
触类旁通Elasticsearch之吊打同行系列:操作篇
点击上方蓝色字体,选择“设为星标”




一、索引数据
1. 使用映射定义文档
curl '172.16.1.127:9200/get-together/_doc/_mapping?pretty'索引新文档时ES可以自动创建映射,例如下面的命令会自动创建my_index索引,在其中索引一个ID为1的文档,该文档有name和date两个字段:
curl -XPUT '172.16.1.127:9200/my_index/_doc/1?pretty' -H 'Content-Type: application/json' -d '{"name": "Late Night with Elasticsearch","date": "2013-10-25T19:00"}'
curl '172.16.1.127:9200/my_index/_doc/_mapping?pretty'{"my_index" : {"mappings" : {"_doc" : {"properties" : {"date" : {"type" : "date"},"name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}}
curl -XPUT '172.16.1.127:9200/my_index?pretty'curl -XPUT '172.16.1.127:9200/my_index/_mapping/_doc?pretty' -H 'Content-Type: application/json' -d '{"_doc": {"properties": {"date": {"type": "date"},"name": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}}'
curl -XPUT '172.16.1.127:9200/my_index/_mapping/_doc?pretty' -H 'Content-Type: application/json' -d '{"_doc": {"properties": {"host": {"type": "text"}}}}'
{"my_index" : {"mappings" : {"_doc" : {"properties" : {"date" : {"type" : "date"},"host" : {"type" : "text"},"name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}}
curl -XPUT '172.16.1.127:9200/my_index/_mapping/_doc?pretty' -H 'Content-Type: application/json' -d '{"_doc": {"properties": {"host": {"type": "long"}}}}'
{"error" : {"root_cause" : [{"type" : "remote_transport_exception","reason" : "[node126][172.16.1.126:9300][indices:admin/mapping/put]"}],"type" : "illegal_argument_exception","reason" : "mapper [host] of different type, current_type [text], merged_type [long]"},"status" : 400}
2. 基本数据类型
curl -XPUT '172.16.1.127:9200/my_index/_doc/1?pretty' -H 'Content-Type: application/json' -d '{"name": "Late Night with Elasticsearch","date": "2013-10-25T19:00"}'
curl '172.16.1.127:9200/my_index/_doc/_search?pretty' -H 'Content-Type: application/json' -d '{"query": {"query_string": {"query": "late"}}}'
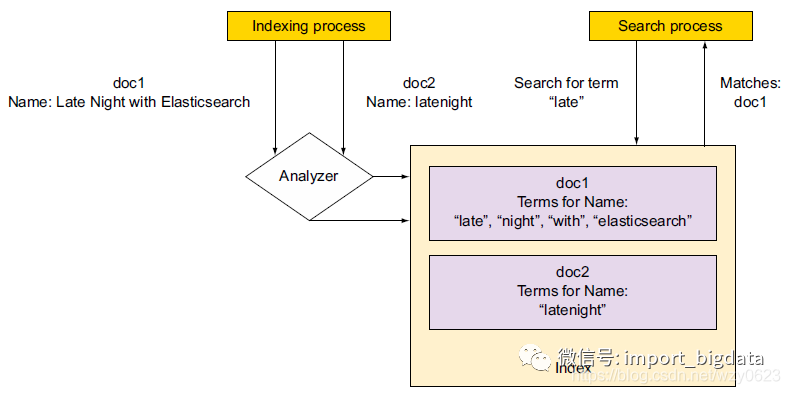
curl '172.16.1.127:9200/my_index/_doc/_search?pretty' -H 'Content-Type: application/json' -d '{"query": {"term": {"name.keyword": "late"}}}'
curl '172.16.1.127:9200/my_index/_doc/_search?pretty' -H 'Content-Type: application/json' -d '{"query": {"term": {"name.keyword": "Late Night with Elasticsearch"}}}'
使用预定义的日期格式。参见https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html#built-in-date-formats
设置自己定制的格式。
curl -XPUT '172.16.1.127:9200/my_index/_mapping/_doc?pretty' -H 'Content-Type: application/json' -d '{"properties": {"next_event": {"type": "date","format": "MMM DD YYYY"}}}'
curl -XPUT '172.16.1.127:9200/my_index/_doc/1?pretty' -H 'Content-Type: application/json' -d '{"name": "Elasticsearch News","first_occurence": "2011-04-03","next_event": "Oct 25 2013"}'
curl '172.16.1.127:9200/my_index/_doc/_mapping?pretty'{"my_index" : {"mappings" : {"_doc" : {"properties" : {"date" : {"type" : "date"},"first_occurence" : {"type" : "date"},"host" : {"type" : "text"},"name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"next_event" : {"type" : "date","format" : "MMM DD YYYY"}}}}}}
boolean类型用于存储文档中的true/false,例如:
curl -XPUT '172.16.1.127:9200/my_index/_doc/1?pretty' -H 'Content-Type: application/json' -d '{"name": "Broadcasted Elasticsearch News","downloadable": true}'
downloadable字段被自动地映射为boolean,在Lucene的索引中被存储为T和F。和date一样,ES解析源文档中提供的值,将true和false分别转化为T和F。(5)数组
所有基本类型都支持数组,无须修改映射,既可以使用单一值,也可以使用数组:
curl -XPUT '172.16.1.127:9200/blog/posts/1?pretty' -H 'Content-Type: application/json' -d '{"tags": ["first", "initial"]}'curl -XPUT '172.16.1.127:9200/blog/posts/2?pretty' -H 'Content-Type: application/json' -d '{"tags": "second"}'curl 'localhost:9200/blog/_mapping/posts?pretty'
{"blog" : {"mappings" : {"posts" : {"properties" : {"tags" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}}
3. 多字段
curl -XPUT '172.16.1.127:9200/blog/_mapping/posts?pretty' -H 'Content-Type: application/json' -d '{"posts": {"properties": {"tags": {"type": "text","index": true,"fields": {"verbatim": {"type": "text","index": false}}}}}}'
curl -XPUT '172.16.1.127:9200/blog/_mapping/posts?pretty' -H 'Content-Type: application/json' -d '{"posts": {"properties": {"tags": {"type": "text"}}}}'curl 'localhost:9200/blog/_mapping/posts?pretty'
{"blog" : {"mappings" : {"posts" : {"properties" : {"tags" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256},"verbatim" : {"type" : "text","index" : false}}}}}}}}
4. 预定义字段
通常不用部署预定义的字段。
字段名揭示了相关字段的功能。
总是以下划线(_)开头。
curl '172.16.1.127:9200/get-together/_doc/1?pretty'{"_index" : "get-together","_type" : "_doc","_id" : "1","_version" : 3,"found" : true,"_source" : {"relationship_type" : "group","name" : "Denver Clojure","organizer" : ["Daniel","Lee"],"description" : "Group of Clojure enthusiasts from Denver who want to hack on code together and learn more about Clojure","created_on" : "2012-06-15","tags" : ["clojure","denver","functional programming","jvm","java"],"members" : ["Lee","Daniel","Mike"],"location_group" : "Denver, Colorado, USA"}}
curl -XGET '172.16.1.127:9200/get-together/_search?pretty' -H 'Content-Type: application/json' -d '{"query": {"terms": {"_id": ["1"]}},"_source": ["name","organizer"]}'
{"took" : 6,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : 1,"max_score" : 1.0,"hits" : [{"_index" : "get-together","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"organizer" : ["Daniel","Lee"],"name" : "Denver Clojure"}}]}}
select name, organizer from get-together where id=1;_source字段存储所有信息,而_all是索引所有的信息。_all字段将所有字段的值连接成一个大字符串,使用空格作为分隔符,然后对其进行分析和索引,但不进行存储。这意味着可以把它作为搜索条件,但不能返回它。_all字段允许在不知道哪个字段包含值的情况下搜索文档中的值。
curl '172.16.1.127:9200/get-together/_search?q=elasticsearch&pretty'curl -X GET '172.16.1.127:9200/get-together/_search?pretty' -H 'Content-Type: application/json' -d'{"query": {"query_string": {"query": "elasticsearch"}}}'
ES用这三个字段识别单个文档。ID可以由用户手动提供:
curl -XPUT '172.16.1.127:9200/manual_id/_doc/1st?pretty' -H 'Content-Type: application/json' -d '{"name": "Elasticsearch Denver"}'
{"_index" : "manual_id","_type" : "_doc","_id" : "1st","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1}
curl -XPOST '172.16.1.127:9200/logs/_doc/?pretty' -H 'Content-Type: application/json' -d '{"message": "I have an automatic id"}'
{"_index" : "logs","_type" : "_doc","_id" : "iEbXOmgBWHJVyzwYQ9ho","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1}
curl '172.16.1.127:9200/_search?q=_index:get-together&pretty'curl '172.16.1.127:9200/_search?q=_index:blog&pretty'
二、更新数据
update get-together set organizer='Roy' where id=2;
从_source字段检索现有文档。
进行指定的修改。
删除旧的文档,在其原有位置索引新的文档。
1. 使用更新API
curl -XPOST '172.16.1.127:9200/get-together/_doc/2/_update?pretty' -H 'Content-Type: application/json' -d '{"doc": {"organizer": "Roy"}}'
curl -XPOST '172.16.1.127:9200/get-together/_doc/2/_update?pretty' -H 'Content-Type: application/json' -d '{"doc": {"organizer": "Roy"},"upsert": {"name": "Elasticsearch Denver","organizer": "Roy"}}'
默认的脚本语言是painless。
由于更新要获得现有文档的_source内容,修改并重新索引新的文档,因此脚本会修改_source中的字段。使用ctx._source来引用_source,使用ctx._source[字段名]来引用某个指定的字段。
如果需要变量,推荐在params下作为参数单独定义,和脚本本身分开。这是因为脚本需要编译,一旦编译完成,就会被缓存。如果使用不同的参数,多次运行同样的脚本,脚本只需要编译一次。之后的运行都会从缓存中获取现有的脚本。相比每次不同的脚本,这样运行会更快,因为不同的脚本每次都需要编译。这个思想和Oracle的绑定变量与软编译概念异曲同工。
curl -XPUT '172.16.1.127:9200/online-shop/_doc/1?pretty' -H 'Content-Type: application/json' -d '{"caption": "Learning Elasticsearch","price": 15}'curl -XPOST '172.16.1.127:9200/online-shop/_doc/1/_update?pretty' -H 'Content-Type: application/json' -d '{"script": {"source": "ctx._source.price += params.price_diff","params": {"price_diff": 10}}}'curl -XGET '172.16.1.127:9200/online-shop/_doc/1?pretty'
{"_index" : "online-shop","_type" : "_doc","_id" : "1","_version" : 2,"found" : true,"_source" : {"caption" : "Learning Elasticsearch","price" : 25}}
2. 通过版本实现并发控制
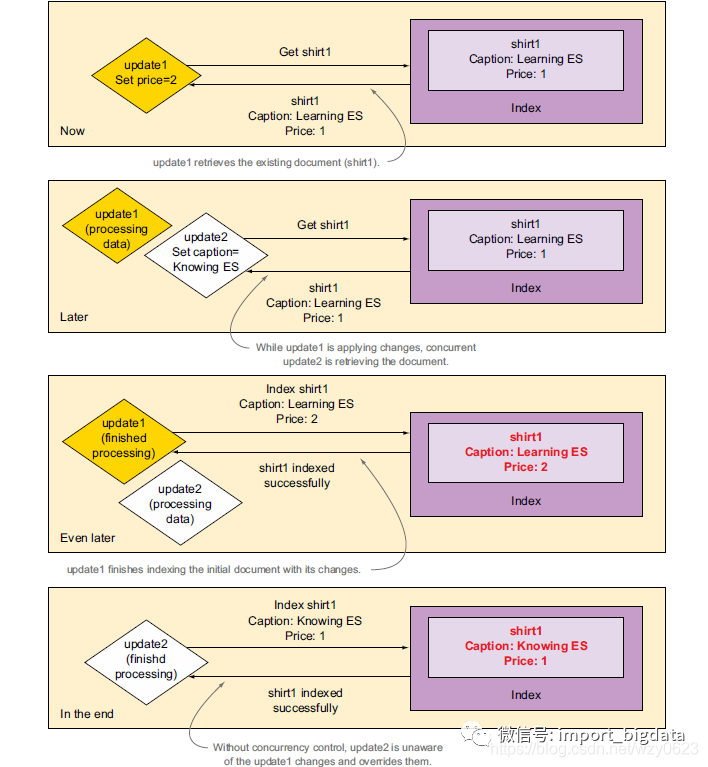
/***curl -XPOST 'localhost:9200/online-shop/shirts/1/_update' -d '{"script": "Thread.sleep(10000); ctx._source.price = 2"}' &% curl -XPOST 'localhost:9200/online-shop/shirts/1/_update' -d '{"script": "ctx._source.caption = \"Knowing Elasticsearch\""}'***/
curl -XGET "172.16.1.127:9200/online-shop/_doc/1?version=2&pretty"curl -XPOST '172.16.1.127:9200/online-shop/_doc/1/_update?pretty' -H 'Content-Type: application/json' -d '{"script": "ctx._source.caption = \"Knowing Elasticsearch\""}'curl -XGET "172.16.1.127:9200/online-shop/_doc/1?version=2&pretty"
{"error" : {"root_cause" : [{"type" : "version_conflict_engine_exception","reason" : "[_doc][1]: version conflict, current version [3] is different than the one provided [2]","index_uuid" : "b6z8mwmRQ1ambP9g5rv9vQ","shard" : "3","index" : "online-shop"}],"type" : "version_conflict_engine_exception","reason" : "[_doc][1]: version conflict, current version [3] is different than the one provided [2]","index_uuid" : "b6z8mwmRQ1ambP9g5rv9vQ","shard" : "3","index" : "online-shop"},"status" : 409}

curl -XPOST '172.16.1.127:9200/online-shop/_doc/1/_update?retry_on_conflict=3&pretty' -H 'Content-Type: application/json' -d '{"script": "ctx._source.price = 2"}'
curl -XPUT "172.16.1.127:9200/online-shop/_doc/1?version=6&pretty" -H 'Content-Type: application/json' -d '{"caption": "I Know about Elasticsearch Versioning","price": 5}'
三、删除数据
1. 删除文档
curl -XDELETE '172.16.1.127:9200/online-shop/_doc/1?pretty'curl -X POST "172.16.1.127:9200/my_index/_delete_by_query?pretty" -H 'Content-Type: application/json' -d'{"query": {"query_string": {"query": "elasticsearch"}}}'
2. 删除索引
# 删除一个索引curl -XDELETE "172.16.1.127:9200/blog?&pretty"# 删除多个索引curl -XDELETE "172.16.1.127:9200/my_index,manual_id?&pretty"
3. 关闭索引
# 关闭索引curl -XPOST '172.16.1.127:9200/logs/_close?pretty'# 打开索引curl -XPOST '172.16.1.127:9200/logs/_open?pretty'


版权声明:
文章不错?点个【在看】吧! ?
评论