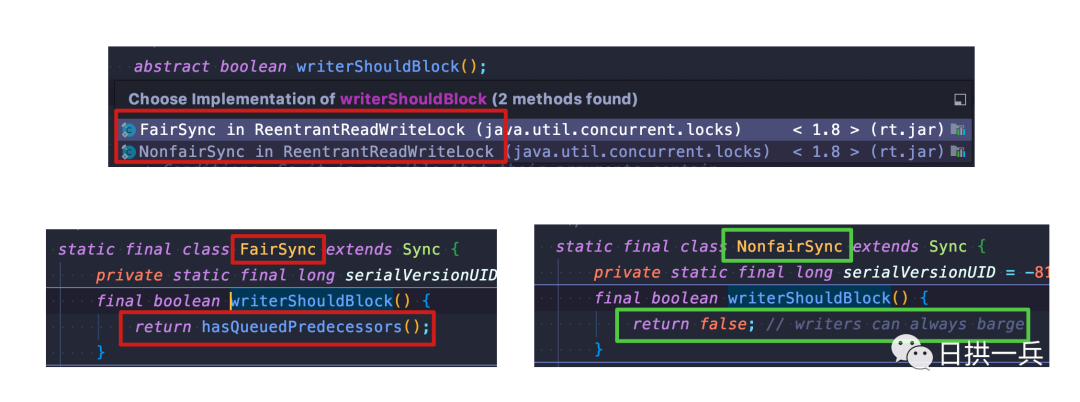
上述代码 第 19 行 writerShouldBlock 也并没有什么神秘的,只不过是公平/非公平获取锁方式的判断(是否有前驱节点来判断)
你瞧,写锁获取方式就是这么简单
读锁分析
由于读锁是共享式的,所以肯定是要重写 AQS 中 tryAcquireShared 方法
protected final int tryAcquireShared(int unused) {
Thread current = Thread.currentThread();
int c = getState();
// 写状态不等于0,并且锁的持有者不是当前线程,根据约定 3,则获取读锁失败
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1;
// 获取读状态值
int r = sharedCount(c);
// 这个地方有点不一样,我们单独说明
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) {
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
// 如果获取读锁失败则进入自旋获取
return fullTryAcquireShared(current);
}
readerShouldBlock 和 writerShouldBlock 在公平锁的实现上都是判断是否有前驱节点,但是在非公平锁的实现上,前者是这样的:
final boolean readerShouldBlock() {
return apparentlyFirstQueuedIsExclusive();
}
final boolean apparentlyFirstQueuedIsExclusive() {
Node h, s;
return (h = head) != null &&
// 等待队列头节点的下一个节点
(s = h.next) != null &&
// 如果是排他式的节点
!s.isShared() &&
s.thread != null;
}
简单来说,如果请求读锁的当前线程发现同步队列的 head 节点的下一个节点为排他式节点,那么就说明有一个线程在等待获取写锁(争抢写锁失败,被放入到同步队列中),那么请求读锁的线程就要阻塞,毕竟读多写少,如果还没有这点判断机制,写锁可能会发生【饥饿】
上述条件都满足了,也就会进入
tryAcquireShared代码的第 14 行到第 25 行,这段代码主要是为了记录线程持有锁的次数。读锁是共享式的,还想记录每个线程持有读锁的次数,就要用到 ThreadLocal 了,因为这不影响同步状态 state 的值,所以就不分析了, 只把关系放在这吧
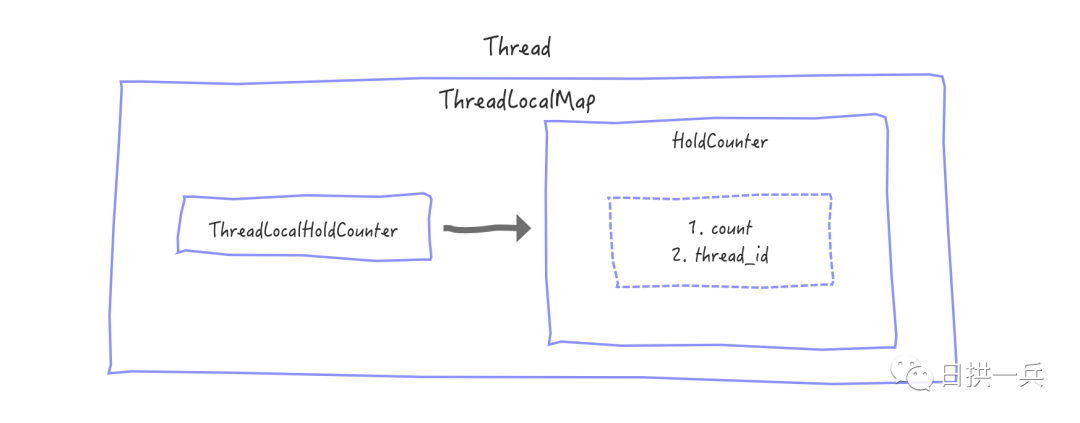
到这里读锁的获取也就结束了,比写锁稍稍复杂那么一丢丢,接下来就说明一下那个可能让你迷惑的锁升级/降级问题吧
读写锁的升级与降级
个人理解:读锁是可以被多线程共享的,写锁是单线程独占的,也就是说写锁的并发限制比读锁高,所以
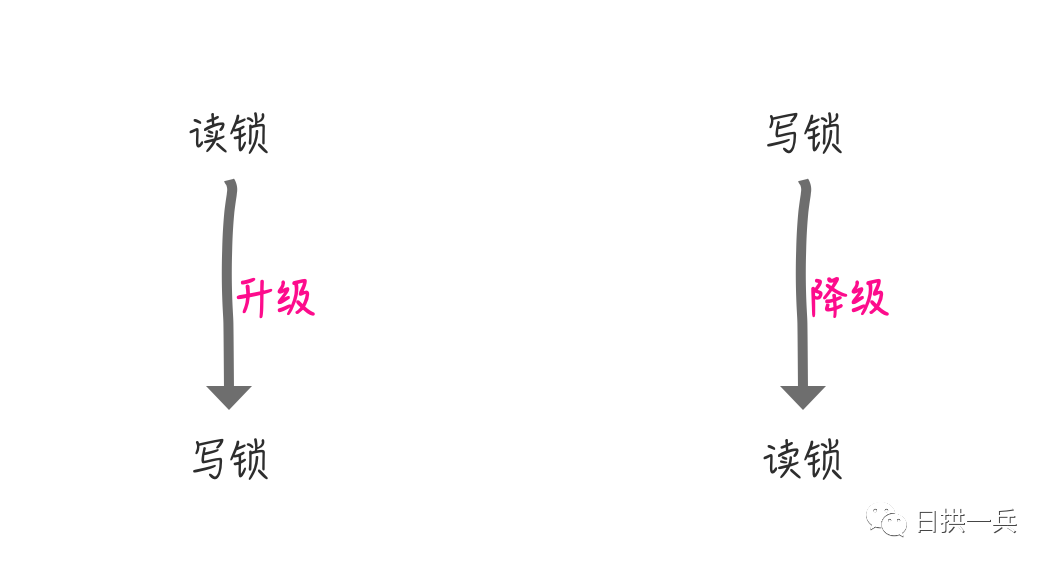
在真正了解读写锁的升级与降级之前,我们需要完善一下本文开头 ReentrantReadWriteLock 的例子
public static final Object get(String key) {
Object obj = null;
rl.lock();
try{
// 获取缓存中的值
obj = map.get(key);
}finally {
rl.unlock();
}
// 缓存中值不为空,直接返回
if (obj!= null) {
return obj;
}
// 缓存中值为空,则通过写锁查询DB,并将其写入到缓存中
wl.lock();
try{
// 再次尝试获取缓存中的值
obj = map.get(key);
// 再次获取缓存中值还是为空
if (obj == null) {
// 查询DB
obj = getDataFromDB(key); // 伪代码:getDataFromDB
// 将其放入到缓存中
map.put(key, obj);
}
}finally {
wl.unlock();
}
return obj;
}
有童鞋可能会有疑问
在写锁里面,为什么代码第19行还要再次获取缓存中的值呢?不是多此一举吗?
其实这里再次尝试获取缓存中的值是很有必要的,因为可能存在多个线程同时执行 get 方法,并且参数 key 也是相同的,执行到代码第 16 行 wl.lock() ,比如这样:
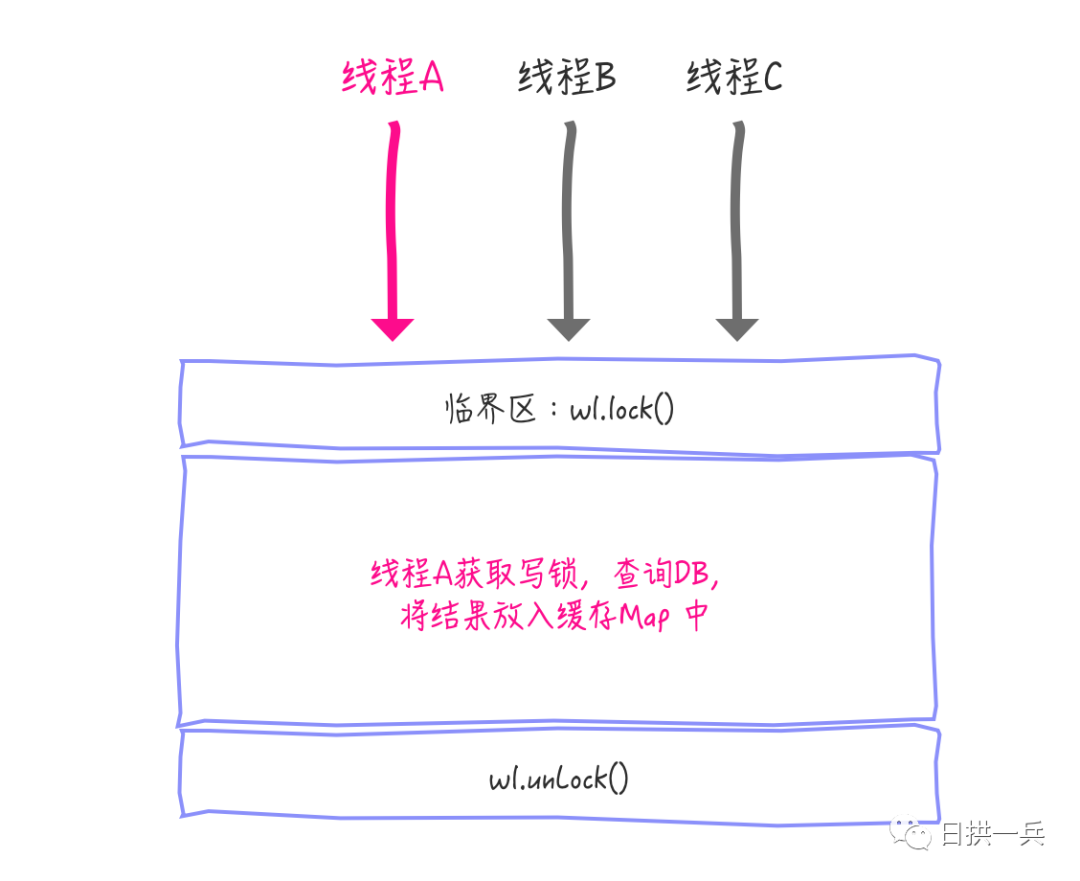
线程 A,B,C 同时执行到临界区 wl.lock(), 只有线程 A 获取写锁成功,线程B,C只能阻塞,直到线程A 释放写锁。这时,当线程B 或者 C 再次进入临界区时,线程 A 已经将值更新到缓存中了,所以线程B,C没必要再查询一次DB,而是再次尝试查询缓存中的值
既然再次获取缓存很有必要,我能否在读锁里直接判断,如果缓存中没有值,那就再次获取写锁来查询DB不就可以了嘛,就像这样:
public static final Object getLockUpgrade(String key) {
Object obj = null;
rl.lock();
try{
obj = map.get(key);
if (obj == null){
wl.lock();
try{
obj = map.get(key);
if (obj == null) {
obj = getDataFromDB(key); // 伪代码:getDataFromDB
map.put(key, obj);
}
}finally {
wl.unlock();
}
}
}finally {
rl.unlock();
}
return obj;
}
这还真是不可以的,因为获取一个写入锁需要先释放所有的读取锁,如果有两个读取锁试图获取写入锁,且都不释放读取锁时,就会发生死锁,所以在这里,锁的升级是不被允许的
读写锁的升级是不可以的,那么锁的降级是可以的嘛?这个是 Oracle 官网关于锁降级的示例 https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/locks/ReentrantReadWriteLock.html
,我将代码粘贴在此处,大家有兴趣可以点进去连接看更多内容
class CachedData {
Object data;
volatile boolean cacheValid;
final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
rwl.readLock().lock();
if (!cacheValid) {
// 必须在获取写锁之前释放读锁,因为锁的升级是不被允许的
rwl.readLock().unlock();
rwl.writeLock().lock();
try {
// 再次检查,原因可能是其他线程已经更新过缓存
if (!cacheValid) {
data = ...
cacheValid = true;
}
//在释放写锁前,降级为读锁
rwl.readLock().lock();
} finally {
//释放写锁,此时持有读锁
rwl.writeLock().unlock();
}
}
try {
use(data);
} finally {
rwl.readLock().unlock();
}
}
}
代码中声明了一个 volatile 类型的 cacheValid 变量,保证其可见性。
首先获取读锁,如果cache不可用,则释放读锁 然后获取写锁 在更改数据之前,再检查一次cacheValid的值,然后修改数据,将cacheValid置为true 然后在释放写锁前获取读锁 此时 cache中数据可用,处理cache中数据,最后释放读锁
这个过程就是一个完整的锁降级的过程,目的是保证数据可见性,听起来很有道理的样子,那么问题来了:
上述代码为什么在释放写锁之前要获取读锁呢?
如果当前的线程A在修改完cache中的数据后,没有获取读锁而是直接释放了写锁;假设此时另一个线程B 获取了写锁并修改了数据,那么线程A无法感知到数据已被修改,但线程A还应用了缓存数据,所以就可能出现数据错误
如果遵循锁降级的步骤,线程A 在释放写锁之前获取读锁,那么线程B在获取写锁时将被阻塞,直到线程A完成数据处理过程,释放读锁,从而保证数据的可见性
那问题又来了:
使用写锁一定要降级吗?
如果你理解了上面的问题,相信这个问题已经有了答案。假如线程A修改完数据之后, 经过耗时操作后想要再使用数据时,希望使用的是自己修改后的数据,而不是其他线程修改后的数据,这样的话确实是需要锁降级;如果只是希望最后使用数据的时候,拿到的是最新的数据,而不一定是自己刚修改过的数据,那么先释放写锁,再获取读锁,然后使用数据也无妨
在这里我要额外说明一下你可能存在的误解:
如果已经释放了读锁再获取写锁不叫锁的升级
如果已经释放了写锁在获取读锁也不叫锁的降级
相信你到这里也理解了锁的升级与降级过程,以及他们被允许或被禁止的原因了
总结
本文主要说明了 ReentrantReadWriteLock 是如何应用 state 做位拆分实现读/写两种同步状态的,另外也通过源码分析了读/写锁获取同步状态的过程,最后又了解了读写锁的升级/降级机制,相信到这里你对读写锁已经有了一定的理解。如果你对文中的哪些地方觉得理解有些困难,强烈建议你回看本文开头的两篇文章,那里铺垫了非常多的内容。接下来我们就看看在应用AQS的最后一个并发工具类 CountDownLatch 吧
灵魂追问
读锁也没修改数据,还允许共享式获取,那还有必要设置读锁吗? 在分布式环境中,你是如何保证缓存数据一致性的呢? 当你打开看ReentrantReadWriteLock源码时,你会发现,WriteLock 中可以使用 Condition,但是ReadLock 使用Condition却会抛出UnsupportedOperationException,这是为什么呢?
// WriteLock
public Condition newCondition() {
return sync.newCondition();
}
// ReadLock
public Condition newCondition() {
throw new UnsupportedOperationException();
}
参考
Java 并发实战 Java 并发编程的艺术 https://www.jianshu.com/p/58697bb2243e

最后免费给大家分享50个Java项目实战资料,涵盖入门、进阶各个阶段学习内容,可以说非常全面了。大部分视频还附带源码,学起来还不费劲!
附上截图。(下面有下载方式)。





项目领取方式:
扫描下方公众号回复:50,
可获取下载链接
???
?长按上方二维码 2 秒 回复「50」即可获取资料
点赞是最大的支持 