
检索用的好,下班走的早!值得收藏
这篇文章是可乐花了很长时间总结出来的,注意:本篇文章不是教大家如何检索,而是教大家如何设计检索系统。
我从宏观层面介绍了各种数据结构和算法,并在结尾介绍了如何设计一个搜索系统,下面是本文目录截图,相信大家看完一定会有收获的。

1、什么是检索?
指从用户特定的信息需求出发,对特定的信息集合采用一定的方法、技术手段,根据一定的线索与规则从中找出相关信息。
对应到我们实际工作中,检索其实就是:
如何用最小的内存(物理成本),最快(时间成本)的取出我们需要的数据。
2、检索体系架构
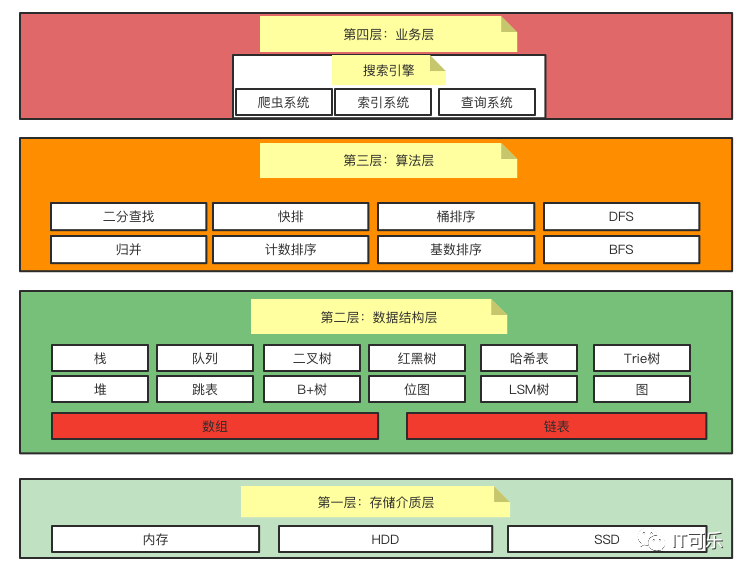
3、存储介质层
3.1 磁盘为什么能存储数据

机械硬盘的磁盘主体是一块金属薄片(也有用其他材料的),上面涂覆一层磁性材料,可以理解为一层小磁针。
硬盘工作时,磁盘在马达的驱动下高速旋转,转速高达数千转每分钟,磁头则在磁头驱动系统的的控制下,在高速旋转的磁盘表面飞行。
①、写数据
磁头线圈上通电,在其周围产生磁场,磁化磁盘表面的磁性材料,不同方向的电流产生的磁场方向不同,磁盘表面的磁性材料被磁化的极性也不同,不同极性便代表0与1;
②、读数据
磁头线圈切割磁盘表面的磁性材料的磁场,产生电信号,不同极性的磁性材料产生的感应电流方向不同,因此可以读出0与1。
注意:断电并不会影响磁盘表面的磁性材料的极性,因此断电后数据仍然不会消失,但剧烈的碰撞或加热则有可能导致数据丢失。
3.2 磁盘和内存的区别
①、持久性
磁盘能永久存储(HDD10年,SDD5年),断电不丢失数据;
内存断电即丢失数据。
②、容量
磁盘通常是几百G到几个T;
内存通常是几个G到几十个G。
③、价格
内存 > 磁盘
④、读写速度
内存 > SDD > HDD
4、数据结构层
4.1 数组

1.数组是相同数据类型的元素的集合。
2.数组各元素是按照先后顺序连续存储的。
3.插入慢:无序数组末尾插入快,其余情况需要维护数组地址连续效率都是比较差。
4.查找:支持下标随机查找快,有序数组也可以用诸如二分法加快查找速度。
5.删除慢:和插入类似,除了末尾插入快。其余情况需要维护数组地址连续都比较慢。
4.2 链表

1.链表物理存储单元上非连续(可以充分利用计算机内存)、非顺序的存储结构。
2.不支持随机读取。
3.存储空间会增大,比如单向链表每个节点都会存储下一个节点的引用。
4.插入快。
5.删除快。
6.查找慢。
其余比如栈、队列、二叉树,红黑树,B+树等等都是这两种数据结构的单独变化或组合变化。
4.3 栈
栈只支持两个基本操作:入栈 push()和出栈 pop()。
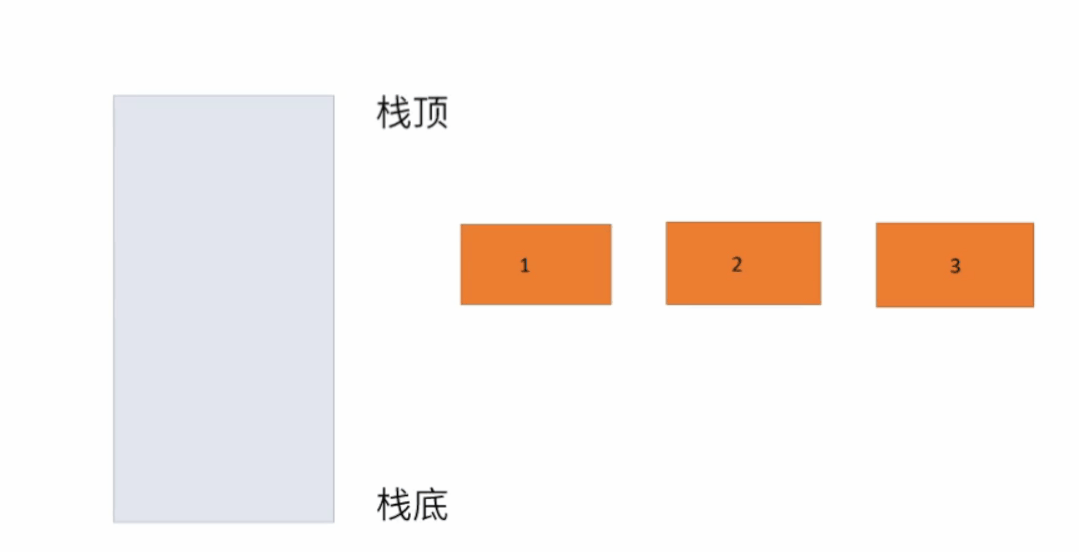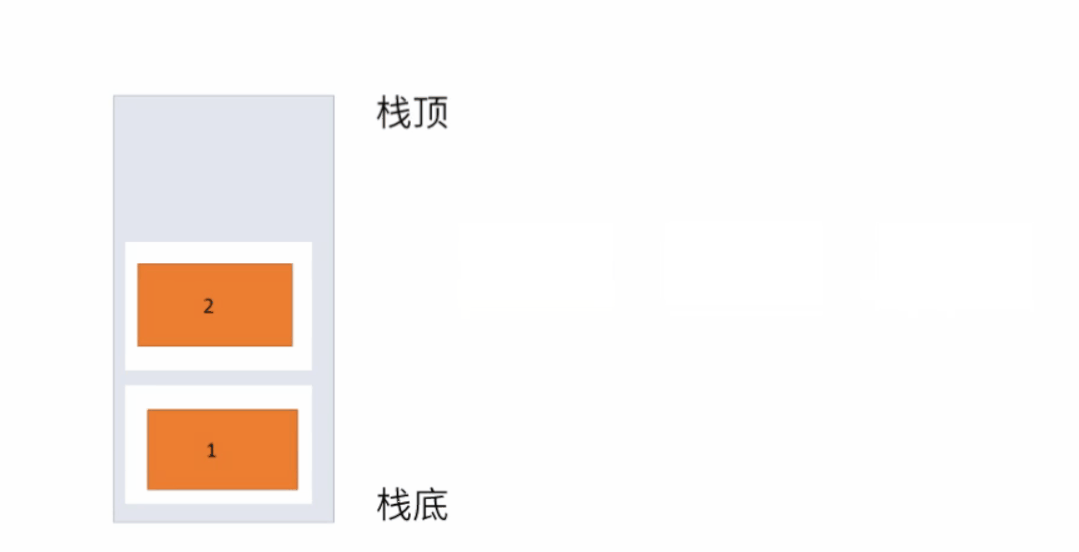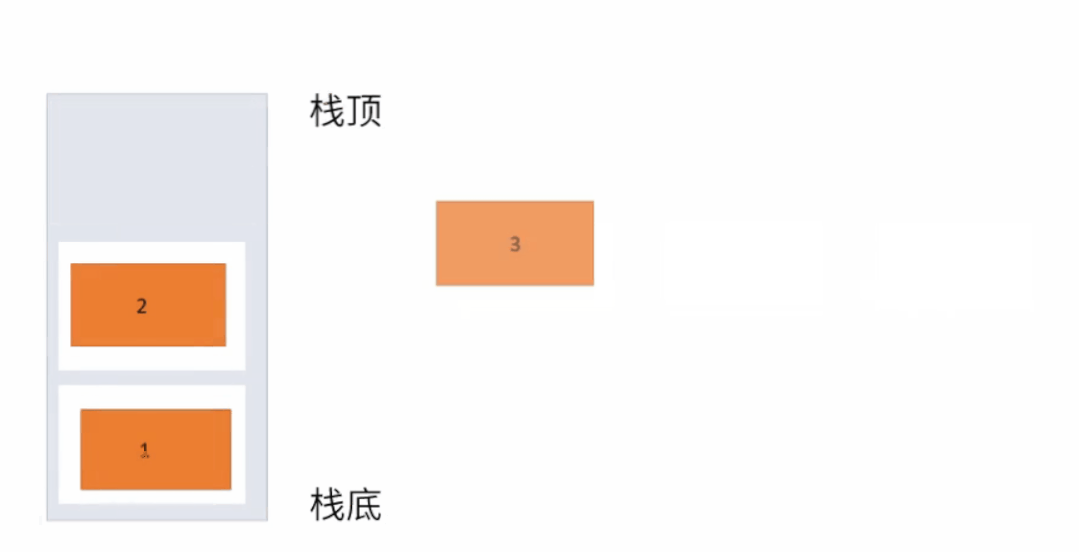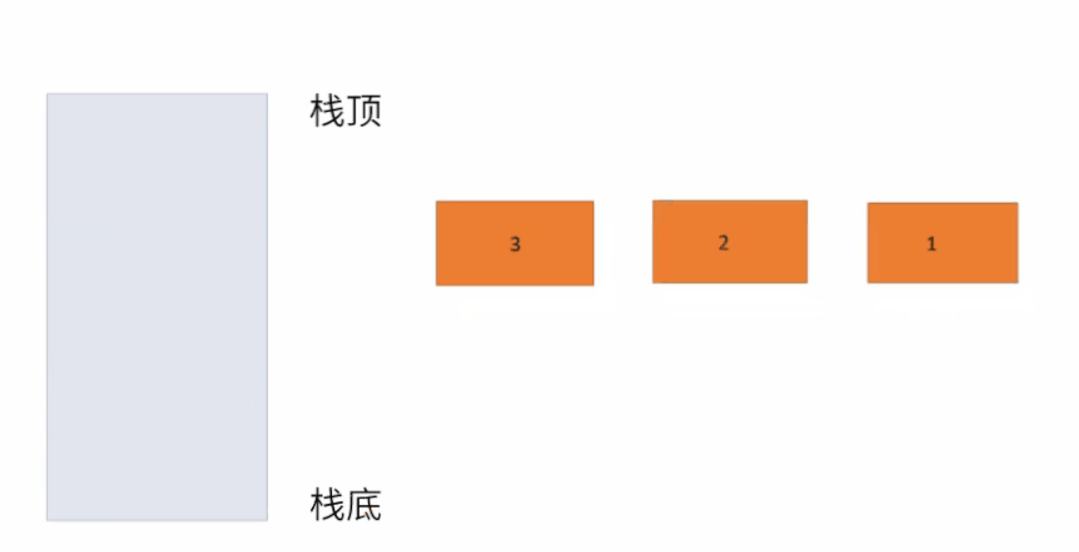
典型应用:
①、实现字符串逆序;
②、判断标签是否匹配;
③、计算机中的函数调用;
4.4 队列
和栈类似,也只支持两个操作:入队 enqueue(),放一个数据到队列尾部;出队 dequeue(),从队列头部取一个元素。

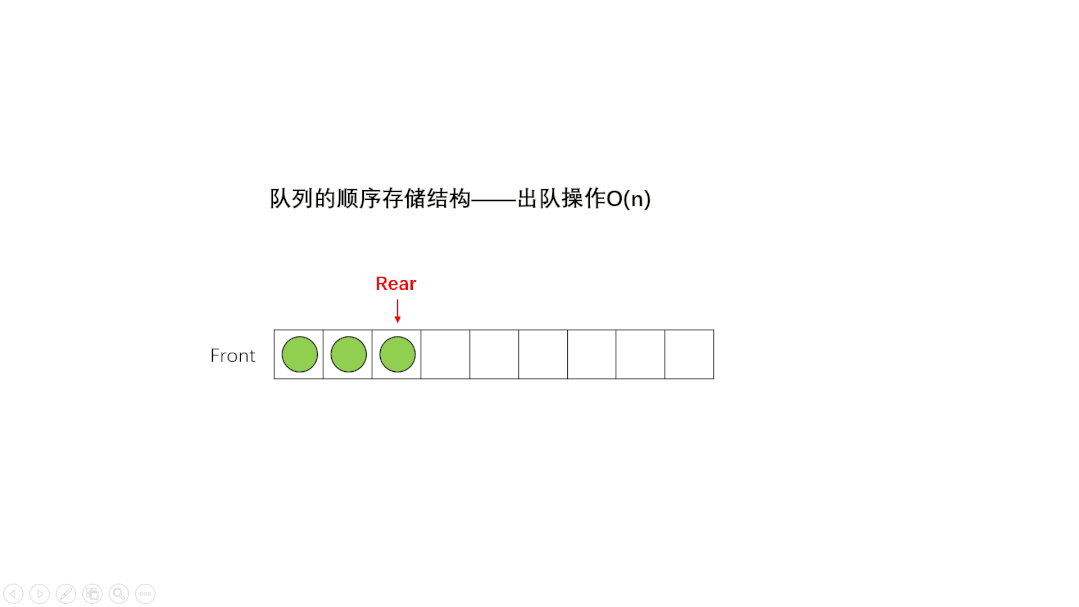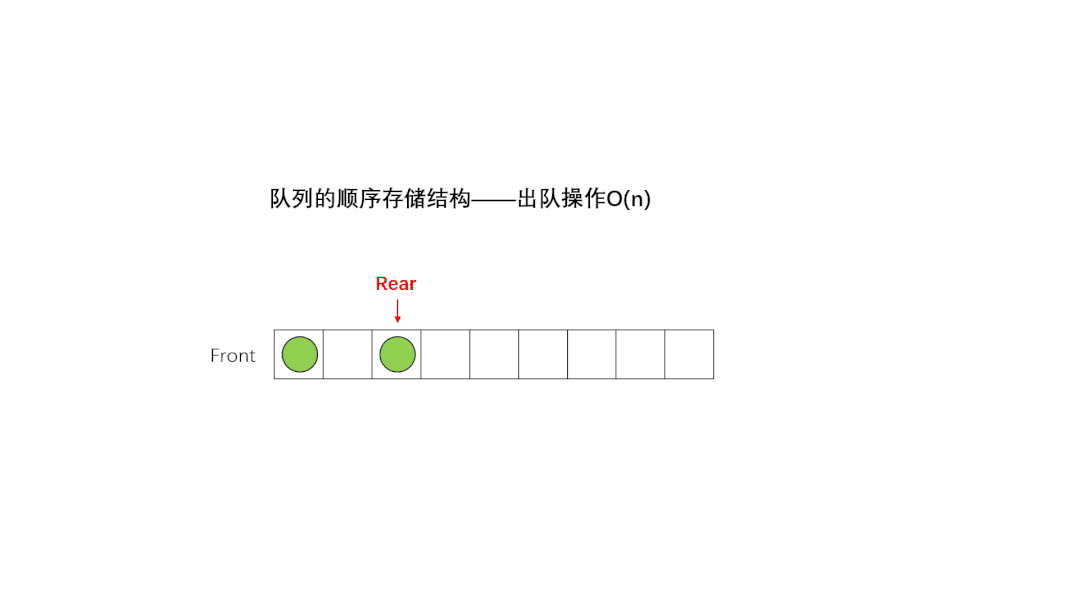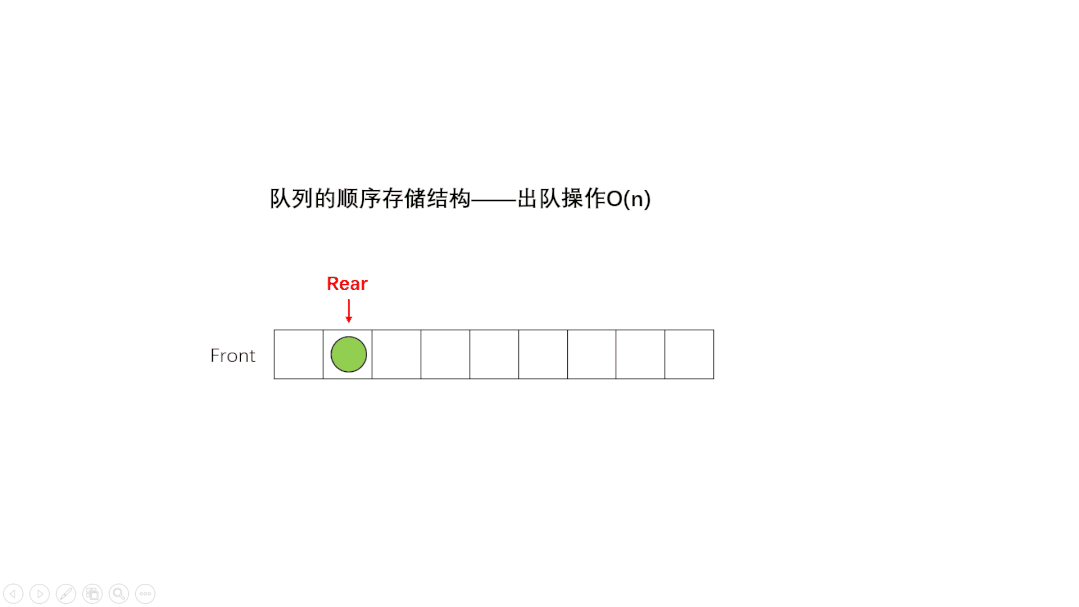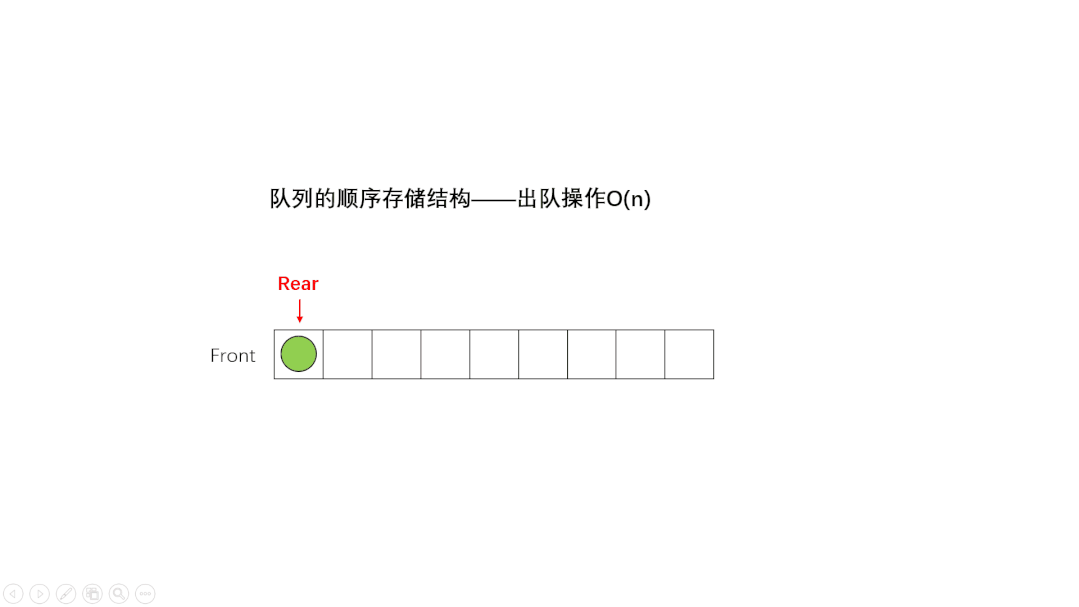
①、单向队列(Queue):只能在一端插入数据,另一端删除数据。
②、双向队列(Deque):每一端都可以进行插入数据和删除数据操作。
③、优先级队列(Priority Queue):数据项按照关键字进行排序,关键字最小(或者最大)的数据项往往在队列的最前面,而数据项在插入的时候都会插入到合适的位置以确保队列的有序。
④、阻塞队列(Block Queue):在队列为空的时候,从队头取数据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才能返回;如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。
典型的生产者-消费者模型。
⑤、并发队列
典型应用:
①、线程池
②、数据库连接池
对于大部分资源有限的场景,当没有空闲资源时,基本上都可以通过“队列”这种数据结构来实现请求排队。
4.5 树
①、二叉树
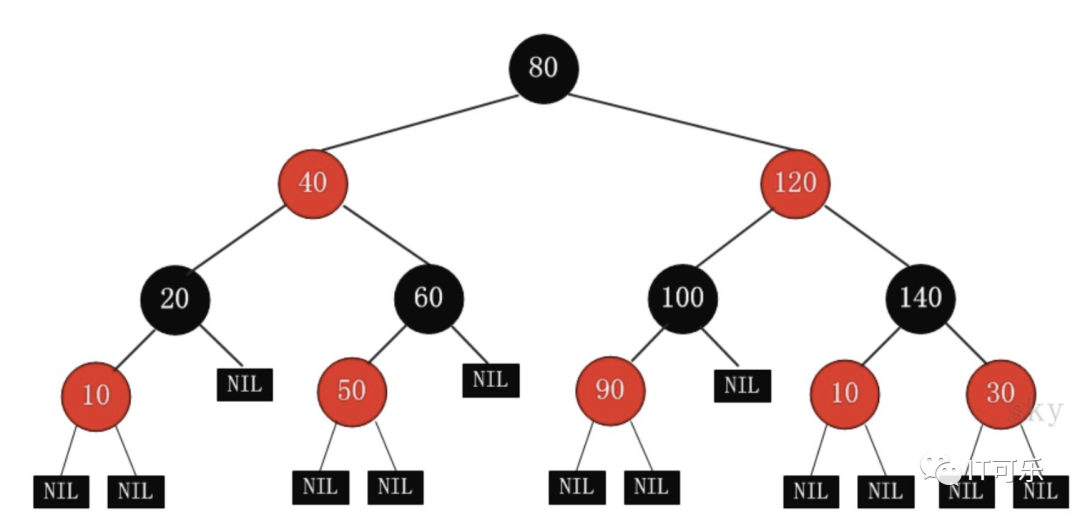
②、红黑树
③、B+树
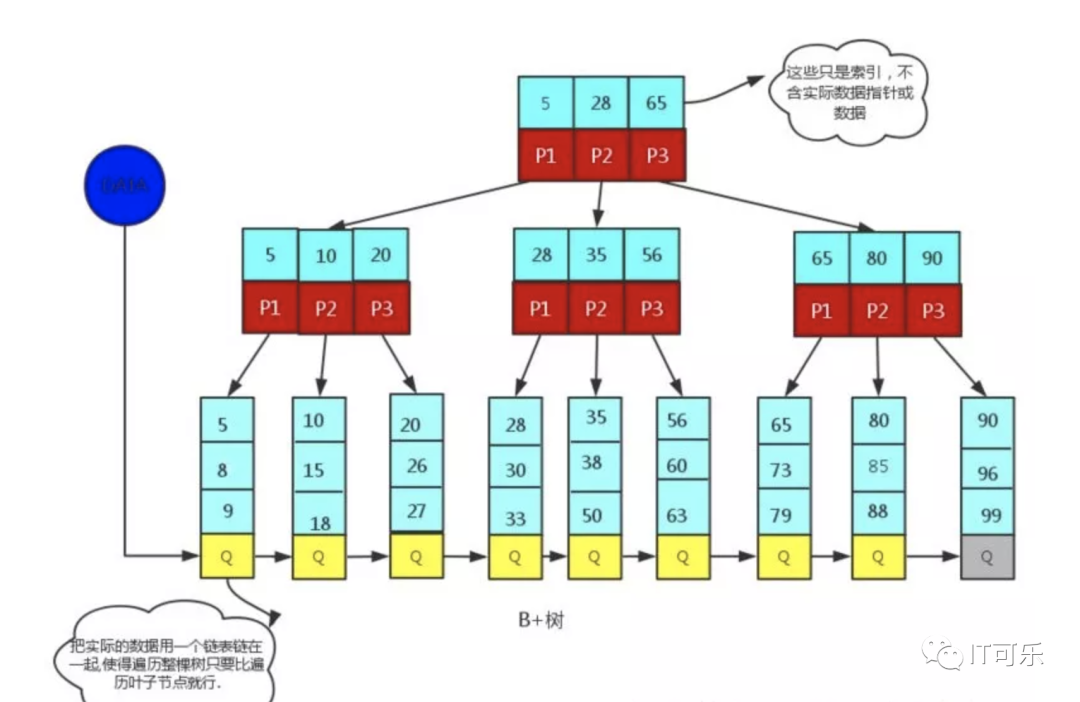
典型应用:关系型数据库存储数据结构。
1.数据很大,不可能全部存储在内存中,还要持久化,故要存储到磁盘上。
2.减少查找过程中磁盘I/O的存取次数。
局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。
与磁盘预读,预读的长度一般为页(page)的整倍数,(在许多操作系统中,页得大小通常为4k)
叶子节点数据多。
3.支持范围查找
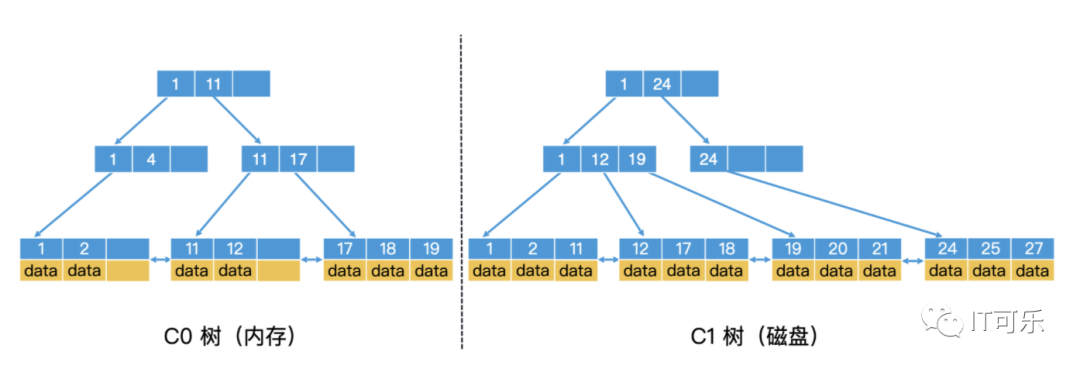
④、LSM 树
Log Structured Merge Trees
一个日志系统有如下特征:
一、数据量大且持续生成
二、写入操作会特别频繁
三、查询快,且查询一般不是全范围的随机搜索,而是近期检索。
B+ 树为什么不行?(叶子节点存储在磁盘中,需要随机写磁盘,数据量大会导致性能急剧下降)
LSM 树:
⑤、Trie 树
字典树、前缀树、单词查找树。
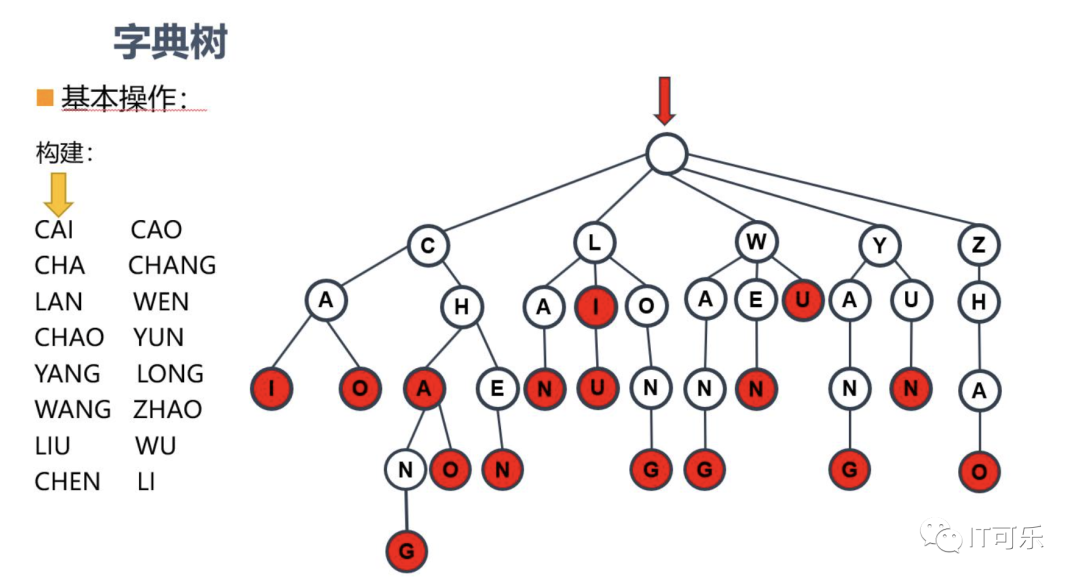
典型应用:
字符串检索
百度谷歌搜索框
拼写检查
4.6 跳表
链表的基础上增加了多级索引。
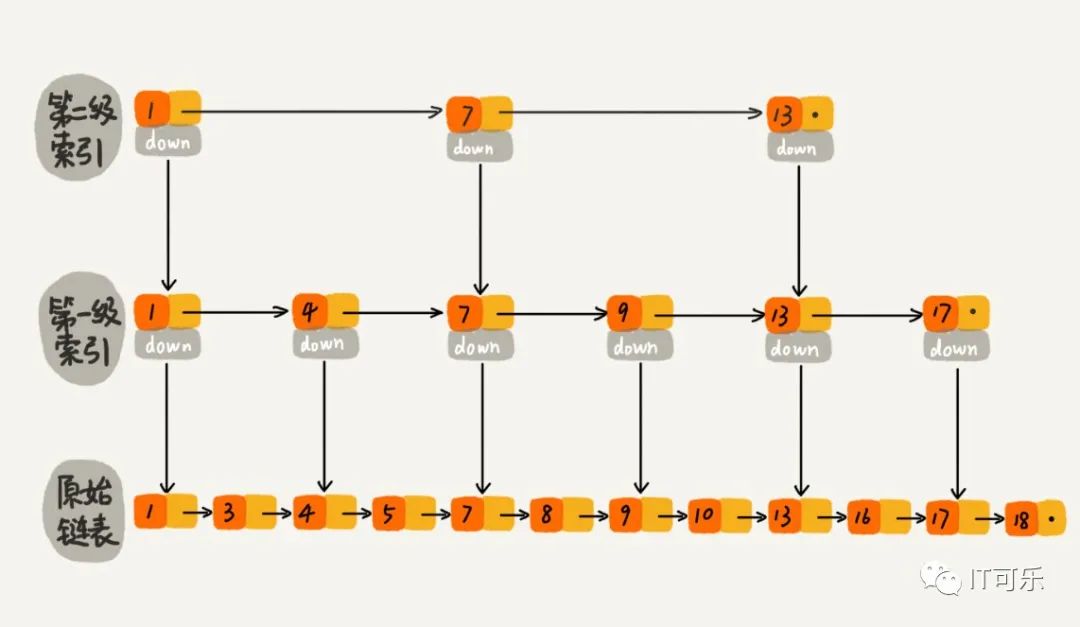
Redis 中的有序集合(Sorted Set)就是用跳表来实现的。
4.7 散列表
通过把关键值映射到表中一个位置来访问记录,这个映射函数叫做散列函数,存放记录的数组叫做散列表。
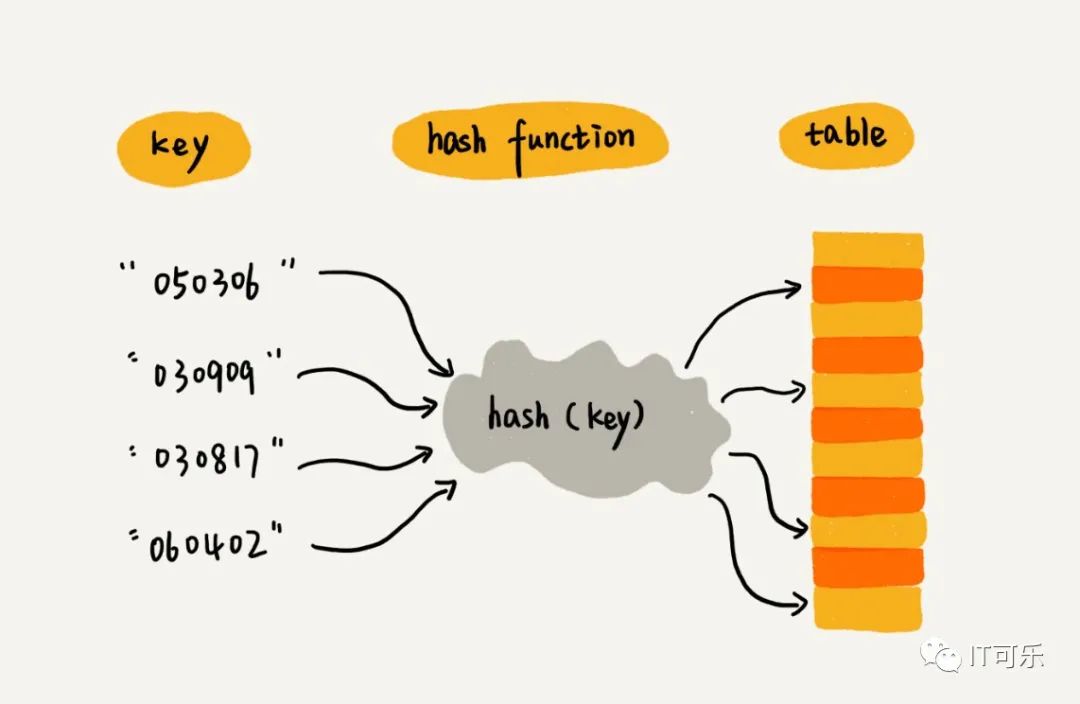
解决哈希冲突:
①、开放寻址法:线性探测、双重散列
②、链表法
散列表设计原则:
①、散列函数
②、初始容量;
③、装载因子;
④、散列冲突解决办法;
典型应用:
①、有限的数据集合中快速查询数据
比如:Word 文档中单词拼写检查功能是如何实现的?
常用的英文单词有 20 万个左右,假设单词的平均长度是 10 个字母,平均一个单词占用 10 个字节的内存空间,那 20 万英文单词大约占 2MB 的存储空间,就算放大 10 倍也就是 20MB。
所以可以将全部英文单词放到散列表,用户输入单词直接去散列表里面查,没有就报错。
②、词频统计、访问统计等等。
4.8 布隆过滤器
简单来说就是一个二进制数组。
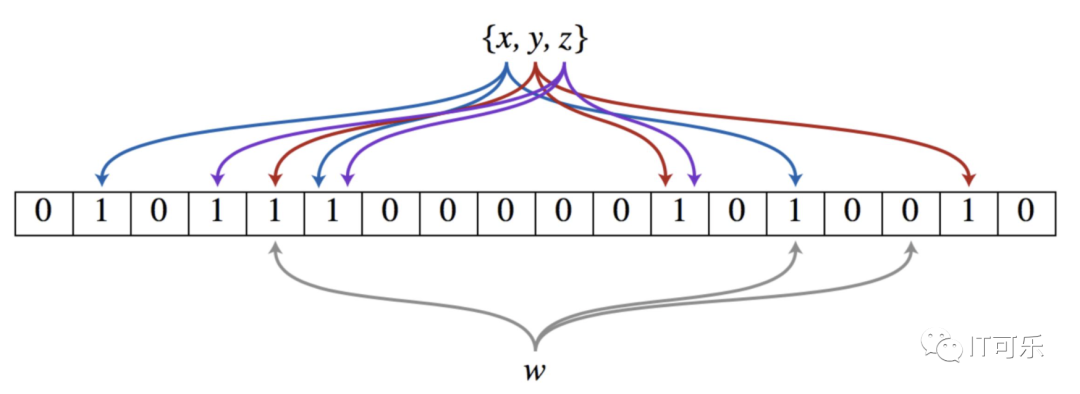
典型应用:数据海量,不要求一定准确的场景。
①、判断ID是否已经注册,即使误判也能容忍。
②、爬虫判断网页是否已经爬过。
4.9 图
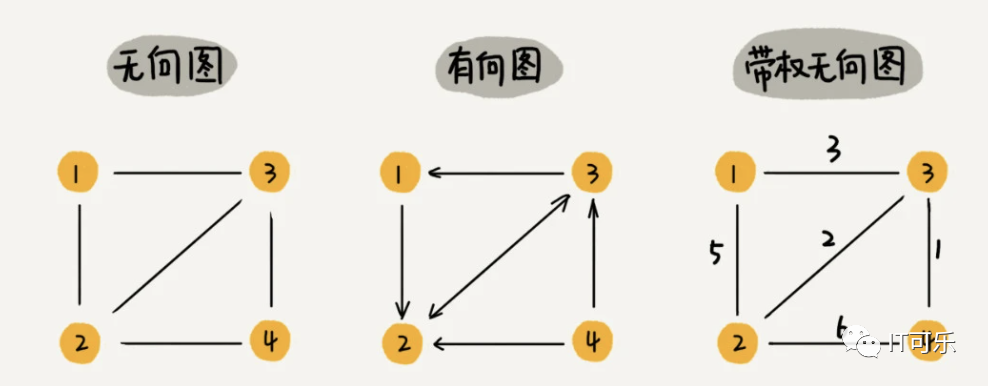
存储:
①、邻接矩阵
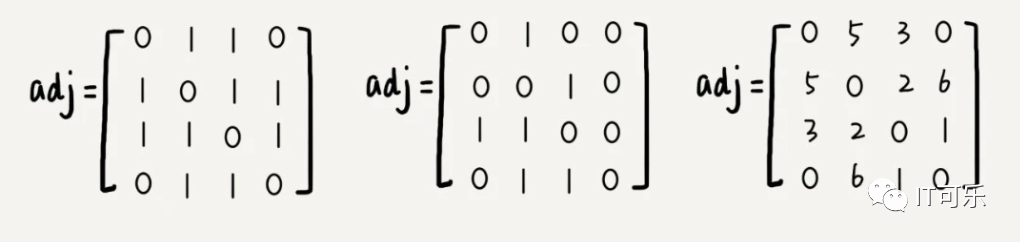
②、邻接表
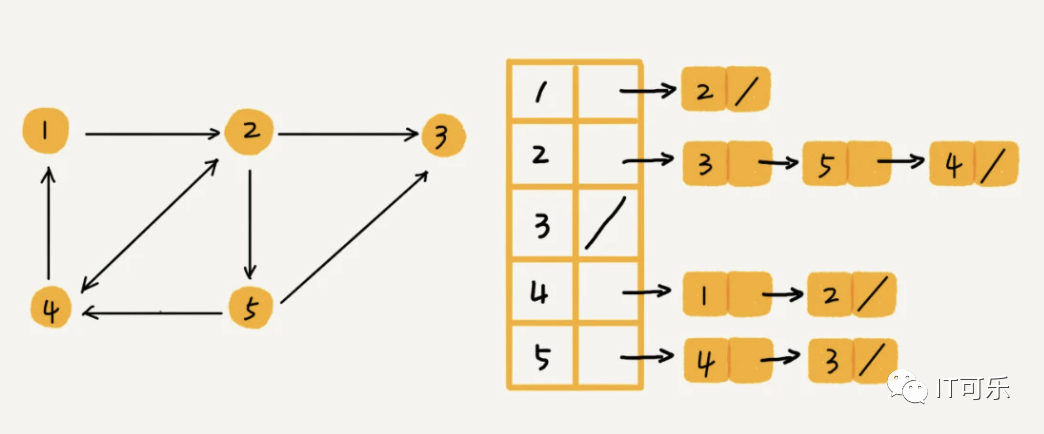
DFS(Deep First Search)深度优先搜索算法
BFS(Breath First Search)广度优先搜索算法
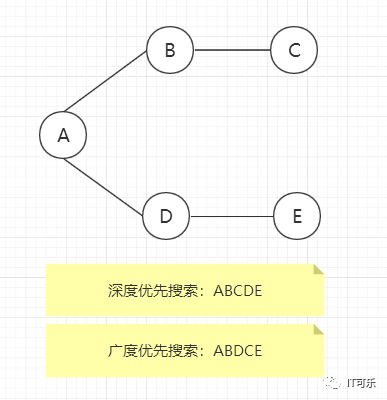
飞机航线
电子线路
城市地图
好友关系
5、算法层
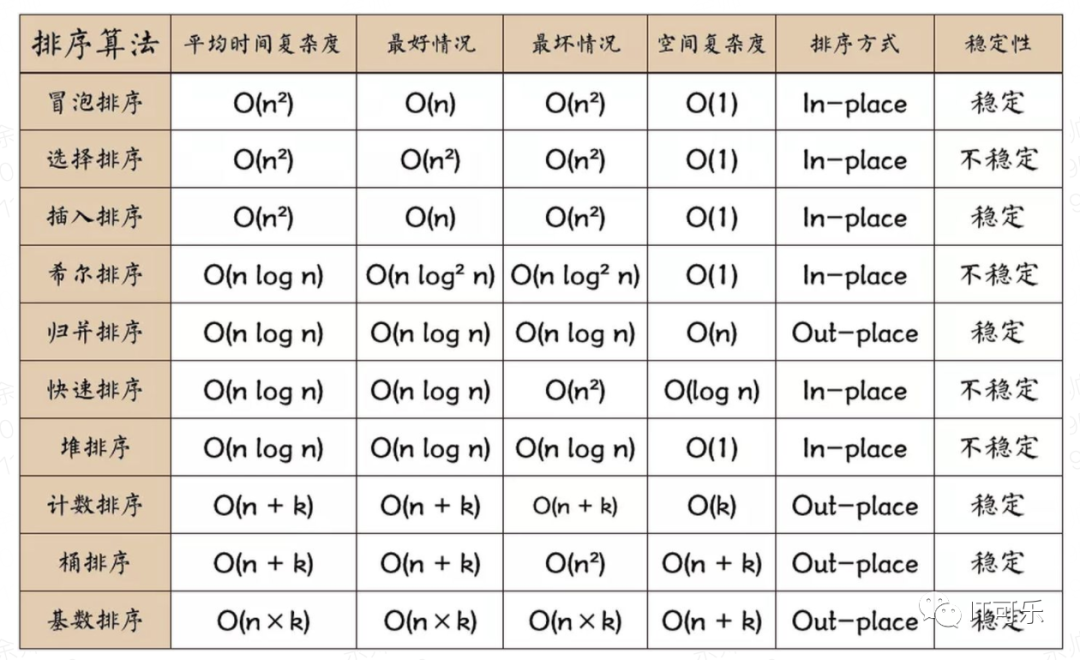
比较好用的查找算法是二分法O(logn),在有序的数据结构中是特别bug的,但是如何进行快速的排序,有如下常用的排序算法:
实际应用:
①、如何根据年龄给100W用户排序?
利用桶排序,从1岁到150岁(有人会说超过150岁,这里超过三界之外的人不算),建立150个桶,然后遍历这100W个用户,依次放入150个桶中,遍历完,边排好序了。
②、如何快速查询每个考生的高考排名?
同样也是桶排序,高考分数0-750,也就是顶多 750 个桶。
6、业务设计层
6.1 爬虫系统
通过高性能的爬虫系统来完成网页的持续抓取,然后将抓取到的网页存入存储平台中。
一般来说是是将抓取到的网页存放在基于 LSM 的 HBase 中,以便支持数据的高效读写。
①、爬取网页
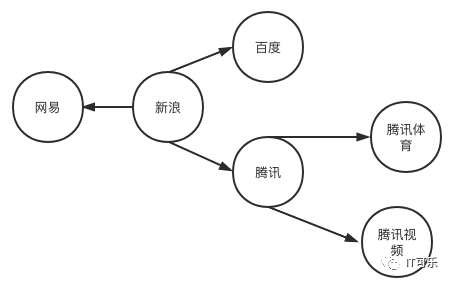
首先找到权重较高的网页,比如新浪、腾讯,通过广度优先搜索算法放入爬取队列中;
计算网页权重算法:PageRank
网页太多,持久化队列,便于断点爬取。
如何爬取网页链接:可以获取到网页的 HTML 文件,看成一个大的字符串,然后利用字符串匹配算法,获取 或者这样的标签内容。
②、网页去重
利用布隆过滤器。
需要注意的是:布隆过滤器是在内存中的,如果机器重启,布隆过滤器就会被清空,防止网页重复爬取,需要持久化布隆过滤器,比如定时每半小时持久化一次。
③、原始网页存储
便于后面的离线分析,索引构建,需要将海量的原始网页存储。
网页很多,通常的文件系统不适合存储这么多的文件,而是将多个网页存储在一个文件中。
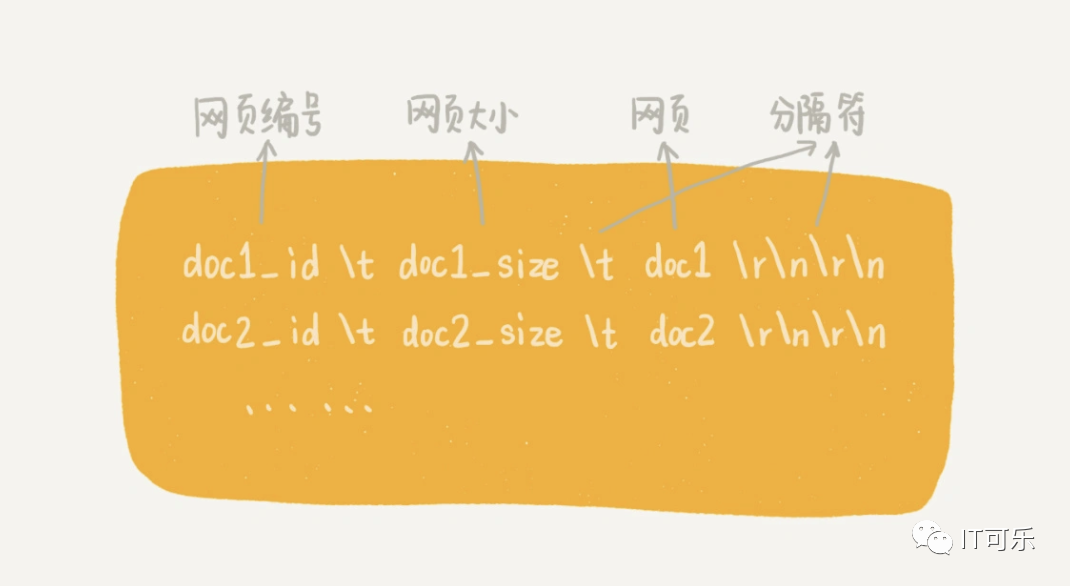
④、网页编号和链接存储
上一步给每个网页分配了一个id,在存储网页的同时,也将网页编号和网页链接存储在一个文件中。
6.2 分析索引系统
①、抽取网页文本信息
网页都是遵循 HTML 规范的,只需要去掉JavaScript代码、CSS代码,还有比如下拉框的代码。
在网页这个大字符串中,一次性查找 , ,
②、网页质量分析
去掉低质量的垃圾网页
③、反作弊
避免一些作弊网页来干扰搜索结果
④、分词创建临时索引
抽取到网页文本信息之后,对文本信息进行分词,并创建临时索引文件。
英文网页:只需要通过空格、标点符号等分隔符,将每个单词分割开来就可以了。
中文网页:借助词库并采用最长匹配规则,来对文本进行分词。
临时索引文件如下:
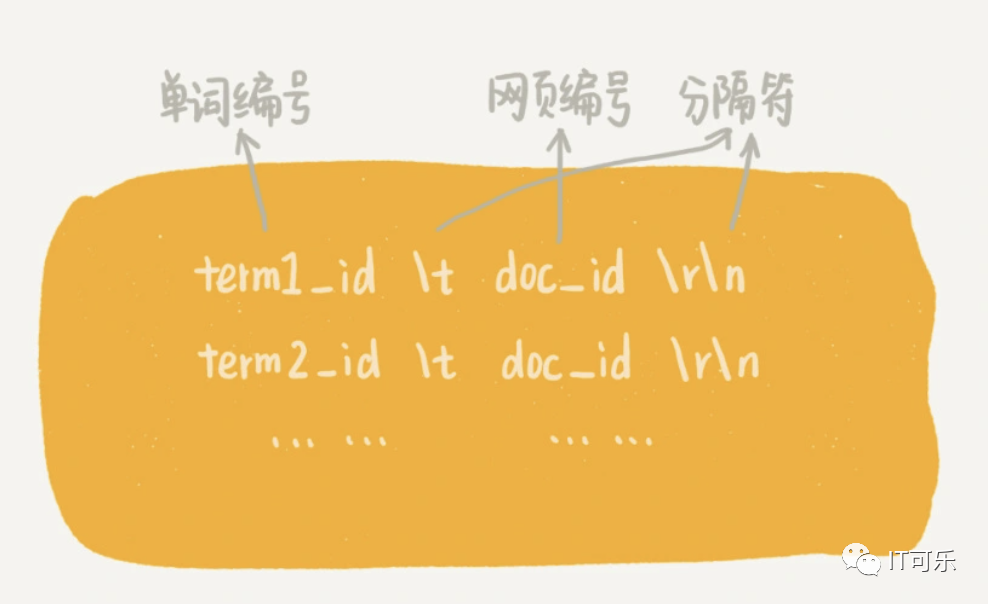
注意这里存的是单词编号,因为单词很多,为了节省内存,用一个散列表存储:单词编号-单词。
⑤、通过临时索引创建倒排索引
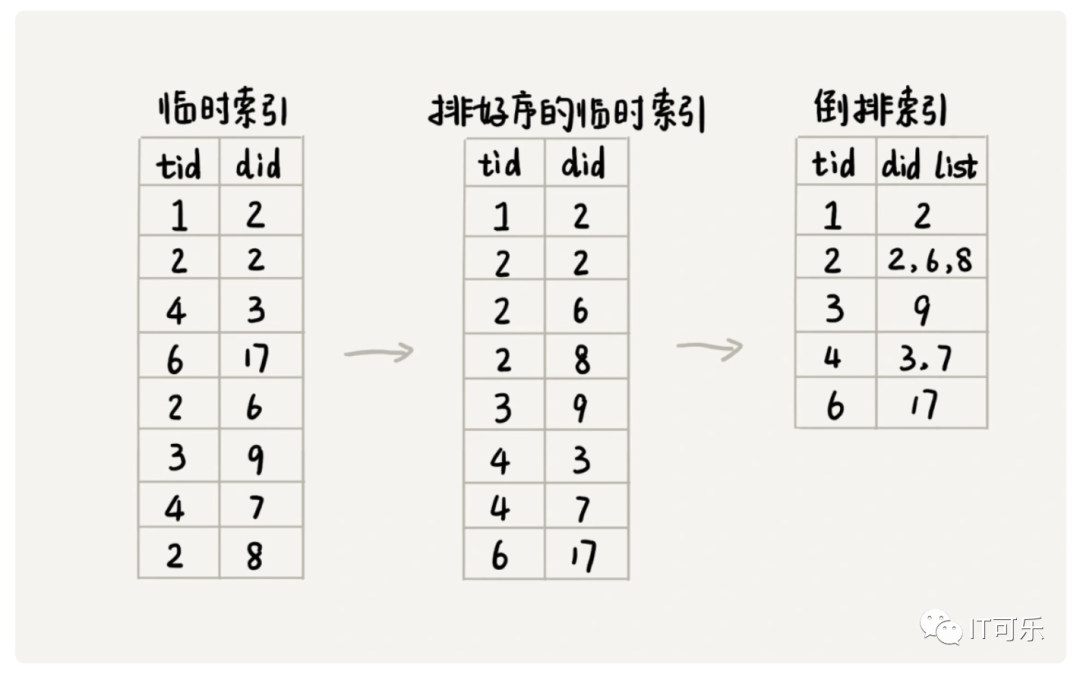
⑥、记录单词编号在倒排索引文件的偏移位置
帮助我们快速地查找某个单词编号在倒排索引中存储的位置,进而快速地从倒排索引中读取单词编号对应的网页编号列表。

6.3 查询
doc_id.bin:记录网页链接和编号之间的对应关系。
term_id.bin:记录单词和编号之间的对应关系。
index.bin:倒排索引文件,记录每个单词编号以及对应包含它的网页编号列表。
term_offsert.bin:记录每个单词编号在倒排索引文件中的偏移位置。
①、当用户在搜索框中,输入某个查询文本的时候,我们先对用户输入的文本进行分词处理。假设分词之后,我们得到 k 个单词。
然后对这 k 个单词进行纠错模型判断:
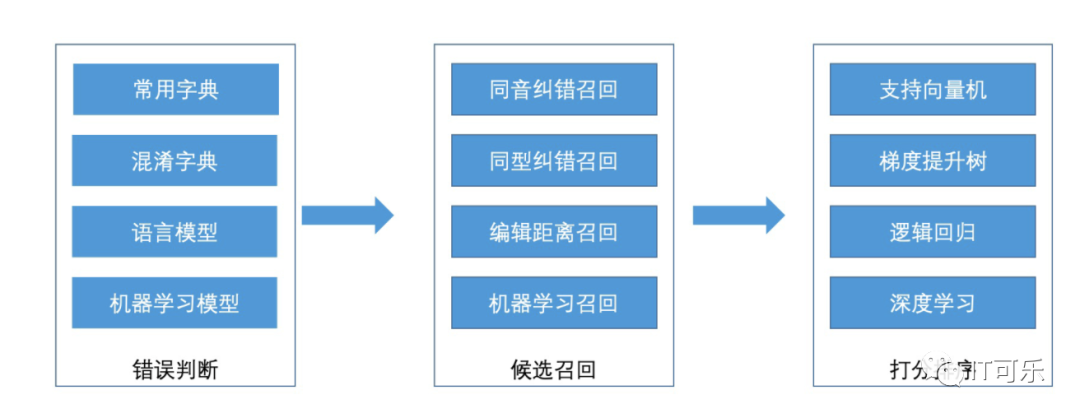
②、纠错完成之后,我们拿这 k 个单词,去 term_id.bin 对应的散列表中,查找对应的单词编号。经过这个查询之后,我们得到了这 k 个单词对应的单词编号。
③、我们拿这 k 个单词编号,去 term_offset.bin 对应的散列表中,查找每个单词编号在倒排索引文件中的偏移位置。经过这个查询之后,我们得到了 k 个偏移位置。
④、我们拿这 k 个偏移位置,去倒排索引(index.bin)中,查找 k 个单词对应的包含它的网页编号列表。经过这一步查询之后,我们得到了 k 个网页编号列表。
⑤、我们针对这 k 个网页编号列表,统计每个网页编号出现的次数。具体到实现层面,我们可以借助散列表来进行统计。统计得到的结果,我们按照出现次数的多少,从小到大排序。出现次数越多,说明包含越多的用户查询单词(用户输入的搜索文本,经过分词之后的单词)。
经过这一系列查询,我们就得到了一组排好序的网页编号。我们拿着网页编号,去 doc_id.bin 文件中查找对应的网页链接,分页显示给用户就可以了。
10、总结
检索核心思路:通过合理的组织数据,尽可能的快速减少查询范围。
①、合理选择存储介质、存储数据结构;
②、合理创建索引,使得索引和数据分离;
③、减少磁盘IO,将频繁读取的数据加载到内存中;
④、读写分离;
⑤、分层处理;
关于我
Java程序猿,公众号「IT可乐」定期分享有趣有料的精品原创文章!
愿你我人生尽量没有遗憾的事,愿你我都能奔赴在各自想去的路上。