
ElasticSearch索引、文档基本操作
一、ElasticSearc 数据结构
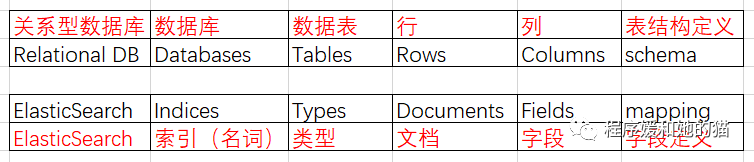
ES 用于索引和搜索的基本单位是文档,可以将其认为是 MySQL 里的一行。文档以类型来分组,类型中包含若干文档,类似 MySQL 表中包含若干行。最终,一个或多个类型存在于同一索引中,索引类似于 MySQL 中的数据库。
注意上面这段话中出现的两个“索引”,在学习 ES 的过程中,有三种“索引”,分别是不同的含义:
1、索引(名词):ES 中存储数据的一个结构,类似于 MySQL 中的数据库。
2、索引(动词):保存一个文档到索引(名词)的过程,类似于 SQL 语句中的 INSERT 关键词,如果该文档已经存在,就相当于 UPDATE 关键字。
3、索引(倒排索引):ES 使用一个叫做“倒排索引”的数据结构,提高数据检索速度,类似于 MySQL 中 B+ 树结构的索引。
我们可以画一个简单的对比图来类比 ElasticSearch 和传统关系型数据库 MySQL,从而帮助我们更好地理解 ES 的这些概念,见下图1。
索引、类型、文档、字段在 ES 中的结构如下图2所示。
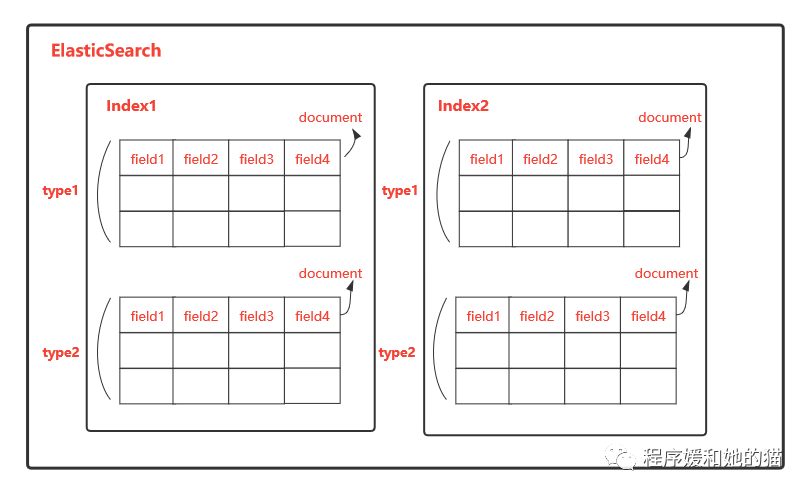
从以上描述,我们可以知道,“索引+类型+文档ID”这个组合就可以“唯一”确定 ES 中的某篇文档,下面我们详细讲述一下什么是文档、类型和索引。
1、索引(Index)
索引是文档的容器,是一类文档的集合,等同于 MySQL 中的数据库。
索引命名规范:索引受文件系统的限制。仅可能为小写字母,不能下划线开头。
举例说明:比如电商系统,有一个 customer_info 索引,存储商城所有客户的信息。
2、类型(Type)
类型用于区分同一个索引下不同的数据类型,等同于 MySQL 中的表。
类型命名规范:类型名称可以包括除了null的任何字符,不能以下划线开头。7.0版本之后不再支持类型,默认为_doc。
举例说明:customer_info 索引中有两个类型,分别是 common_customer_info 和 vip_customer_info,分别表示普通客户信息和vip客户信息。
我们需要注意一下 ES 关于类型(Type)的改革:
在 5.X 版本中,一个索引下可以创建多个类型。
在 6.X 版本中,一个索引下只能存在一个类型。
在 7.X 版本中,一个 Index 中只有一个默认的 Type,这个 Type 的名字为_doc。即在 7.x 版本的 ES 中,库表合一,Index 既可以被认为对应 MySQL 的 Database,也可以认为对应 Table。也可以这样理解:ES 实例对应 MySQL 实例中的一个 Database,Index 对应 MySQL 中的 Table,Document 对应 MySQL 中表的一行记录。
在 8.x 版本中,彻底废除 Type。
为什么不建议使用类型呢?或者说,为什么 ES 后来也逐渐废弃了类型呢?
这是因为 ES 是基于 Lucene 实现的搜索引擎,Lucene 的全文检索功能之所以快,是因为“倒排索引”的存在。而这种“倒排索引”是基于索引(index)生成的,并非类型(type),多个类型(type)反而会减慢搜索的速度。
为了保持 Elasticsearch “一切为了搜索” 的宗旨,适当的做些改变(废除类型)也是无可厚非的,也是值得的。
3、文档(Document)
ES 中的单条记录称为文档,等同于 MySQL 中的行。
举例说明:common_customer_info 中每一行就是一个普通客户的信息,包括客户的 name、age、home、birthday、hobbies 等信息。
4、字段(field)
文档由字段组成,ElasticSearch 中的字段等同于 MySQL 中的列。
字段命名规范:字段不能使用空格,对象类型可以使用点号“.”,举例,info 字段值是一个对象 name,name 对象包括两个属性 firstname 和 lastname。
"info.name.firstname": "zhou"
"info.name.lastname": "xuejiao"
相当于:
"info": {
"name": {
"firstname": "zhou",
"lastname": "xuejiao"
}
}
举例说明:3 示例中的 name、age、home、birthday、hobbies 就是字段。
5、映射(mapping)
在 ES 中,对于字段的定义称为映射,比如 name 字段映射为字符串类型。
二、索引、文档基本操作
1、RESTful 架构
RESTful 架构有以下几个特点:
a.服务端的每一个资源都有一个 URI(统一资源标识符)与之对应。
b.客户端通过 HTTP 协议与服务端进行通信。
c.客户端通过四个 HTTP 动词(GET、POST、PUT、DELETE),对服务器端资源进行操作,GET 用来获取资源,POST 用来新建资源(也可以用于更新资源),PUT 用来更新资源,DELETE用来删除资源。
2、ES 的 RESTful 风格操作
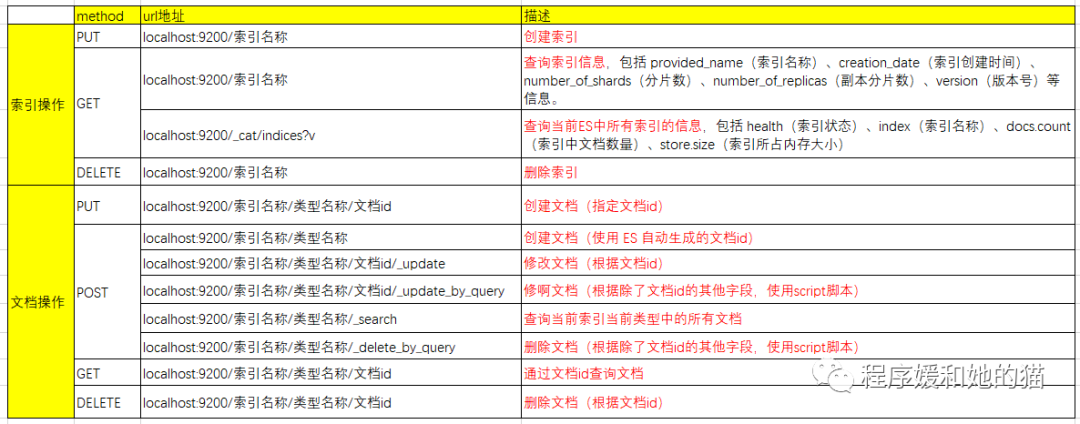
3、索引、文档基本操作案例
操作 ES 的索引、文档有多种方式,我们可以使用 curl 工具,或者使用 Kibana/Head 插件,来操作 ES 中的索引、文档,这两种方式我们都来了解
curl 是一个利用 URL 语法在 Linux 命令行下工作的文件传输工具。
(1)索引操作
a.创建索引
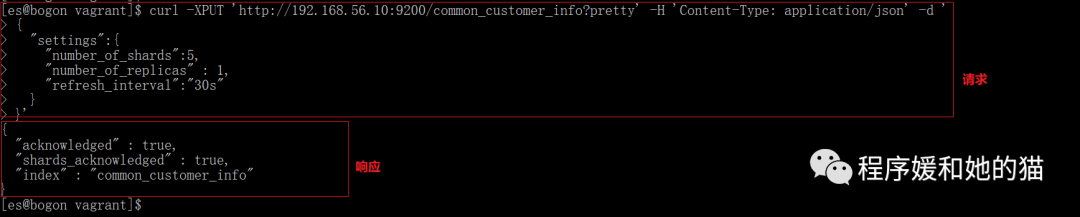
1、使用 curl 命令创建索引。
// 请求
curl -XPUT 'http://192.168.56.10:9200/common_customer_info?pretty' -H 'Content-Type: application/json' -d '
{
"settings":{
"number_of_shards":5, // 指定索引分片数量
"number_of_replicas" : 1, // 指定索引副本分片数量
"refresh_interval":"30s" // 指定索引刷新时间
}
}'
// 响应
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "common_customer_info"
}
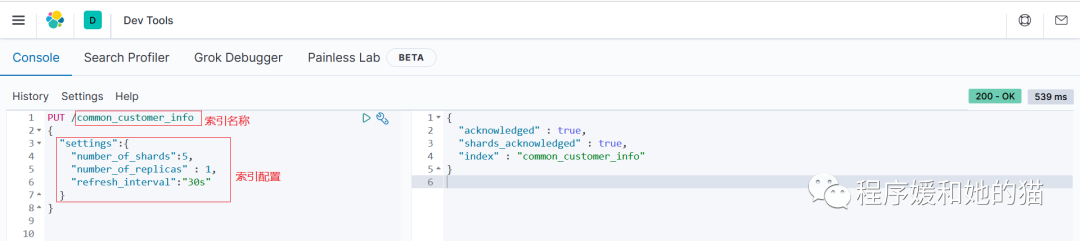
2、使用 Kibana 创建索引。
// 请求
PUT /common_customer_info
{
"settings":{
"number_of_shards":5,
"number_of_replicas" : 1,
"refresh_interval":"30s"
}
}
// 响应
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "common_customer_info"
}
b.查看索引
b.1 查看指定索引
1、使用 curl 命令查看指定索引。
// 请求,查看 common_customer_info 这个索引的信息
// 注意:如果是 GET 请求,curl 命令可以省略 -XGET
curl 'http://192.168.56.10:9200/common_customer_info'
// 响应
{
"common_customer_info" : {
"aliases" : { }, // 别名
"mappings" : { }, // 映射,即索引中有哪些字段,以及字段的类型
"settings" : { // 索引配置
"index" : {
"refresh_interval" : "30s",// 索引刷新时间
"number_of_shards" : "5",// 分片数
"provided_name" : "common_customer_info",// 索引名称
"creation_date" : "1634191993054",// 索引创建时间
"number_of_replicas" : "1",// 副本分片数
"uuid" : "rHtVcwjMSn-4vyvWv_Rr-A",// 索引id
"version" : {// 索引版本号
"created" : "7080099"
}
}
}
}
}

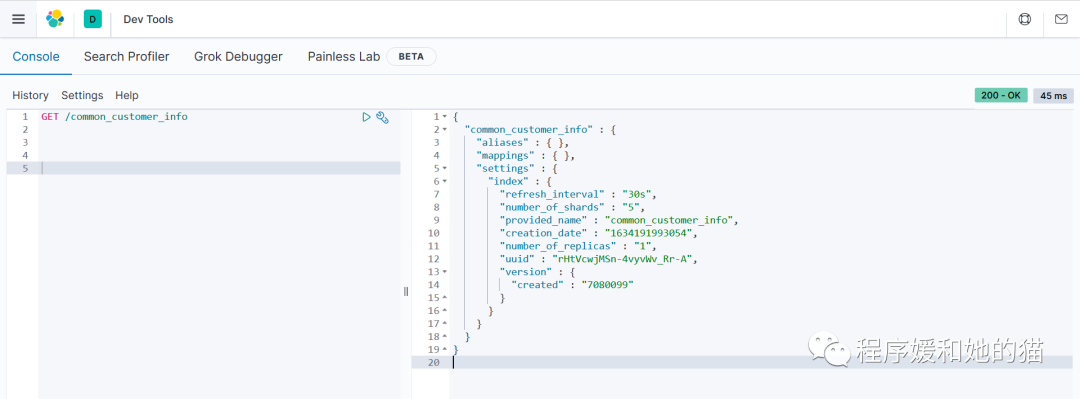
2、使用 Kibana 查看指定索引。
// 请求
GET /common_customer_info
// 响应
{
"common_customer_info" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"refresh_interval" : "30s",
"number_of_shards" : "5",
"provided_name" : "common_customer_info",
"creation_date" : "1634191993054",
"number_of_replicas" : "1",
"uuid" : "rHtVcwjMSn-4vyvWv_Rr-A",
"version" : {
"created" : "7080099"
}
}
}
}
}
b.2 查看所有索引
1、使用 curl 命令查看所有索引。
// 请求
curl http://192.168.56.10:9200/_cat/indices\?v
// 响应
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana-event-log-7.8.0-000001 LjLds26VQV2kafEdLV57Zg 1 0 5 0 25.7kb 25.7kb
green open .apm-custom-link n_FOUb-jQaqQJXeYTzQ85A 1 0 0 0 208b 208b
green open .kibana_task_manager_1 HaE-DEJmT9WoC4RbT-oCCg 1 0 5 0 45.4kb 45.4kb
green open kibana_sample_data_ecommerce K8HCVTKoSj-002bU6TxjBA 1 0 4675 0 4.2mb 4.2mb
green open .apm-agent-configuration lBbpATyqRk-mQOVzSHK7Tw 1 0 0 0 208b 208b
yellow open common_customer_info rHtVcwjMSn-4vyvWv_Rr-A 5 1 0 0 1kb 1kb
green open .kibana_1 DLYiBmlgR7G4CzOE8nNvIA 1 0 216 5 1.1mb 1.1mb

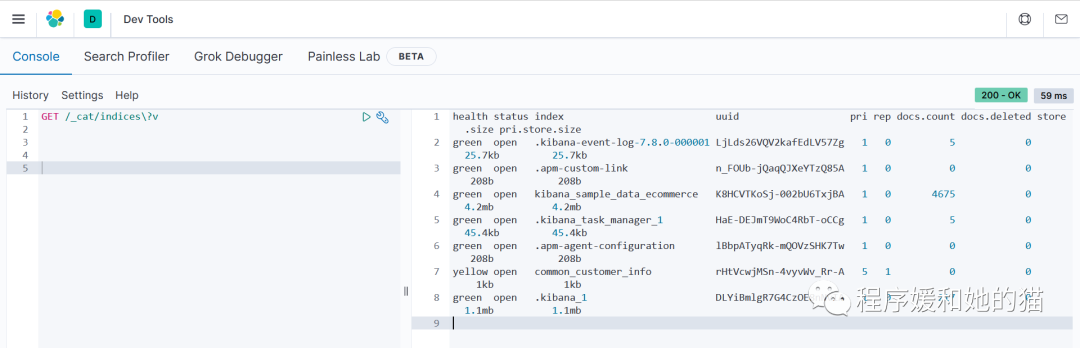
2、使用 Kibana 查看所有索引。
// 请求
GET /_cat/indices\?v
// 响应和 1 一样
b.3 根据条件查看索引
1、使用 curl 命令,根据条件查看索引。
// 请求,查看所有以字母“c”开头的索引
curl http://192.168.56.10:9200/_cat/indices/c\*\?v
// 响应
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open common_customer_info rHtVcwjMSn-4vyvWv_Rr-A 5 1 0 0 1kb 1kb

c.删除索引
1、使用 curl 命令删除索引。
// 请求,删除 common_customer_info 这个索引
curl -XDELETE 'http://192.168.56.10:9200/common_customer_info'
//响应
{
"acknowledged":true
}

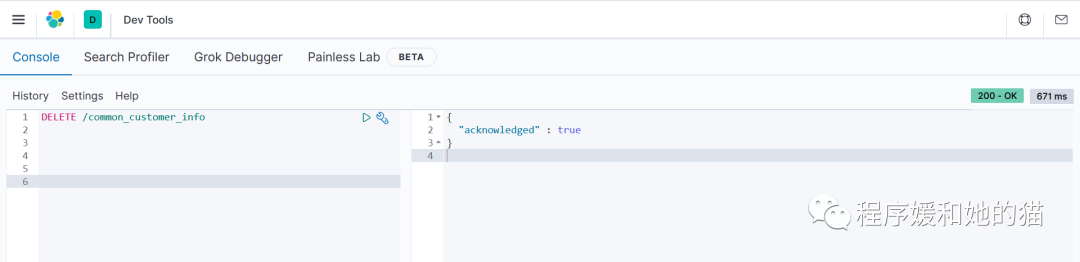
2、使用 Kibana 删除索引。
// 请求
DELETE /common_customer_info
// 响应
{
"acknowledged" : true
}
(2)文档操作
a.创建文档(指定文档id)
1、使用 curl 命令,创建文档(指定文档id)。
// 请求,1 表示新建文档的 id。
curl -XPUT "http://192.168.56.10:9200/common_customer_info/_doc/1" -H 'Content-Type: application/json' -d'
{
"name":"张三",
"age":27,
"home":"北京市朝阳区xx街道xx号",
"birthday":"1996-05-11",
"hobbies":[
"跑步",
"爬山",
"撸猫"
]
}'
// 响应
{
"_index" : "common_customer_info",// 文档所在的索引。
"_type" : "_doc",// 文档所在的类型,我们使用的类型是 ES 7.x 版本默认的 _doc。
"_id" : "1",// 文档id。
"_version" : 1,// 文档的版本信息,每对文档更新一次,版本号就加1。ES 通过使用 version 来保证对文档的变更能以正确的顺序执行,,避免乱序造成的数据丢失。
"result" : "created",// 执行结果,created 文档创建成功。
"_shards" : {// 表示分片信息。
"total" : 2,// 一共有2个分片,由下一句可以知道主分片数量为1,所以副本分片数量为 2-1=1 个。
"successful" : 1,// 数据写入主分片,"successful" : 1 表示主分片有1个,并写入成功。
"failed" : 0// 写入失败0个。
},
"_seq_no" : 0,// 严格递增的顺序号,是一个整数,保证后写入的文档的 _seq_no 大于先写入的文档的_seq_no。
"_primary_term" : 1// 和 _seq_no 一样,也是一个整数,每当主分片发生重分配时,比如重启、主分片选举,_primary_term 会递增1。
}
ElasticSearch 使用 _version、_seq_no、_primary_term 这三个字段来做版本控制。

2、使用 Kibana,创建文档(指定文档id)。
// 请求
PUT /common_customer_info/_doc/1
{
"name":"张三",
"age":27,
"home":"北京市朝阳区xx街道xx号",
"birthday":"1996-05-11",
"hobbies":[
"跑步",
"爬山",
"撸猫"
]
}
// 响应和 1 一样
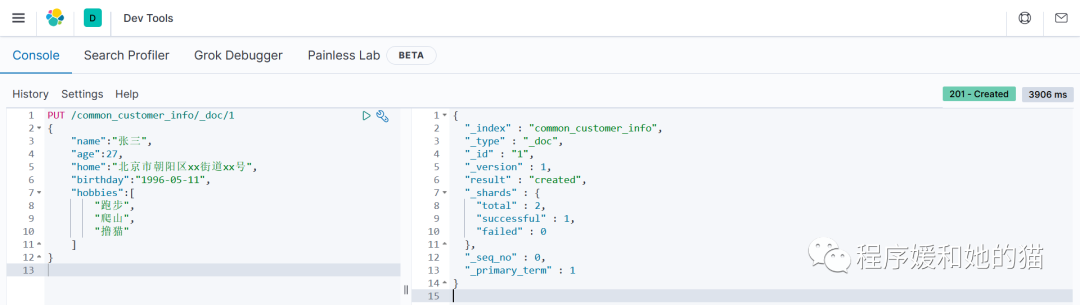
b.创建文档(不指定文档id,使用 ES 自动生成的文档id)
创建文档时,也可以不指定 id,此时 ES 会自动生成一个文档id,如果不指定 id,则需要使用 POST 请求,而不能使用 PUT 请求。
1、使用 curl 命令,创建文档(不指定文档id,使用 ES 自动生成的文档id)。
// 请求
curl -XPOST "http://192.168.56.10:9200/common_customer_info/_doc" -H 'Content-Type: application/json' -d'
{
"name":"张三",
"age":27,
"home":"北京市朝阳区xx街道xx号",
"birthday":"1996-05-11",
"hobbies":[
"跑步",
"爬山",
"撸猫"
]
}'
// 响应
{
"_index": "common_customer_info",
"_type": "_doc",
"_id": "HyrDfXwBWK9BMtd1hplW",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}

2、使用 Kibana,创建文档(不指定文档id,使用 ES 自动生成的文档id)。
POST /common_customer_info/_doc
{
"name":"张三",
"age":27,
"home":"北京市朝阳区xx街道xx号",
"birthday":"1996-05-11",
"hobbies":[
"跑步",
"爬山",
"撸猫"
]
}
// 响应和 1 差不多,只有文档id不一样,因为 ES 生成的文档id是随机的。
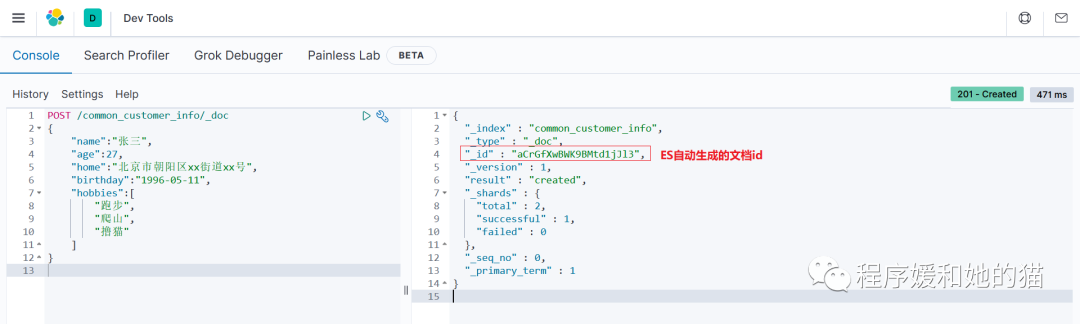
c.查询文档
c.1 查询当前索引当前类型中的所有文档
1、使用 curl 命令,查询当前索引当前类型中的所有文档。
// 请求
curl -XPOST http://192.168.56.10:9200/common_customer_info/_doc/_search
// 响应
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "common_customer_info",
"_type" : "_doc",
"_id" : "aCrGfXwBWK9BMtd1jJl3",
"_score" : 1.0,
"_source" : {
"name" : "张三",
"age" : 27,
"home" : "北京市朝阳区xx街道xx号",
"birthday" : "1996-05-11",
"hobbies" : [
"跑步",
"爬山",
"撸猫"
]
}
}
]
}
}

2、通过 Kibana,查询当前索引当前类型中的所有文档。
// 请求
POST /common_customer_info/_doc/_search
// 响应和 1 一样
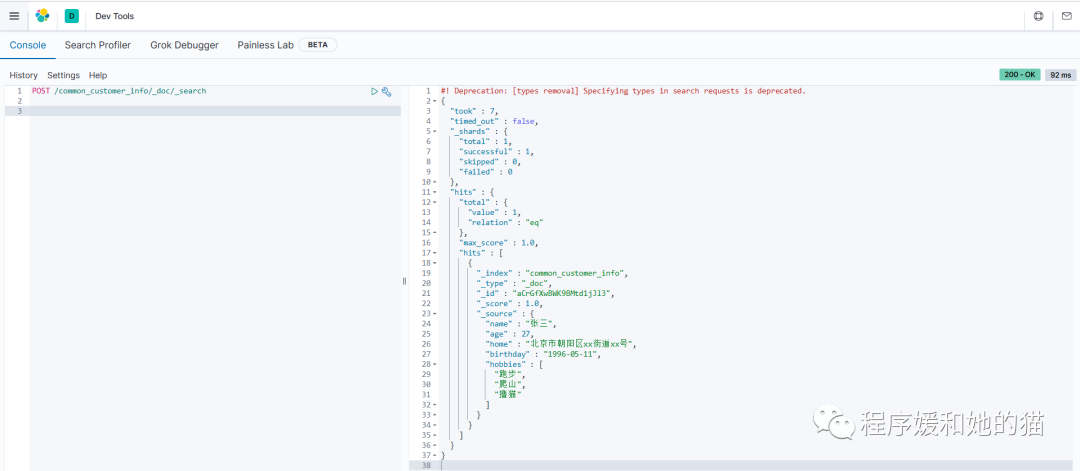
c.2 通过文档id查询文档
1、使用 curl 命令,通过文档 id 查询文档。
// 请求,查询 文档id=aCrGfXwBWK9BMtd1jJl3 的这条文档
curl http://192.168.56.10:9200/common_customer_info/_doc/aCrGfXwBWK9BMtd1jJl3
// 响应
{
"_index" : "common_customer_info",
"_type" : "_doc",
"_id" : "aCrGfXwBWK9BMtd1jJl3",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "张三",
"age" : 27,
"home" : "北京市朝阳区xx街道xx号",
"birthday" : "1996-05-11",
"hobbies" : [
"跑步",
"爬山",
"撸猫"
]
}
}

2、通过 Kibana,通过文档id查询文档。
// 请求
GET /common_customer_info/_doc/aCrGfXwBWK9BMtd1jJl3
// 响应和 1 一样
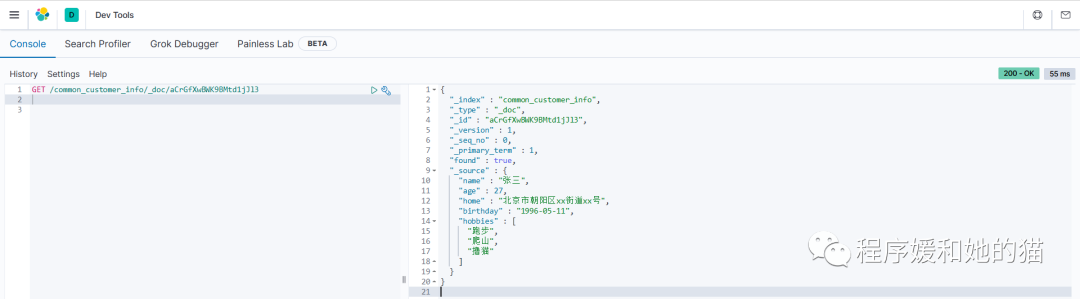
d.更新文档
d.1 根据文档id修改部分字段
在修改字段时,有一个坑大家需要注意,我就经常掉坑里(尴尬)。
我们想要修改上面那个文档,将 name 字段由"张三"修改成"李四",我想当然地写出如下请求命令:
curl -XPOST "http://192.168.56.10:9200/common_customer_info/_doc/aCrGfXwBWK9BMtd1jJl3" -H 'Content-Type: application/json' -d'
{
"name":"李四"
}'
执行这条命令,响应结果如下:
{
"_index": "common_customer_info",
"_type": "_doc",
"_id": "aCrGfXwBWK9BMtd1jJl3",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 2
}
我们再去看一下这个文档,发现name字段值修改成功了,但是整个文档只剩下 name 一个字段了,其他字段全都没了。这是因为使用这种方式,更新的文档 {"name": "李四"} 会覆盖掉原来的文档。
如果不想让除了修改字段之外的其他字段丢失,请求体中必须指明 doc,将要修改的字段放到 doc 中。
// curl 命令
curl -XPOST "http://192.168.56.10:9200/common_customer_info/_doc/aCrGfXwBWK9BMtd1jJl3" -H 'Content-Type: application/json' -d'
{
"doc":{
"name":"李四"
}
}'
// Kibana
POST /common_customer_info/_doc/aCrGfXwBWK9BMtd1jJl3/_update
{
"doc":{
"name":"李四"
}
}
d.2 根据其他条件修改
我们想根据哪个字段(除了文档id)修改文档,就把这个字段放到 script 脚本中。
在 script 脚本中,lang 表示脚本语言,painless 是 es 内置的一种脚本语言。source 表示具体执行的脚本,ctx 是一个上下文对象,通过 ctx 可以访问到 _source、_title 等。
// 请求,将 name = 李四 的 home 修改为 吉林省长春市xx街道xx号
curl -XPOST "http://192.168.56.10:9200/common_customer_info/_doc/_update_by_query" -H 'Content-Type: application/json' -d'
{
"query":{
"match":{
"name":"李四"
}
},
"script":{
"source":"ctx._source.home = \"吉林省长春市xx街道xx号\""
}
}'
f.删除文档
f.1 根据文档id删除文档
// 删除文档 id=aCrGfXwBWK9BMtd1jJl3 这条文档
curl -XDELETE "http://192.168.56.10:9200/common_customer_info/_doc/aCrGfXwBWK9BMtd1jJl3"
f.2 根据其他字段(除了文档id)删除文档
// 删除 name=李四 的所有文档
curl -XPOST "http://192.168.56.10:9200/common_customer_info/_doc/_delete_by_query" -H 'Content-Type: application/json' -d'{
"query":{
"match":{
"name":"李四"
}
}
}'