
一个数据库十年老兵的思考与总结

作者介绍

王竹峰
去哪儿网数据库总监,擅长数据库开发、数据库管理及维护,一直致力于 MySQL 数据库源码的研究与探索,对数据库原理及实现有深刻的理解。曾就职于达梦数据库,从事多年数据库内核开发工作,后转战人人网,任职高级数据库工程师,目前在去哪儿网负责 MySQL 源码研究与运维、数据库管理和自动化运维平台设计开发及实践工作,是 Inception 开源项目及《MySQL运维内参》的作者, MySQL 方向的 Oracle ACE。
一、数据库开发
二、初入运维
三、如何提升效率
1. 需求与实现
设计的产品可能是真正能解决用户需求的,也是用户真正想要的样子。 提需求的人,不需要等待开发去排期,自己就直接做了,不需要看别人脸色,不受制于人。 效率是最高的,不需要来回沟通需求,等排期。 个人成长明显,相对可以做到不被淘汰。 在 DBA 行业里面,这点更加明显,纯运维将来能走的路非常有限,需要有代码能力的支撑。
2. 基础数据建设
人的记忆不具有传递性,如果人离职了,那相应的记忆也离职了。 人的记忆不能保证准确性,容易出现问题。 靠人的记忆去做的话,在合作场景下,顿时失灵,存在数据不一致的问题。 数据化管理效率高,准确。 数据化管理,可以实现数据共享,合作无缝衔接。
3. 自动化平台管理
效率方面,自动化相比人肉,效率提升是可见的。 准确性方面,人为操作是最容易出问题的环节,自动化可以保证准确性,不需要因为频繁的操作失误而被动工作。 人非常不擅长重复性工作的,相反,机器很适合做这类型的工作。 自动化可以实现操作的规范化,标准化,智能化。 自动化可以解放 DBA,让 DBA 腾出双手,提更多的需求,DBA 再把这些需求实现掉,进一步提升效率,进入良性循环。 让 DBA 做更有价值的事情,DBA的耻辱是,一天审核了 1000 个上线 SQL 语句。
4.学会利用资源
四、DBA应该尽可能聚焦
1.做事情不能摊大饼
大项目要拆分成多个子项目,或者分期完成,要把不同模块划分出来,一个个实现,并且这些模块可以阶段性地使用起来,而不是等到最后一刻和其它模块组合起来,才能被使用。 要想清楚做这个项目的初衷是什么,不要把项目方案放大,最终搞成一个宏伟的目标,这样可能永远也实现不了了。 根据项目初衷,设计一个能解决这个初衷的方案即可,不要因为解决一个小问题,而“创造”一个更大的问题出来。 开发者,也要定期向上反馈成果,不要让领导觉得项目是遥遥无期的。
2.避免陷入技术死胡同
新技术,是相对旧技术而言的,通常会出现与旧技术不一样的表现形式,最常见的就是兼容性,带来的问题是,我们需要维护非常多的版本,老的下不掉,“新技术”的版本不断上线,久而久之,维护成本非常高,DBA及平台,需要处理各种新特性的兼容问题,处理不及时,就会导致出现故障之类的问题,吃力不讨好,所以面对新技术,我们扪心自问一下,旧技术是不是够用了?够用就好,这点在 MySQL 上面,我觉得够用的,但PG由于种种原因,会出现各种新技术,如果不谨慎的话,就容易出现上面的问题。 现在流行新技术 docker/k8s,有人经常问到我,你们 MySQL 用 docker 了吗?我通常是用两个成语回复,分别是隔靴搔痒,作茧自缚,你想上k8s,是为了解决什么问题?编排部署安装找资源的问题?MySQL 是一个有状态的大型通用数据库,这么重存储的服务,找资源安装,问题很大吗?又说是资源隔离的问题,资源隔离的需求很紧迫吗?单机单实例就不说了,即使在单机多实例的情况下,也没几个实例,并且 MySQL 本身内部就是多线程的,均衡问题也比较好,同一台机器上一个实例影响其它实例的案例少之又少,所以这需求有那么紧迫吗?而且对于使用 MySQL 没有上到一定量级的情况下,非 k8s 的自动化平台就可以很好的解决资源部署安装编排的问题,为了解决这个问题,创造一个上 k8s 的大问题,这样就有点和初衷背道而驰了。同时 k8s 是一个新的技术栈,支撑它上线,是需要另一个专业团队来做的,投入产出比非常低。我反过来再问一下, MySQL 本身的问题你解决完了吗?慢查询有没有好的工具去优化?主从切换能不能不影响业务?机器挂了能不能不丢数据?数据库服务能不能做到不同机房的多活?自动化 SQL 审核可以自助服务了吗?如果哪个没做到,那就先放弃 k8s 吧。再者,我们专业的 MySQL 运维技术人员,非要作茧自缚,给 MySQL 套一个壳,出了问题,是壳的问题?还是 MySQL 本身的问题?当引入一个变量的时候,可服务率肯定就会有一定程度的下降,因为 99.99%*99.99% 的结果是 99.98%。
3.善于总结
在相对稳定的变化不大的行业中,总结出来的知识,有利于循环利用,有利于进一步提升。 总结,不是做到心里默念一下,感觉会了就表示总结完了。 总结一定要从心里默念,转换到笔记里面去,或者转化到可发表的文章中去,任何有疑问的地方,要有自己的思考并能解释清楚。 总结,在转化为文字之后,要求再高一些的话,就是可以把相应的内容转换为ppt,在公司或者社会上讲出来,好处不言而喻。 如果做到了这些,恭喜你,你已经正在向通往专家的道路上前进了。
五、DBA 应该做什么事情
1.什么是难的事情?
2.什么是正确的事情?
3.产品化思维
4. 正确的需求
长期以往,自己所实现的服务或者产品,会变为一个垃圾场,八面玲珑,样样不行,最终都会走上“重构”的道路。 是不是可以换一种思路去解决?这考验的是需求实现者的判断力。 接受在普适场景下的定制化,而不能为了解决1%的需求,创造一种新的架构或者服务,还是之前说过的原则,不要因为解决一个小问题,进而创造出来一个更大的问题。 不是所有的需求都需要满足。
5. 十年经验
六、打破规则
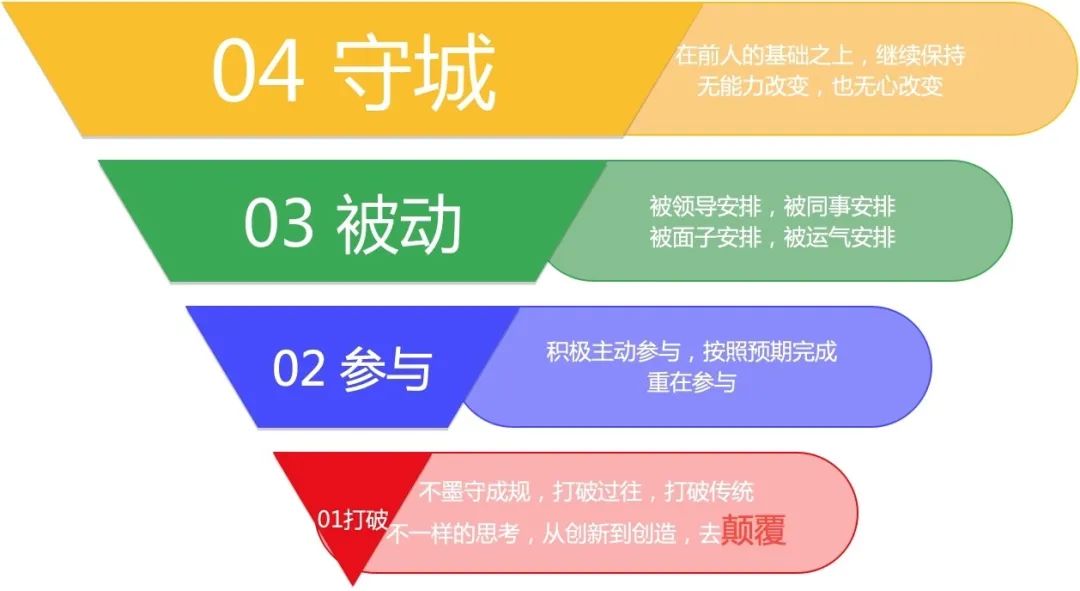
守城型,这种类型的人是最多的,他们可以站在巨人的肩膀上,过得比较安稳,可以继续保持前人留下来的工作,但让他们去改变的话,非常难,难在两方面,一方面是能力不足,另一方面就是心力不足了。 被动型,这种类型的人,相对守城者,会稍微少一些,他们的能力是可以的,不过主题词是一个“被”字,工作被动,生活被动,在我们运维行业中,一个集中表现就是,整天“被”各种故障、问题所累,状态也不好。 参与型,这种类型的人会更少,他们的态度非常积极,很乐观,做事情可以按照预期,甚至超出预期完成,但他们的成就感可能更多地来源于重在参与,很少可以主动去改变现状,去思考面临的问题等等。 打破型:这种类型的人,非常之少,通常不会按照既定陈规出牌,对过去的传统都会产生疑问,和其它三种有不一样的思考方式,他们的出现,通常会石破天惊,会颠覆某一个规则,甚至某一个行业,拥有这样特质的人,可以参考乔布斯、马斯克这样的人。
七、工作模式的转变
数据库出故障了。 有人对你有需求。
各种权限、数据库、SQL 审核等的审批工作以及执行工作。 各种合作伙伴的咨询问题,需要承担客服的角色。 各种问题的追踪、调试、找原因,需要面对各种相关人员的询问以及好奇心,查不清楚或者没有结果,是不可以的。 到处救火,工作时间被安排,没有办法保证。 这样的状态持续久了,团队情绪低落,士气不高。 各种重复的,繁复的日常工作需要处理,效率很低。 等等之类的。
团队人员的时间,可以自由支配,而不会被突如其来的事件所干扰。 是不是可以想办法在故障发生之前,能将故障解决掉,或者破坏掉,故障没了,大家相安无事。 故障变少之后,上面所说的“数据库出故障了”的存在感就会消失,整体上得到的评价不会因为故障而不断降低。 相比所有被动处理的局面,变为主动之后,工作量可能会更少,可以做到有条不紊。 能把被动,变为主动,团队的能力提升肯定是非常大的,这样人员情绪高涨,一举多得。
做了一件事情,能有效地提前避免将来的问题,即是主动。 有效地发现潜在的问题,能主动找到当事人并通知到,即是主动。 能有效地发现数据库的风险,能尽快地解决问题,从而避免问题的发生,即是主动。 能综合过去各种迹象,从整体来评估一个数据库的健康状况,如果风险相对比较高,做出相应措施,即是主动。 能通过事件触发,在关键时刻可以留存一些重要信息,在解决问题的时候能用得上,即是主动。 足够完善的监控系统,日志分析及抓取系统,保存足够的重要数据,即是主动。 能精确地找到资源浪费,使用不合理,空闲等问题,并且能够处理掉,即是主动。
八、我们具体应该做那些事?
1. 智能报警
阈值低报警太多的话,就会将非常重要的信息,淹没在报警的海洋之中,导致报警失效,因为我们根本不能及时发现; 阈值高报警太少的话,就有可能在报出来的时候,已经晚了,还是不能及时发现; 如果不同对象设置不同阈值的话,维护起来又非常不方便,因为报警阈值这种底层配置一般都是本地配置文件,维护困难; 本地个性化配置阈值的话,迁移之后这些配置也得跟随,也是有问题的; 不管报警多,还是少,总是有些不管三七二十一都需要必须马上处理的报警,对于这种及时发现还是个问题。 报警屏蔽,报出来,都会有延迟,经常出现错乱,不知道是延迟导致的还是新出来的报警。
我们现在重要的报警可以在一分钟之内直接打电话给相关人员,电话肯定可以接到。 我们所有报警对象的本地配置,阈值设置的都很低,在智能报警模块去做判断及过滤是不是要报出来。 我们针对没有报警出来的,会做综合分析,然后统计出来,通过对象维度定期去集中解决某类型的报警。 我们现在对报警的管理没有任何延迟,因为做在了智能报警模块中。 我们将来做的一个重要事情是,把报警想象成一个事件,这个事件在报出来的时候,会动态触发新的事件,可能去收集当时数据库或者机器的状态,用来在真正出问题的时候,查问题之用,智能自动化诊断之用。
2. MySQL全日志分析
可以精准掌握资源利用的信息,包括某一个对象是不是还在被使用,哪个是僵尸账号等等,用来回收浪费资源。 某个 SQL 语句什么时候访问了数据库,每一时刻的访问频率是什么,可以用来定位问题及查故障原因。 可以与慢查询日志做联动,能得到慢查询日志中不存在的信息。 用来做安全审计。 用来打通数据库与应用程序之间的技术栈。 用来精确地找到某一个表或者库的使用者,更好的推动业务及数据库的配合事务。 可以做“主动”的工作,做精准通知。 可以发现异常使用及风险相关的问题。
3. 慢查询风险指数
4. 数据库的 HA
5. 自动化操作
这如何防治呢?在防治之前,我们选择先搞明白原因,其实就是操作的随意性,不规范,不标准,想当然,试试看。我们一直强调,在你不能确定这个命令的影响是啥的话,那就别执行,但强调是没用的,能力,状态,熟练程度就摆在那里,强调实在是苍白无力。
九、总结
高效率:低效率的事情都让机器去干。 自动化:让机器去做重复低效的事情。 主动性:具有一定程度上的预言特质,可以把问题提前发现并解决。 覆盖面广:解决一个问题,就可以解决一类问题,从一个点上升到一个线,进一步上升到面儿。 自由支配:事情安排不受制于其它因素,任何时间,任何地点,都可以进行。 轻松愉快:自我成就感高,生活幸福指数高,时刻体现自己的价值。


▊《深入理解MySQL主从原理》
高鹏 著
数位数据库专家/ACEDirector/ACE赞誉推荐
凝结数百次故障诊断经验
从主库端到从库端带你深入解析MySQL主从构架的运行原理
MySQL主从原理是高可用架构的基石,即便是MGR这种集群架构也可以看到主从的影子。要解决一个问题或者故障,最快的方式就是了解它的原理,快速定位问题。
本书从源码层面抽丝剥茧般地描述MySQL主从原理,全面地介绍了GTID相关的知识点,并解析了主要Event的生成、作用和格式,以及线程的初步知识、MDL LOCK、排序等热门话题和主从相关的案例。无论是MySQL DBA和MySQL源码爱好者,还是刚进入数据库行业的小白读者,通过阅读本书,都能通过源码级分析,更好地理解和使用MySQL主从复制技术。
(扫码了解本书详情)
如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐
▼点击阅读原文,获取本书详情~