
Apache Kylin 在贝壳找房指标体系的应用
引言
Apache Kylin 在贝壳找房的发展历程

2017 年 3 月,Kylin 1.6 版本上线
随着指标平台的上线,Kylin 开始对外提供服务。
2017 年底,贝壳已经累计创建了 300 + Cube,每天有 20 多万的查询量
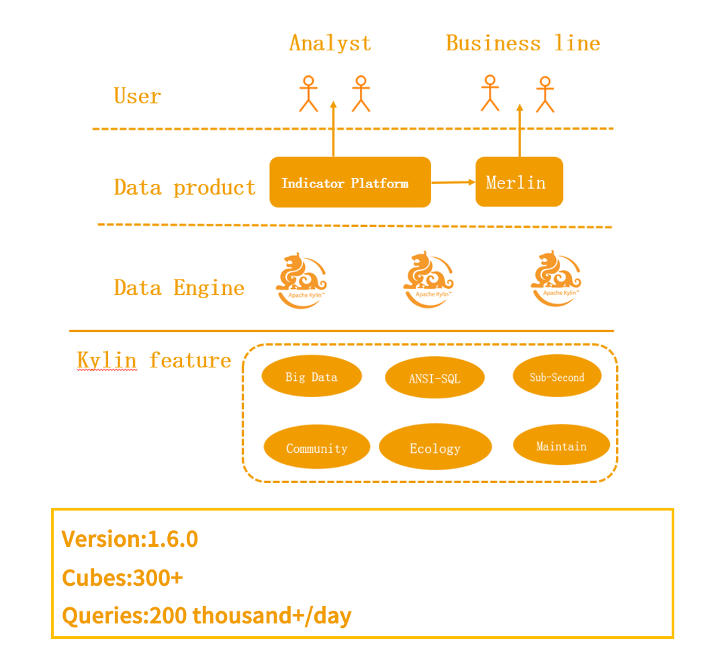
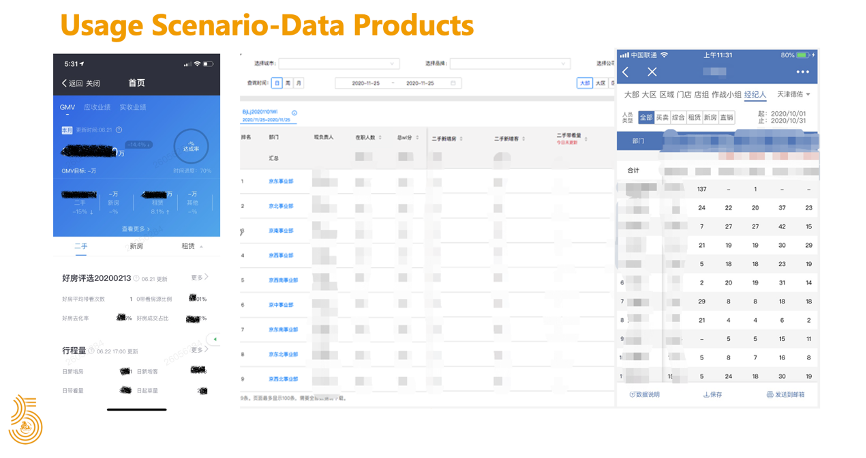
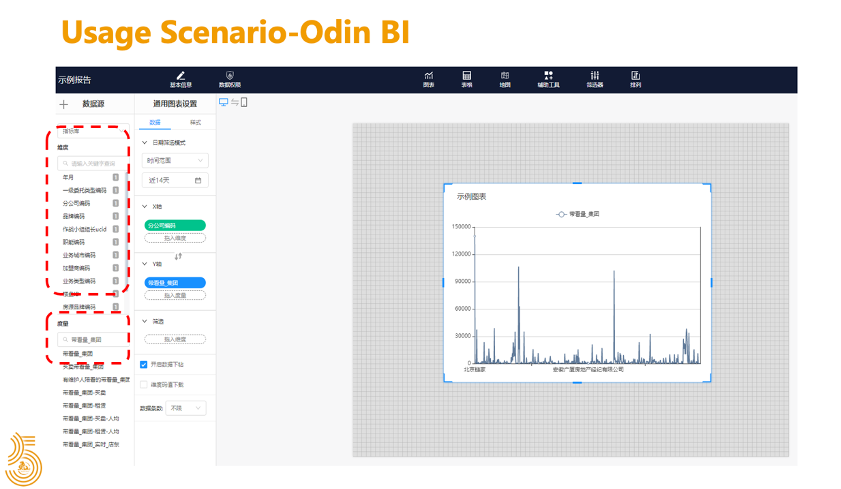
2018 年初,随着指标在各业务线的推广,有越来越多的数据产品开始接入 Kylin
例如像 Merlin、Turing 等数据产品,这些产品从PC端到手机端覆盖的范围非常广泛,涉及到公司组织架构的各个层级,都有相应的数据需求。同时为了保障重点数据的产出和查询,我们又部署了一套集群来给重点业务使用。
2018 年底,贝壳一共有 2 套集群,累计创建了 600+ Cube,每天的查询量达到了 200 万。

2019 年初,我们 Kylin Team 定下了两个 KPI,在机制方面要保障重点数据在每天上午 9 点之前产出,在查询上要达成 3 秒钟内响应占比 99.7%,将 Kylin 升级到 3.1 版本,主要来做实时多维分析的应用。

为了达成这两个目标,在计算方面我们把集群从 1.6.0升级到 2.5.2,引入了 Spark 组件,将重点 Cube 构建的方式从 MR 改为了 Spark。
上图是调优前后的对比,重点 Cube 的平均构建时间从 70 分钟降到了 43 分钟,近 40% 左右的提升;在查询方面也通过一系列的优化,在 12 月就达成了 3 秒内占比 99.7% 的目标。
下图是当时每天的统计数据,到 19 年底贝壳还是两套集群,版本是 2.5.2,累计 700+ Cubes,每天的查询量超过了 1000 万。

2020年初,Kylin 升级到 3.1.0,引入了 Flink 组件。
下图是公司的一级指标使用 Flink 组件前后花费时间的对比,可以看到提升比较明显,截止到 2020 年底,贝壳有两个3.1的集群,累计 800+ Cubes,每天的查询量最高超过了 2300 万。
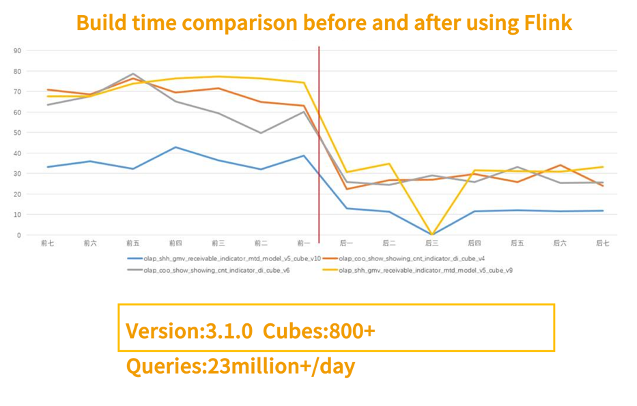
使用 Flink 前后的构建时长对比
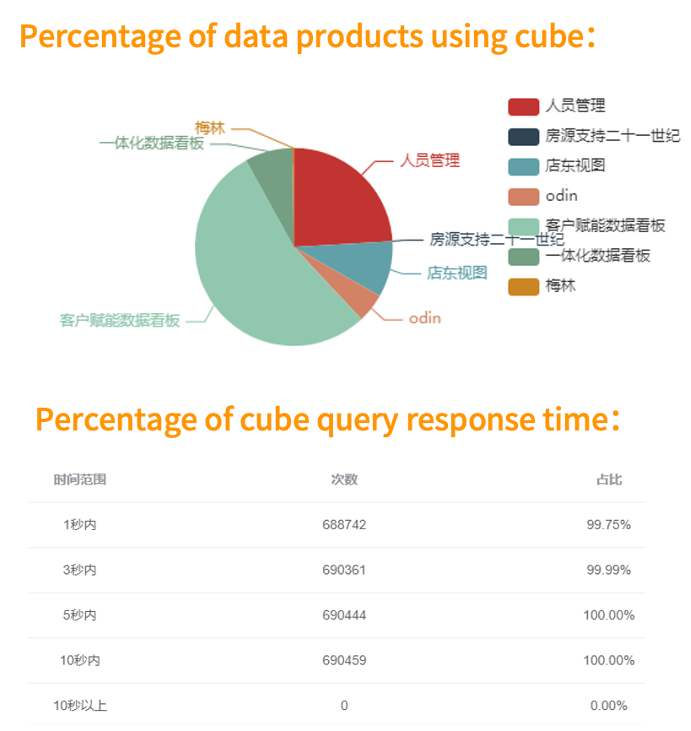
Cube 被使用最多的维度组合排行
Cube 查询慢的组合排行
最近 30 天都没有用到过的维度


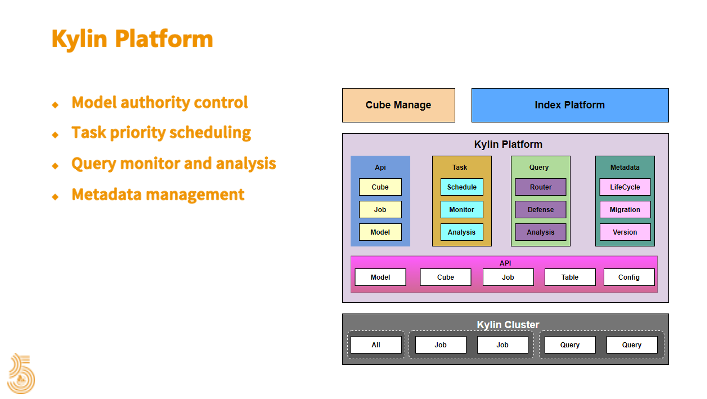
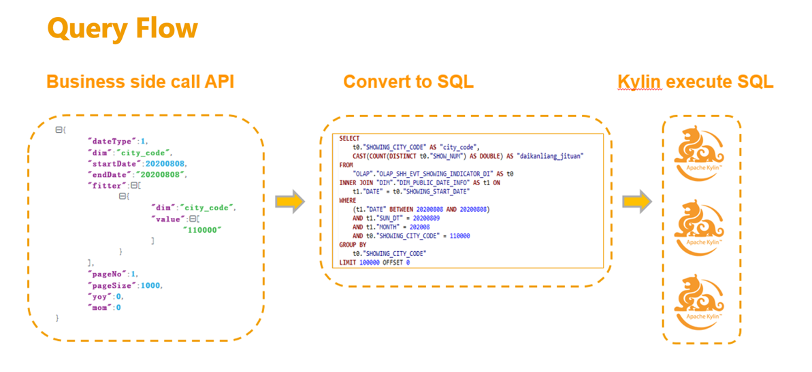
Kylin 在贝壳找房指标体系建设过程中的作用



对 Kylin 未来发展的展望
作者介绍