
一文讲清,MySQL如何解决多事务并发问题
MySQL默认事务隔离级别是repeatable-read(RR),脏读、不可重复读、幻读,都不会发生。它是怎么做到的呢?
这就是由经典的MVCC多版本并发控制机制做到的,MVCC的实现,又是基于undo log版本链的。
前面讲MySQL一行数据的存储格式,讲到了每行数据有两个隐藏的字段:trx_id、roll_pointer。trx_id就是最近一次更新这条数据的事务id,roll_pointer指向了你更新这个事务之前生成的undo log。
假设有一个事务A(id = 50),插入了一条数据A,它的数据格式如下:
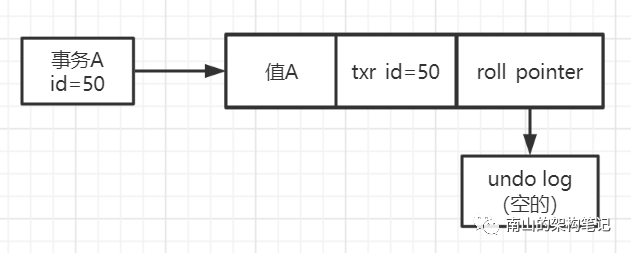
图1 undo log版本链
接着事务B修改这条数据把值修改为B,事务B的id是58,此时会生成一个undo log记录之前的值,roll_pointer指向这个undo log日志。
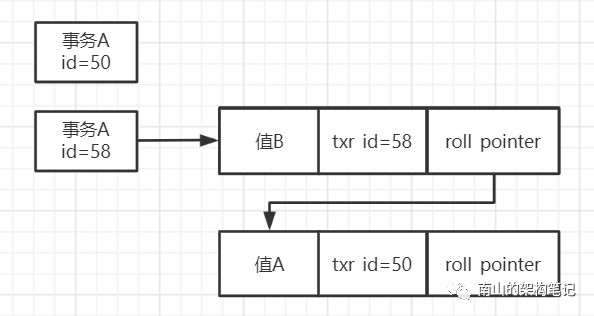
图2 undo log版本链
假设再来了一个事务C,它的事务id是68,把数据值改为了C,此时undo log版本链就变成这样了。
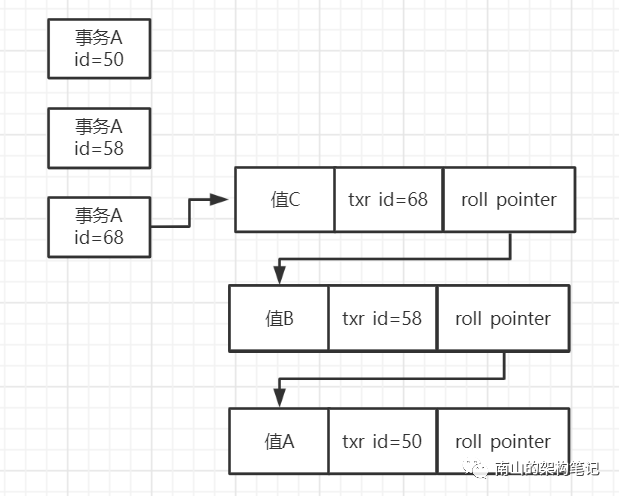
图3 undo log版本链
事务执行的时候,都会更新隐藏的字段trx_id和roll_pointer,同时之前多个数据快照对应的undo log也会通过roll_pointer串联起来,最终形成一个版本链。
基于undo log实现的ReadView
执行一个事务的时候,会生成一个ReadView,里面包含这些东西:
m_ids,此时有哪些事务在MySQL中还没有提交的事务id;
min_trx_id,m_ids里最小的;
max_trx_id,MySQL下一个要生成的事务id;
creator_trx_id,表示生成该ReadView的事务的事务id。
假设数据库中有一行数据,值是A,事务id是32,如下图所示:
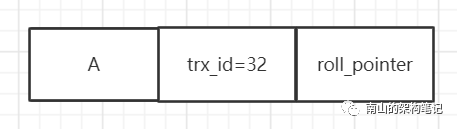
图4 初始情况下,数据库中有一行数据
此时有两个事务并发过来执行,事务A(id=45),事务B(id=59),事务A要去读取这行数据,事务B要去修改这行数据。
事务A开启一个ReadView,此时它长这样:

图5 ReadView
ReadView的m_ids包含事务A和事务B的两个id,45和49,min_trx_id是45,max_trx_id是60,creator_trx_id就是45,就是事务A自己。
这时候事务A第一次查询这行数据,会去判断一下当前这行数据的trx_id是否小于ReadView中的min_trx_id。现在trx_id = 32,是小于ReadView里的min_trx_id=45的,说明你事务开启之前,修改这行数据的事务早就提交了,所以此时可以查询到这行数据。
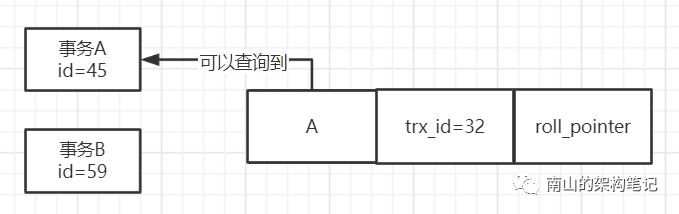
图6 事务A读取数据
接着事务B开始修改这行数据,事务B把值修改为B,然后这行数据的trx_id设置为自己的id,也就是59,同时roll_pointer指向了修改之前生成的undo log。
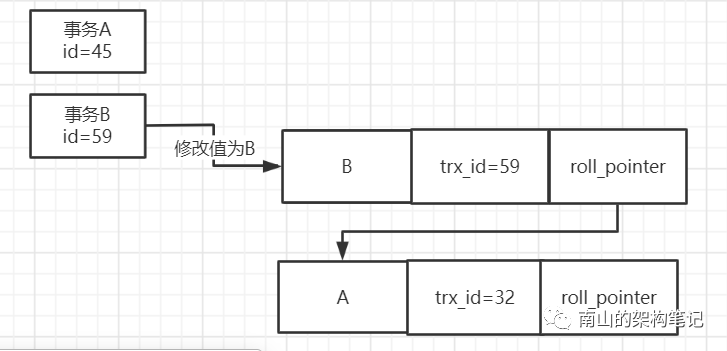
图7 事务B修改数据
这时候事务A第二次查询,发现此时数据行里的trx_id=59,大于ReadView里的min_trx_id=45,同时小于max_trx_id=60,说明更新这条数据的事务,很可能跟自己差不多同时开启。果然ReadView的m_ids里有45和59两个事务id,事务B是跟自己并发执行提交的,所以这行数据是不能查询的。
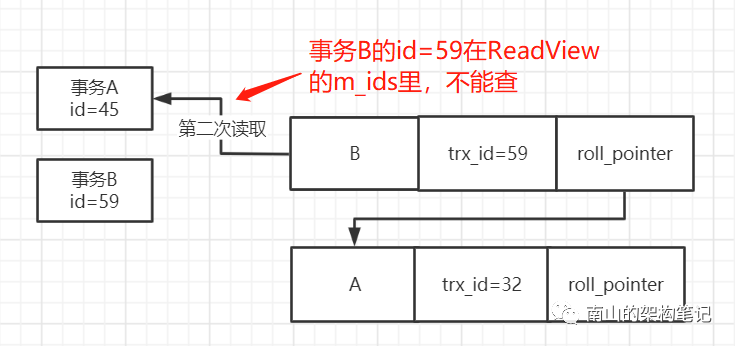
图8 事务A第二次读数据
事务A不能查修改后的值,那怎么办?顺着undo log版本链查询之前的版本!
于是就会查到trx_id=32的数据,trx_id=32是小于ReadView里min_trx_id=45的,可以查出来。
看到这里,大家能不能猜想到多事务并发的时候,MySQL是如何解决那一堆问题的?就是通过undo log版本链 + ReadView解决的!
假设事务A执行的过程中,事务C来更新这行数据为C,事务id=78。

图9 事务C修改数据
此时事务A第三次去查,发现当前数据的trx_id=78,比ReadView中的max_trx_id=60还大,说明这条数据是事务A开启之后修改的,不应该查到!
于是事务A顺着undo log版本链往下找,先找到trx_id=59的数据,上面分析过了,这条数据也不能查,于是继续向undo log版本链向下找,最终返回trx_id=32的数据。
通过undo log版本链和ReadView,MySQL就可以保证你只能读取到事务开启前别的事务更新的值,和自己更新的值。
总的来说,就是一个事务只能读取到事务id小于等于自己的数据。
读已提交(RC)如何基于MVCC实现多事务并发控制?
只要你搞明白了上面的undo log版本链 + ReadView机制,对于RC、RR如何基于这套机制实现多版本并发控制,就非常好理解了。
首先,有一点非常重要,RC隔离级别下,一个事务每次发起查询,都会生成一个ReadView。
假设库里有一行数据,trx_id=50,现在有两个事务A(id=60),事务B(id=70)并发执行。
事务B修改数据值为B,此时trx_id=70,如图:
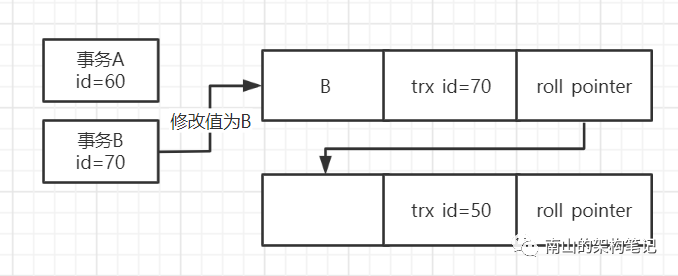
这时候,事务B还没提交,事务A发起查询,那么就会生成已给ReadView。
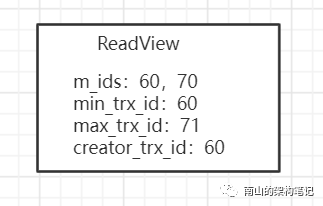
ReadView的m_ids里活跃的事务由60和70,此时事务A是无法查出事务B修改的值B的。于是顺着版本链向下找,就找到trx_id=50的数据了。
接着,事务B提交了,事务A再次发起查询,又生成了一个ReadView。
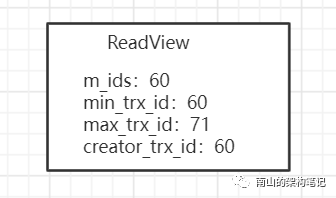
事务A再次基于ReadView查询,发现这条数据的trx_id虽然在min_trx_id和max_trx_id之间,却不在m_id里,说明事务B在生成本次ReadView之前已经提交了,那么本次就可以查询到事务B修改的这个值了。
RC隔离级别如何实现的,级别就讲完了,其关键在于每次查询都会生成一个新的ReadView。
可重复读(RR)如何基于MVCC实现多事务并发控制?
可重复读隔离级别下,解决了脏读、不可重复读、幻读这些问题,它是如何实现的呢?
假设,数据库有一条数据trx_id=50,现在有两个事务A(id=60),事务B(id= 70)并发执行。
事务A发起一个查询,会生成一个ReadView。

这个事务A基于这个ReadView去查这条数据,会发现trx_id =50,小于ReadView里的min_trx_id,可以直接查出来。
接着事务B修改数据值为B,此时会修改trx_id=70,然后提交事务。
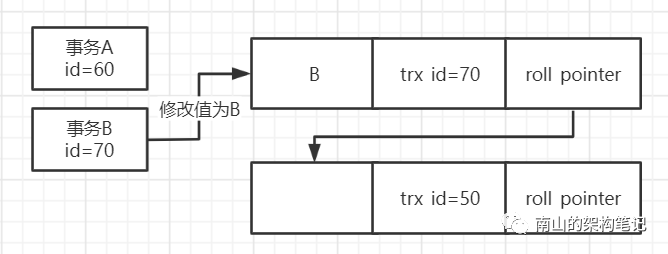
接着事务A第二次去查询这条数据,要知道它的ReadView没有变。它会发现此时数据的trx_id=70在min_trx_id和max_trx_id之间,并且在m_ids中。那肯定不能查询出来。于是顺着undo log版本链向下找。
找到了trx_id=50的数据,这条数据是事务A开启查询之前提交了,可以返回。
所有,RR隔离级别下,事务多次查询,它的ReadView是不变的,这与RC是不同的,RC隔离级别下,每次查询都会生成应给ReadView。
RR隔离级别下,就这样解决了不可重复读问题。
由于RR隔离级别下,ReadView只会生成一次,那么你可以简单的理解成,MySQL多事务并发执行时,只能查询到事务id比小于等于自己的数据。
其实幻读的解决方法与解决不可重复读原理是一样的,笔者这里就不再多赘述,有兴趣的同学可以自己整理下思路,在脑子里过一下它内部的运行流程。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️